Azure Time Series Insights Gen1에서 모니터링을 수행하고 제한을 축소하여 대기 시간 줄이기
참고 항목
Time Series Insights 서비스는 2024년 7월 7일에 사용 중지됩니다. 최대한 빨리 기존 환경을 대체 솔루션으로 마이그레이션하는 것이 좋습니다. 사용 중단 및 마이그레이션에 대한 자세한 내용은 설명서를 참조하세요.
주의
이는 Gen1 문서입니다.
들어오는 데이터의 양이 사용자의 환경 구성을 초과하면 Azure Time Series Insights에서 대기 시간 또는 제한이 발생할 수 있습니다.
분석하려는 데이터의 양에 맞게 환경을 적절히 구성하여 대기 시간 및 제한을 방지할 수 있습니다.
다음과 같은 경우 대기 시간 및 제한이 발생할 수 있습니다.
- 할당된 수신 속도를 초과할 수 있는 오래된 데이터가 포함된 이벤트 원본을 추가합니다(Azure Time Series Insights를 확인해야 합니다).
- 더 많은 이벤트 원본을 환경에 추가하면 추가 이벤트가 발생할 수 있습니다(환경 용량을 초과할 수 있음).
- 많은 양의 기록 이벤트를 이벤트 원본으로 푸시하면 지연이 발생합니다(Azure Time Series Insights를 확인해야 합니다).
- 원격 분석을 사용하여 참조 데이터를 결합하면 이벤트 크기가 더 커집니다. 최대 허용 패킷 크기는 32KB입니다. 32KB보다 큰 데이터 패킷은 잘립니다.
동영상
Azure Time Series Insights 데이터 수신 동작과 그 계획 방법에 대해 알아봅니다.
경고를 사용하여 대기 시간 및 제한 모니터링
경고를 통해 사용자 환경에서 발생하는 대기 시간 문제를 진단하고 완화할 수 있습니다.
Azure Portal에서 Azure Time Series Insights 환경을 선택합니다. 그런 다음 경고를 선택합니다.
+ 새 경고 규칙을 선택합니다. 규칙 생성하기 페이지가 표시됩니다. 조건 아래에서 추가를 선택합니다.
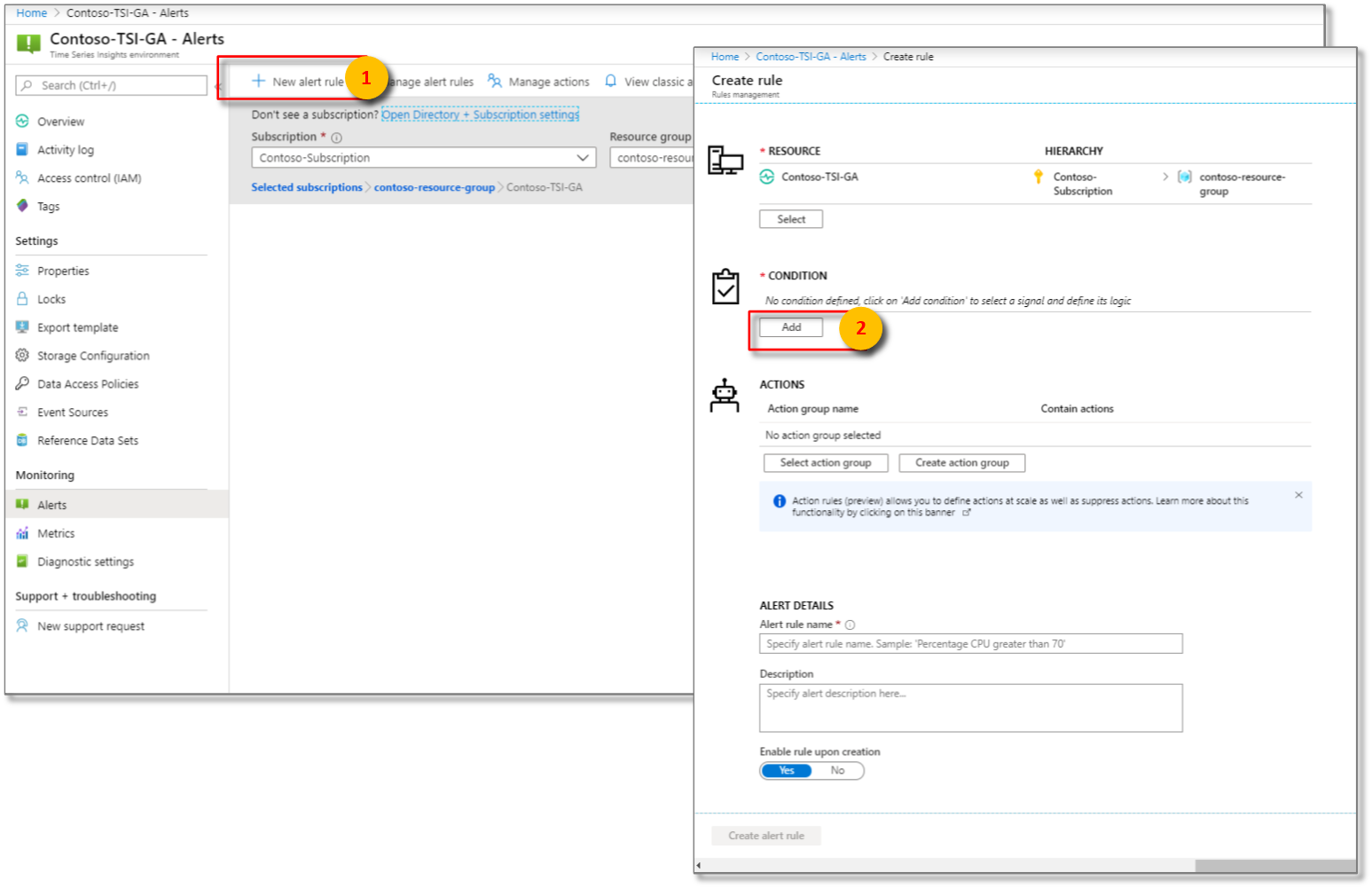
그런 다음 신호 논리에 대한 정확한 조건을 구성합니다.
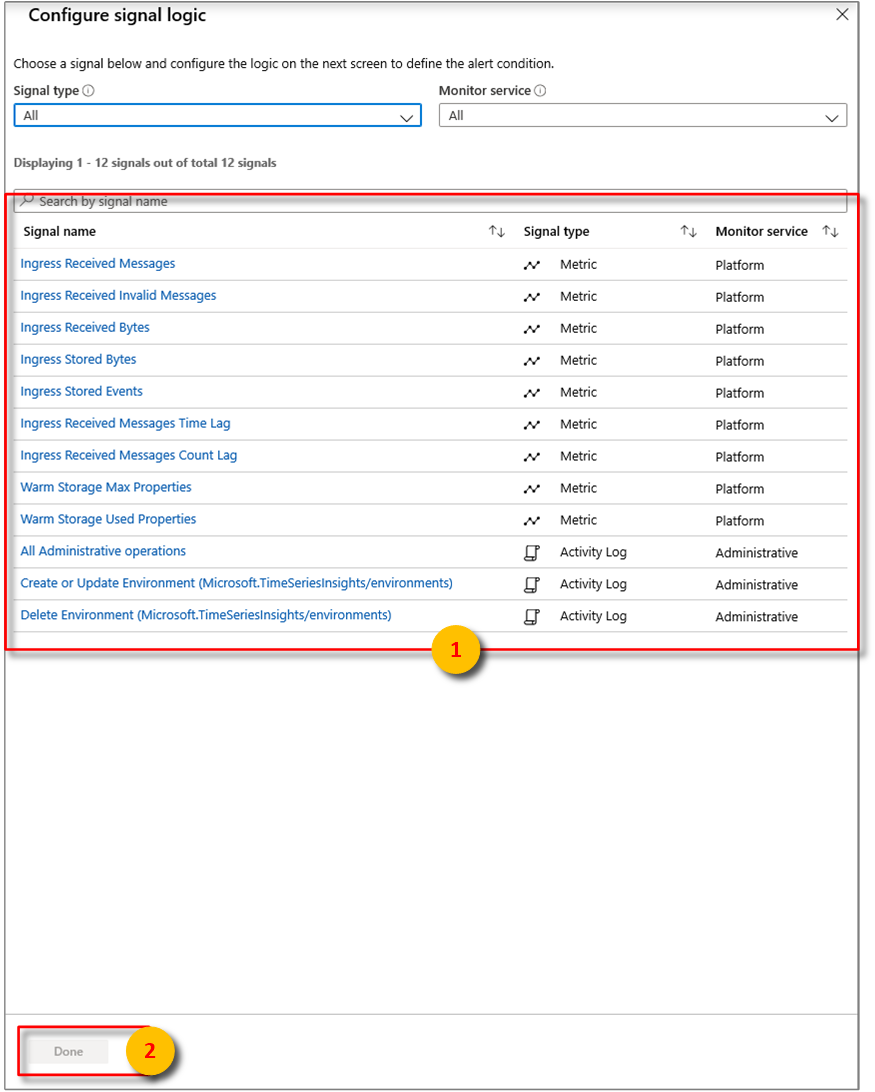
여기에서 다음 조건을 사용하여 경고를 구성할 수 있습니다.
메트릭 설명 수신된 바이트 이벤트 원본에서 읽은 원시 바이트 수입니다. 일반적으로 원시 바이트 수에는 속성 이름 및 값이 포함됩니다. 수신된 잘못된 메시지 모든 Azure Event Hubs 또는 Azure IoT Hub 이벤트 원본에서 읽은 잘못된 메시지 수입니다. 수신된 메시지 모든 Event Hubs 또는 IoT Hub 이벤트 원본에서 읽은 메시지 수입니다. 저장된 수신 바이트 저장되어 쿼리에 사용할 수 있는 총 이벤트 크기입니다. 크기는 속성 값에 대해서만 계산됩니다. 저장된 수신 이벤트 저장되어 쿼리에 사용할 수 있는 일반 이벤트 수입니다. 수신된 메시지 시간 지연 메시지가 이벤트 원본의 큐에 대기되는 시간과 수신 처리되는 시간 간의 차이(초)입니다. 수신된 메시지 수 지연 이벤트 원본 파티션에서 마지막 큐에 대기된 메시지의 시퀀스 번호와 수신 처리되는 메시지의 시퀀스 번호 간의 차이입니다. 완료를 선택합니다.
원하는 신호 논리를 구성한 후에는 선택한 경고 규칙을 시각적으로 검토합니다.
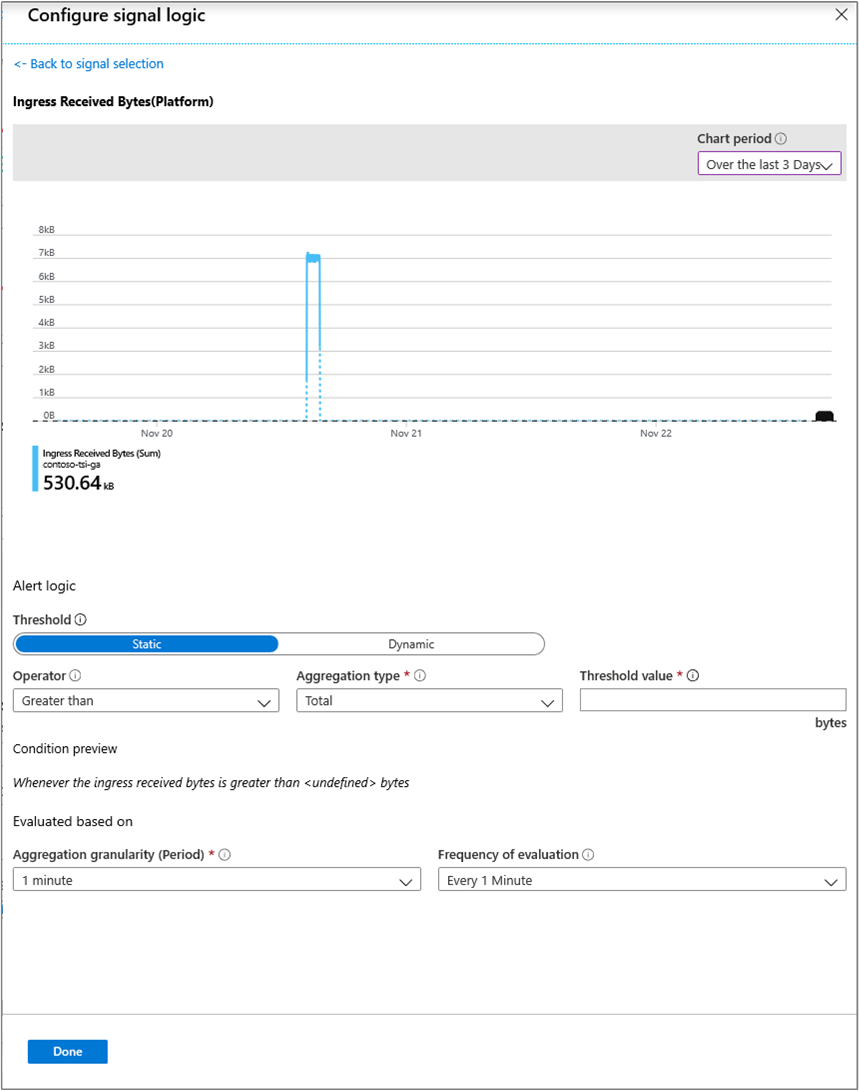




제한 및 수신 관리
제한이 적용되는 경우 Azure Time Series Insights 환경에서 메시지가 이벤트 원본을 거치는 실제 시간이 되기까지 몇 초가 남았는지를 나타내는 수신된 메시지 시간 지연 값이 등록됩니다(약 30-60초의 인덱싱 시간 제외).
수신된 메시지 수 지연에도 값이 표시되므로 메시지가 뒤에 몇 개나 더 남아 있는지 알 수 있습니다. 이러한 차이를 해소하는 가장 쉬운 방법은 작업 환경의 용량을 차이가 극복될 수 있는 크기로 늘리는 것입니다.
예를 들어 S1 환경에서 500만 메시지의 지연 시간을 보여주는 경우, 사용자 환경의 크기를 하루 중 6개 단위로 늘려 검색할 수 있습니다. 더 빠르게 따라잡기 위해 더 크게 늘릴 수도 있습니다. 캐치업 시간은 처음에 환경을 프로비전할 때 일반적으로 발생하고, 이미 이벤트가 포함된 이벤트 원본에 연결하거나 많은 기록 데이터를 대량으로 업로드할 때 특히 두드러집니다.
또 다른 방법은 저장된 수신 이벤트 경고를 2시간 동안의 전체 환경 용량보다 약간 낮게 설정하는 것입니다. 이 경고는 용량이 일정한지 이해하는 데 도움이 되며 대기 시간이 길어질 가능성이 높다는 것을 나타냅니다.
예를 들어 3개의 S1 장치가 프로비전된 경우(또는 1분당 2100개의 이벤트를 수신하는 경우) 저장된 수신 이벤트 경고를 2시간 동안 1900개 이벤트 이하로 설정할 수 있습니다. 이 임계값을 지속적으로 초과하여 경고를 발생시키는 경우 프로비전 부족 상태가 될 가능성이 큽니다.
제한이 의심되는 경우, 수신된 메시지 수를 이벤트 원본의 발신 메시지와 비교할 수 있습니다. Event Hub로 수신된 메시지 수가 수신된 메시지 수보다 크면 Azure Time Series Insights가 제한될 수 있습니다.
성능 향상
제한 또는 대기 시간을 줄이고 싶을 때 이를 수정하는 가장 좋은 방법은 환경의 용량을 늘리는 것입니다.
분석하려는 데이터의 양에 맞게 환경을 적절히 구성하여 대기 시간 및 제한을 방지할 수 있습니다. 환경에 용량을 추가하는 방법에 대한 자세한 내용은 환경 스케일링을 참조하세요.