Red Hat Enterprise Linux Server의 Azure VM에서 IBM DB2 LUW의 고가용성
HADR(고가용성 및 재해 복구) 구성의 LUW(Linux, UNIX 및 Windows)용 IBM Db2는 주 데이터베이스 인스턴스를 실행하는 노드 하나와 보조 데이터베이스 인스턴스를 실행하는 하나 이상의 노드로 구성됩니다. 주 데이터베이스 인스턴스에 대한 변경 사항은 구성에 따라 동기식 또는 비동기식으로 보조 데이터베이스 인스턴스에 복제됩니다.
참고 항목
이 문서에는 Microsoft가 더 이상 사용하지 않는 용어에 대한 참조가 포함되어 있습니다. 해당 용어가 소프트웨어에서 제거되면 이 문서에서도 제거할 것입니다.
이 문서에서는 Azure VM(가상 머신)을 배포 및 구성하고, 클러스터 프레임워크를 설치하고, HADR 구성이 포함된 IBM Db2 LUW를 설치하는 방법을 설명합니다.
SAP 소프트웨어 설치 또는 HADR이 포함된 IBM Db2 LUW를 설치하고 구성하는 방법은 이 문서에서 다루지 않습니다. 이러한 작업을 수행하는 데 도움이 되도록 SAP 및 IBM 설치 설명서에 대한 참조가 제공됩니다. 이 문서에서는 Azure 환경과 관련된 부분에 대해 중점을 두고 설명합니다.
지원되는 IBM Db2 버전은 10.5 이상이며, SAP 노트 1928533에 설명되어 있습니다.
설치를 시작하기 전에 다음 SAP 노트 및 설명서를 참조하세요.
| SAP 노트 | 설명 |
|---|---|
| 1928533 | Azure의 SAP 애플리케이션: 지원 제품 및 Azure VM 유형 |
| 2015553 | Azure의 SAP: 필수 구성 요소 지원 |
| 2178632 | Azure의 SAP에 대한 주요 모니터링 메트릭 |
| 2191498 | Azure와 Linux의 SAP: 향상된 모니터링 |
| 2243692 | Linux on Azure(IaaS) VM: SAP 라이선스 문제 |
| 2002167 | Red Hat Enterprise Linux 7.x: 설치 및 업그레이드 |
| 2694118 | Azure의 Red Hat Enterprise Linux HA 추가 항목 |
| 1999351 | SAP용 고급 Azure 모니터링 문제 해결 |
| 2233094 | DB6: Linux, UNIX 및 Windows용 IBM Db2를 사용하는 Azure의 SAP 애플리케이션 - 추가 정보 |
| 1612105 | DB6: HADR이 포함된 Db2에 대한 FAQ |
| 설명서 |
|---|
| SAP Community Wiki: Linux에 필요한 모든 SAP 노트를 포함하고 있습니다. |
| Linux에서 SAP용 Azure Virtual Machines 계획 및 구현 가이드 |
| Linux에서 SAP용 Azure Virtual Machines 배포(이 문서) |
| Linux에서 SAP용 Azure Virtual Machines DBMS(데이터베이스 관리 시스템) 배포 가이드 |
| Azure의 SAP 워크로드 계획 및 배포 검사 목록 |
| Red Hat Enterprise Linux 7용 고가용성 추가 항목 개요 |
| High Availability Add-On Administration(고가용성 추가 기능 관리) |
| High Availability Add-On Reference(고가용성 추가 기능 참조) |
| Support Policies for RHEL High Availability Clusters - Microsoft Azure Virtual Machines as Cluster Members(RHEL 고가용성 클러스터용 지원 정책 - Microsoft Azure Virtual Machines(클러스터 멤버)) |
| Installing and Configuring a Red Hat Enterprise Linux 7.4 (and later) High-Availability Cluster on Microsoft Azure(Microsoft Azure에서 Red Hat Enterprise Linux 7.4 이상 고가용성 클러스터 설치 및 구성) |
| SAP 워크로드용 IBM DB2 Azure Virtual Machines DBMS 배포 |
| IBM Db2 HADR 11.1 |
| IBM Db2 HADR 10.5 |
| RHEL 고가용성 클러스터에 대한 지원 정책 - 클러스터에서 Linux, Unix 및 Windows용 IBM Db2 관리 |
개요
고가용성을 달성하기 위해 HADR이 포함된 IBM Db2 LUW는 두 개 이상의 Azure Virtual Machines에 설치되며, 이 가상 머신은 가용성 영역 또는 가용성 집합에서 유연한 오케스트레이션을 통해 가상 머신 확장 집합에 배포됩니다.
다음 그래픽에는 두 데이터베이스 서버 Azure VM의 설정이 나와 있습니다. 두 데이터베이스 서버 Azure VM은 각자 자체 스토리지와 연결되어 있고 실행 중입니다. HADR에서는 Azure VM 중 하나의 데이터베이스 인스턴스 하나가 주 인스턴스 역할을 갖습니다. 모든 클라이언트는 주 인스턴스에 연결됩니다. 데이터베이스 트랜잭션의 모든 변경 내용은 로컬에서 Db2 트랜잭션 로그에 유지됩니다. 트랜잭션 로그 레코드가 로컬에 유지되면서, TCP/IP를 통해 두 번째 데이터베이스 서버, 대기 서버 또는 대기 인스턴스의 데이터베이스 인스턴스로 레코드가 전송됩니다. 대기 인스턴스는 전송된 트랜잭션 로그 레코드를 롤포워드하여 로컬 데이터베이스를 업데이트합니다. 이러한 방식으로 대기 서버는 주 서버와 동기화된 상태를 유지합니다.
HADR은 복제 기능일 뿐입니다. 오류 검색 및 자동 인수 또는 장애 조치(failover) 기능은 없습니다. 대기 서버로의 전송이나 인수는 데이터베이스 관리자가 수동으로 시작해야 합니다. 자동 인수 및 오류 검색을 수행하기 위해 Linux Pacemaker 클러스터링 기능을 사용할 수 있습니다. Pacemaker는 두 개의 데이터베이스 서버 인스턴스를 모니터링합니다. 주 데이터베이스 서버 인스턴스가 충돌하면 Pacemaker는 대기 서버에서 자동 HADR 인수를 시작합니다. 또한 Pacemaker는 가상 IP 주소가 새 주 서버에 할당되도록 합니다.
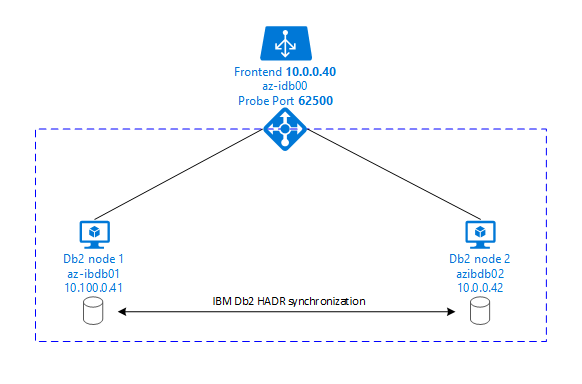
SAP 애플리케이션 서버를 주 데이터베이스에 연결하려면 가상 호스트 이름 및 가상 IP 주소가 필요합니다. 장애 조치(failover) 후 SAP 애플리케이션 서버는 새로운 주 데이터베이스 인스턴스에 연결됩니다. Azure 환경에서 IBM Db2의 HADR에 필요한 방식으로 가상 IP 주소를 사용하려면 Azure Load Balancer가 필요합니다.
HADR 및 Pacemaker가 포함된 IBM Db2 LUW가 고가용성 SAP 시스템 설정에 얼마나 적합한지 완전히 이해하는 데 참고할 수 있는 IBM Db2 데이터베이스에 기반한 SAP 시스템의 고가용성 설정에 대한 개요가 아래 이미지에 제공됩니다. 이 문서에서는 IBM Db2에 대해서만 설명하고 SAP 시스템의 다른 구성 요소를 설정하는 방법에 대해서는 다른 문서에 대한 참조를 제공합니다.
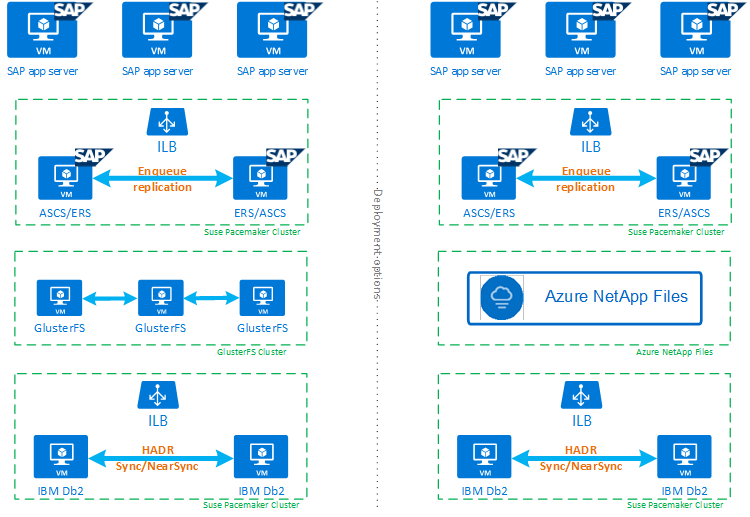
필요한 단계에 대한 대략적인 개요
IBM Db2 구성을 배포하려면 다음 단계를 수행해야 합니다.
- 환경을 계획합니다.
- VM을 배포합니다.
- RHEL Linux를 업데이트하고 파일 시스템을 구성합니다.
- Pacemaker를 설치하고 구성합니다.
- glusterfs 클러스터 또는 Azure NetApp Files를 설정합니다.
- 별도의 클러스터에 ASCS/ERS를 설치합니다.
- 분산형/고가용성 옵션(SWPM)을 사용하여 IBM Db2 데이터베이스를 설치합니다.
- 보조 데이터베이스 노드 및 인스턴스를 설치 및 생성하고 HADR을 구성합니다.
- HADR이 작동하는지 확인합니다.
- Pacemaker 구성을 적용하여 IBM Db2를 제어합니다.
- Azure Load Balancer를 구성합니다.
- 주 애플리케이션 서버 및 대화 애플리케이션 서버를 설치합니다.
- SAP 애플리케이션 서버의 구성을 확인하고 조정합니다.
- 장애 조치(failover) 및 인수 테스트를 수행합니다.
HADR이 포함된 IBM Db2 LUW를 호스트하기 위한 Azure 인프라 계획
배포를 실행하기 전에 계획 프로세스를 완료합니다. 계획을 통해 Azure에서 HADR이 포함된 Db2 구성을 배포하기 위한 토대를 구축합니다. IMB Db2 LUW(SAP 환경의 데이터베이스 부분) 계획에 포함해야 하는 주요 요소는 다음 표에 나와있습니다.
| 항목 | 간단한 설명 |
|---|---|
| Azure 리소스 그룹 정의 | VM, 가상 네트워크, Azure Load Balancer 및 기타 리소스를 배포하는 리소스 그룹입니다. 기존 그룹을 사용해도 되고 새로 만들어도 됩니다. |
| 가상 네트워크/서브넷 정의 | IBM Db2 및 Azure Load Balancer용 VM이 배포되는 위치입니다. 기존 위치를 사용해도 되고 새로 만들어도 됩니다. |
| IBM Db2 LUW를 호스트하는 가상 머신 | VM 크기, 스토리지, 네트워킹, IP 주소입니다. |
| IBM Db2 데이터베이스의 가상 호스트 이름 및 가상 IP | 가상 IP 또는 호스트 이름은 SAP 애플리케이션 서버 연결에 사용됩니다. db-virt-hostname, db-virt-ip. |
| Azure 펜싱 | 스플릿 브레인 상황을 피하는 메서드는 금지됩니다. |
| Azure Load Balancer | 표준(권장), Db2 데이터베이스용 프로브 포트(권장 62500) 프로브 포트를 사용합니다. |
| 이름 확인 | 환경에서 이름 확인이 작동하는 방식입니다. DNS 서비스가 적극 권장됩니다. 로컬 호스트 파일을 사용할 수 있습니다. |
Azure의 Linux Pacemaker에 대한 자세한 내용은 Azure의 Red Hat Enterprise Linux에서 Pacemaker 설정을 참조하세요.
Important
Db2 버전 11.5.6 이상의 경우 IBM의 Pacemaker를 사용하는 통합 솔루션을 사용하는 것이 좋습니다.
Red Hat Enterprise Linux에 배포
IBM Db2 LUW의 리소스 에이전트는 Red Hat Enterprise Linux Server HA 추가 항목에 포함되어 있습니다. 이 문서에서 설명하는 설치의 경우 Red Hat Enterprise Linux for SAP를 사용해야 합니다. Azure Marketplace에는 새 Azure 가상 머신을 배포하는 데 사용할 수 있는 Red Hat Enterprise Linux 7.4 for SAP 이상의 이미지가 포함되어 있습니다. Azure VM Marketplace에서 VM 이미지를 선택하는 경우, Azure Marketplace를 통해 Red Hat에서 제공하는 다양한 지원 또는 서비스 모델을 알고 있어야 합니다.
호스트: DNS 업데이트
호스트 이름 확인에 대한 적절한 IP 주소를 사용할 수 있도록 가상 호스트 이름을 포함한 모든 호스트 이름의 목록을 만들고 DNS 서버를 업데이트합니다. DNS 서버가 없거나 DNS 항목을 업데이트 및 생성할 수 없으면 이 시나리오에 참여하는 개별 VM의 로컬 호스트 파일을 사용해야 합니다. 호스트 파일 항목을 사용하는 경우에는 해당 항목이 SAP 시스템 환경의 모든 VM에 적용되는지 확인합니다. 그러나 이상적으로는 Azure로 확장되는 DNS를 사용하는 것이 좋습니다.
수동 배포
선택한 OS가 IBM Db2 LUW용 IBM/SAP에서 지원되는지 확인합니다. Azure VM 및 Db2 릴리스에 대해 지원되는 OS 버전 목록은 SAP노트 1928533에 제공됩니다. 개별 Db2 릴리스의 OS 릴리스 목록은 SAP 제품 가용성 매트릭스에서 확인할 수 있습니다. Red Hat Enterprise Linux 7.4 for SAP 이상을 적극 권장합니다. 이 이상의 Red Hat Enterprise Linux 버전에서 Azure 관련 성능이 향상되었기 때문입니다.
- 리소스 그룹을 만들거나 선택합니다.
- 가상 네트워크 및 서브넷을 만들거나 선택합니다.
- SAP 가상 머신에 적합한 배포 유형을 선택합니다. 일반적으로 유연한 오케스트레이션을 갖춘 가상 머신 확장 집합입니다.
- 가상 머신 1을 만듭니다.
- Azure Marketplace에서 Red Hat Enterprise Linux for SAP 이미지를 사용합니다.
- 3단계에서 만든 확장 집합, 가용성 영역 또는 가용성 집합을 선택합니다.
- 가상 머신 2를 만듭니다.
- Azure Marketplace에서 Red Hat Enterprise Linux for SAP 이미지를 사용합니다.
- 3단계에서 만든 확장 집합, 가용성 영역 또는 가용성 집합을 선택합니다(4단계와 동일한 영역 아님).
- VM에 데이터 디스크를 추가한 다음, SAP 워크로드용 IBM Db2 Azure Virtual Machines DBMS 배포 문서에서 파일 시스템 설정 권장 사항을 확인합니다.
IBM Db2 LUW 및 SAP 환경 설치
IBM Db2 LUW를 기반으로 SAP 환경 설치를 시작하기 전에 다음 문서를 검토하세요.
- Azure 설명서
- SAP 설명서.
- IBM 설명서.
이 설명서에 대한 링크는 이 문서의 서두에 제공됩니다.
IBM Db2 LUW에 NetWeaver 기반 애플리케이션을 설치하는 방법에 대한 SAP 설치 설명서를 확인하세요. SAP Installation Guide Finder를 사용하여 SAP 도움말 포털에서 가이드를 찾을 수 있습니다.
다음 필터를 설정하여 포털에 표시되는 가이드 수를 줄일 수 있습니다.
- I want to: 새 시스템을 설치합니다.
- My Database 필터에서 IBM Db2 for Linux, Unix 및 Windows를 선택합니다.
- SAP NetWeaver 버전, 스택 구성 또는 운영 체제에 대한 추가 필터를 설정합니다.
Red Hat 방화벽 규칙
Red Hat Enterprise Linux에는 기본적으로 방화벽을 사용하도록 설정되어 있습니다.
#Allow access to SWPM tool. Rule is not permanent.
sudo firewall-cmd --add-port=4237/tcp
HADR이 포함된 IBM Db2 LUW 설정에 대한 설치 힌트
주 IBM Db2 LUW 데이터베이스 인스턴스를 설정하려면 다음을 수행합니다.
- 고가용성 또는 분산 옵션을 사용합니다.
- SAP ASCS/ERS 및 데이터베이스 인스턴스를 설치합니다.
- 새로 설치된 데이터베이스를 백업합니다.
Important
설치 중에 설정된 "데이터베이스 통신 포트"를 적어 둡니다. 두 데이터베이스 인스턴스에 대해 동일한 포트 번호여야 합니다.
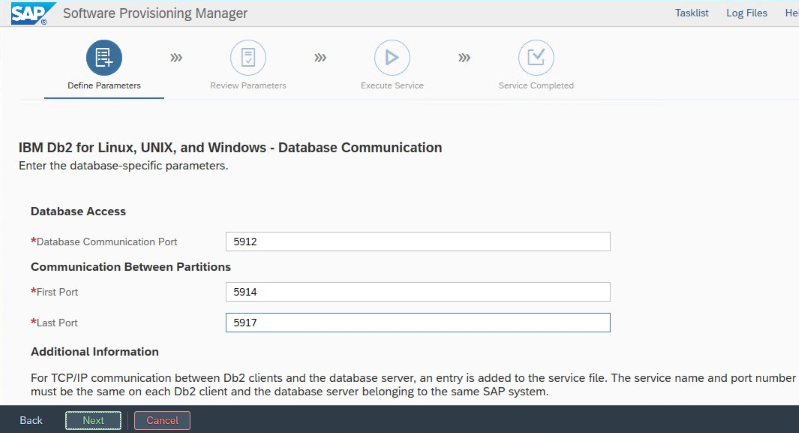
Azure에 대한 IBM Db2 HADR 설정
Azure Pacemaker 펜싱 에이전트를 사용하는 경우 다음 매개 변수를 설정합니다.
- HADR 피어 지속 시간(초)(HADR_PEER_WINDOW) = 240
- HADR 제한 시간 값(HADR_TIMEOUT) = 45
초기 장애 조치(failover)/인수 테스트에 따라 앞의 매개 변수를 사용하는 것이 좋습니다. 이러한 매개 변수 설정을 사용하여 장애 조치(failover) 및 인수의 적절한 기능을 테스트해야 합니다. 개별 구성은 다를 수 있으므로 매개 변수를 조정해야 할 수도 있습니다.
참고 항목
정상적인 시작 시 HADR 구성이 포함된 IBM Db2에만 해당: 주 데이터베이스 인스턴스를 시작하려면 먼저 보조 또는 대기 데이터베이스 인스턴스를 시작 및 실행 중이어야 합니다.
참고 항목
Azure 및 Pacemaker와 관련된 설치 및 구성의 경우: SAP Software Provisioning Manager를 통한 설치 과정 중에 IBM Db2 LUW의 고가용성에 대한 명시적인 질문이 있습니다.
- IBM Db2 pureScale을 선택하지 마세요.
- Install IBM Tivoli System Automation for Multiplatforms를 선택하지 마세요.
- Generate cluster configuration files(클러스터 구성 파일 생성)를 선택하지 마세요.
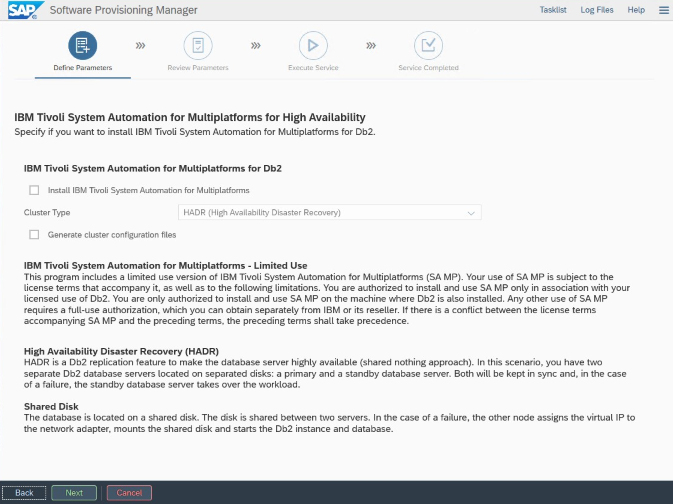
SAP 동종 시스템 복사 프로시저를 사용하여 대기 데이터베이스 서버를 설정하려면 다음 단계를 실행합니다.
- 시스템 복사 옵션 >대상 시스템>분산형>데이터베이스 인스턴스를 선택합니다.
- 복사 방법으로 Homogeneous System(동종 시스템)을 선택합니다. 그래야 백업을 사용하여 대기 서버 인스턴스에서 백업을 복원할 수 있습니다.
- 동종 시스템 복사를 위해 데이터베이스를 복원하는 종료 단계에 도달하면 설치 프로그램을 종료합니다. 주 호스트의 백업에서 데이터베이스를 복원합니다. 주 데이터베이스 서버에서 모든 후속 설치 단계가 이미 실행되었습니다.
DB2 HADR에 대한 Red Hat 방화벽 규칙
HADR이 작동하도록 DB2에 대한 트래픽 및 DB2 간 트래픽을 허용하는 방화벽 규칙을 추가합니다.
- 데이터베이스 통신 포트. 파티션을 사용하는 경우 해당 포트도 추가합니다.
- HADR 포트(DB2 매개 변수 HADR_LOCAL_SVC의 값).
- Azure 프로브 포트.
sudo firewall-cmd --add-port=<port>/tcp --permanent
sudo firewall-cmd --reload
IBM Db2 HADR 검사
이 문서에 설명된 절차 및 데모용 데이터베이스 SID는 ID2입니다.
HADR을 구성하고 주 노드 및 대기 노드의 상태가 PEER 및 CONNECTED이면 다음 검사를 수행합니다.
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
Database Member 0 -- Database ID2 -- Active -- Up 1 days 15:45:23 -- Date 2019-06-25-10.55.25.349375
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.076494 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 5
HEARTBEAT_EXPECTED = 52
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 5
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 369280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 132242668
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 300
PEER_WINDOW_END = 06/25/2019 11:12:03.000000 (1561461123)
READS_ON_STANDBY_ENABLED = N
#Secondary output:
Database Member 0 -- Database ID2 -- Standby -- Up 1 days 15:45:18 -- Date 2019-06-25-10.56.19.820474
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.078116 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 10
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 367360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 1000
PEER_WINDOW_END = 06/25/2019 11:12:59.000000 (1561461179)
READS_ON_STANDBY_ENABLED = N
Azure Load Balancer 구성
VM 구성 중에 네트워킹 섹션에서 기존 부하 분산 장치를 만들거나 선택할 수 있는 옵션이 있습니다. DB2 데이터베이스의 고가용성 설정을 위해 표준 Load Balancer를 설정하려면 아래 단계를 따릅니다.
Azure Portal을 사용하여 고가용성 SAP 시스템에 대한 표준 부하 분산 장치를 설정하려면 부하 분산 장치 만들기의 단계를 따릅니다. 부하 분산 장치를 설정하는 동안 다음 사항을 고려합니다.
- 프런트 엔드 IP 구성: 프런트 엔드 IP를 만듭니다. 데이터베이스 가상 머신과 동일한 가상 네트워크 및 서브넷 이름을 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 만들고 데이터베이스 VM을 추가합니다.
- 인바운드 규칙: 부하 분산 규칙을 만듭니다. 두 부하 분산 규칙에 대해 동일한 단계를 수행합니다.
- 프런트 엔드 IP 주소: 프런트 엔드 IP를 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 선택합니다.
- 고가용성 포트: 이 옵션을 선택합니다.
- 프로토콜: TCP를 선택합니다.
- 상태 프로브: 다음 세부 정보를 사용하여 상태 프로브를 만듭니다.
- 프로토콜: TCP를 선택합니다.
- 포트: 예를 들어 인스턴스 가 625<개입니다>.
- 간격: 5를 입력 합니다.
- 프로브 임계값: 2를 입력합니다.
- 유휴 시간 제한(분): 30을 입력합니다.
- 부동 IP 사용: 이 옵션을 선택합니다.
참고 항목
포털에서 비정상 임계값이라고도 하는 상태 프로브 구성 속성numberOfProbes은 적용되지 않습니다. 성공 또는 실패한 연속 프로브 수를 제어하려면 속성을 probeThreshold2.로 설정합니다. 현재 Azure Portal을 사용하여 이 속성을 설정할 수 없으므로 Azure CLI 또는 PowerShell 명령을 사용합니다.
Important
부동 IP는 부하 분산 시나리오의 NIC 보조 IP 구성에서 지원되지 않습니다. 자세한 내용은 Azure Load Balancer 제한 사항을 참조하세요. VM에 다른 IP 주소가 필요한 경우 두 번째 NIC를 배포합니다.
참고 항목
공용 IP 주소가 없는 VM이 표준 Azure Load Balancer의 내부(공용 IP 주소 없음) 인스턴스의 백 엔드 풀에 배치되면 공용 엔드포인트로의 라우팅을 허용하도록 추가 구성이 수행되지 않는 한 아웃바운드 인터넷 연결이 이루어지지 않습니다. 아웃바운드 연결을 달성하는 방법에 대한 자세한 내용은 SAP 고가용성 시나리오에서 Azure 표준 Load Balancer를 사용하는 VM에 대한 공용 엔드포인트 연결을 참조하세요.
Important
Azure Load Balancer 뒤에 배치되는 Azure VM에서 TCP 타임스탬프를 사용하도록 설정하면 안 됩니다. TCP 타임스탬프를 사용하도록 설정하면 상태 프로브가 실패할 수 있습니다. net.ipv4.tcp_timestamps 매개 변수를 0으로 설정합니다. 자세한 내용은 부하 분산 장치 상태 프로브를 참조하세요.
[A] 프로브 포트에 대한 방화벽 규칙 추가:
sudo firewall-cmd --add-port=<probe-port>/tcp --permanent
sudo firewall-cmd --reload
Pacemaker 클러스터 만들기
이 IBM Db2 서버에 대한 기본 Pacemaker 클러스터를 만들려면 Azure의 Red Hat Enterprise Linux에서 Pacemaker 설정을 참조하세요.
Db2 Pacemaker 구성
노드 오류가 발생할 경우 자동 장애 조치(failover)에 Pacemaker를 사용하는 경우 Db2 인스턴스와 Pacemaker를 적절히 구성해야 합니다. 이 섹션에서는 이러한 유형의 구성에 대해 설명합니다.
항목에는 다음 중 한 가지 접두사가 추가됩니다.
- [A]: 모든 노드에 적용 가능
- [1]: 노드 1에만 적용 가능
- [2]: 노드 2에만 적용 가능
[A] Pacemaker 구성의 선행 조건:
사용자 db2<sid>로 db2stop을 사용하여 두 데이터베이스 서버를 종료합니다.
db2<sid> 사용자의 셸 환경을 /bin/ksh로 변경합니다.
# Install korn shell: sudo yum install ksh # Change users shell: sudo usermod -s /bin/ksh db2<sid>
Pacemaker 구성
[1] IBM Db2 HADR 관련 Pacemaker 구성:
# Put Pacemaker into maintenance mode sudo pcs property set maintenance-mode=true[1] IBM Db2 리소스 만들기:
RHEL 7.x에서 클러스터를 빌드하는 경우 패키지 리소스-에이전트를 버전
resource-agents-4.1.1-61.el7_9.15이상으로 업데이트해야 합니다. 다음 명령을 사용하여 클러스터 리소스를 만듭니다.# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' master meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-master meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-master #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-master then g_ipnc_db2id2_ID2RHEL 8.x에서 클러스터를 빌드하는 경우 패키지 리소스-에이전트를 버전
resource-agents-4.1.1-93.el8이상으로 업데이트해야 합니다. 자세한 내용은 Red Hat KBA HADR이 있는db2리소스가 상태PRIMARY/REMOTE_CATCHUP_PENDING/CONNECTED로 승격에 실패를 참조하세요. 다음 명령을 사용하여 클러스터 리소스를 만듭니다.# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' promotable meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-clone meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-clone #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-clone then g_ipnc_db2id2_ID2[1] IBM Db2 리소스 시작:
Pacemaker를 유지 관리 모드에서 해제합니다.
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo pcs property set maintenance-mode=false[1] 클러스터 상태가 정상이며 모든 리소스가 시작되었는지 확인합니다. 리소스가 어떤 노드에서 실행되는지는 중요하지 않습니다.
sudo pcs status 2 nodes configured 5 resources configured Online: [ az-idb01 az-idb02 ] Full list of resources: rsc_st_azure (stonith:fence_azure_arm): Started az-idb01 Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2] Masters: [ az-idb01 ] Slaves: [ az-idb02 ] Resource Group: g_ipnc_db2id2_ID2 vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01 nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Important
Pacemaker 클러스터형 Db2 인스턴스는 Pacemaker 도구를 사용하여 관리해야 합니다. db2stop과 같은 db2 명령을 사용하면 Pacemaker는 해당 동작을 리소스 실패로 감지합니다. 유지 관리를 수행하는 경우 노드 또는 리소스를 유지 관리 모드로 전환할 수 있습니다. Pacemaker가 모니터링 리소스를 일시 중단한 다음, 일반 db2 관리 명령을 사용할 수 있습니다.
연결에 가상 IP를 사용하도록 SAP 프로필 변경
HADR 구성의 주 인스턴스에 연결하려면 Azure Load Balancer에 대해 정의하고 구성한 가상 IP 주소가 SAP 애플리케이션 계층에 사용되어야 합니다. 다음과 같은 변경이 필요합니다.
/sapmnt/<SID>/profile/DEFAULT.PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/<SID>/global/db6/db2cli.ini
Hostname=db-virt-hostname
주 애플리케이션 서버 및 대화 애플리케이션 서버 설치
Db2 HADR 구성에 대해 주 애플리케이션 서버 및 대화 애플리케이션 서버를 설치할 때는 구성에 대해 선택한 가상 호스트 이름을 사용합니다.
Db2 HADR 구성을 만들기 전에 설치를 수행한 경우 이전 섹션에서 설명한 대로 변경하고 SAP Java 스택의 경우 다음과 같이 변경합니다.
ABAP+Java 또는 Java 스택 시스템 JDBC URL 확인
J2EE Config 도구를 사용하여 JDBC URL을 확인하거나 업데이트합니다. J2EE Config 도구는 그래픽 도구이므로 X 서버가 설치되어 있어야 합니다.
J2EE 인스턴스의 주 애플리케이션 서버에 로그인하고 다음을 실행합니다.
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.sh왼쪽 프레임에서 보안 저장소를 선택합니다.
오른쪽 프레임에서 키
jdbc/pool/\<SAPSID>/url을 선택합니다.JDBC URL의 호스트 이름을 가상 호스트 이름으로 변경합니다.
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0추가를 선택합니다.
변경 내용을 저장하려면 왼쪽 위에서 디스크 아이콘을 선택합니다.
구성 도구를 닫습니다.
Java 인스턴스를 다시 시작합니다.
HADR 설정에 대한 로그 보관 구성
HADR 설정에 대한 Db2 로그 보관을 구성하려면 주 데이터베이스와 대기 데이터베이스가 모든 로그 보관 위치에서 자동 로그 검색 기능을 갖추도록 구성하는 것이 좋습니다. 주 데이터베이스와 대기 데이터베이스는 각각의 데이터베이스 인스턴스가 로그 파일을 보관할 수 있는 모든 로그 보관 위치에서 로그 보관 파일을 검색할 수 있어야 합니다.
로그 보관은 주 데이터베이스에서만 수행됩니다. 데이터베이스 서버의 HADR 역할을 변경하거나 오류가 발생하면 새로운 주 데이터베이스가 로그 보관을 담당합니다. 여러 로그 보관 위치를 설정하면 로그가 두 번 보관될 수 있습니다. 로컬 또는 원격 보완의 경우 보관된 로그를 이전 주 서버에서 새로운 주 서버의 활성 로그 위치로 수동으로 복사해야 할 수도 있습니다.
두 노드에서 로그가 기록되는 공통 NFS 공유 또는 GlusterFS를 구성하는 것이 좋습니다. NFS 공유 또는 GlusterFS는 고가용성이어야 합니다.
기존의 고가용성 NFS 공유 또는 GlusterFS를 전송 또는 프로필 디렉토리에 사용할 수 있습니다. 자세한 내용은 다음을 참조하세요.
- SAP NetWeaver에 대한 Red Hat Enterprise Linux에 있는 Azure VM의 GlusterFS.
- SAP 애플리케이션용 Azure NetApp Files를 사용하여 Red Hat Enterprise Linux에서 Azure VM의 SAP NetWeaver 고가용성 실현.
- Azure NetApp Files(NFS 공유 만들기)
클러스터 설정 테스트
이 섹션에서는 Db2 HADR 설정을 테스트하는 방법을 설명합니다. 모든 테스트는 az-idb01 가상 머신에서 IBM Db2 주 데이터베이스가 실행되고 있다고 가정합니다. 루트(권장하지 않음) 또는 sudo 권한이 있는 사용자를 사용해야 합니다.
모든 테스트 사례의 초기 상태는 (crm_mon -r 또는 pcs status)에 설명되어 있습니다.
- pcs status는 실행 시 Pacemaker 상태의 스냅샷입니다.
- crm_mon -r은 Pacemaker 상태의 지속적인 출력입니다.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
SAP 시스템의 원래 상태는 트랜잭션 DBACOCKPIT > 구성 > 개요에 다음 이미지와 같이 문서화되어 있습니다.
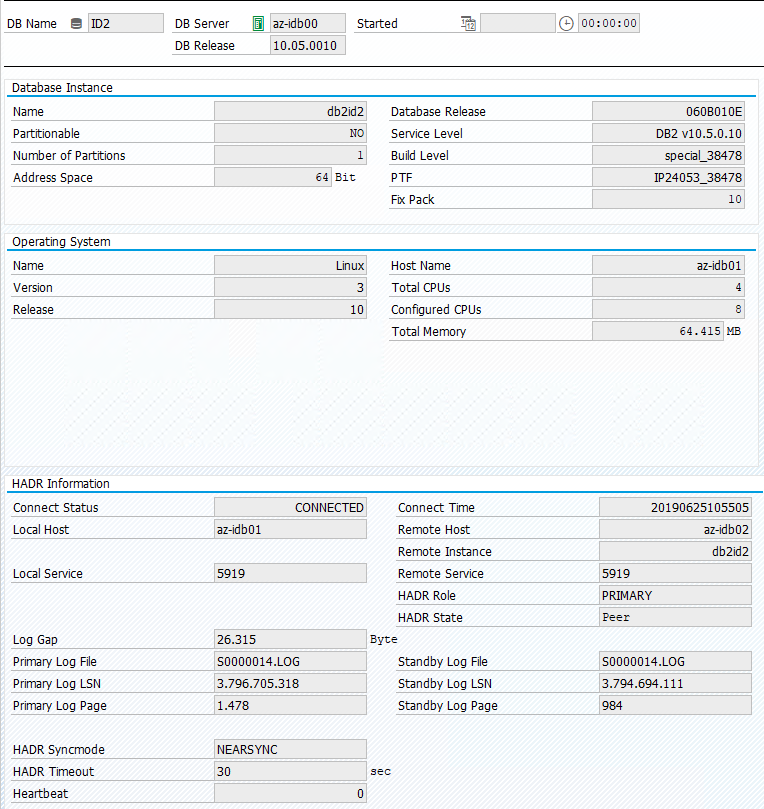
IBM Db2의 인수 테스트
Important
테스트를 시작하기 전에 다음을 확인해야 합니다.
Pacemaker에는 실패한 작업(pcs status)이 없습니다.
위치 제약 조건이 없습니다(마이그레이션 테스트의 나머지).
IBM Db2 HADR 동기화가 작동합니다. 사용자 db2<sid>를 확인합니다.
db2pd -hadr -db <DBSID>
다음 명령을 실행하여 기본 Db2 데이터베이스를 실행하는 노드를 마이그레이션합니다.
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
마이그레이션이 완료되면 crm 상태 출력은 다음과 같습니다.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
SAP 시스템의 원래 상태는 트랜잭션 DBACOCKPIT > 구성 > 개요에 다음 이미지와 같이 문서화되어 있습니다.
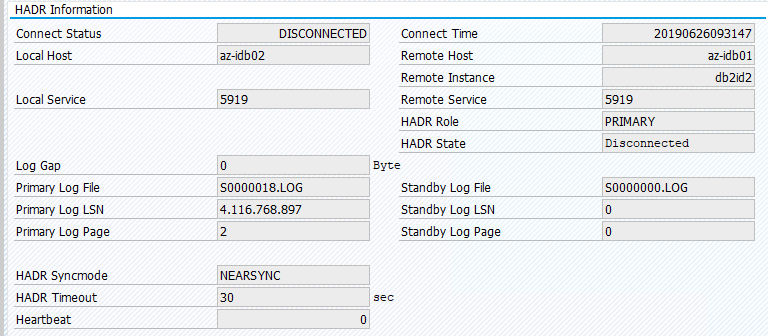
"pcs resource move"를 사용한 리소스 마이그레이션은 위치 제약 조건을 만듭니다. 이 경우 위치 제약 조건으로 인해 az-idb01에서 IBM Db2 인스턴스를 실행하지 못합니다. 위치 제약 조건이 삭제되지 않으면 리소스가 장애 복구될 수 없습니다.
위치 제약 조건을 제거하면 대기 노드가 az-idb01에서 시작됩니다.
# On RHEL 7.x
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource clear Db2_HADR_ID2-clone
그리고 클러스터 상태는 다음과 같이 변경됩니다.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
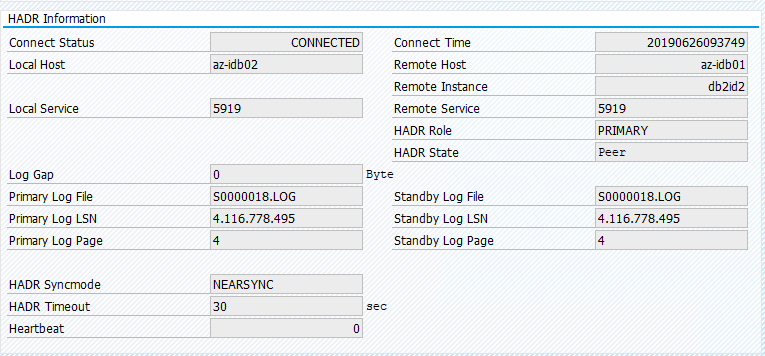
리소스를 az-idb01로 다시 마이그레이션하고 위치 제약 조건을 지웁니다.
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master az-idb01
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
sudo pcs resource clear Db2_HADR_ID2-clone
- RHEL 7.x -
pcs resource move <resource_name> <host>: 위치 제약 조건을 만들고 인수 문제를 일으킬 수 있습니다. - RHEL 8.x -
pcs resource move <resource_name> --master: 위치 제약 조건을 만들고 인수 문제를 일으킬 수 있습니다. pcs resource clear <resource_name>: 위치 제약 조건 지우기pcs resource cleanup <resource_name>: 리소스의 모든 오류 지우기
수동 인수 테스트
az-idb01 노드에서 Pacemaker 서비스를 중지하여 수동 인수를 테스트할 수 있습니다.
systemctl stop pacemaker
az-ibdb02의 상태
2 nodes configured
5 resources configured
Node az-idb01: pending
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
장애 조치(failover) 후 az-idb01에서 서비스를 다시 시작할 수 있습니다.
systemctl start pacemaker
HADR 주 데이터베이스를 실행하는 노드에서 Db2 프로세스 종료
#Kill main db2 process - db2sysc
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 34598
Db2 인스턴스가 실패하고 Pacemaker가 마스터 노드를 이동하고 다음 상태를 보고합니다.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=49, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 09:57:35 2019', queued=0ms, exec=362ms
Pacemaker는 동일한 노드에서 Db2 주 데이터베이스 인스턴스를 다시 시작하거나 보조 데이터베이스 인스턴스를 실행하는 노드로 장애 조치(failover)되고 오류가 보고됩니다.
보조 데이터베이스 인스턴스를 실행하는 노드에서 Db2 프로세스 종료
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2id2 23144 23142 2 09:53 ? 00:00:13 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 23144
노드가 실패한 상태가 되고 오류가 보고됩니다.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Failed Actions:
* Db2_HADR_ID2_monitor_20000 on az-idb02 'not running' (7): call=144, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 10:02:09 2019', queued=0ms, exec=0ms
Db2 인스턴스는 이전에 할당한 보조 역할에서 다시 시작됩니다.
HADR 주 데이터베이스 인스턴스를 실행하는 노드에서 db2stop force를 통해 DB 중지
사용자 db2<sid>로 db2stop force 명령을 실행합니다.
az-idb01:db2ptr> db2stop force
검색된 오류:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Slaves: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Stopped
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Stopped
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Db2 HADR 보조 데이터베이스 인스턴스가 주 역할로 승격되었습니다.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
"halt"로 인해 HADR 주 데이터베이스 인스턴스를 실행하는 VM 작동 중단
#Linux kernel panic.
sudo echo b > /proc/sysrq-trigger
이러한 경우 Pacemaker는 주 데이터베이스 인스턴스를 실행하는 노드가 응답하지 않음을 검색합니다.
2 nodes configured
5 resources configured
Node az-idb01: UNCLEAN (online)
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
다음 단계는 스플릿 브레인(Split brain) 상황을 확인하는 것입니다. 주 데이터베이스 인스턴스를 마지막으로 실행한 노드가 중단된 것이 생존 노드에서 확인되면 리소스에 대한 장애 조치(failover)가 실행됩니다.
2 nodes configured
5 resources configured
Online: [ az-idb02 ]
OFFLINE: [ az-idb01 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
커널 패닉이 발생하면 실패한 노드는 펜싱 에이전트에 의해 다시 시작됩니다. 실패한 노드가 다시 온라인 상태가 되면 다음을 실행하여 Pacemaker 클러스터를 시작해야 합니다.
sudo pcs cluster start
Db2 인스턴스를 보조 역할로 시작합니다.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02