Microsoft Fabric의 Apache Spark에 대한 청구 및 사용률 보고
적용 대상:✅ Microsoft Fabric에서 데이터 엔지니어 및 데이터 과학
이 문서에서는 Microsoft Fabric에서 Synapse 데이터 엔지니어 및 Science 워크로드를 구동하는 ApacheSpark에 대한 컴퓨팅 사용률 및 보고에 대해 설명합니다. 컴퓨팅 사용률에는 테이블 미리 보기, 델타로 로드, 인터페이스에서 Notebook 실행, 예약된 실행, 파이프라인의 Notebook 단계에 의해 트리거되는 실행 및 Apache Spark 작업 정의 실행과 같은 Lakehouse 작업이 포함됩니다.
Microsoft Fabric의 다른 환경과 마찬가지로 데이터 엔지니어 작업 영역과 연결된 용량을 사용하여 이러한 작업을 실행하고 전체 용량 요금이 Microsoft Cost Management 구독의 Azure Portal에 표시됩니다. 패브릭 청구에 대한 자세한 내용은 패브릭 용량에 대한 Azure 청구서 이해를 참조 하세요.
패브릭 용량
사용자는 Azure 구독을 사용하여 지정하여 Azure에서 패브릭 용량을 구매할 수 있습니다. 용량의 크기는 사용 가능한 계산 능력의 양을 결정합니다. 패브릭용 Apache Spark의 경우 구매한 모든 CU는 2개의 Apache Spark VCore로 변환됩니다. 예를 들어 패브릭 용량 F128을 구매하면 256 SparkVCore로 변환됩니다. 패브릭 용량은 추가된 모든 작업 영역에서 공유되며, 허용되는 총 Apache Spark 컴퓨팅은 용량에 연결된 모든 작업 영역에서 제출된 모든 작업에서 공유됩니다. Spark에서 다양한 SKU, 코어 할당 및 제한에 대해 이해하려면 Microsoft Fabric용 Apache Spark의 동시성 제한 및 큐를 참조하세요.
Spark 컴퓨팅 구성 및 구매한 용량
패브릭용 Apache Spark 컴퓨팅은 컴퓨팅 구성과 관련하여 두 가지 옵션을 제공합니다.
시작 풀: 이러한 기본 풀은 몇 초 내에 Microsoft Fabric 플랫폼에서 Spark를 빠르고 쉽게 사용할 수 있는 방법입니다. Spark가 노드를 설정할 때까지 기다리지 않고 바로 Spark 세션을 사용할 수 있으므로 데이터를 사용하여 더 많은 작업을 수행하고 인사이트를 더 빠르게 얻을 수 있습니다. 청구 및 용량 사용과 관련하여 Notebook 또는 Spark 작업 정의 또는 Lakehouse 작업을 실행하기 시작하면 요금이 청구됩니다. 클러스터가 풀에서 유휴 상태인 시간에 대해서는 요금이 청구되지 않습니다.
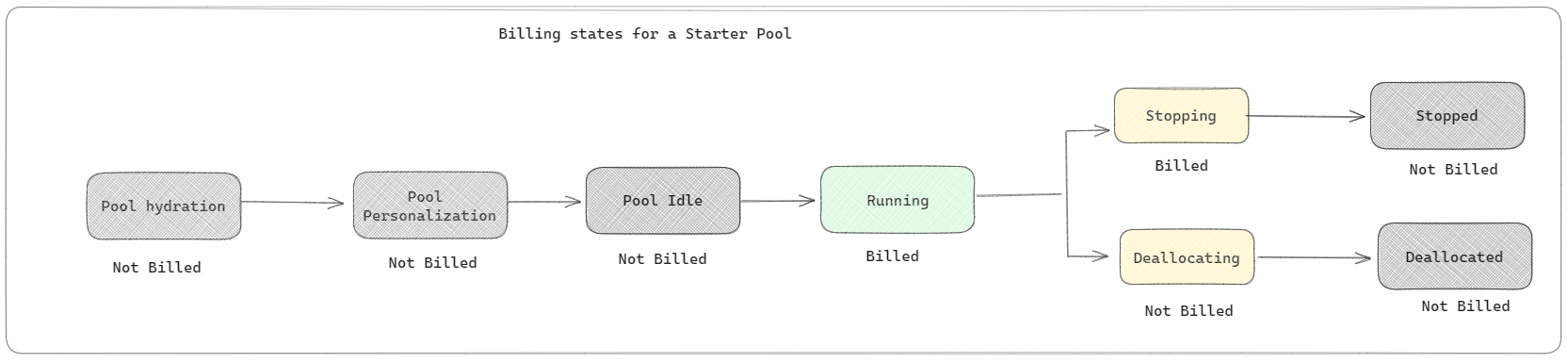
예를 들어 시작 풀에 Notebook 작업을 제출하는 경우 Notebook 세션이 활성 상태인 기간 동안만 요금이 청구됩니다. 청구된 시간에는 Spark 컨텍스트를 사용하여 세션을 개인 설정하는 데 걸린 유휴 시간 또는 시간이 포함되지 않습니다. 구매한 패브릭 용량 SKU를 기반으로 스타터 풀을 구성하는 방법에 대해 자세히 알아보려면 패브릭 용량에 따라 시작 풀 구성을 방문 하세요.
Spark 풀: 데이터 분석 작업에 필요한 리소스 크기를 사용자 지정할 수 있는 사용자 지정 풀입니다. Spark 풀에 이름을 지정하고 노드의 수와 크기(작업을 수행하는 컴퓨터)를 선택할 수 있습니다. 작업량에 따라 노드 수를 조정하는 방법을 Spark에 알릴 수도 있습니다. Spark 풀 만들기는 무료입니다. 풀에서 Spark 작업을 실행한 다음 Spark에서 노드를 설정하는 경우에만 비용을 지불합니다.
- 사용자 지정 Spark 풀에 포함할 수 있는 노드의 크기와 수는 Microsoft Fabric 용량에 따라 달라집니다. 총 Spark VCore 수가 128을 초과하지 않는 한 이러한 Spark VCore를 사용하여 사용자 지정 Spark 풀에 대해 서로 다른 크기의 노드를 만들 수 있습니다.
- Spark 풀은 시작 풀과 같이 요금이 청구됩니다. Notebook 또는 Spark 작업 정의를 실행하기 위해 만든 활성 Spark 세션이 없으면 만든 사용자 지정 Spark 풀에 대한 비용을 지불하지 않습니다. 작업 실행 기간에 대해서만 요금이 청구됩니다. 작업이 완료된 후 클러스터 만들기 및 할당 취소와 같은 단계에 대해서는 요금이 청구되지 않습니다.
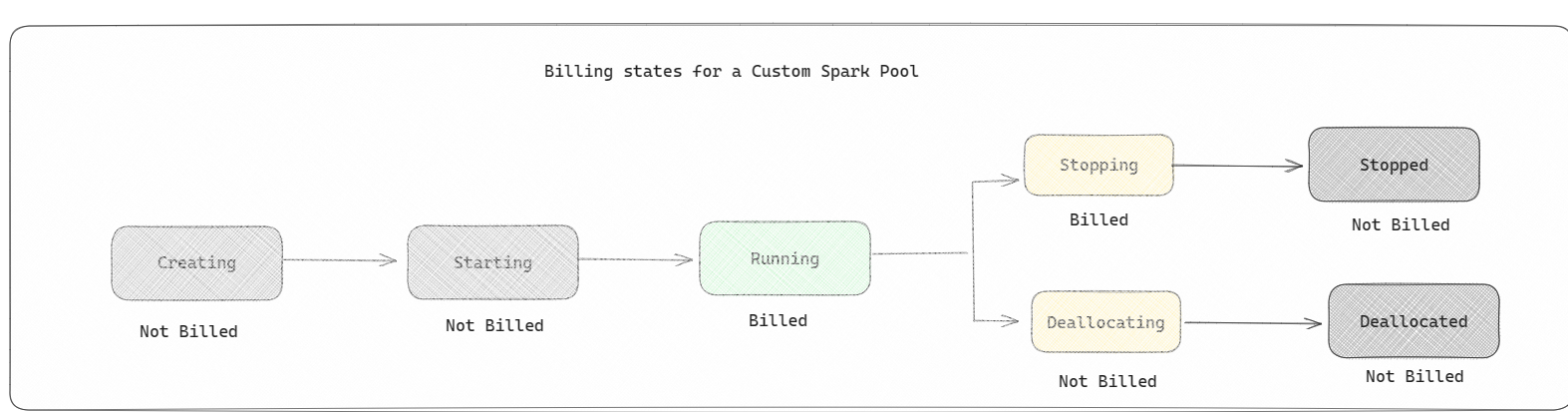
예를 들어 사용자 지정 Spark 풀에 Notebook 작업을 제출하는 경우 세션이 활성화된 기간 동안만 요금이 청구됩니다. Spark 세션이 중지되거나 만료되면 해당 Notebook 세션에 대한 청구가 중지됩니다. 클라우드에서 클러스터 인스턴스를 획득하는 데 걸린 시간 또는 Spark 컨텍스트를 초기화하는 데 걸린 시간에 대해서는 요금이 부과되지 않습니다. 구매한 패브릭 용량 SKU를 기반으로 Spark 풀을 구성하는 방법에 대해 자세히 알아보려면 패브릭 용량을 기반으로 풀 구성을 참조 하세요.


참고 항목
만든 시작 풀 및 Spark 풀의 기본 세션 만료 기간은 20분으로 설정됩니다. 세션이 만료된 후 2분 동안 Spark 풀을 사용하지 않으면 Spark 풀의 할당이 취소됩니다. 세션 만료 기간 전에 Notebook 실행을 완료한 후 세션 및 청구를 중지하려면 Notebook 홈 메뉴에서 세션 중지 단추를 클릭하거나 모니터링 허브 페이지로 이동하여 해당 위치에서 세션을 중지할 수 있습니다.
Spark 컴퓨팅 사용 현황 보고
Microsoft Fabric 용량 메트릭 앱은 한 곳에서 모든 패브릭 워크로드의 용량 사용량을 확인할 수 있습니다. 용량 관리자는 구매한 용량에 비해 워크로드의 성능과 사용량을 모니터링하는 데 사용됩니다.
앱을 설치한 후 항목 종류 선택 드롭다운 목록에서 Notebook, Lakehouse, Spark 작업 정의 항목 유형을 선택합니다. 이제 다중 메트릭 리본 차트 차트를 원하는 기간으로 조정하여 선택한 모든 항목의 사용량을 파악할 수 있습니다.
모든 Spark 관련 작업은 백그라운드 작업으로 분류됩니다. Spark의 용량 사용량은 Notebook, Spark 작업 정의 또는 레이크하우스 아래에 표시되며 작업 이름 및 항목별로 집계됩니다. 예를 들어 Notebook 작업을 실행하는 경우 Notebook 실행, Notebook에서 사용하는 CU(총 Spark VCore/2에서 1 CU는 2개의 Spark VCore 제공), 보고서에서 작업을 수행한 기간을 확인할 수 있습니다.
 Spark 용량 사용 현황 보고에 대한 자세한 내용은 Apache Spark 용량 사용량 모니터링을 참조 하세요.
Spark 용량 사용 현황 보고에 대한 자세한 내용은 Apache Spark 용량 사용량 모니터링을 참조 하세요.
청구 예제
다음 시나리오를 살펴 보십시오.
Fabric 작업 영역 W1을 호스트하는 용량 C1이 있으며 이 작업 영역에는 Lakehouse LH1 및 Notebook NB1이 포함되어 있습니다.
- Notebook(NB1) 또는 Lakehouse(LH1)가 수행하는 모든 Spark 작업은 용량 C1에 대해 보고됩니다.
이 예제를 패브릭 작업 영역 W2를 호스트하고 이 작업 영역에 Spark 작업 정의(SJD1) 및 Lakehouse(LH2)가 포함되어 있다고 말하는 다른 용량 C2가 있는 시나리오로 확장합니다.
- W2(작업 영역)의 SDJ2(Spark 작업 정의)가 LH1(Lakehouse)에서 데이터를 읽는 경우 항목을 호스팅하는 작업 영역(W2)과 연결된 용량 C2에 대해 사용량이 보고됩니다.
- Notebook(NB1)이 Lakehouse(LH2)에서 읽기 작업을 수행하는 경우 용량 사용량은 Notebook 항목을 호스트하는 작업 영역 W1에 전원을 공급하는 용량 C1에 대해 보고됩니다.