이 문서에서는 Azure SQL Database를 참조로 사용하여 SQL 데이터베이스 원본으로 복사 작업 최적화하는 데 도움이 되는 기술에 대해 설명합니다. 데이터 전송 속도, 비용, 모니터링, 개발 용이성 및 최상의 결과를 위해 이러한 다양한 고려 사항의 균형을 맞추는 등 최적화의 다양한 측면을 다룹니다.
복사 작업 옵션
참고
이 문서에 포함된 메트릭은 다양한 기능에서 동작을 비교하고 대조하는 테스트 사례의 결과이며 공식적인 엔지니어링 벤치마크가 아닙니다. 모든 테스트 사례는 미국 동부 2에서 미국 서부 2 지역으로 데이터를 이동하고 있습니다.
파이프라인 복사 작업으로 시작하는 경우 개발을 시작하기 전에 원본 및 대상 시스템을 이해하는 것이 중요합니다. 최적화 대상을 명시하고 원본, 대상 및 파이프라인을 모니터링하여 최상의 리소스 사용률, 성능 및 소비를 달성하는 방법을 이해해야 합니다.
Azure SQL Database에서 소싱하는 경우 다음을 이해하는 것이 중요합니다.
- IOPS(초당 입출력 작업 수).
- 데이터 볼륨
- 하나 이상의 테이블 데이터 정의 언어 (DDL)
- 스키마 분할
- 데이터 분포가 좋은 기본 키 또는 기타 열(편향)
- 동시 연결 수와 같이 할당된 컴퓨팅 및 관련 제한 사항
귀하의 목적지도 마찬가지입니다. 둘 다 이해하면 우선 순위에 맞게 최적화하면서 원본과 대상의 범위 및 제한 내에서 작동하도록 파이프라인을 디자인할 수 있습니다.
참고
원본과 대상 간의 네트워크 대역폭과 각 IOP(초당 입력/출력)는 모두 처리량에 병목 현상이 발생할 수 있으며 이러한 경계를 이해하는 것이 좋습니다. 그러나 네트워킹은 이 문서의 범위 내에 있지 않습니다.
원본과 대상을 모두 이해하면 복사 작업 다양한 옵션을 사용하여 우선 순위에 대한 성능을 향상시킬 수 있습니다. 이러한 옵션에는 다음이 포함될 수 있습니다.
- 원본 분할 옵션 - 없음, 실제 파티션, 동적 범위
- 원본 격리 수준 - 없음, 커밋되지 않은 읽기, 커밋된 읽기, 스냅샷
- 지능형 처리량 최적화 설정 - 자동, 표준, 균형, 최대치
- 복사 병렬 처리 설정 수준 - 자동, 지정된 값
- 논리 분할 - 여러 동시 복사 작업을 생성하는 파이프라인 디자인
원본 세부 정보: Azure SQL Database
구체적인 예제를 제공하기 위해 Azure SQL Database에서 Fabric Lakehouse(테이블) 및 Fabric Warehouse 테이블로 데이터를 이동하는 여러 시나리오를 테스트했습니다. 이 예제에서는 4개의 원본 테이블을 테스트했습니다. 모두 스키마와 레코드 수가 동일합니다. 하나는 힙을 사용하고, 두 번째는 클러스터형 인덱스를 사용하고, 세 번째와 네 번째는 각각 8개와 85개의 파티션을 사용합니다. 이 예제에서는 Microsoft Fabric(미국 서부 2)에서 평가판 용량(F64)을 사용했습니다.
- 서비스 계층: 일반 목적
- 컴퓨팅 계층: 서버리스
- 하드웨어 구성: 표준 시리즈(Gen5)
- 최대 vCore 수: 80
- 최소 vCore 수: 20
- 레코드 수: 1,500,000,000
- 지역: 미국 동부 2
기본 평가
원본 파티션 옵션을 설정하기 전에 복사 작업 기본 동작을 이해하는 것이 중요합니다.
기본 설정은 다음과 같습니다.
출처
- 파티션 옵션 - 없음
- 격리 수준 - 없음
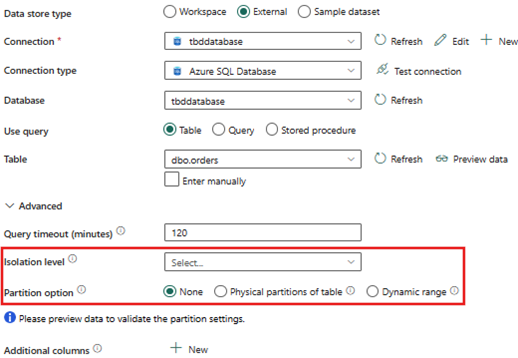
고급 설정
- 지능형 처리량 최적화 - 자동
- 복사 병렬 처리 수준 - 자동
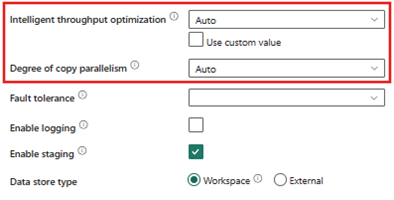


향후 비교를 위해 초기 벤치마크를 설정하기 위해 각 대상에 15억 개의 레코드를 로드하고 복사 작업당 2시간이 조금 넘게 걸린 복사 작업 실행에 대한 기본 설정을 사용했습니다.
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 |
|---|---|---|---|---|
| 직물 창고 | None | 자동 | 1 | 02:23:21 |
| 패브릭 레이크하우스 | None | 자동 | 1 | 02:10:37 |
이 문서에서는 총 기간에 집중합니다. 총 기간은 큐, 사전 스크립트 및 전송 기간과 같은 다른 단계를 포함합니다. 이러한 단계에 대한 자세한 내용은 복사 작업 실행 세부 정보를 참조하세요. 원본으로 Azure SQL Database의 복사 작업 속성에 대한 광범위한 개요는 복사 작업 대한 Azure SQL Database 원본 속성을 참조하세요.
설정
ITO(지능형 처리량 최적화)
ITO는 작업에서 사용할 수 있는 CPU, 메모리 및 네트워크 리소스 할당의 최대 양을 결정합니다. ITO를 최대값(또는 256)으로 설정하면 서비스는 가장 최적화된 처리량을 제공하는 가장 높은 값을 선택합니다. 이 문서에서는 서비스에서 필요한 것만 사용하고 실제 값이 256보다 낮지만 모든 테스트 사례에서 ITO를 최대값으로 설정합니다.
ITO에 대한 자세한 내용은 지능형 처리량 최적화를 참조하세요.
참고
복사 작업 싱크가 Fabric Warehouse인 경우 스테이징이 필요합니다. 복사 병렬 처리 수준 및 지능형 처리량 최적화와 같은 옵션은 원본에서 스테이징으로의 경우에만 적용됩니다. Lakehouse에 대한 테스트 사례는 스테이징을 사용하도록 설정하지 않았습니다.
파티션 옵션
원본이 Azure SQL 데이터베이스와 같은 관계형 데이터베이스인 경우 고급 섹션에서 파티션 옵션을 지정할 수 있습니다. 기본적으로 이 설정은 테이블의 실제 파티션과 동적 범위의 두 가지 다른 옵션을 사용하여 없음으로 설정됩니다.
동적 범위
힙 테이블
동적 범위를 사용하면 서비스에서 원본에 대한 쿼리를 지능적으로 생성할 수 있습니다. 생성된 쿼리 수는 런타임에 선택한 서비스를 사용한 병렬 복사본의 수와 같습니다. 동적 범위 파티션 옵션의 사용을 최적화할 때는 복사 병렬 처리 수준과 사용된 병렬 복사본을 고려해야 합니다.
파티션 범위
파티션 상한 및 하한은 파티션 진행을 지정할 수 있는 선택적 필드입니다. 이러한 테스트 사례에서는 상한과 하한을 모두 미리 정의했습니다. 이러한 필드를 지정하지 않으면 시스템에서 원본을 쿼리하여 범위를 확인하는 데 추가 오버헤드가 발생합니다. 최적의 성능을 위해, 특히 일회성 기록 로드의 경우 경계를 미리 가져옵니다.
자세한 내용은 Azure SQL Database 커넥터 문서의 SQL Database의 병렬 복사본 섹션에 있는 테이블을 참조하세요.
다음 SQL 쿼리는 범위 최소 및 최대값을 결정합니다.

그런 다음 동적 범위 구성에서 이러한 세부 정보를 제공합니다.

다음은 동적 범위를 사용하여 복사 작업 생성한 예제 쿼리입니다.
SELECT * FROM [dbo].[orders] WHERE [o_orderkey] > '4617187501' AND [o_orderkey] <= '4640625001'
복사 병렬 처리 수준
기본적으로 자동은 복사 병렬 처리의 정도에 할당됩니다. 그러나 자동은 최적의 병렬 복사본 수를 달성하지 못할 수 있습니다. 병렬 복사본은 원본 데이터베이스에 설정된 세션 수와 상관 관계가 있습니다. 너무 많은 병렬 복사본이 생성되면 원본 데이터베이스 CPU가 과부가 될 위험이 있으므로 쿼리가 일시 중단된 상태가 됩니다.
자동을 사용하는 동적 범위에 대한 원래 테스트 사례에서 서비스는 실제로 런타임에 251개의 병렬 복사본을 생성했습니다. 복사 병렬 처리의 정도에 값을 지정하여 최대 병렬 복사본 수를 설정합니다. 이 설정을 사용하면 원본에 대한 동시 세션 수를 제한하여 리소스 관리를 보다 효율적으로 제어할 수 있습니다. 이러한 테스트 사례에서는 50을 값으로 지정하여 총 기간과 원본 리소스 사용률이 모두 향상되었습니다.
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 사용된 병렬 사본 | 총 기간 |
|---|---|---|---|---|
| 직물 창고 | None | 자동 | 1 | 02:23:21 |
| 직물 창고 | 동적 범위 | 50 | 50 | 00:13:05 |
병렬 복사 정도가 있는 동적 범위는 성능을 크게 향상시킬 수 있습니다. 그러나 설정을 사용하려면 경계를 미리 정의하거나 서비스에서 런타임 시 값을 확인하도록 허용해야 합니다. 서비스에서 런타임 시 값을 확인하도록 허용하면 원본 테이블의 DDL 및 데이터 볼륨에 따라 총 기간에 영향을 줄 수 있습니다. 또한 서비스에서 런타임 시 값을 결정할 수 있도록 허용하는 것은 원본이 처리할 수 있는 병렬 복사본의 수를 이해하는 데도 연결되어야 합니다. 값이 너무 높으면 원본 시스템과 복사 작업 성능이 저하될 수 있습니다.
병렬 복사본에 대한 자세한 내용은 복사 작업 성능 기능: 병렬 복사를 참조하세요.
동적 범위가 있는 Fabric Warehouse
기본적으로 격리 수준은 지정되지 않으며 병렬 처리 수준은 자동으로 설정됩니다.
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 |
|---|---|---|---|---|
| 직물 창고 | None | 자동 | 1 | 02:23:21 |
| 직물 창고 | 동적 범위 | 자동 | 251 | 00:39:03 |
동적 범위가 있는 패브릭 레이크하우스(테이블)
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 |
|---|---|---|---|---|
| 패브릭 레이크하우스 | None | 자동 | 1 | 02:23:21 |
| 패브릭 레이크하우스 | 동적 범위 | 자동 | 251 | 00:36:40 |
| 패브릭 레이크하우스 | 동적 범위 | 50 | 50 | 00:12:01 |
클러스터형 인덱스
힙 테이블에 비해 동적 범위의 파티션 열에 대해 선택한 열에 클러스터형 키 인덱스가 있는 테이블은 성능 및 리소스 사용률을 크게 향상시켰습니다. 복사 병렬 처리 수준을 자동으로 설정한 경우에도 마찬가지입니다.
클러스터형 인덱스가 있는 Fabric Warehouse
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 |
|---|---|---|---|---|
| 직물 창고 | None | 자동 | 1 | 02:23:21 |
| 직물 창고 | 동적 범위 | 자동 | 251 | 00:09:02 |
| 직물 창고 | 동적 범위 | 50 | 50 | 00:08:38 |
클러스터형 인덱스가 있는 Fabric Lakehouse 내 테이블
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 |
|---|---|---|---|---|
| 패브릭 레이크하우스 | None | 자동 | 1 | 02:23:21 |
| 패브릭 레이크하우스 | 동적 범위 | 자동 | 251 | 00:06:44 |
| 패브릭 레이크하우스 | 동적 범위 | 50 | 50 | 00:06:34 |
논리 파티션 디자인
논리 파티션 디자인 패턴은 고급이며 더 많은 개발자 노력이 필요합니다. 그러나 이 디자인은 엄격한 데이터 로드 요구 사항이 있는 시나리오에서 사용됩니다. 이 디자인은 원래 1.5시간 안에 180GB의 데이터를 로드하기 위해 온-프레미스 Oracle 데이터베이스의 요구 사항을 충족하도록 개발되었습니다. 복사 작업의 기본값을 사용하는 원래 디자인에는 65시간이 넘게 걸렸습니다. 논리 분할 디자인을 사용하면 1.5시간 안에 동일한 데이터가 전송됩니다.
이 디자인은 이 블로그 시리즈인 파이프라인 성능 향상 1부: 시간 간격을 초로 변환하는 방법)에도 사용되었습니다. 이 디자인은 큰 원본 테이블을 로드할 때 사용자 환경에서 에뮬레이트하는 데 적합하며, 데이터 범위를 설정하여 원본 데이터 읽기를 분할하는 등의 기술을 사용하여 최적의 로드 성능이 필요합니다. 이 디자인은 여러 하위 날짜 범위를 생성합니다. 그런 다음 For-Each 작업을 사용하여 범위를 반복하면 지정된 범위 간의 원본 데이터에 많은 복사 작업이 호출됩니다. For-Each 작업 내에서 모든 복사 작업은 병렬로 실행되고(최대 일괄 처리 수 최대 50개까지) 복사 병렬 처리 수준을 자동로 설정합니다.
아래 예제에서는 분할된 날짜 값이 다음 값으로 설정되었습니다.
- 시작 값: 1992-01-01
- 종료 값: 1998-08-02
- 버킷 간격 (일수): 50
병렬 복사본 및 총 기간은 생성된 모든 50개의 복사 작업에서 관찰되는 최대 값입니다. 50개 모두 병렬로 실행되었으므로 전체 기간의 최대값은 모든 복사 작업이 병렬로 완료되는 데 걸린 시간입니다.
논리 파티션 디자인이 있는 Fabric Warehouse
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 |
|---|---|---|---|---|
| 직물 창고 | None | 자동 | 1 | 02:23:21 |
| 직물 창고 | 논리적 디자인 | 자동 | 1 | 00:12:11 |
논리 파티션 디자인이 적용된 패브릭 레이크하우스(테이블)
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 |
|---|---|---|---|---|
| 패브릭 레이크하우스 | None | 자동 | 1 | 02:10:37 |
| 패브릭 레이크하우스 | 논리적 디자인 | 자동 | 1 | 00:09:14 |
테이블의 물리적 파티션
참고
실제 파티션을 사용하는 경우 파티션 열 및 메커니즘은 실제 테이블 정의에 따라 자동으로 결정됩니다.
테이블의 실제 파티션을 사용하려면 원본 테이블을 분할해야 합니다. 파티션 수가 성능에 미치는 영향을 이해하기 위해 파티션이 8개이고 파티션이 85개인 두 개의 분할된 테이블을 만들었습니다.
실제 파티션 수는 복사 병렬 처리 수준을 제한합니다. 파티션 수보다 작은 값을 지정하여 숫자를 제한할 수 있습니다.
실제 파티션이 있는 Fabric Warehouse
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 사용된 병렬 복사본 | 총 기간 |
|---|---|---|---|---|
| 직물 창고 | None | 자동 | 1 | 02:23:21 |
| 직물 창고 | 물리적 | 자동 | 8 | 00:26:29 |
| 직물 창고 | 물리적 | 자동 | 85 | 00:08:31 |
실제 파티션이 있는 패브릭 레이크하우스(테이블)
| 목적지 | 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 |
|---|---|---|---|---|
| 패브릭 레이크하우스 | None | 자동 | 1 | 02:10:37 |
| 패브릭 레이크하우스 | 물리적 | 자동 | 8 | 00:36:36 |
| 패브릭 레이크하우스 | 물리적 | 자동 | 85 | 00:12:21 |
격리 수준
다른 격리 수준 설정을 지정하면 성능에 미치는 영향을 비교해 보겠습니다. 자동으로 설정된 복사 병렬 처리 수준이 있는 격리 수준을 선택하면 복사 작업 원본 시스템을 과부수하고 실패할 위험이 있습니다. 복사 병렬 처리 수준을 자동으로 설정하려면 격리 수준을 없음으로 두는 것이 좋습니다.
참고
Azure SQL 데이터베이스의 기본값은 *격리 수준Read_Committed_Snapshot입니다.
복사 병렬 처리 수준이 50으로 설정된 동적 범위에 대한 테스트 사례를 확장하고 격리 수준이 성능에 미치는 영향을 살펴보겠습니다.
| 격리 수준 | 총 기간 | 용량 단위 | DB 최대 CPU % | 최대 DB 세션 |
|---|---|---|---|---|
| 없음(기본값) | 00:14:23 | 93,960 | 70 | 76 |
| 커밋되지 않은 읽기 | 00:13:46 | 89,280 | 81 | 76 |
| 커밋된 읽기 | 00:25:34 | 97,560 | 81 | 76 |
데이터베이스 원본 쿼리에 대해 선택하는 격리 수준은 최적화 경로보다는 요구 사항에 더 가까울 수 있지만 각 옵션 간의 성능 및 용량 단위 사용량의 차이를 이해하는 것이 중요합니다.
격리 수준에 대한 자세한 내용은** IsolationLevel 열거형을 참조하세요.
ITO 및 용량 사용량
병렬 복사본의 정도와 마찬가지로 ITO(지능형 처리량 최적화)는 설정할 수 있는 또 다른 최대값입니다. 비용을 최적화하는 경우 ITO는 원하는 결과에 맞게 조정하는 것이 좋습니다.
ITO 범위:
| ITO | 최댓값 |
|---|---|
| 자동 | 지정되지 않음 |
| 표준 | 64 |
| 균형 잡힌 | 128 |
| 최대 | 256 |
드롭다운은 위의 설정을 허용하지만 4에서 256 사이의 사용자 지정 값도 사용할 수 있습니다.
참고
사용된 실제 ITO 수는 복사 작업 출력 usedDataIntegrationUnits 필드에서 찾을 수 있습니다.
병렬 복사본의 정도가 자동으로 설정된 동적 범위 힙 테스트 사례의 경우 서비스는 실제 값이 100인 밸런스형를 선택했습니다. 사용자 지정 값 50을 지정하여 ITO를 반으로 줄이면 어떻게 되는지 살펴보겠습니다.
| ITO를 지정합니다. | 총 기간 | 용량 단위 | DB 최대 CPU % | 최대 DB 세션 | 최적화된 처리량 사용 |
|---|---|---|---|---|---|
| 최대(256) | 00:13:46 | 89,280 | 81 | 76 | 균형형(100) |
| 50 | 00:18:28 | 48,600 | 76 | 61 | 표준(48) |
ITO를 50% 줄임으로써 총 기간은 34% 증가했습니다. 그러나 서비스는 45.5% 더 적은 용량 단위를 사용했습니다. 총 기간을 개선하도록 최적화하지 않고 사용된 용량 단위를 줄이려면 ITO를 더 낮은 값으로 설정하는 것이 좋습니다.
요약
다음 차트는 Fabric Warehouse 및 Fabric Lakehouse 테이블에 로드하는 동작을 요약합니다. 테이블에 실제 파티션이 있는 경우 파티션 옵션을 사용합니다. 테이블의 실제 파티션은 원본에서 전송 기간, 용량 단위 및 컴퓨팅 오버헤드에 대해 가장 균형 잡힌 방법입니다. 이 설정은 데이터 이동 중에 데이터베이스에 대해 실행되는 세션이 더 많은 경우에 특히 적합합니다.
테이블에 실제 파티션이 없는 경우에도 파티션 옵션인 동적 범위를 사용할 수 있습니다. 이 옵션을 사용하려면 상한 및 하한을 결정하기 위한 이전 단계가 필요하지만, 용량 소비량이 약간 더 많이 드는 비용, 원본 컴퓨팅 사용률 및 최적의 병렬 처리 수준을 테스트해야 하는 기본 옵션에 비해 전송 기간이 크게 향상되었습니다.
복사 작업의 성능을 최대화하는 또 다른 중요한 요소는 단일 클라우드 지역 내에서 데이터 이동을 유지하는 것입니다. 예를 들어 미국 서부의 데이터 팩터리를 사용하여 미국 서부의 원본 및 대상 데이터 저장소에서의 데이터 이동은 미국 동부에서 미국 서부로 데이터를 이동하는 복사 작업보다 성능이 뛰어됩니다.
마지막으로 속도가 최적화의 가장 중요한 측면인 경우 원본 테이블의 최적화된 DDL을 갖는 것이 실제 파티션 옵션을 사용하는 데 중요합니다. 분할되지 않은 테이블의 경우 동적 범위를 사용해 보세요. 이 설정이 충분히 빠르지 않은 경우 논리 분할 또는 논리 분할의 하이브리드 접근 방식과 하위 범위 내의 동적 범위를 고려합니다.
지침
Cost 조정, 지능형 처리량 최적화 및 병렬 복사본의 수준 조정 분할된 테이블의 속도입니다. 파티션 수가 많은 경우 파티션 옵션인 테이블의 실제 파티션을 사용합니다. 그렇지 않으면 데이터가 기울어지거나 파티션 수가 제한된 경우 동적 범위를 사용하는 것이 좋습니다. 인덱스가 있는 힙 및 테이블의 경우 원본에서 일시 중단된 쿼리 수를 제한하는 병렬 복사본의 정도와 함께 동적 범위를 사용합니다. 파티션 상한/하한을 미리 정의할 수 있는 경우 추가 성능 향상을 실현할 수 있습니다.
유지 관리 효율성 및 개발자의 노력을 고려합니다. 기본 옵션을 그대로 두면 데이터를 이동하는 데 시간이 가장 오래 걸리지만, 특히 원본 테이블의 DDL을 알 수 없는 경우 기본값으로 실행하는 것이 가장 좋은 옵션일 수 있습니다. 또한 합리적인 용량 단위 사용량도 제공합니다.
테스트 사례
Fabric Warehouse 테스트 사례
| 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 | 용량 단위 | 최대 CPU % | 최대 세션 수 |
|---|---|---|---|---|---|---|
| None | 자동 | 1 | 02:23:21 | 51,839 | < 1 | 2 |
| 물리적(8) | 자동 | 8 | 00:26:29 | 49,320 | 3 | 10 |
| 물리적(85) | 자동 | 85 | 00:08:31 | 108,000 | 15 | 83 |
| 동적 범위(힙) | 자동 | 242 | 00:39:03 | 282,600 | 100 | 272 |
| 동적 범위(힙) | 50 | 50 | 00:13:05 | 92,159 | 81 | 76 |
| 동적 범위(클러스터형 인덱스) | 자동 | 251 | 00:09:02 | 64,080 | 9 | 277 |
| 동적 범위(클러스터형 인덱스) | 50 | 50 | 00:08:38 | 55,440 | 10 | 77 |
| 논리적 디자인 | 자동 | 1 | 00:12:11 | 226,108 | 91 | 50 |
Fabric Lakehouse(테이블) 테스트 사례
| 파티션 옵션 | 복사 병렬 처리 수준 | 병렬 복사본 사용 | 총 기간 | 용량 단위 | 최대 CPU % | 최대 세션 수 |
|---|---|---|---|---|---|---|
| None | 자동 | 1 | 02:10:37 | 47,520 | <1% | 2 |
| 물리적(8) | 자동 | 8 | 00:36:36 | 64,079 | 2 | 10 |
| 물리적(85) | 자동 | 85 | 00:12:21 | 275,759 | ||
| 동적 범위(힙) | 자동 | 251 | 00:36:12 | 280,080 | 100 | 276 |
| 동적 범위(힙) | 50 | 50 | 00:12:01 | 101,159 | 68 | 76 |
| 동적 범위(클러스터형 인덱스) | 자동 | 251 | 00:06:44 | 59,760 | 11 | 276 |
| 동적 범위(클러스터형 인덱스) | 50 | 50 | 00:06:34 | 54,760 | 10 | 76 |
| 논리적 디자인 | 자동 | 1 | 00:09:14 | 164,908 | 82 | 50 |