데이터 흐름은 셀프 서비스, 클라우드 기반 데이터 준비 기술입니다. 이 문서에서는 첫 번째 데이터 흐름을 만들고, 데이터 흐름에 대한 데이터를 가져온 다음, 데이터를 변환하고, 데이터 흐름을 게시합니다.
필수 조건
시작하기 전에 다음 필수 조건이 필요합니다.
- 활성 구독이 있는 Microsoft Fabric 테넌트 계정입니다. 무료 계정을 만듭니다.
- Microsoft Fabric 사용 가능한 작업 영역이 있는지 확인합니다. 작업 영역 만들기.
데이터 흐름 만들기
이 섹션에서는 첫 번째 데이터 흐름을 만듭니다.
메모
2026년 4월부터 모든 새 Dataflow Gen2 항목은 기본적으로 CI/CD 및 Git 통합 지원을 사용하여 만들어집니다. CI/CD 지원 없이 Dataflow Gen2 항목을 만드는 옵션은 더 이상 사용할 수 없습니다. 기존 비 CI/CD 데이터 흐름은 계속 작동합니다.
Microsoft Fabric 포털로 이동하여 Microsoft Fabric 작업 영역으로 이동하고 왼쪽 탐색 창에서 Workspaces 선택한 다음 목록에서 작업 영역을 선택합니다.
+새 항목을 선택한 다음, Dataflow Gen2를 선택합니다.
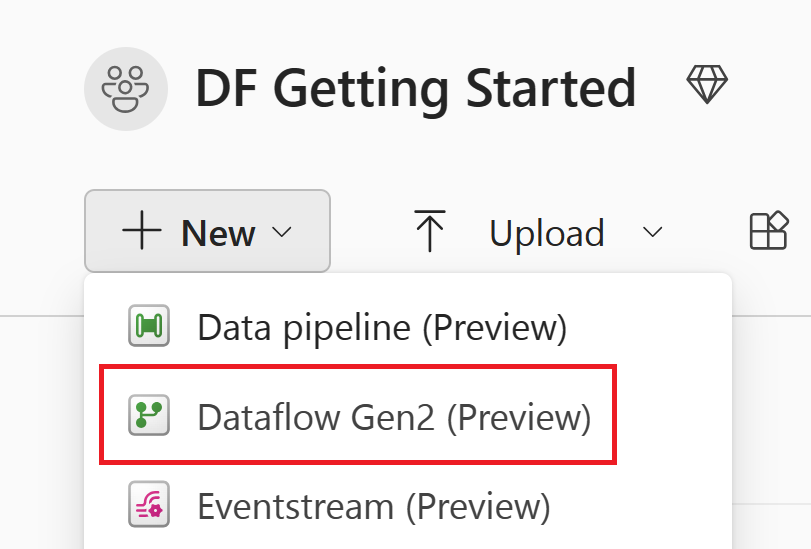
데이터 가져오기
몇 가지 데이터를 가져와 보겠습니다! 이 예제에서는 OData 서비스에서 데이터를 가져옵니다. 데이터 흐름에서 데이터를 가져오려면 다음 단계를 따르세요.
데이터 흐름 편집기에서 데이터 가져오기를 선택한 다음, 자세히를 선택합니다.
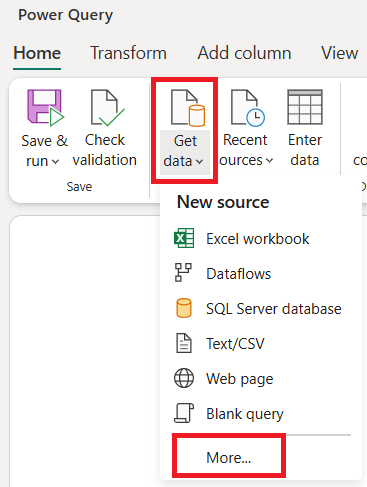
데이터 원본 선택에서 자세히 보기를 선택합니다.
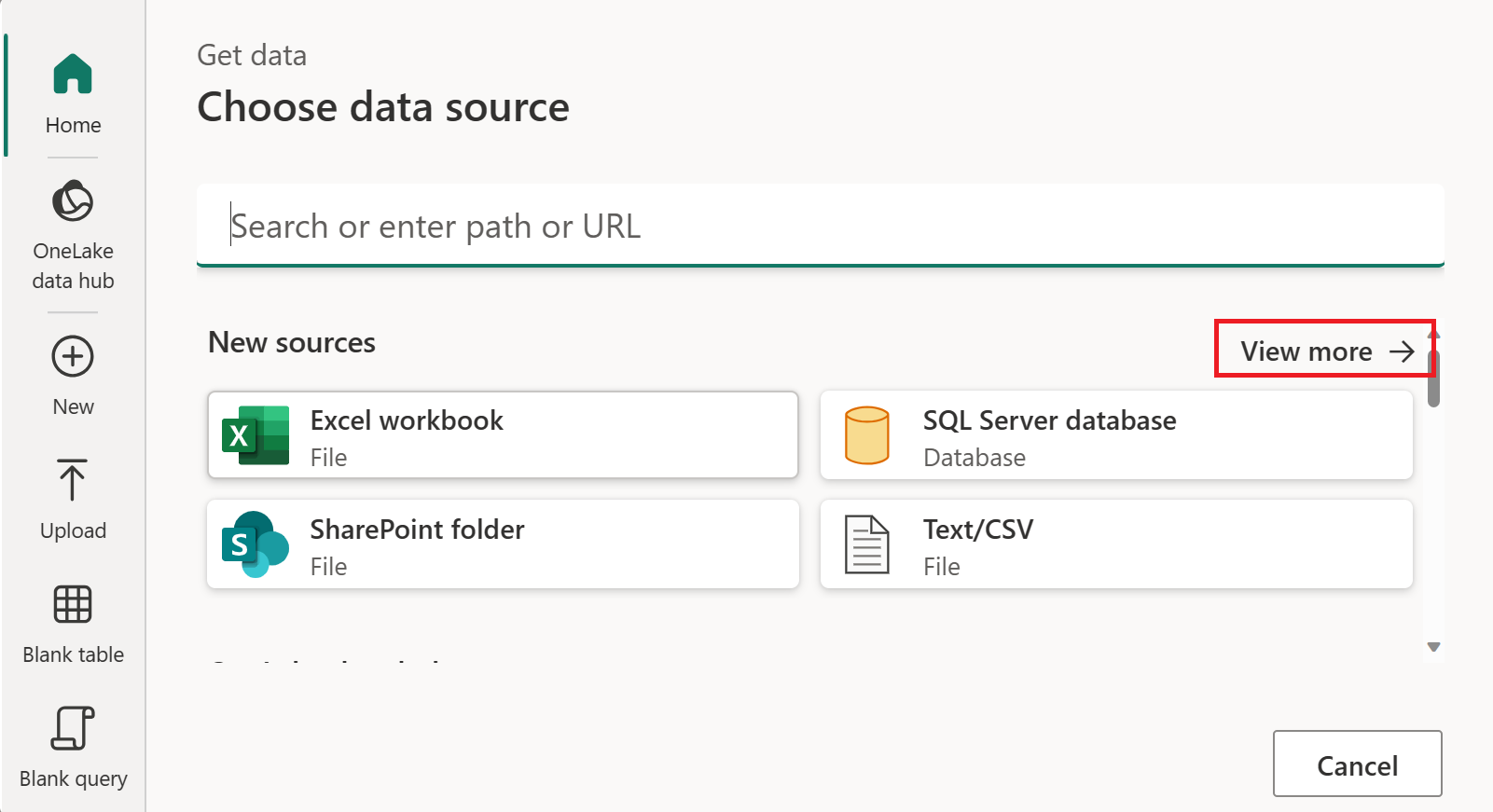
새 원본에서 다른>OData를 데이터 원본으로 선택합니다.

URL
https://services.odata.org/v4/northwind/northwind.svc/를 입력한 후 다음을 선택합니다.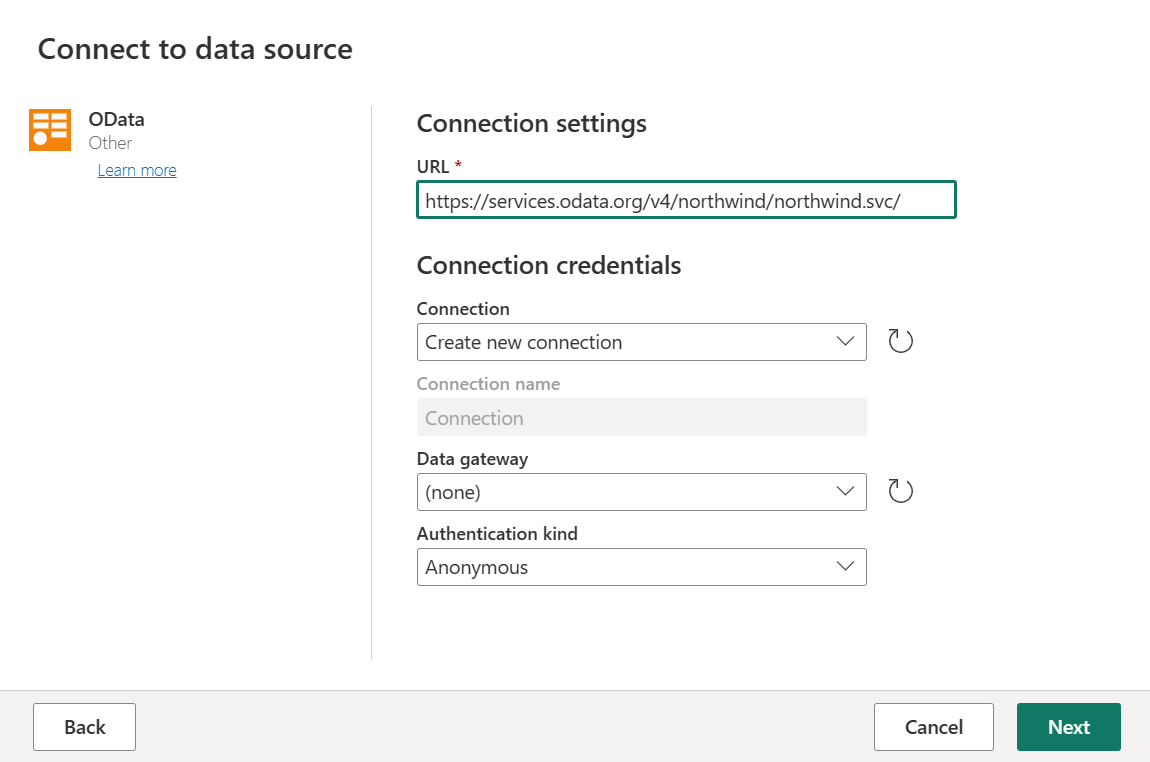
Orders 및 Customers 테이블을 선택한 다음, 만들기를 선택합니다.
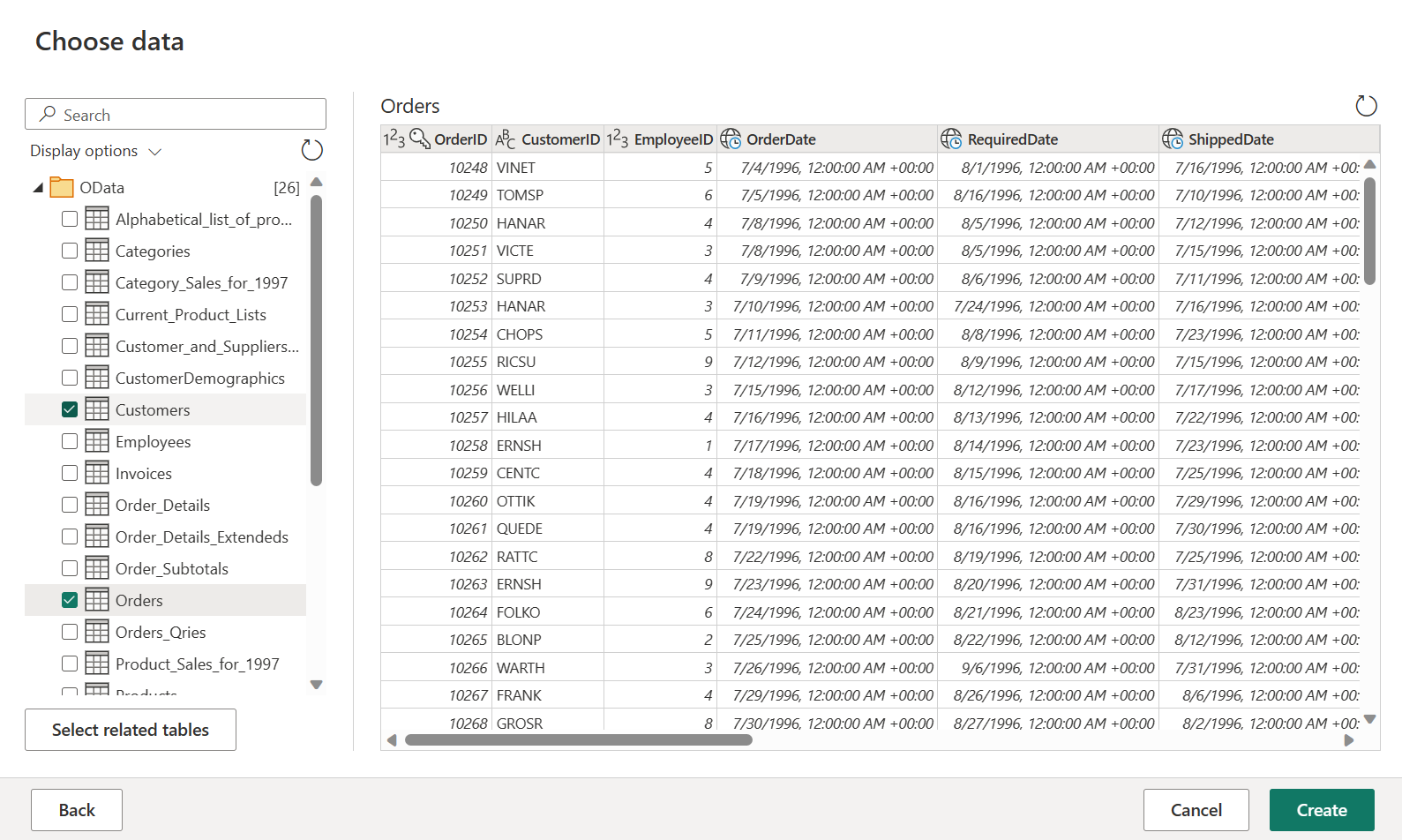 >
>



데이터 가져오기 개요에서 데이터 가져오기 환경 및 기능에 대해 자세히 알아볼 수 있습니다.
변환 적용 및 게시
첫 번째 데이터 흐름에 데이터를 로드했습니다. 축하합니다! 이제 이 데이터를 필요한 모양으로 가져오기 위해 몇 가지 변환을 적용해야 합니다.
Power Query 편집기에서 데이터를 변환합니다. Power Query 편집기의 자세한 개요는 Power Query 사용자 인터페이스 찾을 수 있지만 이 섹션에서는 기본 단계를 안내합니다.
데이터 프로파일링 도구가 켜져 있는지 확인합니다. 홈>옵션>전역 옵션으로 이동한 다음 열 프로필에서 모든 옵션을 선택합니다.
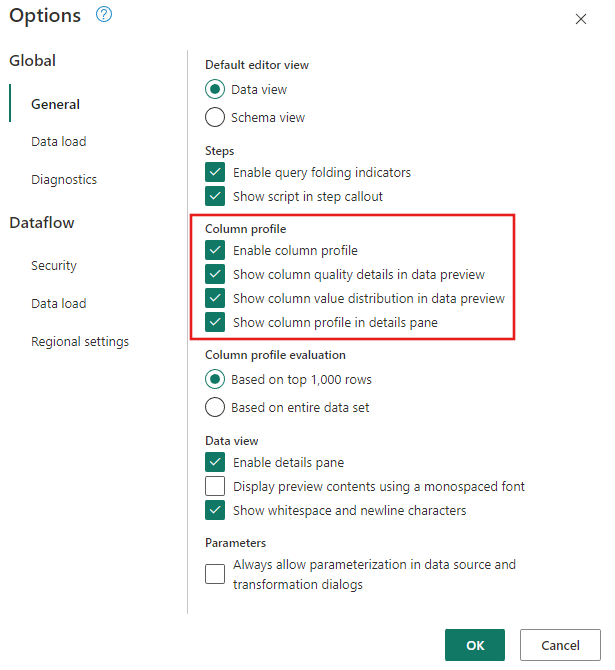
또한 Power Query 편집기 리본 메뉴의 View 탭에서 레이아웃 구성을 사용하거나 Power Query 창의 오른쪽 아래에 있는 다이어그램 보기 아이콘을 선택하여 다이어그램 보기를 사용하도록 설정해야 합니다.
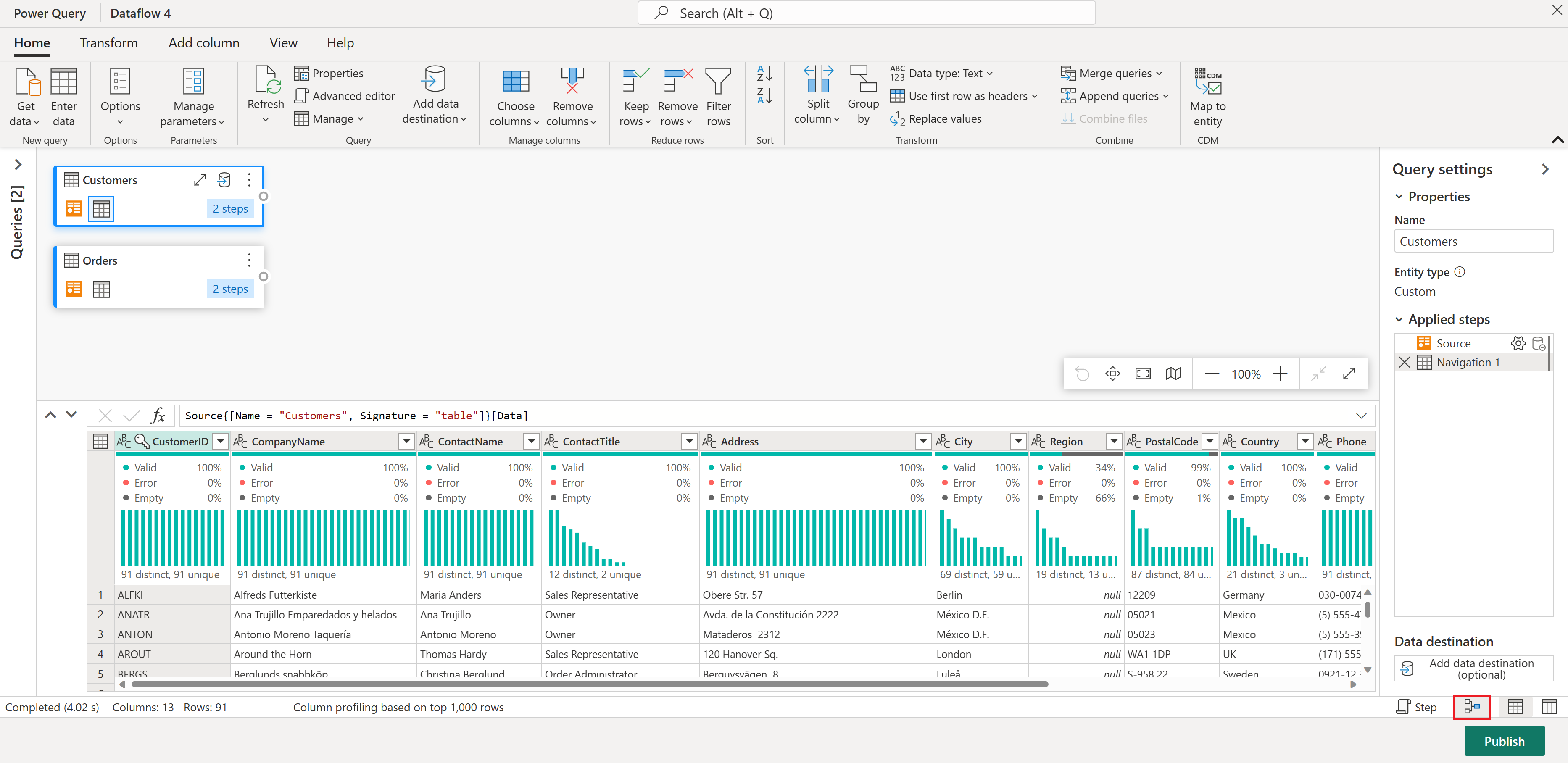
Orders 테이블 내에서 고객당 총 주문 수를 계산합니다. 데이터 미리 보기에서 CustomerID 열을 선택한 다음 리본 메뉴의 변환 탭 아래에서 그룹화 방법을 선택합니다.
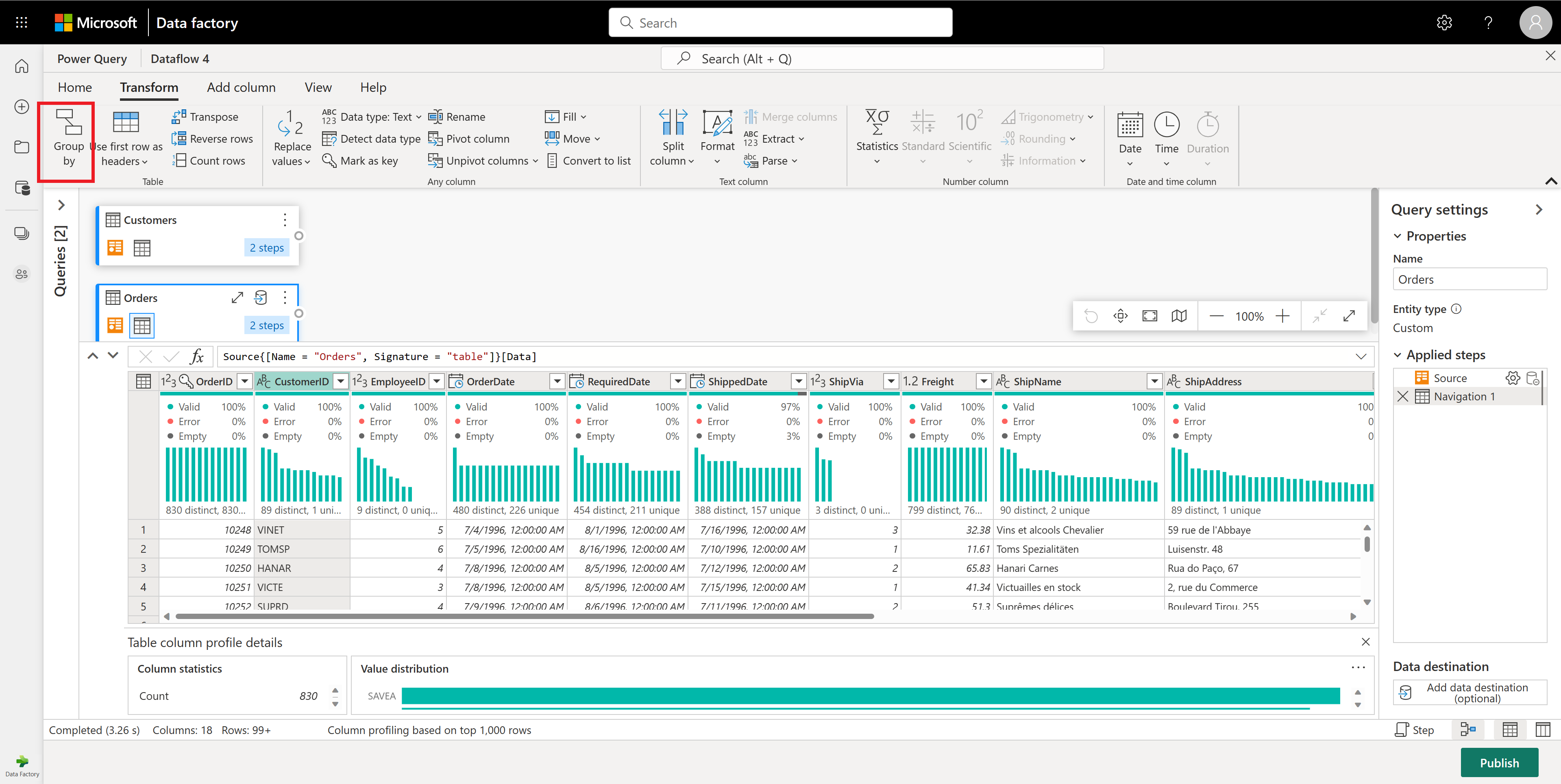
Group By 내에서 집계로 행 수를 수행합니다. 행 그룹화 또는 요약에서 Group By 기능에 대해 자세히 알아볼 수 있습니다.
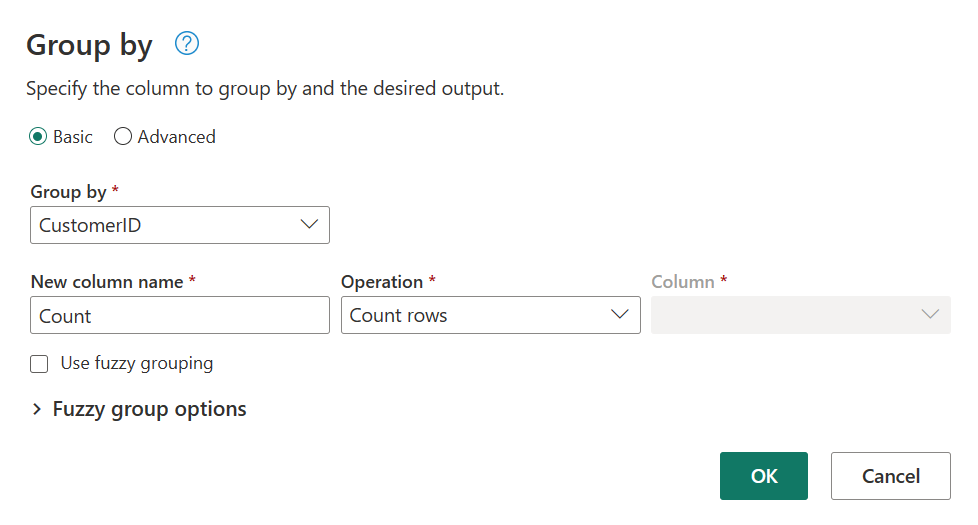
Orders 테이블에서 데이터를 그룹화한 후 CustomerID 및 Count를 열로 사용하여 2열 테이블을 가져옵니다.
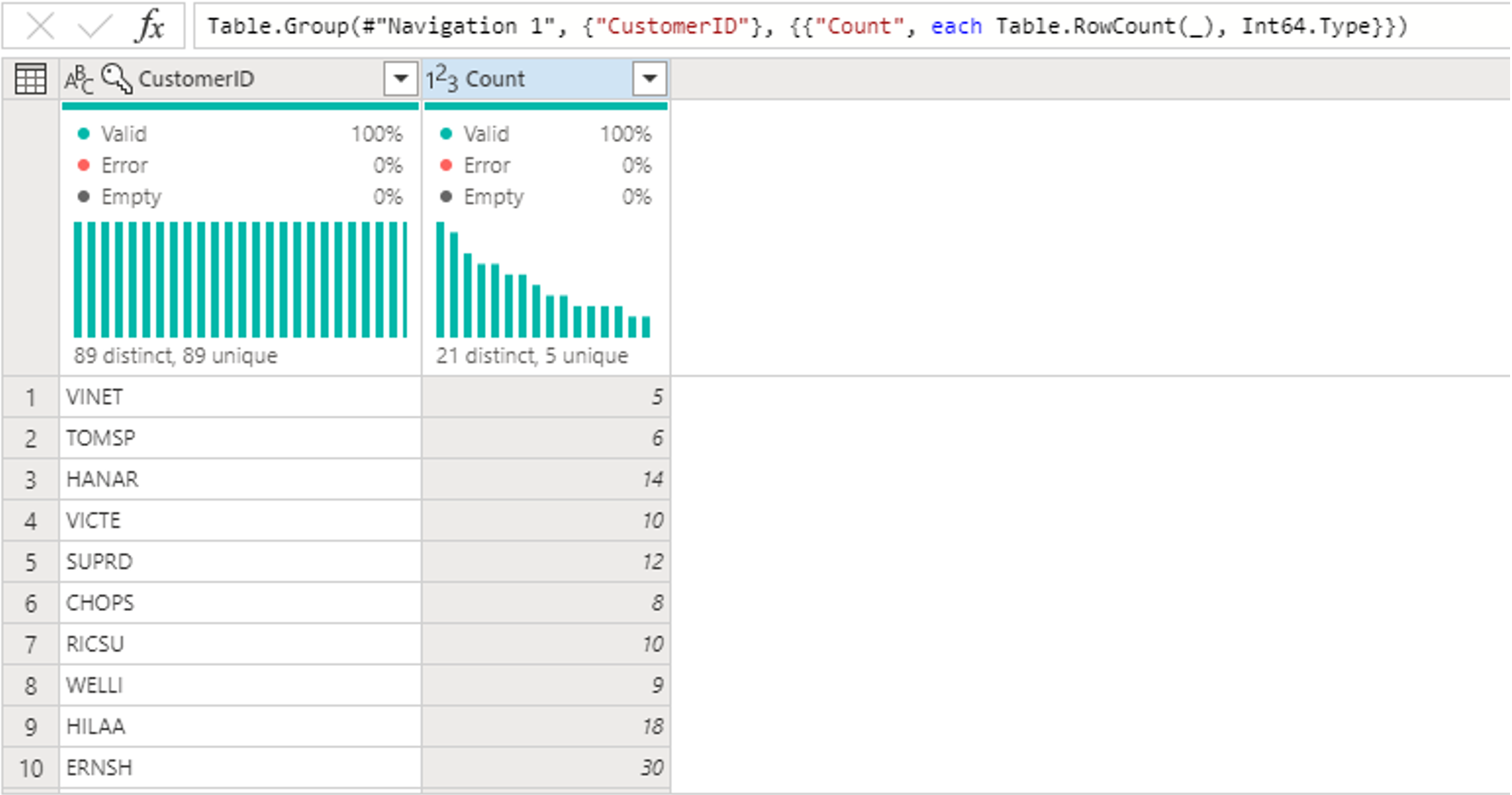
다음으로 고객 테이블의 데이터를 고객별 주문 수와 결합하려고 합니다. 다이어그램 보기에서 고객 쿼리를 선택한 후, "⋮" 메뉴를 사용하여 새로 병합 쿼리를 생성하는 변환에 액세스합니다.
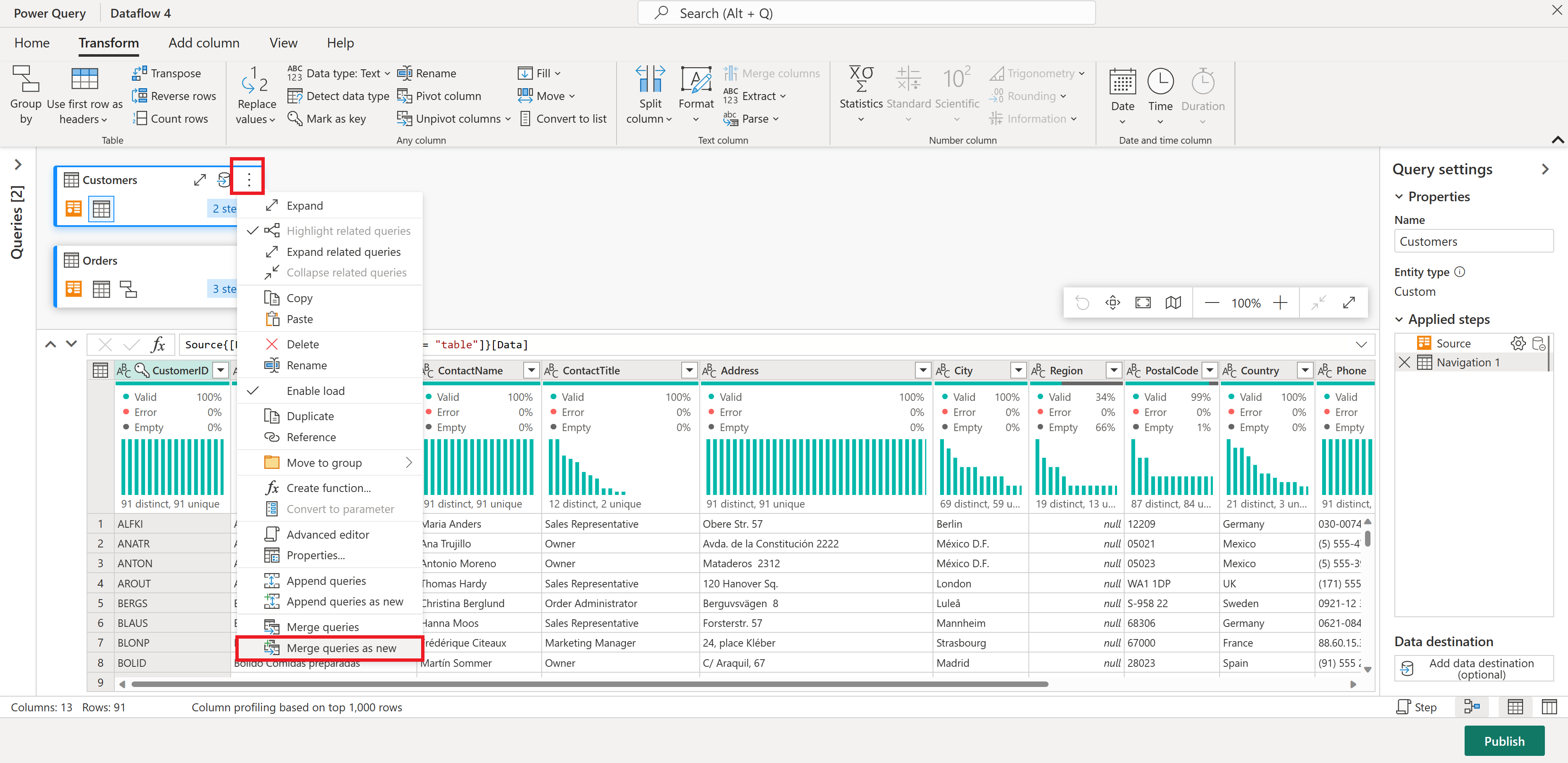
두 테이블에서 일치하는 열로 CustomerID를 선택하여 병합 작업을 구성합니다. 그런 다음, 확인을 선택합니다.
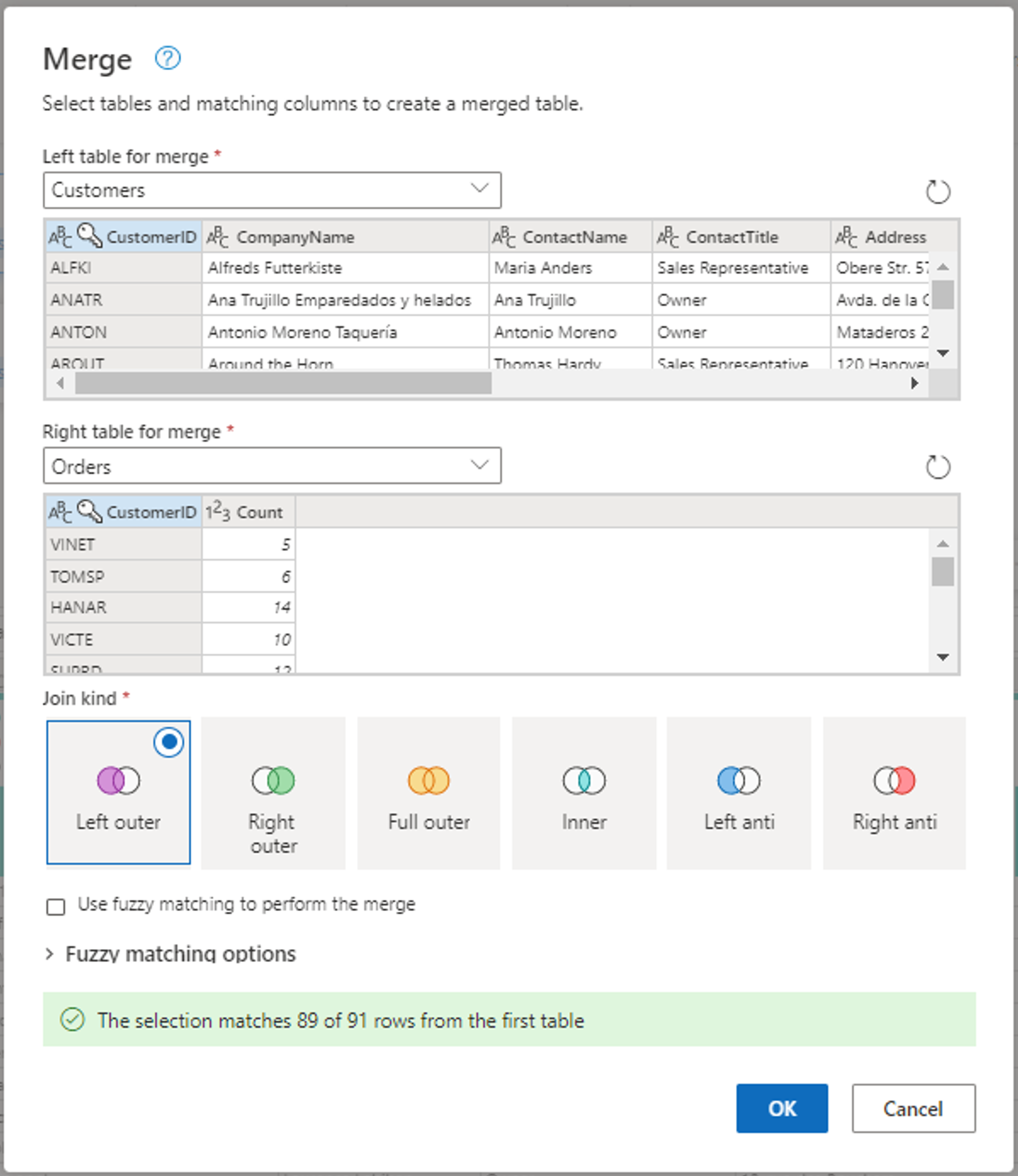
병합을 위한 왼쪽 테이블이 Customers 테이블로 설정되고 병합의 오른쪽 테이블이 Orders 테이블로 설정된 병합 창의 스크린샷 CustomerID 열은 고객 및 주문 테이블 모두에 대해 선택됩니다. 또한 조인 종류는 왼쪽 외부로 설정됩니다. 다른 모든 선택사항은 기본값으로 설정됩니다.
이제 Customers 테이블의 모든 열과 Orders 테이블의 중첩된 데이터가 있는 하나의 열이 있는 새 쿼리가 있습니다.
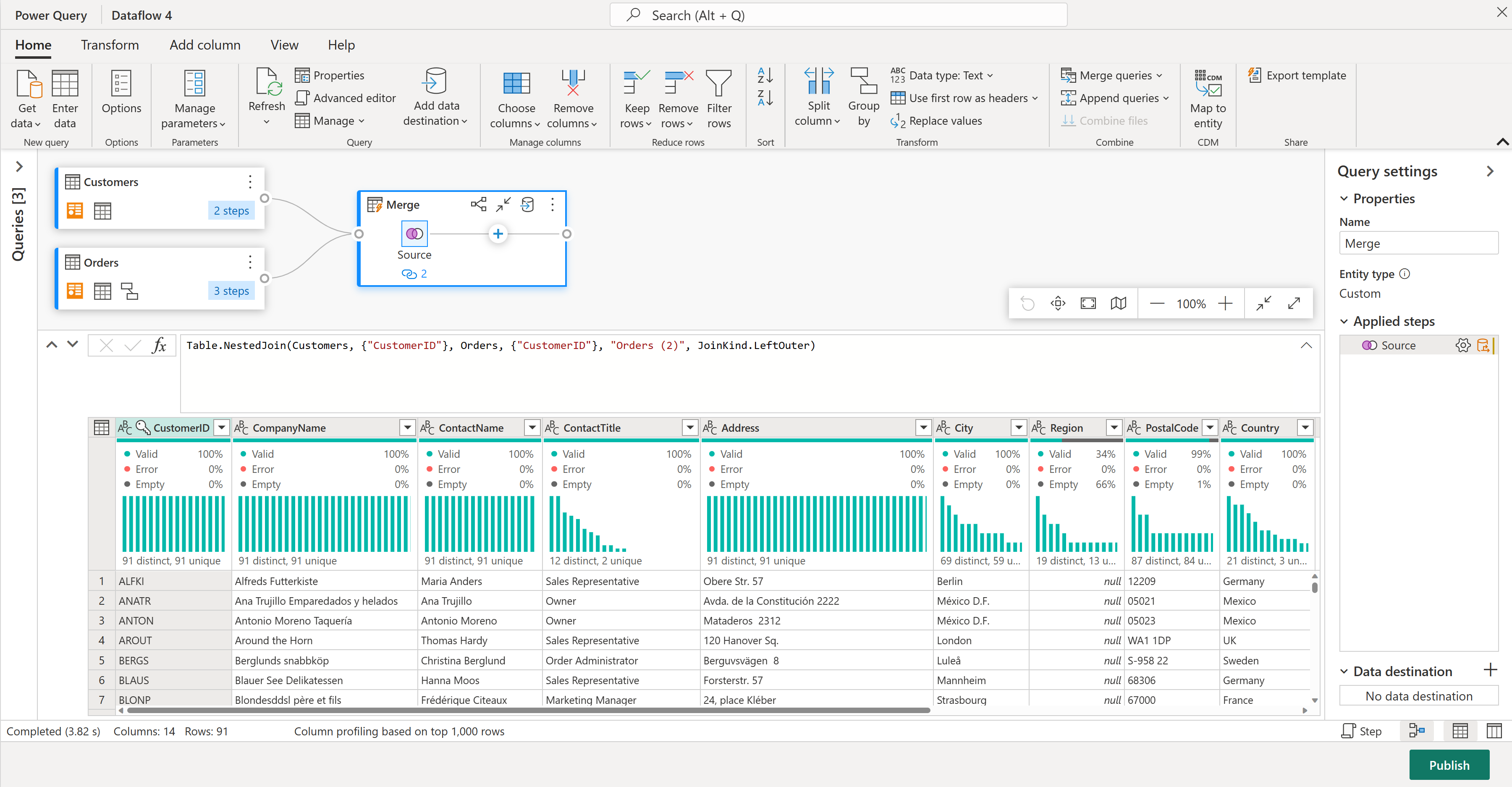
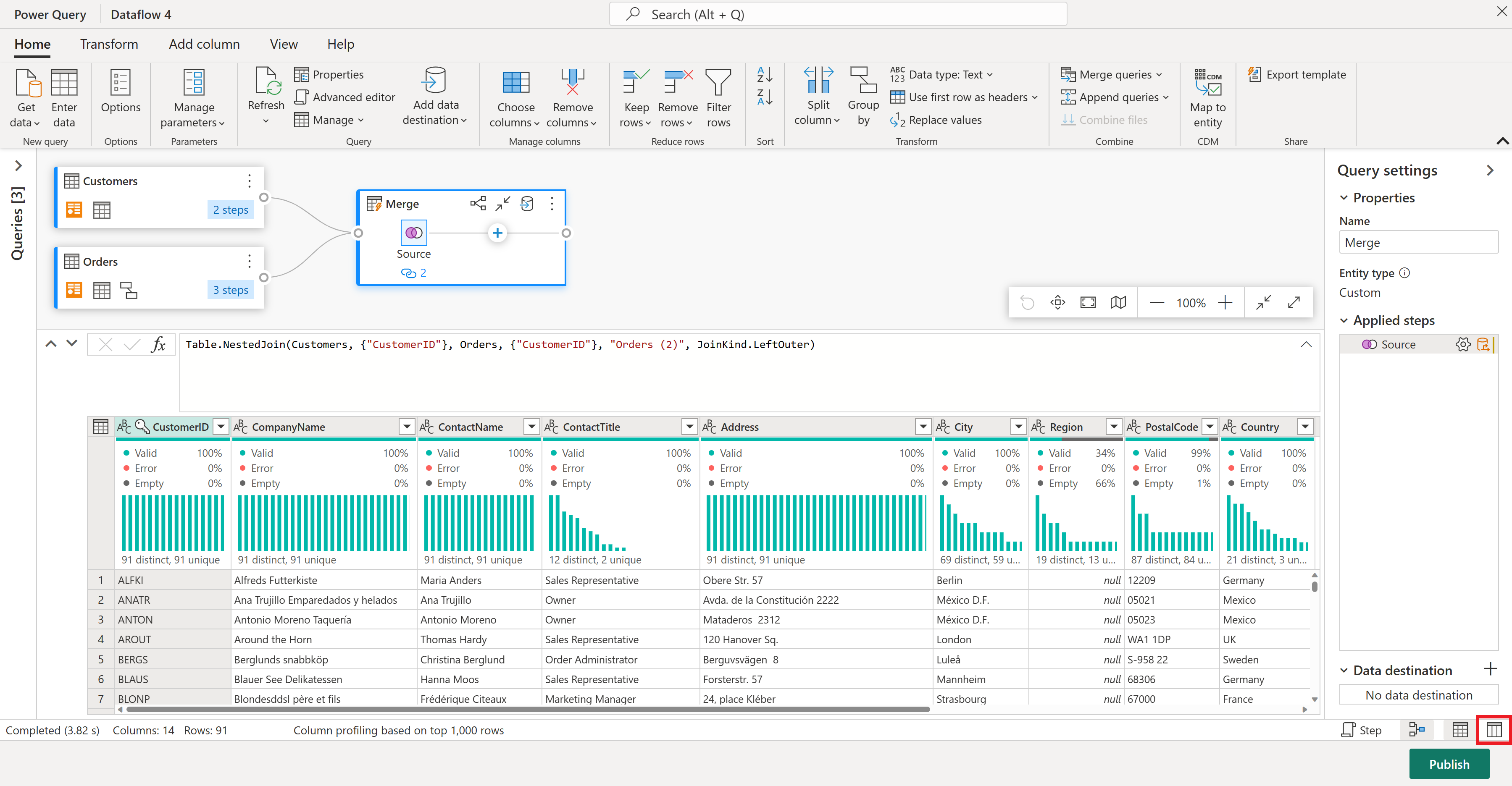
Customers 테이블에서 단 몇 개의 열에만 집중해 보겠습니다. 이렇게 하려면 데이터 흐름 편집기의 오른쪽 아래 모서리에 있는 스키마 보기 단추를 선택하여 스키마 보기를 켭니다.
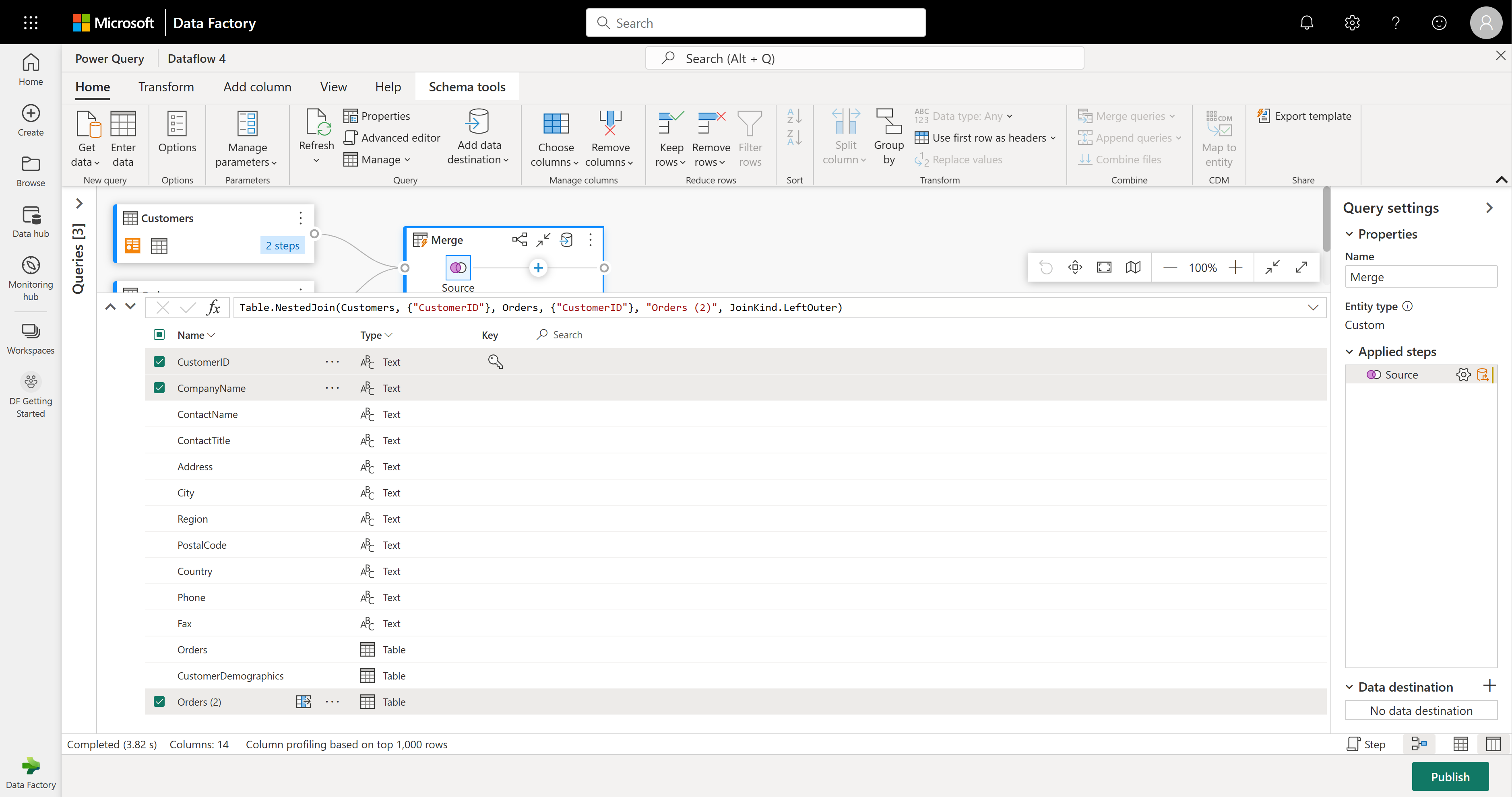
스키마 보기에는 테이블의 모든 열이 표시됩니다. CustomerID, CompanyName 및 Orders(2)를 선택합니다. 그런 다음 스키마 도구 탭으로 이동하여 열 제거를 선택하고 다른 열 제거를 선택합니다. 이렇게 하면 원하는 열만 유지됩니다.
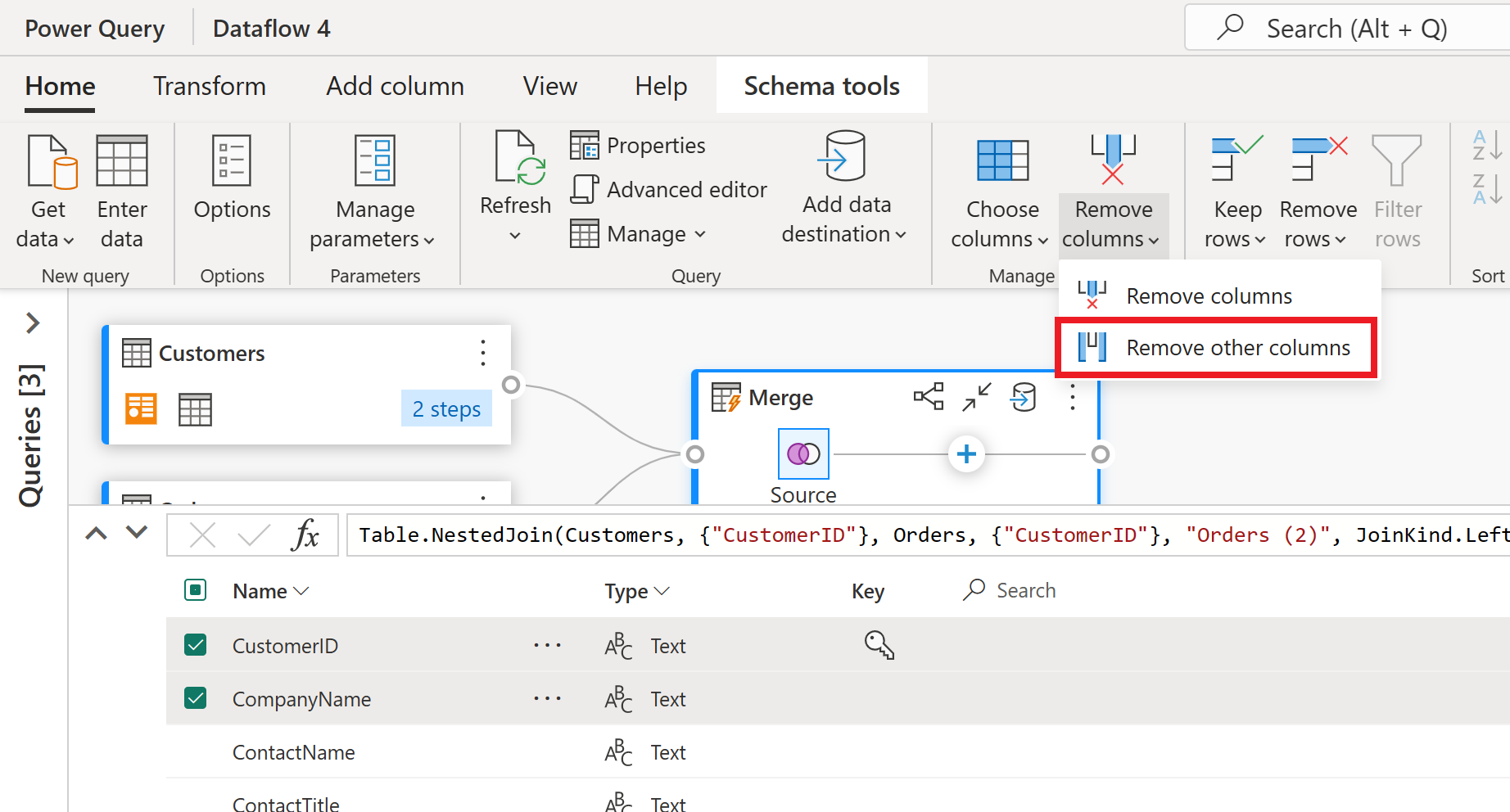
Orders(2) 열에는 병합 단계의 추가 세부 정보가 포함됩니다. 이 데이터를 보고 사용하려면 스키마 보기 표시 옆에 있는 오른쪽 아래 모서리에서 데이터 보기 표시 단추를 선택합니다. 그런 다음 Orders(2) 열 머리글에서 열 확장 아이콘을 선택하고 개수 열을 선택합니다. 그러면 각 고객의 주문 수가 테이블에 추가됩니다.
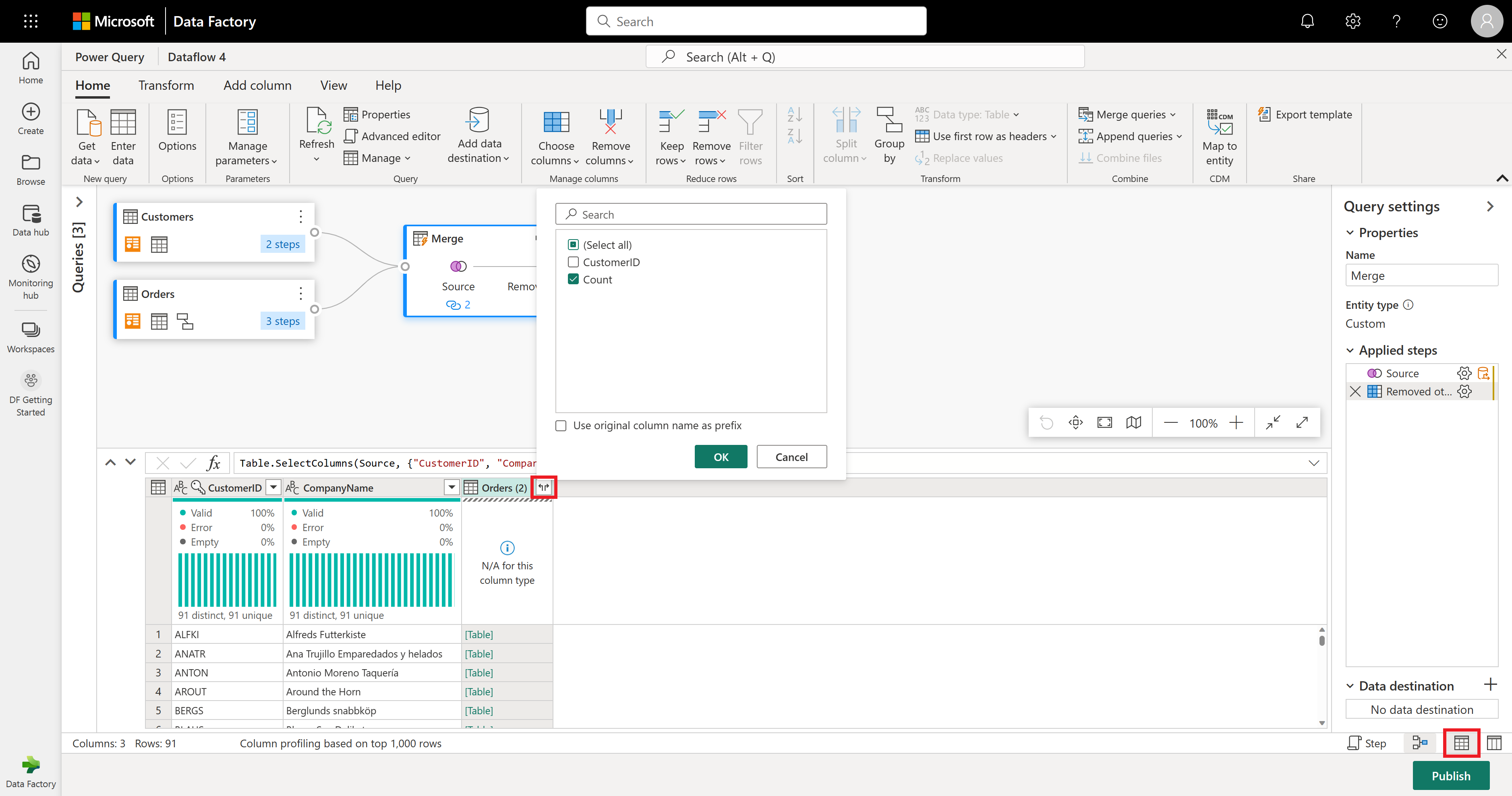
이제 고객의 주문 수를 기준으로 순위를 지정해 보겠습니다. 개수 열을 선택한 다음, 열 추가 탭으로 이동하여 순위 열을 선택합니다. 그러면 주문 횟수에 따라 각 고객의 순위를 보여 주는 새 열이 추가됩니다.
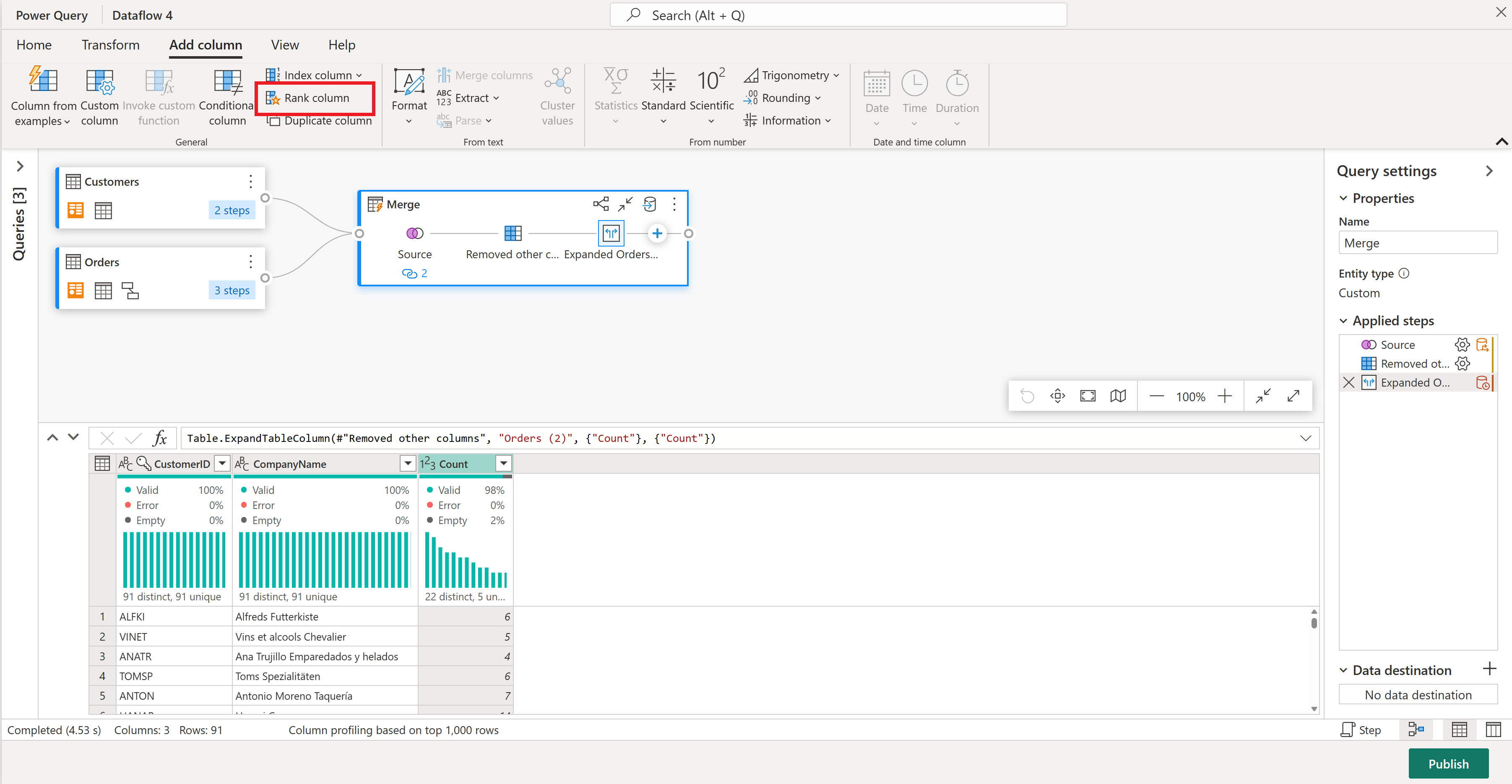
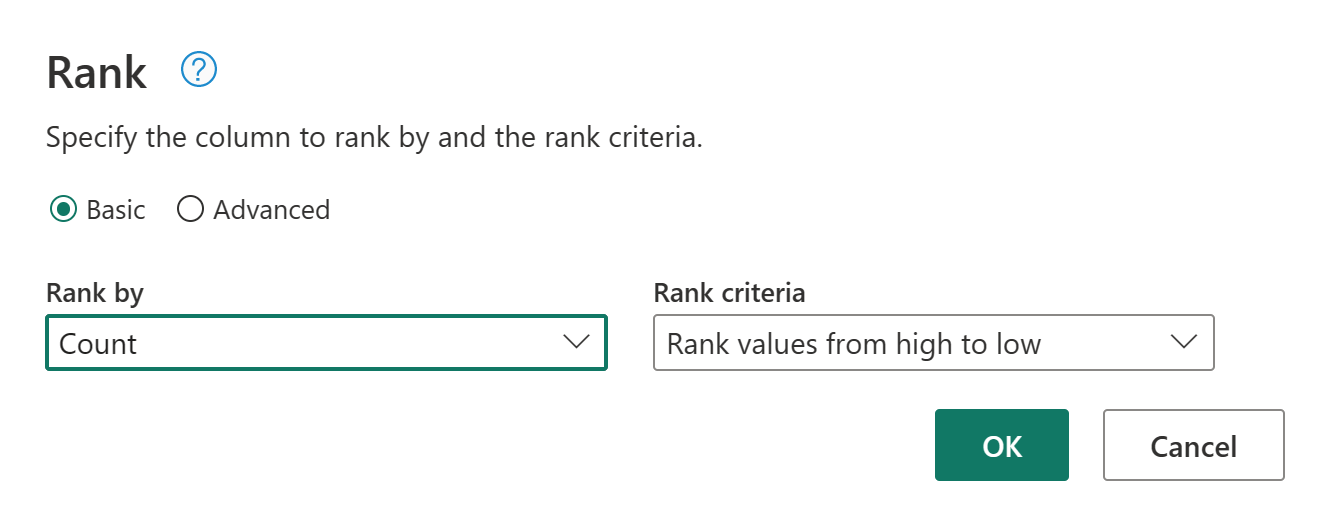
Rank 열에 기본 설정을 유지합니다. 그런 다음 확인을 선택하여 이 변환을 적용합니다.
이제 화면 오른쪽에 있는 쿼리 설정 창을 사용하여 결과 쿼리의 이름을 순위가 매겨진 고객으로 바꿉니다.
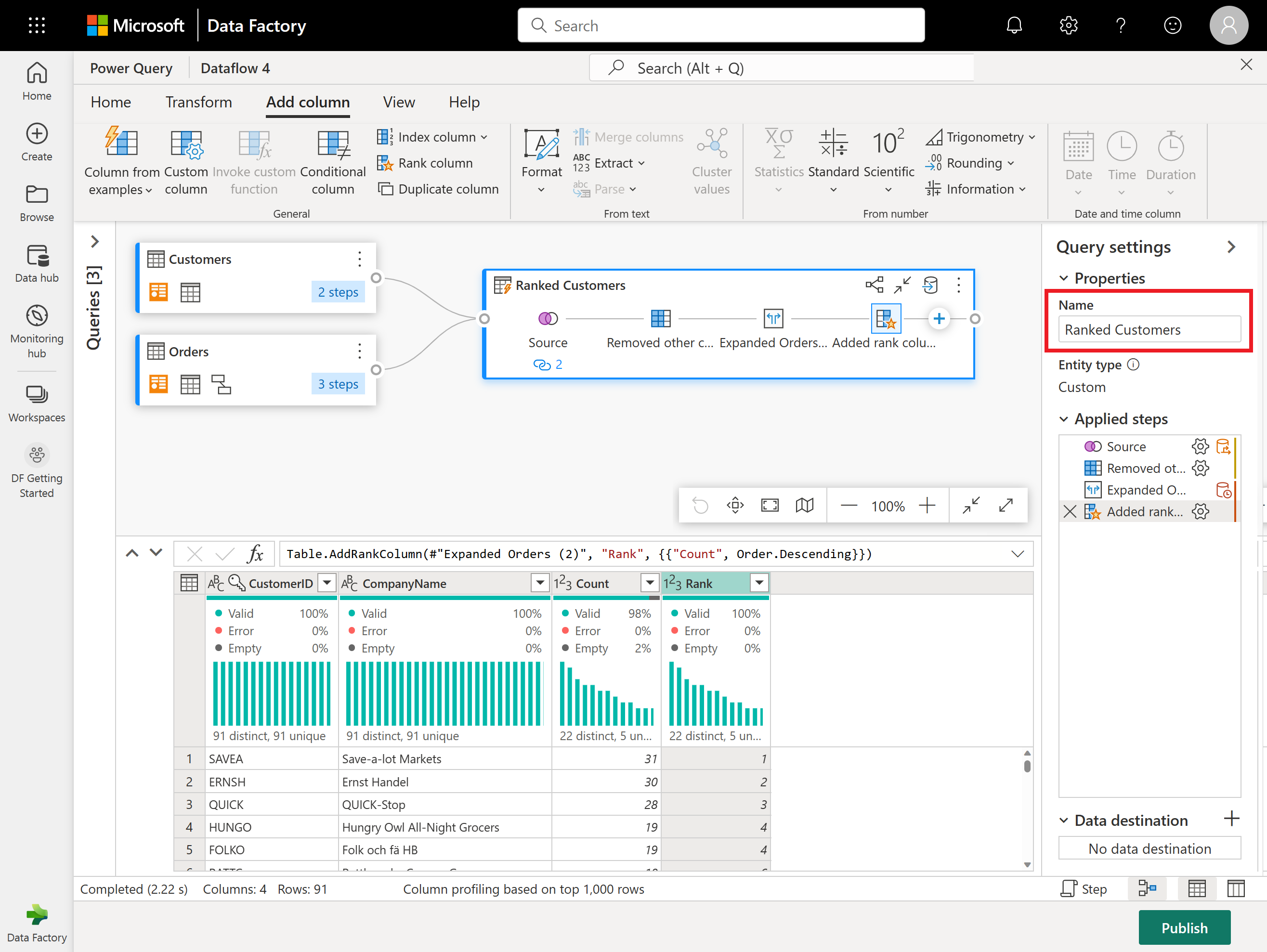
데이터가 어디로 가는지 설정할 준비가 된 것입니다. 쿼리 설정 창에서 아래쪽으로 스크롤하고 데이터 대상 선택을 선택합니다.
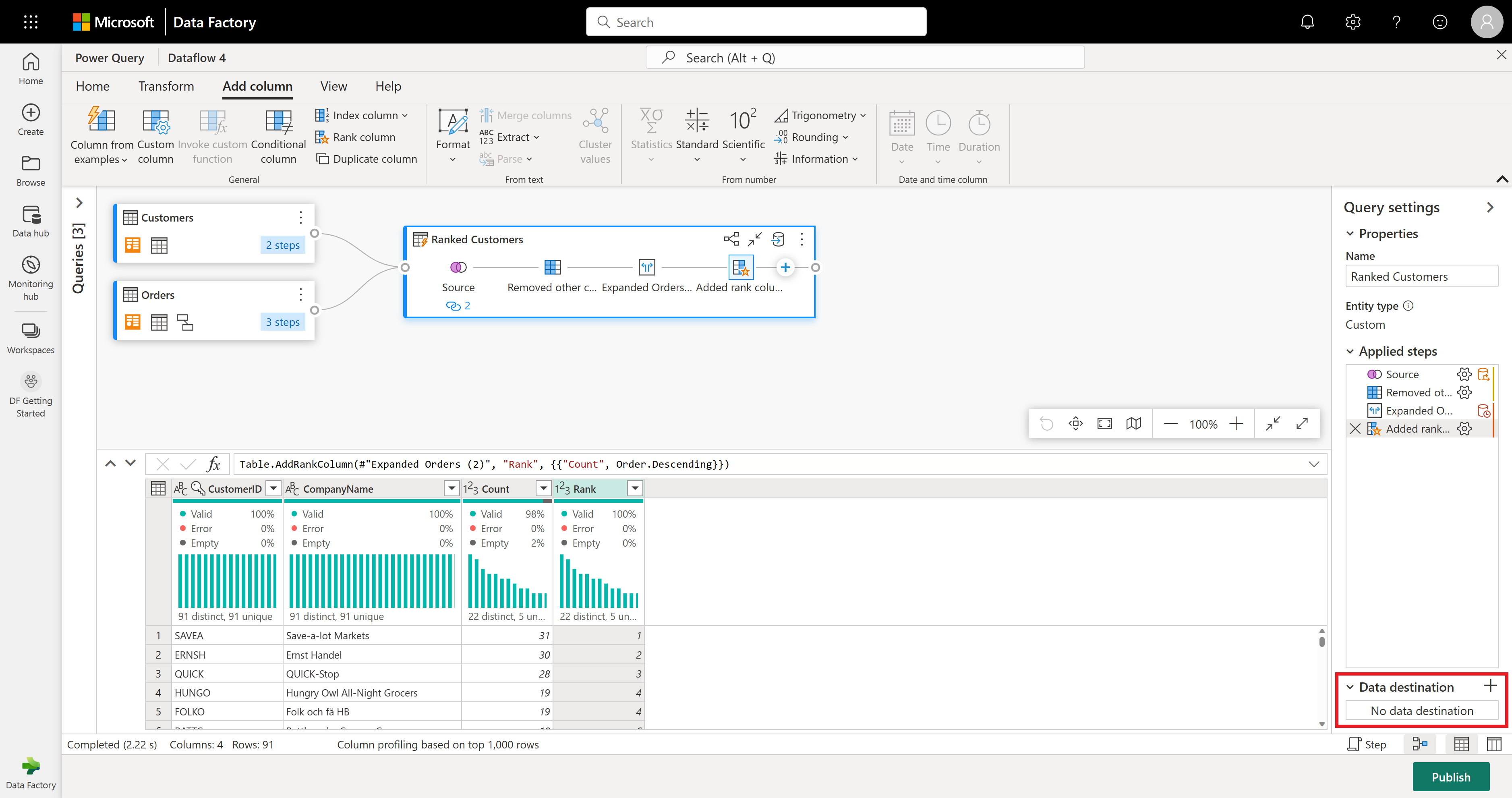
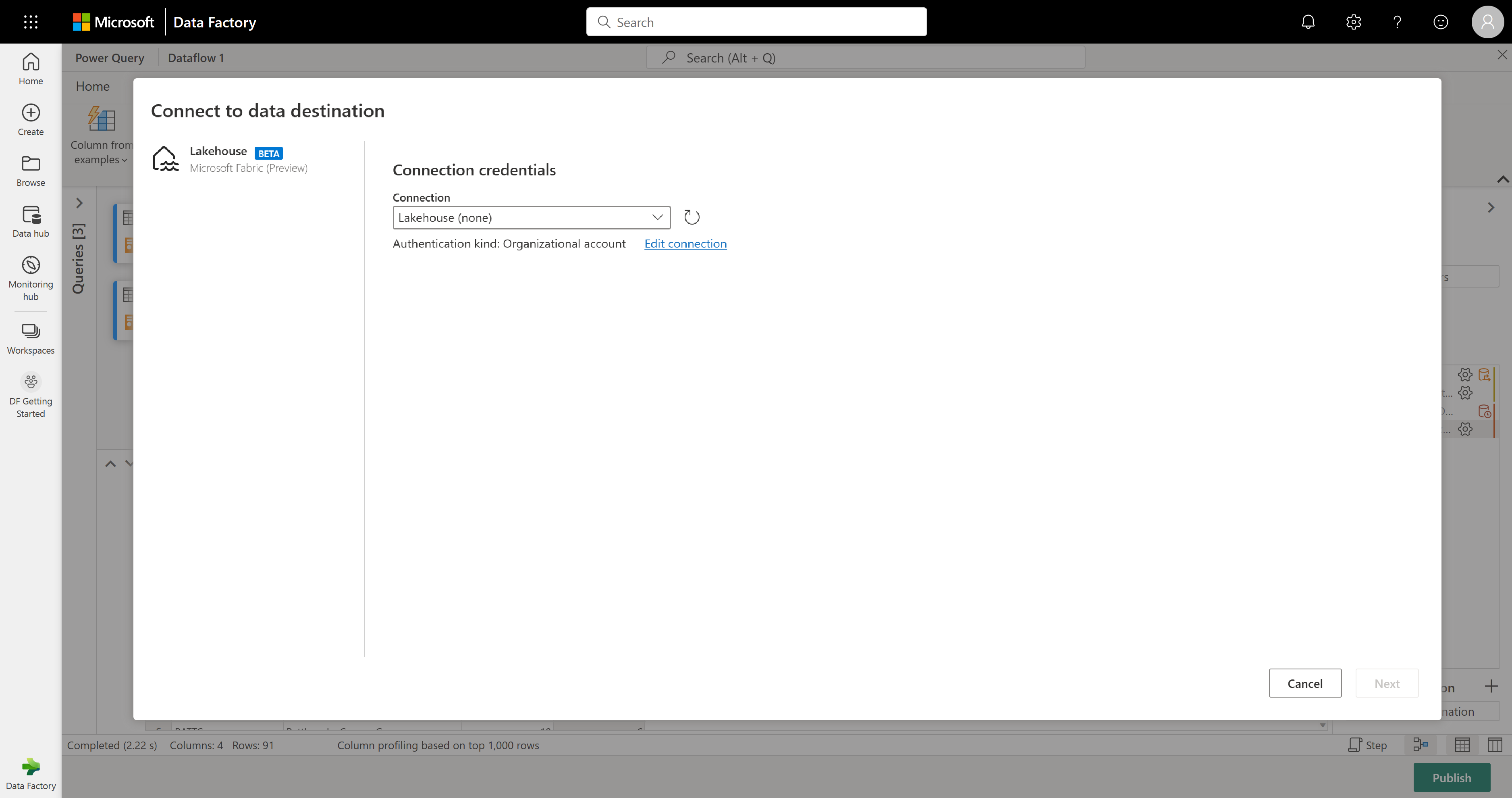
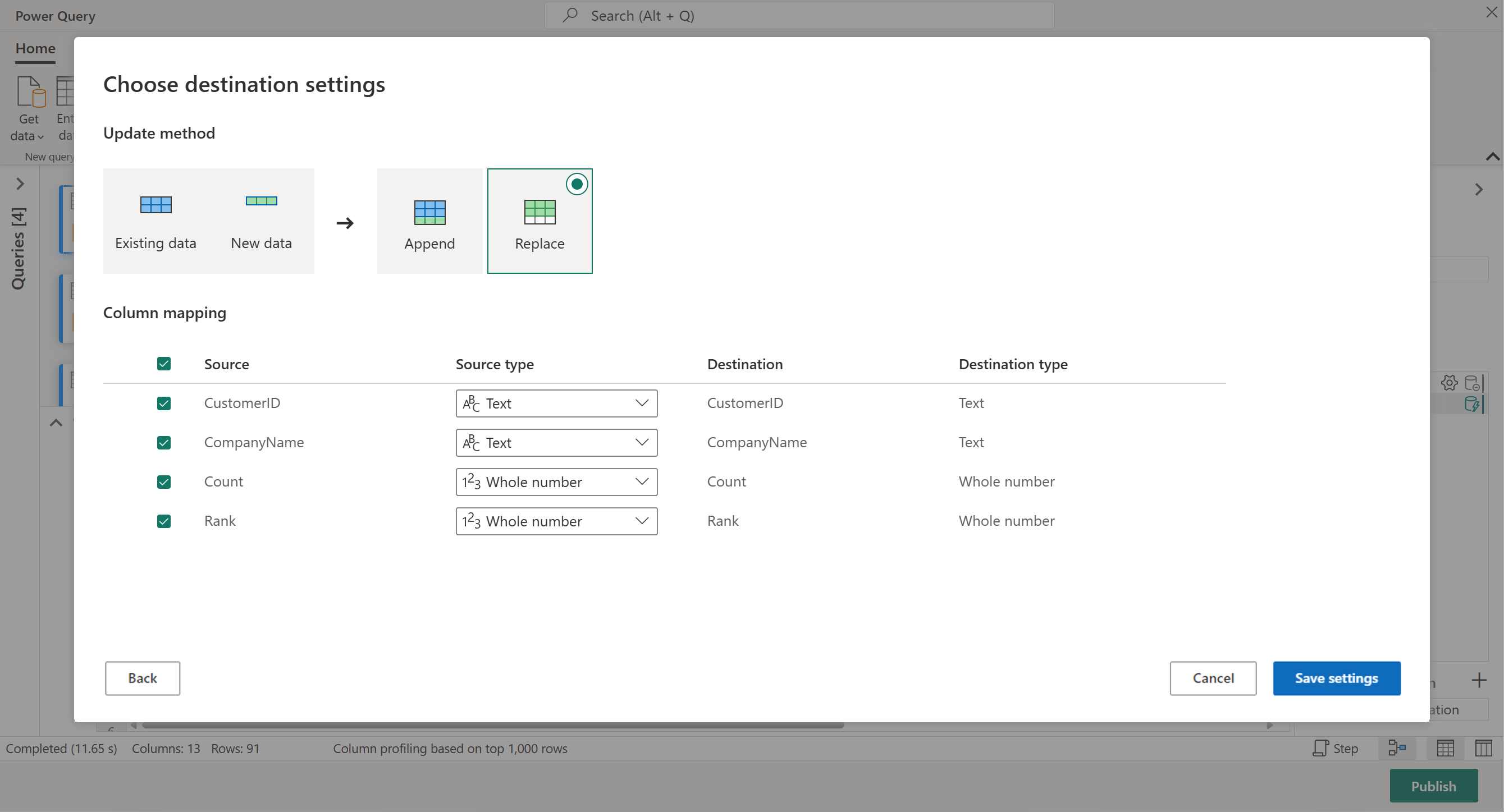
결과가 있는 경우 레이크하우스로 결과를 보내거나, 그렇지 않은 경우 이 단계를 건너뛸 수 있습니다. 여기서는 데이터에 사용할 레이크하우스 및 테이블을 선택하고 새 데이터를 추가할지(추가) 또는 해당 데이터 바꾸기(바꾸기)를 선택할 수 있습니다.
이제 데이터 흐름을 게시할 준비가 되었습니다. 다이어그램 보기에서 쿼리를 검토한 다음 게시를 선택합니다.
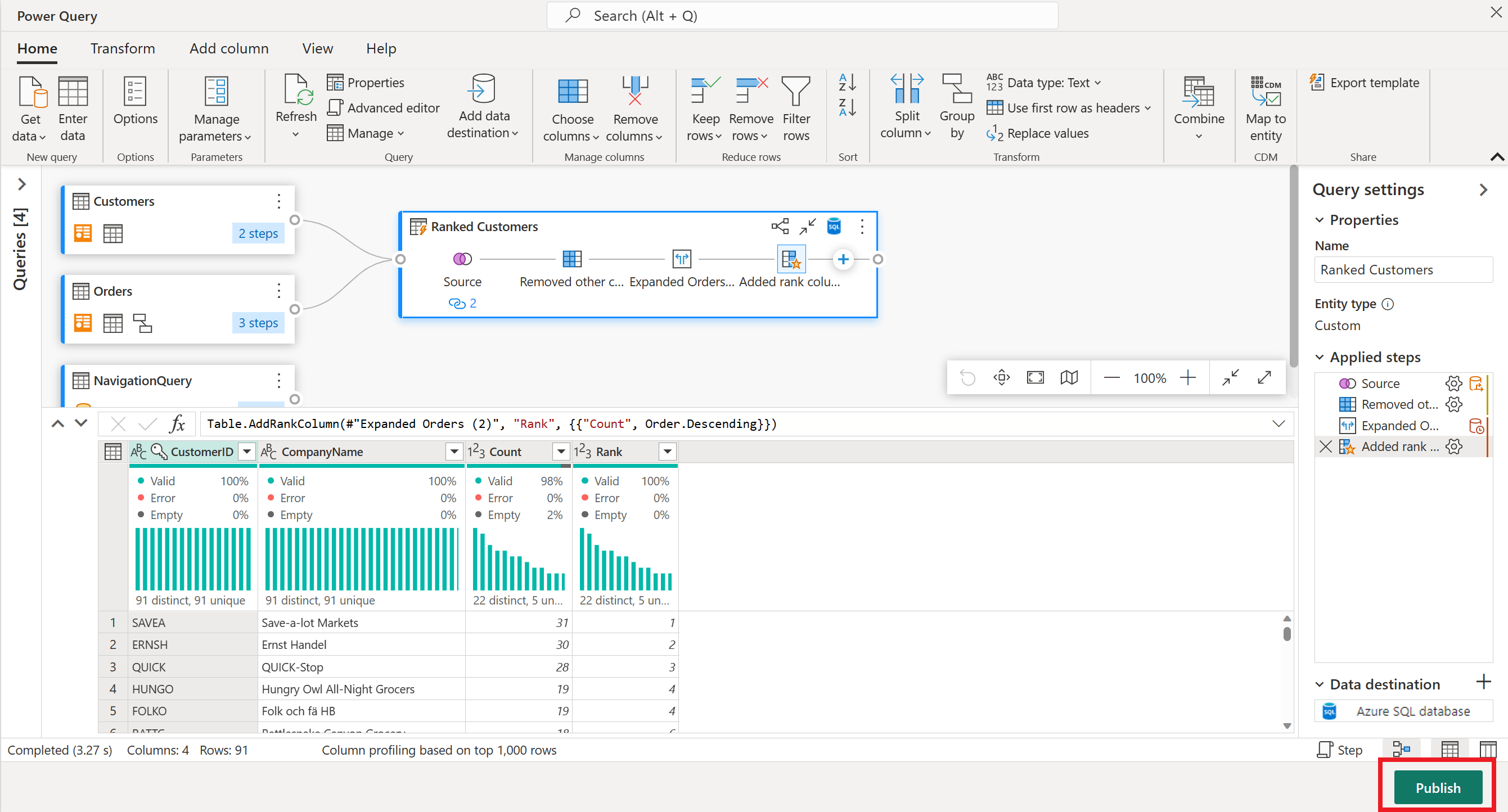
오른쪽 아래 모서리에서 게시 를 선택하여 데이터 흐름을 저장합니다. 작업 영역으로 돌아가면, 데이터 흐름 이름 옆에 있는 회전체 아이콘이 게시 중임을 나타냅니다. 스피너가 사라지면 데이터 흐름을 새로 고칠 준비가 된 것입니다.
중요합니다
작업 영역에서 Dataflow Gen2를 처음 만들 때 Fabric 데이터 흐름 실행에 도움이 되는 일부 백그라운드 항목(Lakehouse 및 Warehouse)을 설정합니다. 이러한 항목은 작업 영역의 모든 데이터 흐름에서 공유되므로 삭제하면 안 됩니다. 직접 사용할 수 있는 것은 아니며 일반적으로 작업 영역에 표시되지 않지만 Notebook 또는 SQL 분석과 같은 다른 위치에서 볼 수 있습니다. 시작하는
DataflowStaging로 시작하는 이름을 찾아보세요.작업 영역에서 일정 새로 고침 아이콘을 선택합니다.

예약된 새로 고침을 켜고, 다른 시간 추가를 선택하고, 다음 스크린샷과 같이 새로 고침을 구성합니다.
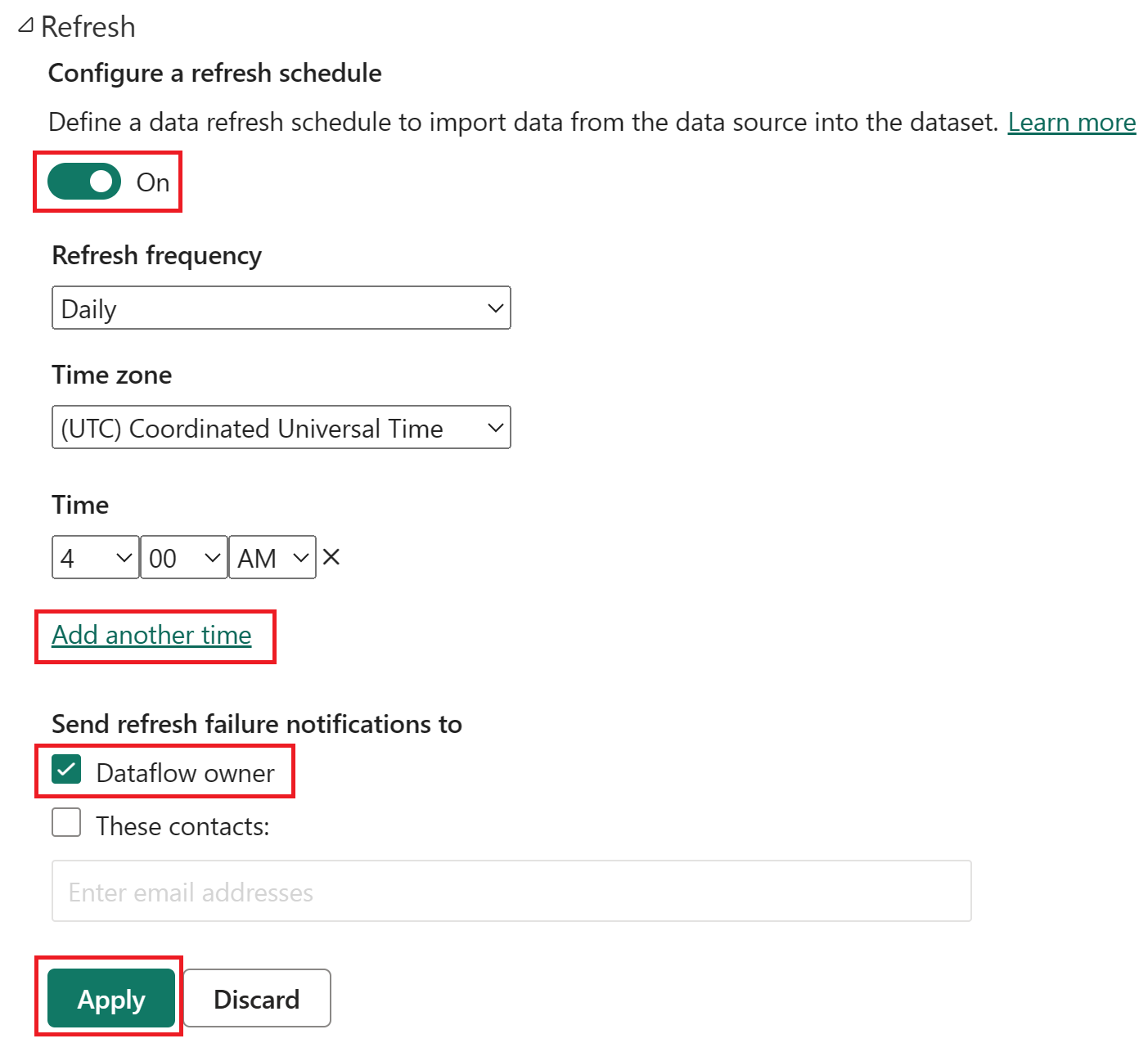
예약된 새로 고침이 켜져 있고 새로 고침 빈도가 매일로 설정되고 표준 시간대가 조정된 세계 시간으로 설정되고 시간이 오전 4:00로 설정된 예약된 새로 고침 옵션의 스크린샷 켜기 단추, 다른 시간 선택 추가, 데이터 흐름 소유자 및 적용 단추가 모두 강조되어 있습니다.













리소스 정리
이 데이터 흐름을 계속 사용하지 않을 경우 다음 단계에 따라 삭제할 수 있습니다.
Microsoft Fabric 작업 영역으로 이동합니다.
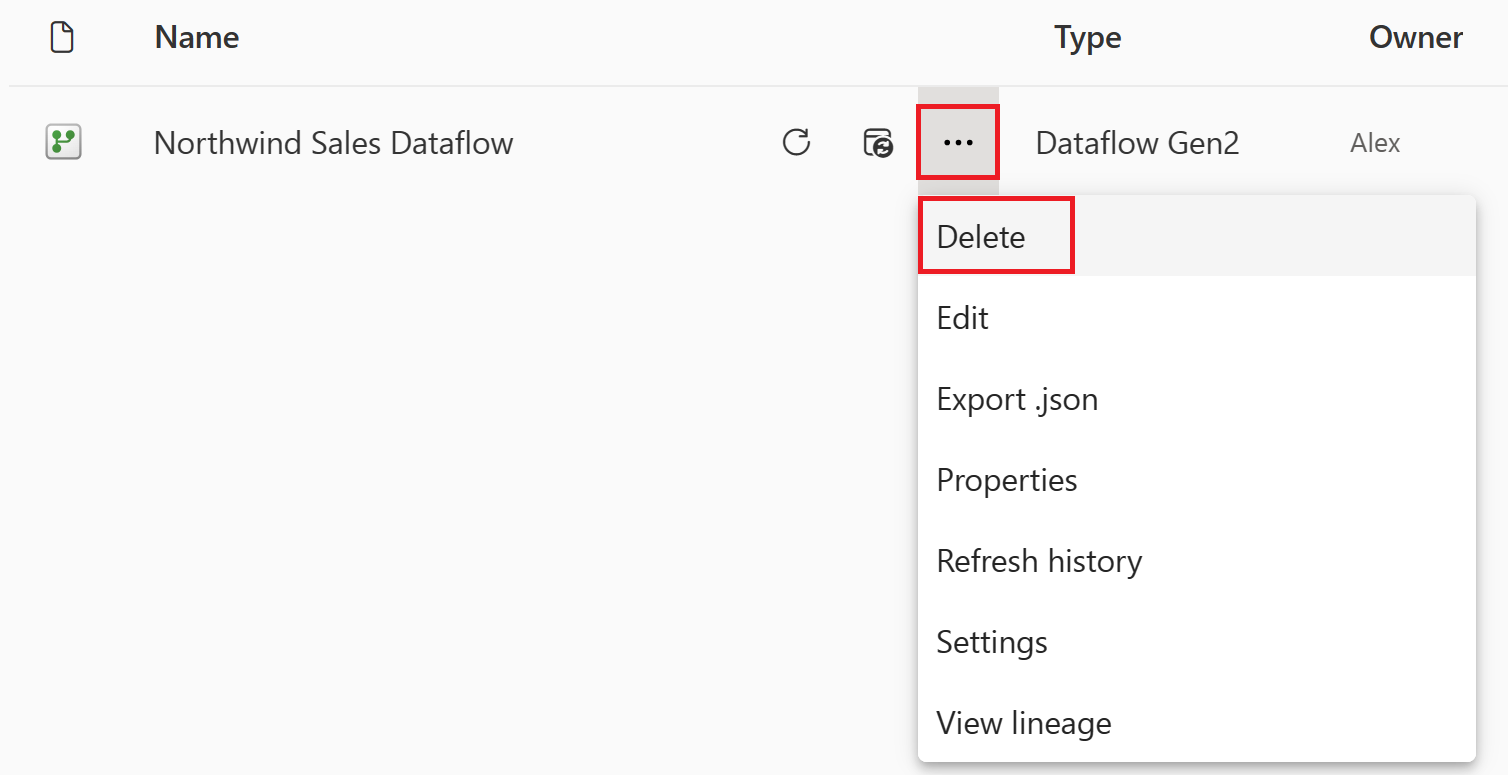
데이터 흐름 이름 옆의 세로 줄임표를 선택한 다음 삭제를 선택합니다.
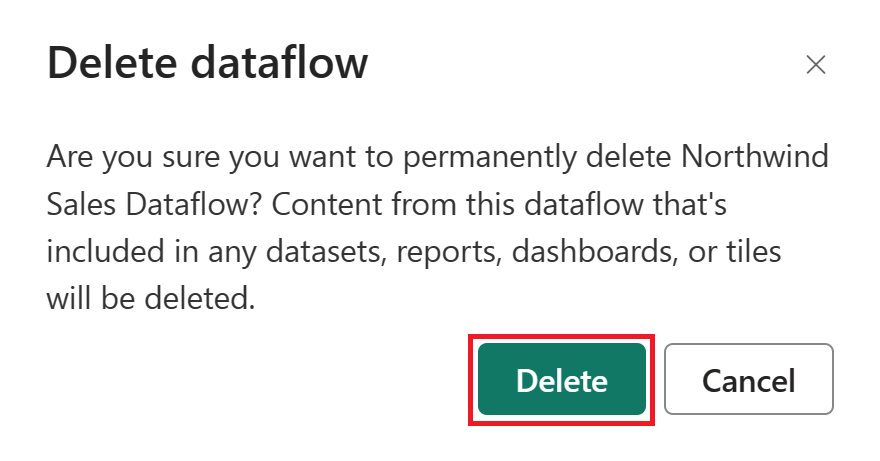
삭제를 선택하여 데이터 흐름의 삭제를 확인합니다.
관련 콘텐츠
이 샘플의 데이터 흐름은 Dataflow Gen2에서 데이터를 로드하고 변환하는 방법을 보여 줍니다. 다음 방법에 대해 알아보았습니다.
- 데이터 흐름 Gen2를 만듭니다.
- 데이터를 변환합니다.
- 변환된 데이터에 대한 대상 설정을 구성합니다.
- 파이프라인을 실행하고 예약합니다.
다음 문서로 이동하여 첫 번째 파이프라인을 만드는 방법을 알아봅니다.