자습서: R을 사용하여 비행 지연 예측
이 자습서에서는 Microsoft Fabric에서 Synapse 데이터 과학 워크플로의 엔드투엔드 예시를 제공합니다. nycflights13 데이터 및 R을 사용하여 비행기가 30분 이상 늦게 도착하는지 여부를 예측합니다. 그런 다음 예측 결과를 사용하여 대화형 Power BI 대시보드를 빌드합니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- tidymodels 패키지(레시피, 파스닙, rsample, 워크플로)를 사용하여 데이터를 처리하고 기계 학습 모델을 학습합니다.
- 출력 데이터를 델타 테이블로 레이크하우스에 씁니다.
- 해당 레이크하우스의 데이터에 직접 액세스하는 Power BI 시각적 개체 보고서 빌드
필수 조건
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈페이지 왼쪽의 환경 전환기를 사용하여 Synapse 데이터 과학 환경으로 전환합니다.

Notebook을 열거나 만듭니다. 방법을 알아보려면 Microsoft Fabric Notebook을 사용하는 방법을 참조하세요.
언어 옵션을 SparkR(R) 로 설정하여 기본 언어를 변경합니다.
레이크하우스에 Notebook을 첨부합니다. 왼쪽에서 추가를 선택하여 기존 레이크하우스를 추가하거나 레이크하우스를 만듭니다.
패키지 설치
이 자습서의 코드를 사용하려면 nycflights13 패키지를 설치합니다.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
데이터 탐색
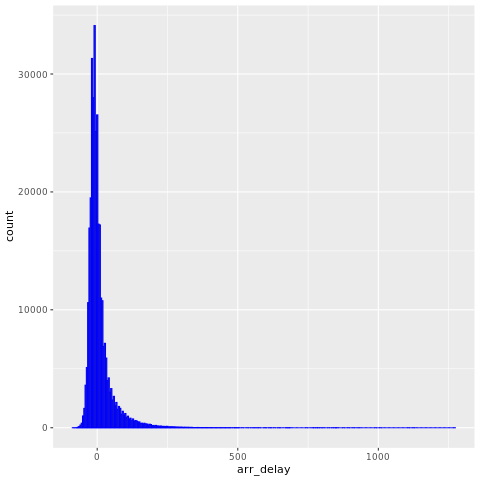
nycflights13 데이터에는 2013년 뉴욕시 근처에 도착한 325,819편의 항공편에 대한 정보가 있습니다. 먼저 비행 지연 분포를 확인합니다. 이 그래프는 도착 지연 분포가 올바르게 기울어진 것을 보여 줍니다. 높은 값에 긴 꼬리가 있습니다.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
데이터를 로드하고 변수를 몇 가지 변경합니다.
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
모델을 빌드하기 전에 전처리 및 모델링 모두에 중요한 몇 가지 특정 변수를 고려합니다.
arr_delay 변수는 요인 변수입니다. 로지스틱 회귀 모델 학습의 경우 결과 변수가 요소 변수인 것이 중요합니다.
glimpse(flight_data)
이 데이터 세트의 항공편 중 약 16%가 30분 이상 늦게 도착했습니다.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
dest 기능에는 104개의 비행 목적지가 있습니다.
unique(flight_data$dest)
16개의 개별 운송업체가 있습니다.
unique(flight_data$carrier)
데이터 분할
단일 데이터 세트를 학습 집합과 테스트 집합의 두 집합으로 분할합니다. 학습 데이터 세트의 원래 데이터 세트(임의로 선택된 하위 집합)에 있는 대부분의 행을 유지합니다. 학습 데이터 세트를 사용하여 모델에 맞고 테스트 데이터 세트를 사용하여 모델 성능을 측정합니다.
rsample 패키지를 사용하여 데이터를 분할하는 방법에 대한 정보가 포함된 개체를 만듭니다. 그런 다음, 두 개의 rsample 함수를 더 사용하여 학습 및 테스트 집합에 대한 DataFrame을 만듭니다.
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
레시피 및 역할 만들기
간단한 로지스틱 회귀 모델에 대한 레시피를 만듭니다. 모델을 학습하기 전에 레시피를 사용하여 새 예측 변수를 만들고 모델에 필요한 전처리를 수행합니다.
update_role() 함수를 사용하여 레시피가 flight 및 time_hour(이)가 변수임과 ID라는 사용자 지정 역할을 가진다는 것을 알도록 합니다. 역할에는 문자 값이 있을 수 있습니다. 이 수식은 arr_delay(을)를 제외한 학습 집합의 모든 변수를 예측 변수로 포함합니다. 이 레시피는 이러한 두 ID 변수를 유지하지만 결과 또는 예측 변수로 사용하지는 않습니다.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
현재 변수 및 역할 집합을 보려면 summary() 함수를 사용합니다.
summary(flights_rec)
기능 만들기
몇 가지 기능 엔지니어링을 수행하여 모델을 개선합니다. 항공편 날짜는 지연 도착 가능성에 적절한 영향을 미칠 수 있습니다.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
모델에 중요할 수 있는 날짜에서 파생된 모델 용어를 추가하는 데 도움이 될 수 있습니다. 단일 날짜 변수에서 다음과 같은 의미 있는 기능을 파생합니다.
- 요일
- 월
- 날짜가 휴일에 해당하는지 여부
레시피에 다음 세 단계를 추가합니다.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
레시피로 모델 맞춤
로지스틱 회귀를 사용하여 비행 데이터를 모델링합니다. 먼저 parsnip 패키지를 사용하여 모델 사양을 빌드합니다.
lr_mod <-
logistic_reg() %>%
set_engine("glm")
workflows 패키지를 사용하여 레시피(flights_rec)와 함께 parsnip 모델(lr_mod)을 번들로 묶습니다.
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
모델 학습
이 함수는 레시피를 준비하고 결과 예측 변수에서 모델을 학습시킬 수 있습니다.
flights_fit <-
flights_wflow %>%
fit(data = train_data)
xtract_fit_parsnip() 및 extract_recipe() 도우미 함수를 사용하고 워크플로에서 모델 또는 레시피 개체를 추출합니다. 이 예제에서는 맞춤 모델 개체를 끌어온 다음 broom::tidy() 함수를 사용하여 모델 계수의 깔끔한 tibble을 가져옵니다.
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
결과 예측
학습된 워크플로(flights_fit)를 사용하여 보이지 않는 테스트 데이터를 사용하여 예측을 만드는 predict()(으)로의 단일 호출입니다. predict() 메서드는 새 데이터에 레시피를 적용한 다음, 해당 결과를 맞춤 모델에 전달합니다.
predict(flights_fit, test_data)
predict()(으)로부터 출력을 가져와서 예측 클래스(late 대 on_time)를 반환합니다. 그러나 각 비행에 대한 예측 클래스 확률에 대해 테스트 데이터와 결합된 모델과 augment()(을)를 함께 사용하여 저장합니다.
flights_aug <-
augment(flights_fit, test_data)
데이터 검토:
glimpse(flights_aug)
모델 평가
이제 예측된 클래스 확률이 있는 tibble이 있습니다. 처음 몇 개의 행에서 모델은 5개의 정시 플라이트(.pred_on_time의 값은 p > 0.50)를 올바르게 예측했습니다. 그러나 총 81,455개의 행을 예측할 수 있습니다.
결과 변수(arr_delay)의 실제 상태에 비해 모델이 지연 도착을 얼마나 잘 예측했는지를 알려주는 메트릭이 필요합니다.
AUC-ROC을 수신자 조작 특성으로 사용합니다. yardstick 패키지에서 roc_curve() 및 roc_auc()와 컴퓨팅합니다.
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
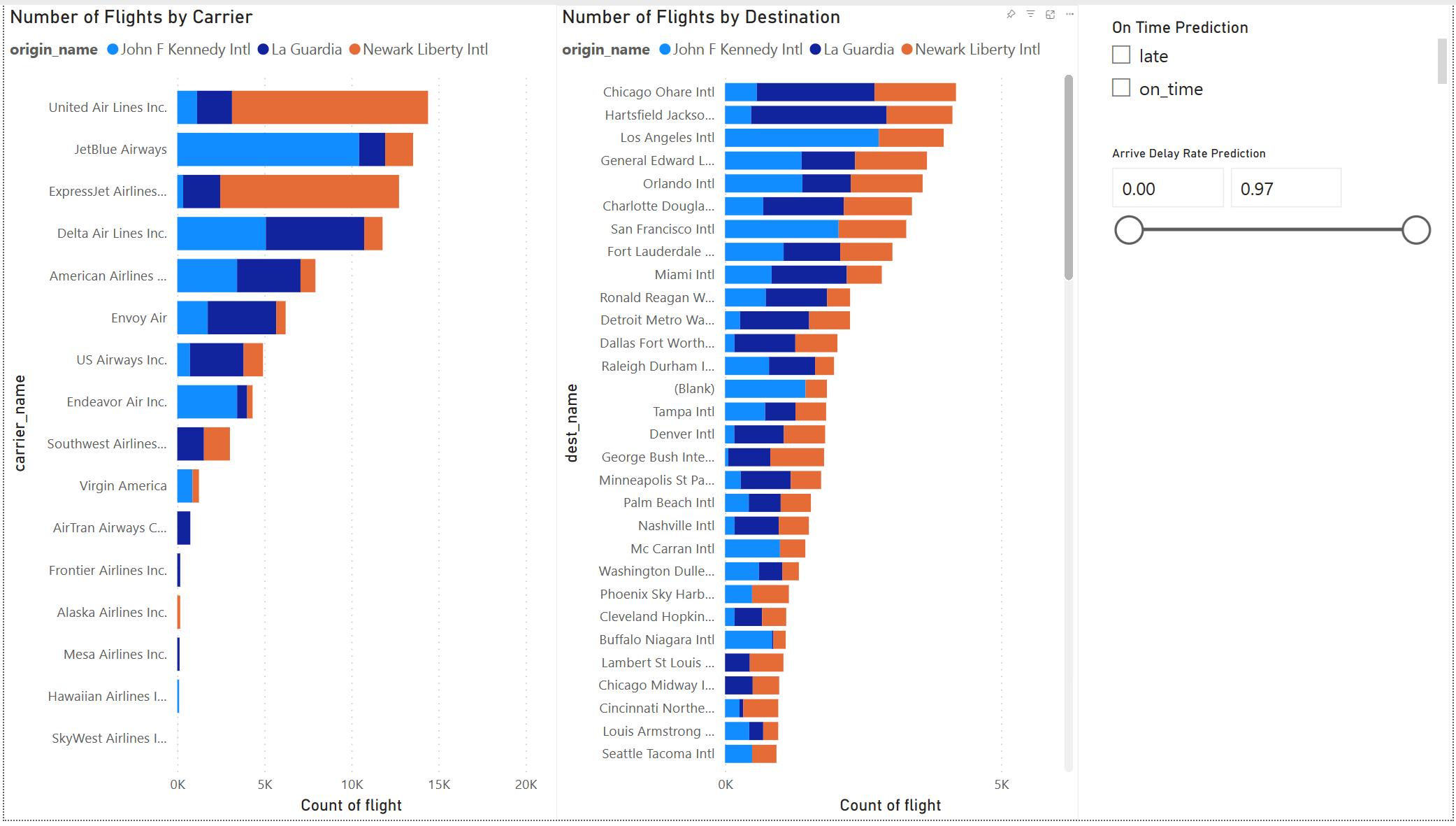
Power BI 보고서 작성
모델 결과가 좋아 보입니다. 플라이트 지연 예측 결과를 사용하여 대화형 Power BI 대시보드를 빌드합니다. 대시보드에는 항공사별 항공편 수와 목적지별 항공편 수가 표시됩니다. 대시보드는 지연 예측 결과를 통해 필터링할 수 있습니다.
예측 결과 데이터 세트에 항공사 이름 및 공항 이름을 포함합니다.
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
데이터 검토:
glimpse(flights_clean)
Spark DataFrame으로 데이터를 변환합니다.
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
레이크하우스의 델타 테이블에 데이터를 씁니다.
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
델타 테이블을 사용하여 의미 체계 모델을 만듭니다.
왼쪽에서 OneLake 데이터 허브를 선택합니다.
Notebook에 첨부한 레이크하우스 선택
열기를 선택합니다.
새 시맨틱 모델을 선택합니다
새 시맨틱 모델에 대해 nycflight13을 선택하고 확인을 선택합니다.
의미 체계 모델이 만들어집니다. 새 보고서를 선택합니다
데이터 및 시각화 창에서 보고서 캔버스로 필드를 선택하거나 끌어 보고서를 작성합니다.
이 구역의 시작 부분에 표시된 보고서를 만들려면 다음 시각화 및 데이터를 사용합니다.
 다음을 가진 스택형 막대형 차트:
다음을 가진 스택형 막대형 차트: - Y축: carrier_name
- X축: 플라이트. 집계는 세기를 선택합니다
- 범례: origin_name
- 다음을 가진 스택형 막대형 차트:
- Y축: dest_name
- X축: 플라이트. 집계는 세기를 선택합니다
- 범례: origin_name
 다음을 가진 슬라이서:
다음을 가진 슬라이서: - 필드: _pred_class
- 다음을 가진 슬라이서:
- 필드: _pred_late