Tidyverse 사용
Tidyverse는 데이터 과학자가 일상적인 데이터 분석에서 일반적으로 사용하는 R 패키지 컬렉션입니다. 여기에는 데이터 가져오기(readr), 데이터 시각화(ggplot2), 데이터 조작(dplyr, tidyr), 함수형 프로그래밍(purrr), 모델 빌드(tidymodels) 등을 위한 패키지가 포함됩니다. tidyverse의 패키지는 원활하게 함께 작동하도록 설계되었으며 일관된 일련의 설계 원칙을 따릅니다.
Microsoft Fabric은 모든 런타임 릴리스에 안정적인 tidyverse 최신 버전을 배포합니다. 익숙한 R 패키지를 가져오고 사용할 수 있습니다.
필수 조건
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈페이지 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

Notebook을 열거나 만듭니다. 방법을 알아보려면 Microsoft Fabric Notebook을 사용하는 방법을 참조하세요.
언어 옵션을 SparkR(R) 로 설정하여 기본 언어를 변경합니다.
레이크하우스에 Notebook을 첨부합니다. 왼쪽에서 추가를 선택하여 기존 레이크하우스를 추가하거나 레이크하우스를 만듭니다.
tidyverse 로드
# load tidyverse
library(tidyverse)
데이터 가져오기
readr은 CSV, TSV, 고정 너비 파일과 같은 사각형 데이터 파일을 읽는 도구를 제공하는 R 패키지입니다.
readr은 CSV 및 TSV 파일을 각각 읽기 위한 함수 read_csv() 및 read_tsv()를 제공하는 등 직사각형 데이터 파일을 읽는 빠르고 사용자 친화적인 방법을 제공합니다.
먼저 R data.frame을 만들고, readr::write_csv()를 사용하여 레이크하우스에 쓰고, readr::read_csv()를 사용하여 다시 읽어 보겠습니다.
참고 항목
readr를 사용하여 레이크하우스 파일에 액세스하려면 파일 API 경로를 사용해야 합니다. 레이크하우스 탐색기에서 액세스하려는 파일 또는 폴더를 마우스 오른쪽 버튼으로 클릭하고 상황별 메뉴에서 해당 파일 API 경로를 복사합니다.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
그런 다음 파일 API 경로를 사용하여 레이크하우스에 데이터를 씁니다.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
레이크하우스에서 데이터를 읽습니다.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
데이터 정리
tidyr은 지저분한 데이터 작업을 위한 도구를 제공하는 R 패키지입니다.
tidyr의 주요 기능은 데이터를 정리된 형식으로 재구성하는 데 도움을 주기 위해 설계되었습니다. 정리된 데이터에는 각 변수가 열이고 각 관찰 사항이 행인 특정 구조를 가지고 있어 R 및 기타 도구에서 데이터를 더 쉽게 사용할 수 있습니다.
예를 들어 gather()의 tidyr 함수를 사용하면 넓은 데이터를 긴 데이터로 변환할 수 있습니다. 예를 들어 다음과 같습니다.
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
함수 프로그래밍
purrr은 함수 및 벡터 작업을 위한 완전하고 일관된 도구 세트를 제공하여 R의 기능 프로그래밍 도구 키트를 향상시키는 R 패키지입니다.
purrr을 시작하기에 가장 좋은 위치는 map()의 함수군으로, 이를 사용하면 많은 for 루프를 더 간결하고 읽기 쉬운 코드로 바꿀 수 있습니다. 다음은 목록의 각 요소에 함수를 적용하는 데 map()을 사용하는 예시입니다.
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
데이터 조작
dplyr은 이름에 따라 변수를 선택하고, 값에 따라 사례를 선택하고, 여러 값을 단일 요약으로 줄이고, 행 순서를 변경하는 것과 같이 가장 일반적인 데이터 조작 문제를 해결하는 데 도움이 되는 일관된 동사 세트를 제공하는 R 패키지입니다. 다음은 몇 가지 예시입니다.
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
데이터 시각화
ggplot2는 The Grammar of Graphics를 기반으로 그래픽을 선언적으로 만들기 위한 R 패키지입니다. 사용자가 데이터를 제공하고, ggplot2에 변수를 미학에 어떻게 매핑할지, 어떤 그래픽 기본 요소를 사용할지 알려주면 가 세부 사항을 처리합니다. 다음 몇 가지 예를 참조하세요.
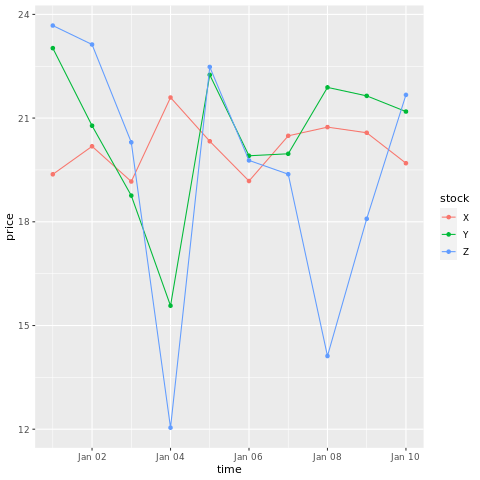
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
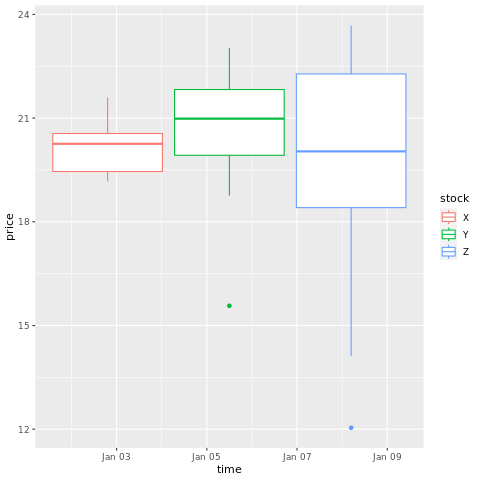
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
모델 빌드
tidymodels 프레임워크는 tidyverse 원칙을 사용하는 모델링 및 기계 학습을 위한 패키지 컬렉션입니다. 학습/테스트 데이터 세트 샘플 분할을 위한 rsample, 모델 사양을 위한 parsnip, 데이터 전처리를 위한 recipes, 모델링 워크플로를 위한 workflows, 하이퍼파라미터 튜닝을 위한 tune, 모델 평가를 위한 yardstick, 모델 출력 분석을 위한 broom, 튜닝 매개변수 관리를 위한 dials 등 다양한 모델 빌드 작업을 위한 핵심 패키지 목록을 다룹니다.
tidymodels 웹 사이트를 방문하여 패키지에 대해 자세히 알아볼 수 있습니다. 다음은 자동차의 중량(wt)에 따라 연비(mpg)를 예측하는 선형 회귀 모델을 빌드하는 예시입니다.
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
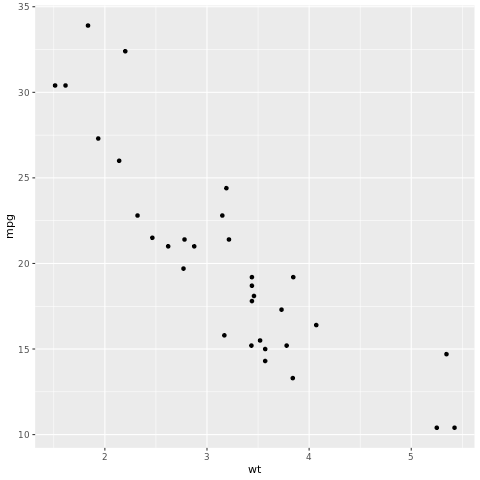
산점도에서 관계는 대략 선형으로 보이고 분산은 상수로 보입니다. 선형 회귀를 사용하여 이를 모델링해 보겠습니다.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
선형 회귀 모델을 적용하여 테스트 데이터 세트에서 예측합니다.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
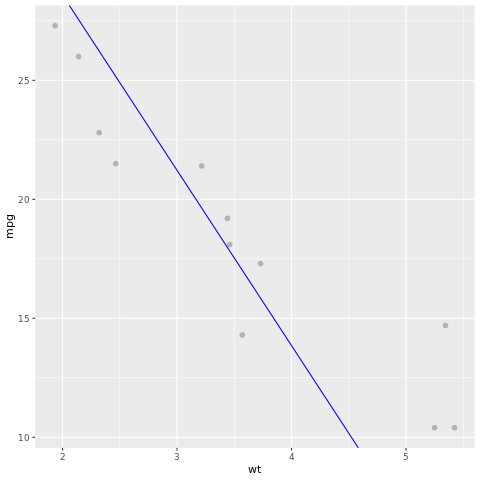
모델 결과를 살펴보겠습니다. 모델을 꺾은선형 차트로, 그리고 테스트 그라운드 진리 데이터를 동일한 차트의 점으로 그릴 수 있습니다. 모델이 양호해 보입니다.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")