이 자습서에서는 4부에서 생성한 예측 데이터에서 Power BI 보고서를 작성합니다. 일괄 처리 채점을 수행하고 예측을 Lakehouse에 저장합니다.
당신은 다음을 배우게 됩니다:
- 예측 데이터에서 의미 체계 모델 만들기
- Power BI에서 데이터에 새 측정값 추가
- Power BI 보고서 만들기
- 시각화 요소를 보고서에 추가
필수 조건
Microsoft Fabric 구독을 받으세요. 또는 무료 Microsoft Fabric 평가판 등록합니다.
Microsoft Fabric 로그인합니다.
홈 페이지의 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

이 자습서는 자습서 시리즈의 5부 중 5부입니다. 이 자습서를 완료하려면 먼저 다음을 완료합니다.
- 1부: Apache Spark를 사용하여 데이터를 Microsoft Fabric 레이크하우스로 가져오기.
- Part 2: Microsoft Fabric Notebook을 사용하여 데이터를 탐색하고 시각화하여 데이터에 대해 자세히 알아봅니다.
- Part 3: machine learning 모델 학습 및 등록.
- 4부: 일괄 처리 채점 수행 및 레이크하우스에 예측 저장
의미 체계 모델 만들기
4부에서 생성한 예측 데이터에 연결된 새 의미 체계 모델을 만듭니다.
왼쪽에서 작업 영역을 선택합니다.
다음 스크린샷과 같이 오른쪽 위에서 필터로 Lakehouse 를 선택합니다.
다음 스크린샷과 같이 자습서 시리즈의 이전 부분에서 사용한 레이크하우스를 선택합니다.
다음 스크린샷과 같이 위쪽 리본에서 새 의미 체계 모델을 선택합니다.
의미 체계 모델에 이름(예: "은행 변동 예측")을 지정합니다. 그런 다음, 다음 스크린샷과 같이 customer_churn_test_predictions 데이터 세트를 선택합니다.
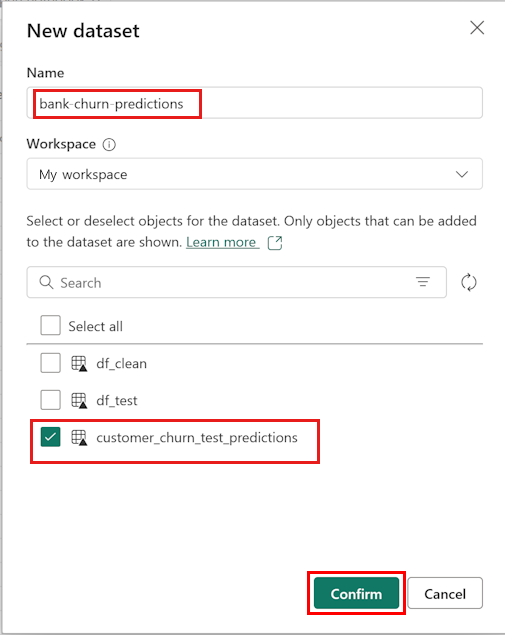
확인을 선택합니다.




새 측정값 추가
의미 체계 모델에 몇 가지 측정값을 추가합니다.
이탈률에 대한 새 측정값을 추가합니다.
다음 위쪽 리본에서 새 측정값을 선택합니다. 이 작업은 customer_churn_test_predictions 데이터 세트에 Measure라는 새 항목을 추가하고 다음 스크린샷과 같이 표 위에 수식 입력줄을 엽니다.
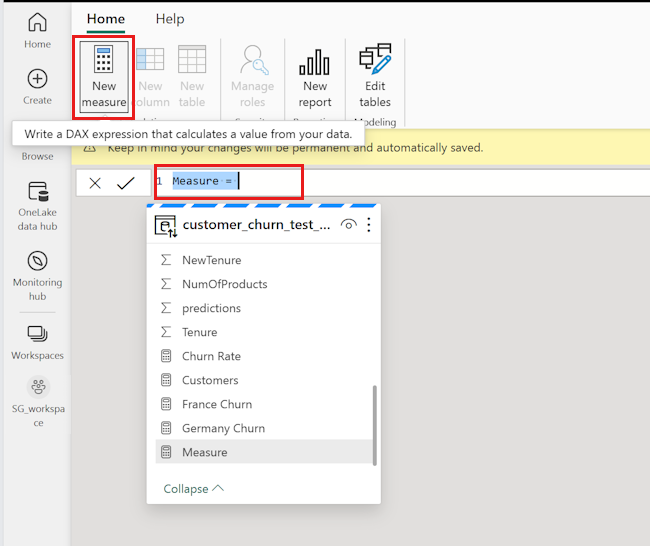
평균 예측 이탈률을 계산하려면 수식 입력줄에서
Measure =를 다음 코드 조각으로 대체하십시오.Churn Rate = AVERAGE(customer_churn_test_predictions[predictions])수식을 적용하려면 다음 스크린샷과 같이 수식 입력줄에서 확인 표시를 선택합니다.
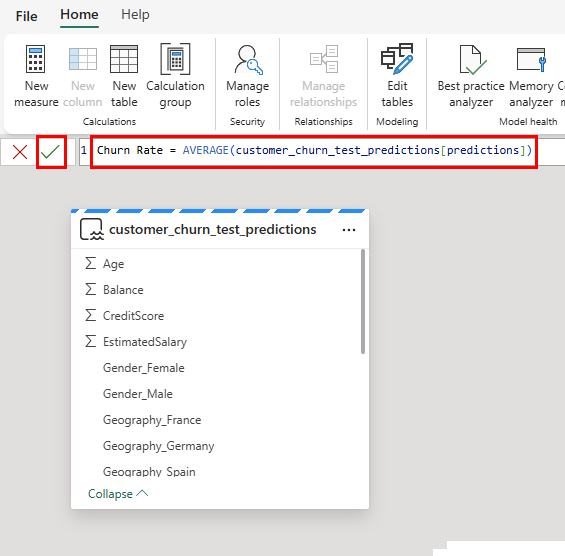
다음 스크린샷과 같이 새 측정값이 데이터 테이블에 나타납니다.
 계산기 아이콘은 측정값으로 생성되었음을 나타냅니다. 데이터 테이블에서 변동률 측정값을 선택합니다. 다음으로, 다음 스크린샷과 같이 다음을 선택합니다.
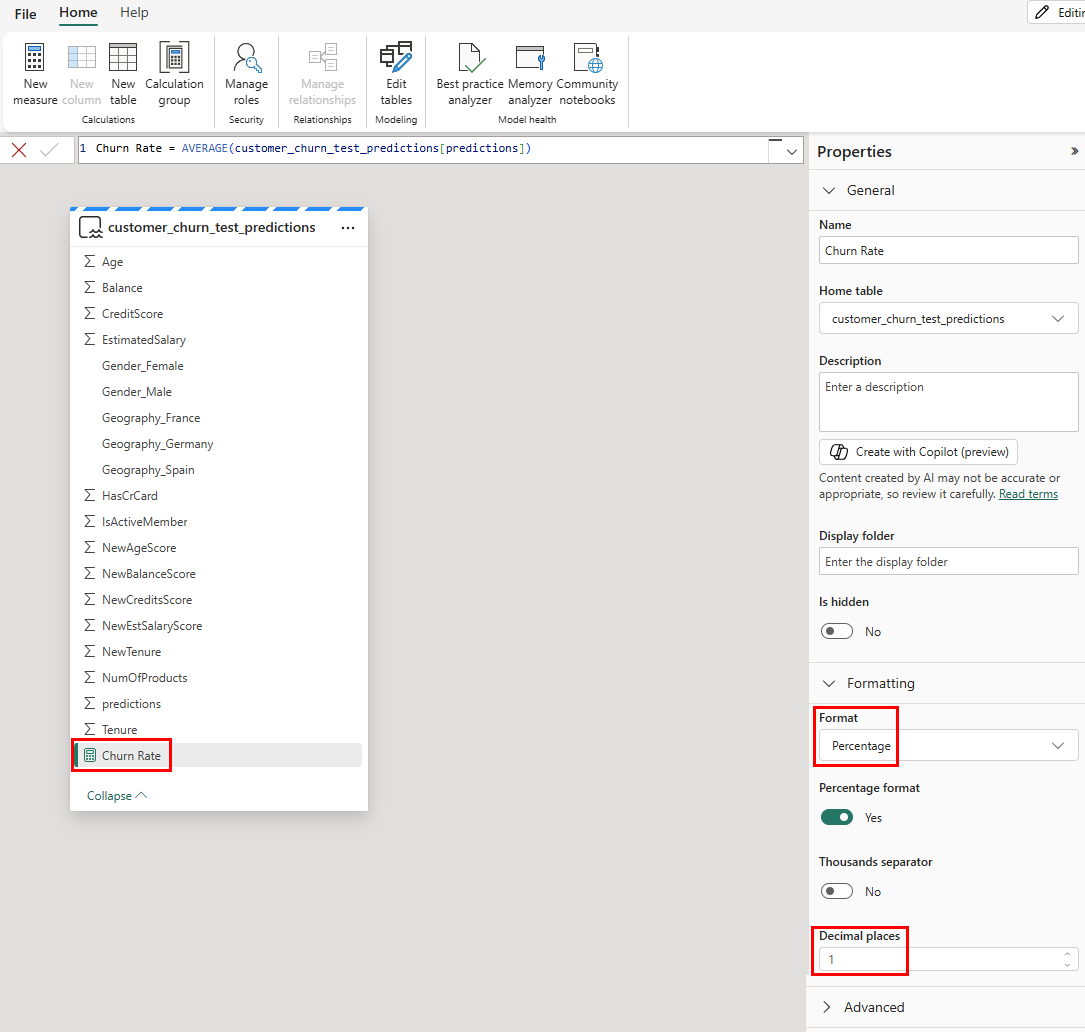
계산기 아이콘은 측정값으로 생성되었음을 나타냅니다. 데이터 테이블에서 변동률 측정값을 선택합니다. 다음으로, 다음 스크린샷과 같이 다음을 선택합니다.속성 패널에서 서식을 일반에서 백분율로 변경합니다.
속성 패널에서 아래로 스크롤하여 소수점 자릿수를 1로 변경합니다.
총 은행 고객 수를 계산하는 새 측정값을 추가합니다. 다른 새로운 조치에는 그것이 필요합니다.
상단 리본에서 새 측정값을 선택하여 데이터 세트에 측정값이라는
customer_churn_test_predictions을 추가합니다. 이 작업을 수행하면 표 위에 수식 입력줄이 열립니다.각 예측은 하나의 고객을 나타냅니다. 총 고객 수를 확인하려면 수식 입력줄에서
Measure =을 바꿉니다.Customers = COUNT(customer_churn_test_predictions[predictions])수식을 적용하려면 수식 입력줄에서 확인 표시를 선택합니다.
독일의 이탈률을 추가하세요.
상단 리본에서 새 측정값을 선택하여 데이터 세트에 측정값이라는
customer_churn_test_predictions을 추가합니다. 이 작업을 수행하면 표 위에 수식 입력줄이 열립니다.독일의 이탈률을 확인하려면 수식 입력줄에서
Measure =을 다음으로 바꿉니다.Germany Churn = CALCULATE(AVERAGE(customer_churn_test_predictions[predictions]),FILTER(customer_churn_test_predictions, customer_churn_test_predictions[Geography_Germany] = TRUE()))이 구문은 지리 항목이 독일로 설정된 행(Geography_Germany가 1과 같은 경우)을 추출합니다.
수식을 적용하려면 수식 입력줄에서 확인 표시를 선택합니다.
이전 단계를 반복하여 프랑스와 스페인의 변동률을 추가합니다.
스페인의 이탈률:
Spain Churn = CALCULATE(AVERAGE(customer_churn_test_predictions[predictions]),FILTER(customer_churn_test_predictions, customer_churn_test_predictions[Geography_Spain] = TRUE()))프랑스의 이탈률:
France Churn = CALCULATE(AVERAGE(customer_churn_test_predictions[predictions]),FILTER(customer_churn_test_predictions, customer_churn_test_predictions[Geography_France] = TRUE()))




새 보고서 만들기
앞에서 설명한 모든 작업을 완료한 후 맨 위 리본 파일 옵션 목록에서 새 보고서 만들기를 선택하여 다음 스크린샷과 같이 Power BI 보고서 작성 페이지를 엽니다.

보고서 페이지가 새 브라우저 탭에 나타납니다. 보고서에 다음 시각적 개체를 추가합니다.
다음 스크린샷과 같이 위쪽 리본에서 텍스트 상자를 선택합니다.
보고서의 제목(예: 다음 스크린샷과 같이 "은행 고객 변동")을 입력합니다.

서식 패널에서 글꼴 크기와 배경색을 변경합니다. 텍스트를 선택하고 서식 표시줄을 사용하여 글꼴 크기와 색상을 조정합니다.
시각화 패널에서 다음 스크린샷과 같이 카드 아이콘을 선택합니다.
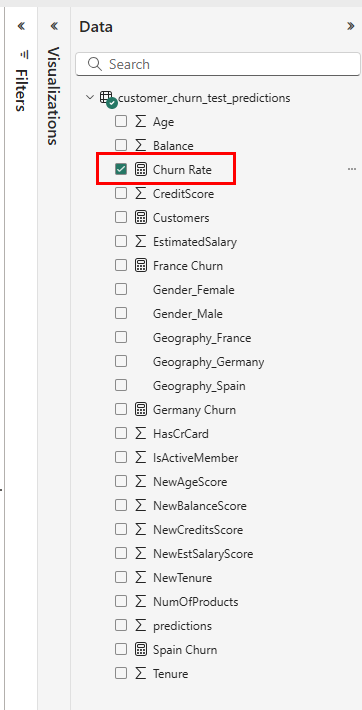
다음 스크린샷과 같이 데이터 창에서 변동률을 선택합니다.
다음 스크린샷과 같이 서식 패널에서 글꼴 크기와 배경색을 변경합니다.
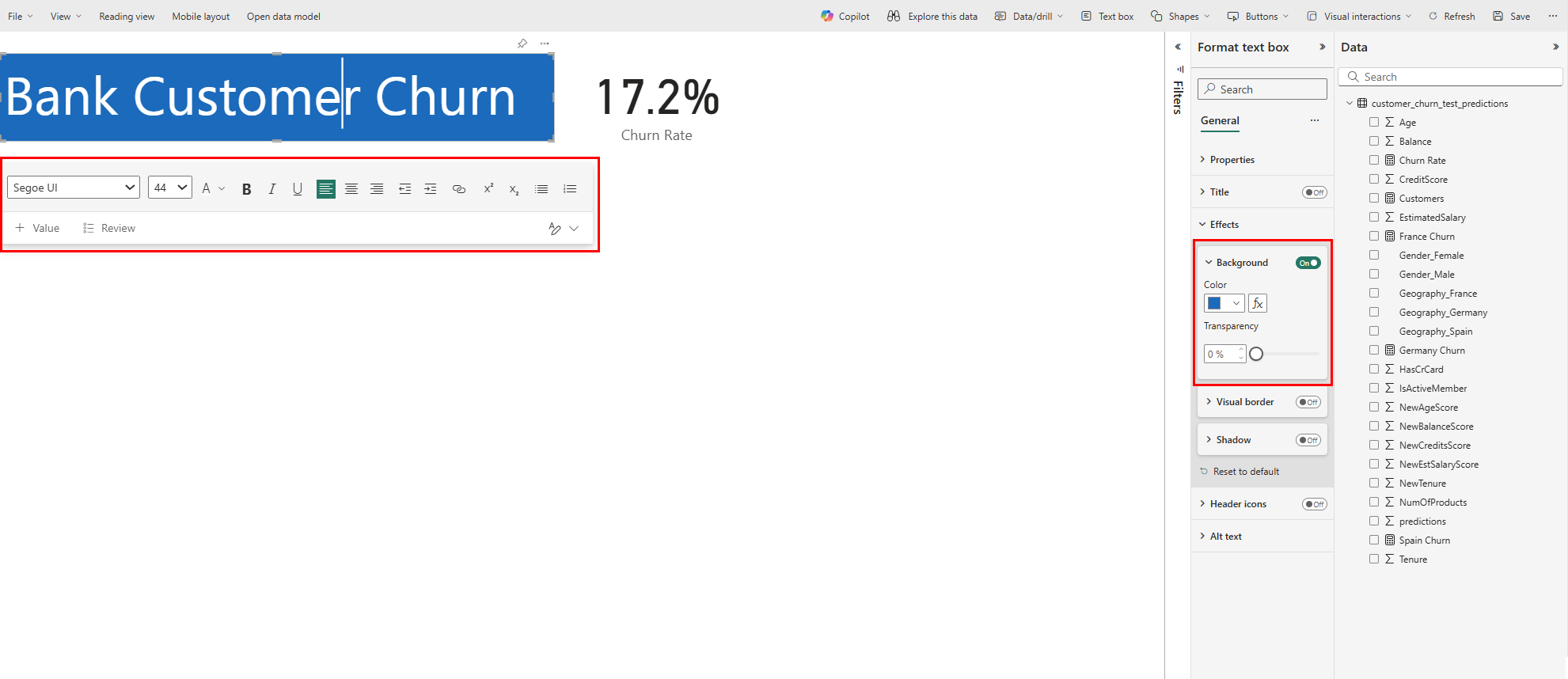
다음 스크린샷과 같이 이탈률 카드를 리포트의 오른쪽 상단으로 드래그합니다.
시각화 패널에서 다음 스크린샷과 같이 꺾은선형 및 누적 세로 막대형 차트를 선택합니다.
차트는 보고서에 표시됩니다. 데이터 창에서 선택합니다
- 나이
- 이탈률
- 고객
다음 스크린샷에 표시된 대로:
다음 스크린샷과 같이 꺾은선형 및 누적 세로 막대형 차트를 구성합니다.
- 데이터 창에서 시각화 창의 X축 필드로 나이 끌기
- 데이터 창에서 시각화 창의 선 y축 필드로 고객을 끌어옵니다.
- 데이터 창에서 시각화 창의 열 y축 필드로 변동률 끌기
열 y축 필드에 변동률 인스턴스가 하나만 있는지 확인합니다. 이 필드에서 다른 모든 항목을 삭제합니다.
시각화 창에서 선형 및 누적 세로 막대형 차트 아이콘을 선택합니다. 이전 선 및 누적 세로 막대형 차트 구성을 따라, 다음 스크린샷과 같이 x축의 NumOfProducts를, 열 y축의 이탈률을, 선 y축의 고객 수를 선택합니다.
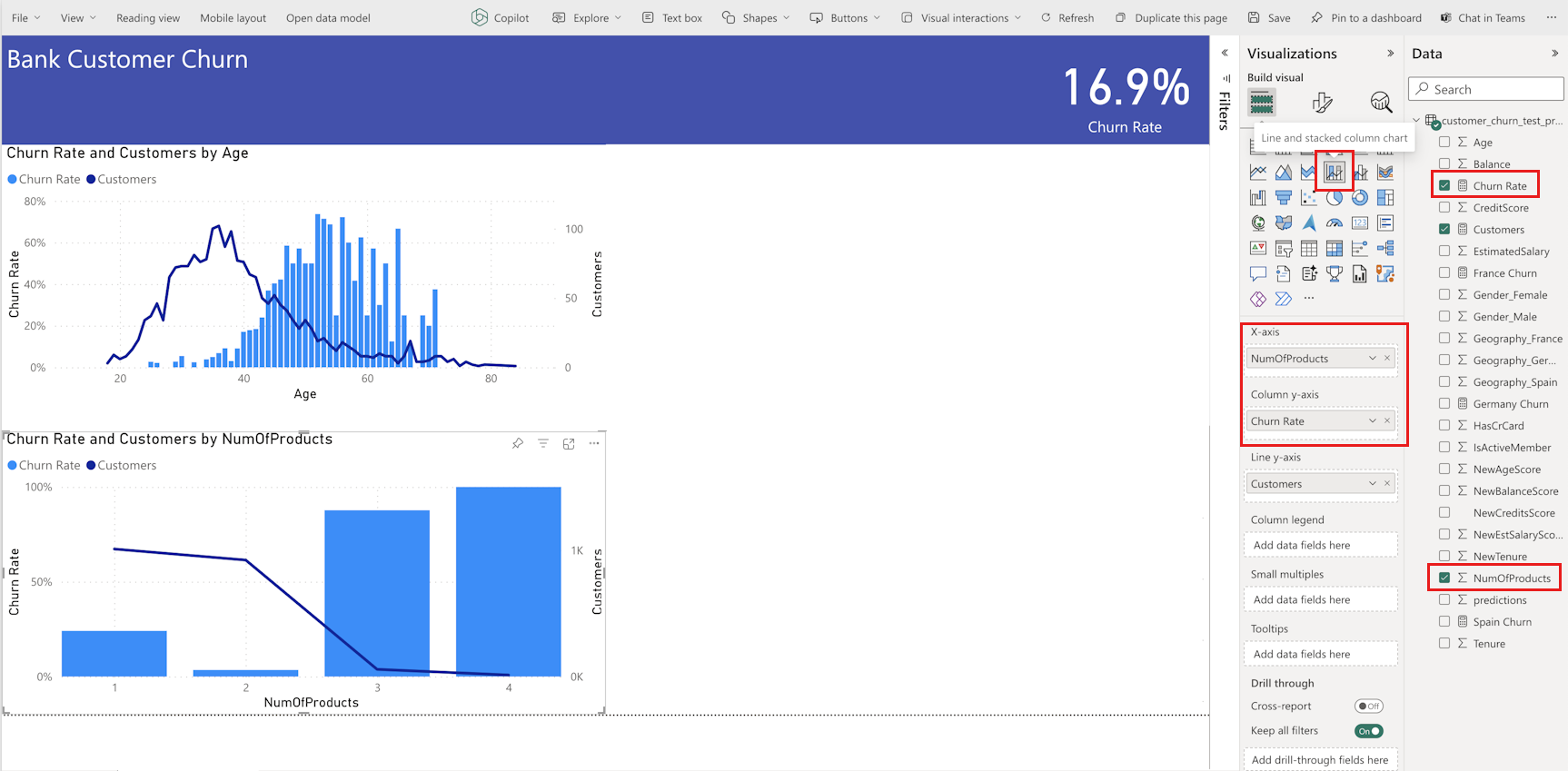
시각화 패널에서 두 차트의 오른쪽을 왼쪽으로 이동하여 두 개의 차트를 더 사용할 수 있는 공간을 만듭니다. 그런 다음 누적 세로 막대형 차트 아이콘을 선택합니다. 다음 스크린샷과 같이 x축에 대해 NewCreditsScore 를 선택하고 y축의 변동률을 선택합니다.
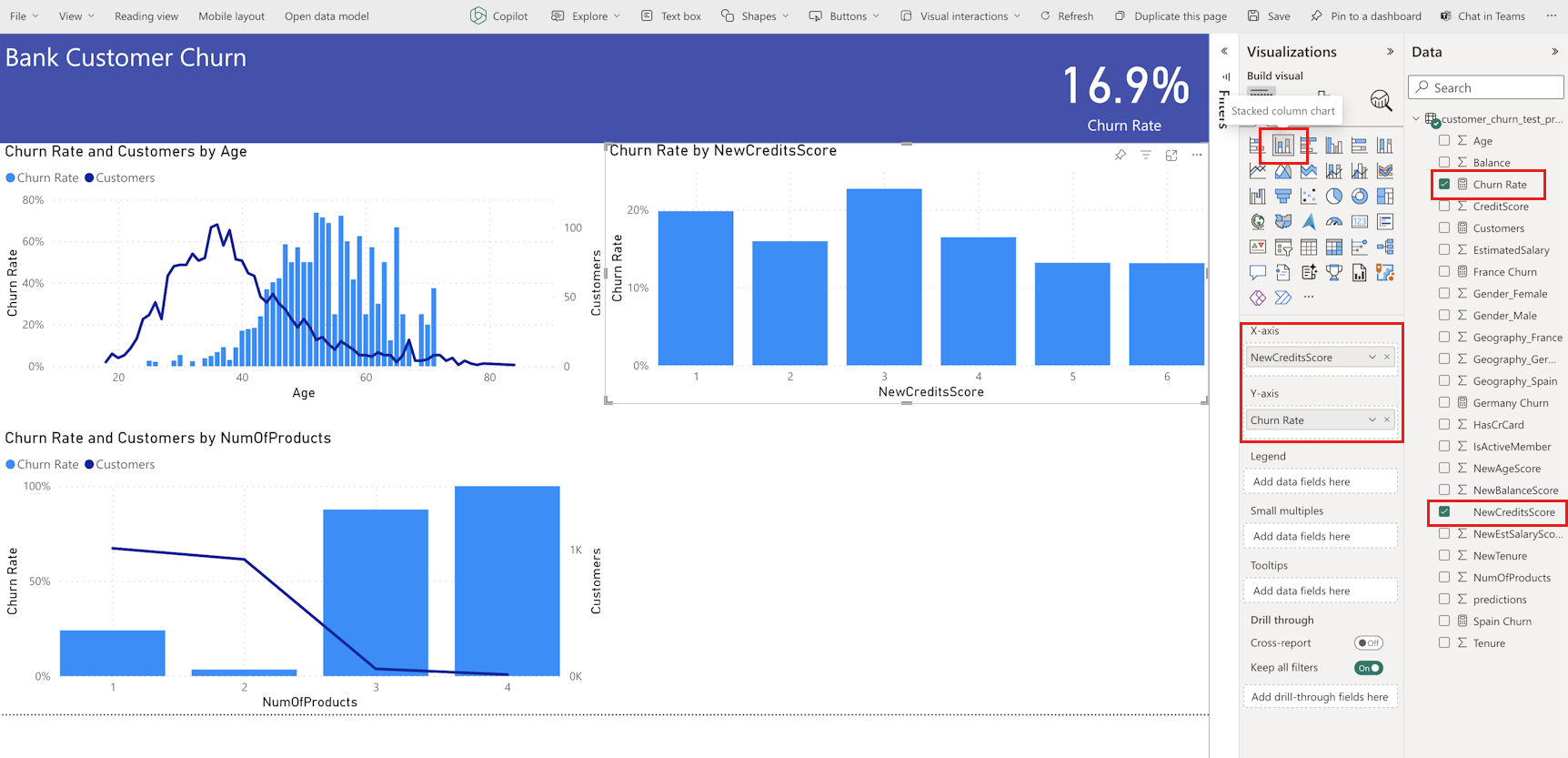
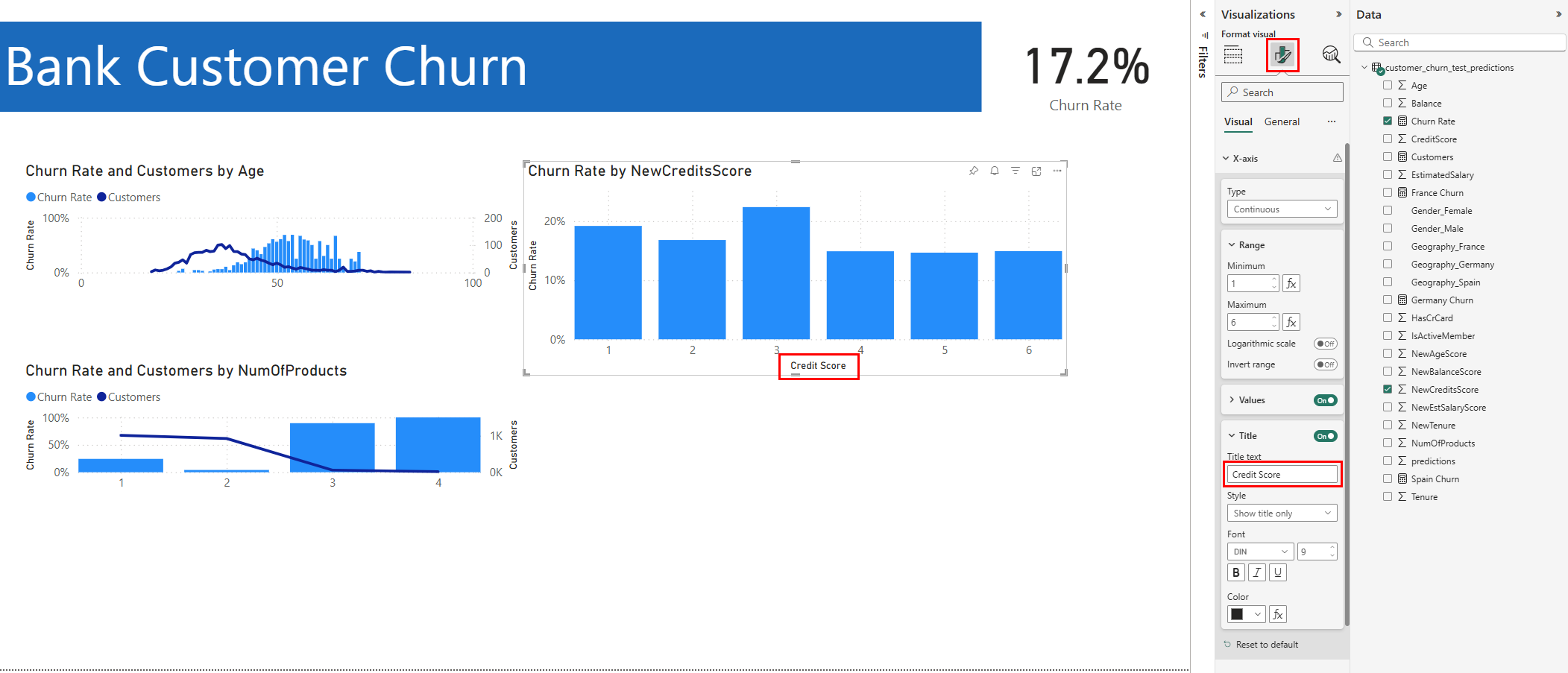
다음 스크린샷과 같이 서식 패널에서 제목 "NewCreditsScore"를 "크레딧 점수"로 변경합니다. 이 단계에서는 차트의 x축 크기를 확장해야 할 수 있습니다.
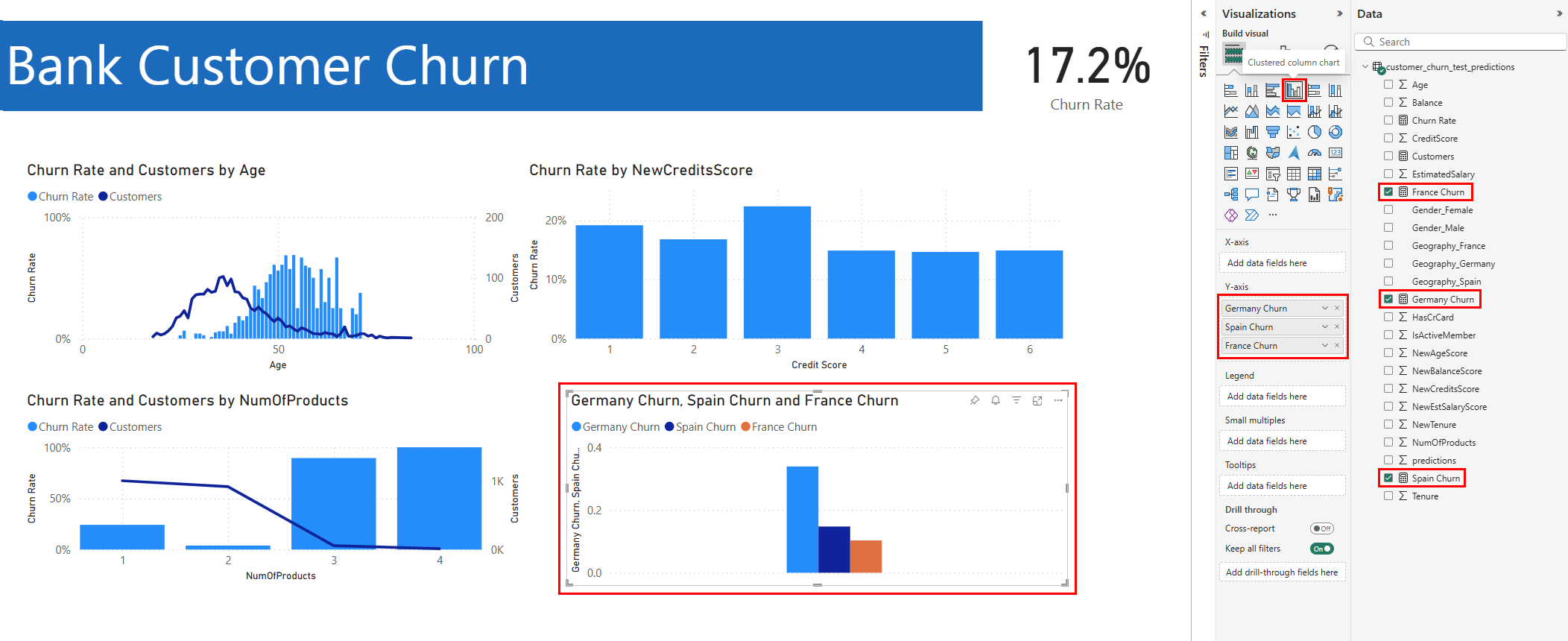
시각화 패널에서 묶은 세로 막대형 차트를 선택합니다. 다음 스크린샷과 같이 y축에 대해 해당 순서대로 독일 변동, 스페인 변동, 프랑스 변동 을 선택합니다. 필요에 따라 개별 보고서 차트의 크기를 조정합니다.












참고 사항
이 자습서에서는 Power BI에서 저장된 예측 결과를 분석하는 방법을 설명합니다. 그러나 주제별 전문 지식에 따라 실제 고객 이탈 사용 사례는 보고서에 필요한 특정 시각화에 대한 보다 자세한 계획이 필요할 수 있습니다. 비즈니스 분석 팀과 회사가 표준화된 메트릭을 설정한 경우 해당 메트릭도 계획의 일부가 되어야 합니다.
Power BI 보고서에는 다음이 표시됩니다.
- 은행 상품 중 두 개 이상을 사용하는 은행 고객은 변동률이 높지만 두 개 이상의 제품을 가진 고객은 거의 없습니다. 은행은 더 많은 데이터를 수집하고 더 많은 제품과 상관 관계가 있는 다른 기능을 조사해야 합니다(왼쪽 아래 패널에서 플롯 검토).
- 독일의 은행 고객은 프랑스와 스페인의 고객에 비해 이탈률이 높습니다(오른쪽 아래 패널에서 플롯 검토). 이러한 변동률은 고객이 떠나도록 유도한 요인에 대한 조사가 도움이 될 수 있음을 시사합니다.
- 중년 고객(25~45세)이 더 많고, 45~60세 고객은 더 떠나는 경향이 있습니다.
- 마지막으로 신용 점수가 낮은 고객은 다른 금융 기관을 위해 은행을 떠날 가능성이 큽니다. 은행은 신용 점수와 계좌 잔액이 낮은 고객이 은행에 머물도록 장려하는 방법을 찾아야 합니다.
다음 단계
이 자습서 시리즈는 완료되었습니다. 다른 엔드 투 엔드 샘플 자습서는 다음을 참조하세요.