이 자습서에서는 GX( Great Expectations )와 함께 SemPy를 사용하여 Power BI 의미 체계 모델에서 데이터 유효성 검사를 수행하는 방법을 알아봅니다.
이 자습서에서는 다음 방법을 보여줍니다.
- Great Expectation의 패브릭 데이터 원본(의미 체계 링크 기반)을 사용하여 패브릭 작업 영역의 데이터 세트에 대한 제약 조건의 유효성을 검사합니다.
- GX 데이터 컨텍스트, 데이터 자산 및 기대치를 구성합니다.
- GX 검사점을 사용하여 유효성 검사 결과를 봅니다.
- 의미 체계 링크를 사용하여 원시 데이터를 분석합니다.
Prerequisites
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈 페이지의 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

- 왼쪽 탐색 창에서 작업 영역을 선택하여 작업 영역을 찾아 선택합니다. 이 작업 영역은 현재 작업 영역이 됩니다.
- 소매 분석 샘플 PBIX.pbix 파일을 다운로드합니다.
- 작업 영역에서 가져오기>보고서 또는 페이지를 매긴 보고서>이 컴퓨터에서를 선택하여 소매 분석 샘플 PBIX.pbix 파일을 작업 영역에 업로드합니다.
노트북에서 내용을 따라하세요
great_expectations_tutorial.ipynb 는 이 자습서와 함께 제공되는 Notebook입니다.
이 자습서에 대해 함께 제공되는 노트북을 열기 위해서는 데이터 과학 자습서를 위한 시스템 준비 설명에 따라 노트북을 작업공간으로 가져옵니다.
이 페이지에서 코드를 복사하여 붙여넣으려는 경우 새 Notebook을 만들 수 있습니다.
코드를 실행하기 전에 노트북에 레이크하우스를 연결해야 합니다.
Notebook 설정
이 섹션에서는 필요한 모듈 및 데이터를 사용하여 Notebook 환경을 설정합니다.
- PyPI에서
SemPy및 해당Great Expectations라이브러리를 Notebook 내의%pip인라인 설치 기능을 사용하여 설치합니다.
# install libraries
%pip install semantic-link 'great-expectations<1.0' great_expectations_experimental great_expectations_zipcode_expectations
# load %%dax cell magic
%load_ext sempy
- 나중에 필요한 모듈의 필요한 가져오기를 수행합니다.
import great_expectations as gx
from great_expectations.expectations.expectation import ExpectationConfiguration
from great_expectations_zipcode_expectations.expectations import expect_column_values_to_be_valid_zip5
GX 데이터 컨텍스트 및 데이터 원본 설정
큰 기대를 시작하려면 먼저 GX 데이터 컨텍스트를 설정해야 합니다. 컨텍스트는 GX 작업의 진입점 역할을 하며 모든 관련 구성을 보유합니다.
context = gx.get_context()
이제 이 컨텍스트에 패브릭 데이터 세트를 데이터 원본 으로 추가하여 데이터와 상호 작용을 시작할 수 있습니다. 이 자습서에서는 표준 Power BI 샘플 의미 체계 모델 소매 분석 샘플 .pbix 파일을 사용합니다.
ds = context.sources.add_fabric_powerbi("Retail Analysis Data Source", dataset="Retail Analysis Sample PBIX")
데이터 자산 지정
작업하려는 데이터의 하위 집합을 지정하도록 데이터 자산을 정의합니다. 자산은 전체 테이블만큼 간단하거나 DAX(사용자 지정 데이터 분석 식) 쿼리만큼 복잡할 수 있습니다.
여기서는 여러 자산을 추가합니다.
- Power BI 테이블
- Power BI 측정값
- 사용자 지정 DAX 쿼리
- DMV(동적 관리 뷰) 쿼리
Power BI 테이블
Power BI 테이블을 데이터 자산으로 추가합니다.
ds.add_powerbi_table_asset("Store Asset", table="Store")
Power BI 측정값
데이터 세트에 미리 구성된 측정값이 포함된 경우 SemPy evaluate_measure와 유사한 API에 따라 측정값을 자산으로 추가합니다.
ds.add_powerbi_measure_asset(
"Total Units Asset",
measure="TotalUnits",
groupby_columns=["Time[FiscalYear]", "Time[FiscalMonth]"]
)
DAX
고유한 측정값을 정의하거나 특정 행을 더 자세히 제어하려는 경우 사용자 지정 DAX 쿼리를 사용하여 DAX 자산을 추가할 수 있습니다. 여기서는 두 개의 기존 측정값을 나누어 측정값을 정의 Total Units Ratio 합니다.
ds.add_powerbi_dax_asset(
"Total Units YoY Asset",
dax_string=
"""
EVALUATE SUMMARIZECOLUMNS(
'Time'[FiscalYear],
'Time'[FiscalMonth],
"Total Units Ratio", DIVIDE([Total Units This Year], [Total Units Last Year])
)
"""
)
DMV 쿼리
경우에 따라 데이터 유효성 검사 프로세스의 일부로 DMV( 동적 관리 뷰 ) 계산을 사용하는 것이 유용할 수 있습니다. 예를 들어 데이터 세트 내의 참조 무결성 위반 수를 추적할 수 있습니다. 자세한 내용은 데이터 정리 = 더 빠른 보고서를 참조하세요.
ds.add_powerbi_dax_asset(
"Referential Integrity Violation",
dax_string=
"""
SELECT
[Database_name],
[Dimension_Name],
[RIVIOLATION_COUNT]
FROM $SYSTEM.DISCOVER_STORAGE_TABLES
"""
)
Expectations
자산에 특정 제약 조건을 추가하려면 먼저 Expectation Suites를 구성해야 합니다. 각 제품군 에 개별 Expectations 를 추가한 후 새 제품군을 사용하여 처음에 설정된 데이터 컨텍스트를 업데이트할 수 있습니다. 사용 가능한 기대치의 전체 목록은 GX Expectation Gallery를 참조하세요.
먼저 다음 두 가지 기대 사항이 있는 "Retail Store Suite"를 추가합니다.
- 유효한 우편 번호
- 행 수가 80에서 200 사이인 테이블
suite_store = context.add_expectation_suite("Retail Store Suite")
suite_store.add_expectation(ExpectationConfiguration("expect_column_values_to_be_valid_zip5", { "column": "PostalCode" }))
suite_store.add_expectation(ExpectationConfiguration("expect_table_row_count_to_be_between", { "min_value": 80, "max_value": 200 }))
context.add_or_update_expectation_suite(expectation_suite=suite_store)
TotalUnits 측정
하나의 기대치를 가지고 "Retail Measure Suite"를 추가합니다.
- 열 값은 50,000보다 커야 합니다.
suite_measure = context.add_expectation_suite("Retail Measure Suite")
suite_measure.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_between",
{
"column": "TotalUnits",
"min_value": 50000
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_measure)
Total Units Ratio DAX
한 가지 예상과 함께 "Retail DAX Suite"를 추가합니다.
- 총 단위 비율의 열 값은 0.8에서 1.5 사이여야 합니다.
suite_dax = context.add_expectation_suite("Retail DAX Suite")
suite_dax.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_between",
{
"column": "[Total Units Ratio]",
"min_value": 0.8,
"max_value": 1.5
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_dax)
참조 무결성 위반 (DMV)
"기대 사항은 하나입니다: 'Retail DMV Suite'를 추가하세요."
- RIVIOLATION_COUNT 0이어야 합니다.
suite_dmv = context.add_expectation_suite("Retail DMV Suite")
# There should be no RI violations
suite_dmv.add_expectation(ExpectationConfiguration(
"expect_column_values_to_be_in_set",
{
"column": "RIVIOLATION_COUNT",
"value_set": [0]
}
))
context.add_or_update_expectation_suite(expectation_suite=suite_dmv)
Validation
데이터에 대해 지정된 기대치를 실제로 실행하려면 먼저 검사점을 만들고 컨텍스트에 추가합니다. 검사점 구성에 대한 자세한 내용은 데이터 유효성 검사 워크플로를 참조하세요.
checkpoint_config = {
"name": f"Retail Analysis Checkpoint",
"validations": [
{
"expectation_suite_name": "Retail Store Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Store Asset",
},
},
{
"expectation_suite_name": "Retail Measure Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Total Units Asset",
},
},
{
"expectation_suite_name": "Retail DAX Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Total Units YoY Asset",
},
},
{
"expectation_suite_name": "Retail DMV Suite",
"batch_request": {
"datasource_name": "Retail Analysis Data Source",
"data_asset_name": "Referential Integrity Violation",
},
},
],
}
checkpoint = context.add_checkpoint(
**checkpoint_config
)
이제 검사점을 실행하고 간단한 서식 지정을 위해 결과를 pandas DataFrame으로 추출합니다.
result = checkpoint.run()
결과를 처리하고 인쇄합니다.
import pandas as pd
data = []
for run_result in result.run_results:
for validation_result in result.run_results[run_result]["validation_result"]["results"]:
row = {
"Batch ID": run_result.batch_identifier,
"type": validation_result.expectation_config.expectation_type,
"success": validation_result.success
}
row.update(dict(validation_result.result))
data.append(row)
result_df = pd.DataFrame.from_records(data)
result_df[["Batch ID", "type", "success", "element_count", "unexpected_count", "partial_unexpected_list"]]

이러한 결과에서 사용자 지정 DAX 쿼리를 통해 정의한 "총 단위 YoY 자산"을 제외하고 모든 기대치가 유효성 검사를 통과했음을 확인할 수 있습니다.
Diagnostics
의미 체계 링크를 사용하여 원본 데이터를 가져와서 범위를 벗어난 정확한 연도를 파악할 수 있습니다. 의미 체계 링크는 DAX 쿼리를 실행하기 위한 인라인 매직을 제공합니다. 의미 체계 링크를 사용하여 GX 데이터 자산에 전달한 것과 동일한 쿼리를 실행하고 결과 값을 시각화합니다.
%%dax "Retail Analysis Sample PBIX"
EVALUATE SUMMARIZECOLUMNS(
'Time'[FiscalYear],
'Time'[FiscalMonth],
"Total Units Ratio", DIVIDE([Total Units This Year], [Total Units Last Year])
)
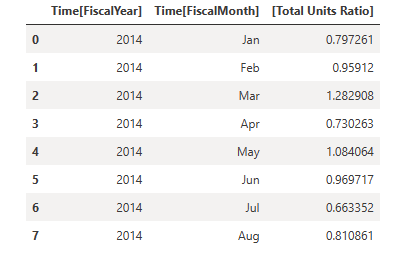
이러한 결과를 DataFrame에 저장합니다.
df = _
결과를 그래프에 그리세요.
import matplotlib.pyplot as plt
df["Total Units % Change YoY"] = (df["[Total Units Ratio]"] - 1)
df.set_index(["Time[FiscalYear]", "Time[FiscalMonth]"]).plot.bar(y="Total Units % Change YoY")
plt.axhline(0)
plt.axhline(-0.2, color="red", linestyle="dotted")
plt.axhline( 0.5, color="red", linestyle="dotted")
None
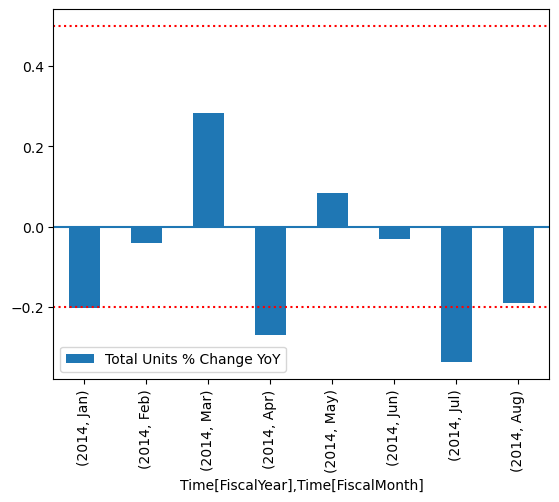
플롯에서 4 월과 7 월이 약간 범위를 벗어난 것을 볼 수 있으며 조사를 위해 추가 조치를 취할 수 있습니다.
GX 구성 저장
시간이 지남에 따라 데이터 세트의 데이터가 변경되면 방금 수행한 GX 유효성 검사를 다시 실행할 수 있습니다. 현재 데이터 컨텍스트(연결된 데이터 자산, Expectation Suites 및 검사점 포함)는 임시로 사용되지만 나중에 사용할 수 있도록 파일 컨텍스트로 변환할 수 있습니다. 또는 파일 컨텍스트를 인스턴스화할 수 있습니다( 데이터 컨텍스트 인스턴스화 참조).
context = context.convert_to_file_context()
컨텍스트를 저장했으므로 레이크하우스에 gx 디렉터리를 복사합니다.
Important
이 셀은 여러분이 노트북에 레이크하우스를 추가했다고 가정합니다. 연결된 레이크하우스가 없으면 오류가 표시되지 않지만 나중에 컨텍스트를 가져올 수도 없습니다. 레이크하우스를 지금 추가하면 커널이 다시 시작되므로 이 시점으로 돌아가려면 전체 Notebook을 다시 실행해야 합니다.
# copy GX directory to attached lakehouse
!cp -r gx/ /lakehouse/default/Files/gx
이제 이 자습서의 모든 구성을 사용하기 위해 context = gx.get_context(project_root_dir="<your path here>")로 향후 컨텍스트를 만들 수 있습니다.
예를 들어 새 Notebook에서 동일한 레이크하우스를 연결하고 context = gx.get_context(project_root_dir="/lakehouse/default/Files/gx")을(를) 사용하여 컨텍스트를 검색합니다.
관련 콘텐츠
의미 체계 링크/SemPy에 대한 다른 자습서를 확인하세요.