이 자습서에서는 의미 체계 모델(Power BI 데이터 세트)으로 저장된 Power BI 분석가의 작업을 기반으로 합니다. Microsoft Fabric의 Synapse 데이터 과학 환경에서 SemPy(미리 보기)를 사용하여 DataFrame 열의 기능 종속성을 분석합니다. 이 분석을 통해 미묘한 데이터 품질 문제를 검색하여 보다 정확한 인사이트를 얻을 수 있습니다.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- 도메인 지식을 적용하여 의미 체계 모델의 함수 종속성에 대한 가설을 공식화합니다.
- Power BI와 통합되고 데이터 품질 분석을 자동화하는 데 도움이 되는 SemPy(Semantic Link Python 라이브러리)의 구성 요소에 대해 알아보세요. 이러한 구성 요소는 다음과 같습니다.
- FabricDataFrame — pandas와 같은 구조에 추가적인 의미 정보로 강화된 구조체
- 패브릭 작업 영역에서 Notebook으로 의미 체계 모델을 끌어오는 함수
- 함수 종속성 가설을 평가하고 의미 체계 모델에서 관계 위반을 식별하는 함수
필수 조건
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈 페이지의 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

탐색 창에서 작업 영역을 선택하여 작업 영역을 찾아 선택합니다. 이 작업 영역은 현재 작업 영역이 됩니다.
fabric-samples GitHub 리포지토리에서 고객 수익성 샘플.pbix 파일을 다운로드합니다.
작업 영역에서 보고서>가져오기 또는 페이지가 매겨진 보고서>를 선택하고, 이 컴퓨터에서 고객 수익성 Sample.pbix 파일을 작업 영역에 업로드하십시오.
Notebook에서 따라 하기
이 자습서에는 powerbi_dependencies_tutorial.ipynb Notebook이 함께 제공됩니다.
이 자습서와 함께 제공된 노트북을 열려면 데이터 과학 자습서를 위해 시스템을 준비하기 지침에 따라 노트북을 작업 공간으로 가져오세요.
이 페이지에서 코드를 복사하여 붙여넣으려는 경우 새 Notebook을 만들 수 있습니다.
코드를 실행하기 전에 노트북에 레이크하우스를 연결해야 합니다.
Notebook 설정
필요한 모듈 및 데이터를 사용하여 Notebook 환경을 설정합니다.
노트북에서 PyPI로부터 SemPy를 설치하려면
%pip을 사용하세요.%pip install semantic-link필요한 모듈을 가져옵니다.
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
데이터 로드 및 전처리
이 자습서에서는 표준 샘플 의미 체계 모델인 Customer Profitability Sample.pbix를 사용합니다. 의미 체계 모델에 대한 설명은 Power BI에 대한 고객 수익성 샘플을 참조하세요.
함수
FabricDataFrame을(를) 사용하여 Power BI 데이터를fabric.read_table에 로드합니다.dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()State에 테이블을 로드합니다FabricDataFrame.state = fabric.read_table(dataset, "State") state.head()출력은 pandas DataFrame처럼 보이지만 이 코드는 pandas 위에 작업을 추가하는 데이터
FabricDataFrame구조를 초기화합니다.의 데이터 형식을 확인합니다
customer.type(customer)출력은 다음과 같습니다
customersempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.customer및stateDataFrame개체를 결합합니다.customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
함수 종속성 식별
기능 종속성은 DataFrame에 있는 두 개 이상의 열에서 값 간에 일 대 다 관계입니다. 이러한 관계를 사용하여 데이터 품질 문제를 자동으로 검색합니다.
병합된
find_dependencies항목에서 SemPy 함수DataFrame를 실행하여 열 값 간의 기능 종속성을 식별합니다.dependencies = customer_state_df.find_dependencies() dependenciesSemPy의
plot_dependency_metadata함수를 사용하여 종속성을 시각화합니다.plot_dependency_metadata(dependencies)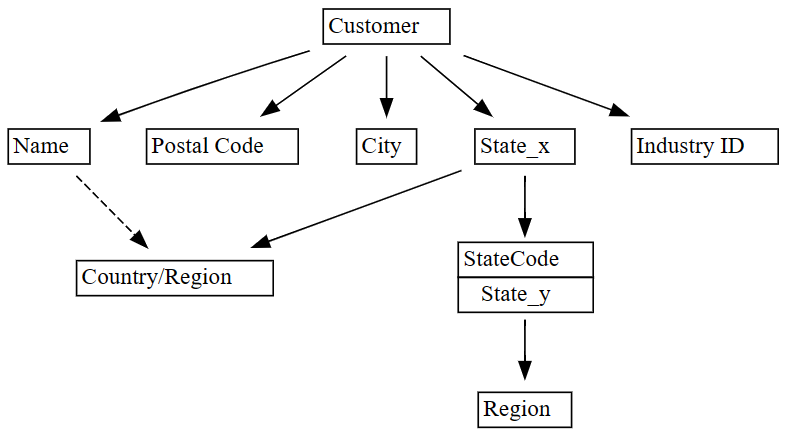
기능 종속성 그래프는 열이
Customer열과 같은CityPostal CodeName열을 결정한다는 것을 보여 줍니다.그래프는 아마도 열
City과Postal Code간의 관계에 많은 위반이 있기 때문에 함수 종속성을 표시하지 않는 것 같습니다. SemPy 함수plot_dependency_violations를 사용하여 특정 열 간의 종속성 위반을 시각화합니다.

품질 문제에 대한 데이터 탐색
SemPy의
plot_dependency_violations시각화 함수를 사용하여 그래프를 그릴 수 있습니다.customer_state_df.plot_dependency_violations('Postal Code', 'City')
종속성 위반 그래프에서는 왼쪽에
Postal Code의 값이, 오른쪽에City의 값이 각각 나타납니다. 이 두 값이 포함된 행이 있는 경우 가장자리는 왼쪽의Postal Code와 오른쪽의City를 연결합니다. 가장자리에는 그러한 행의 수가 주석으로 표시됩니다. 예를 들어 우편 번호가 20004인 두 개의 행이 있는데, 한 행에는 도시가 ‘North Tower’이고 다른 행에는 도시가 ‘Washington’입니다.또한 플롯에는 몇 가지 위반과 많은 빈 값이 표시됩니다.
Postal Code에 대한 빈 값 수를 확인합니다.customer_state_df['Postal Code'].isna().sum()50개의 행에는 NA 값이 포함되어 있습니다
Postal Code.빈 값이 있는 행을 삭제합니다. 그런 다음
find_dependencies함수를 사용하여 종속성을 찾습니다. SemPy의 내부 작업을 엿볼 수 있는 추가 매개 변수verbose=1을 확인하세요.customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Postal Code및City의 조건부 엔트로피는 0.049입니다. 이 값은 함수 종속성 위반이 있음을 나타냅니다. 위반을 수정하기 전에 조건부 엔트로피에 대한 임계값을 기본값인0.01에서0.05로 올려 종속성을 확인할 수 있습니다. 임계값이 낮을수록 종속성이 줄어들거나 선택성이 높아집니다.조건부 엔트로피의 임계값을 기본값
0.01에서0.05로 올립니다.plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))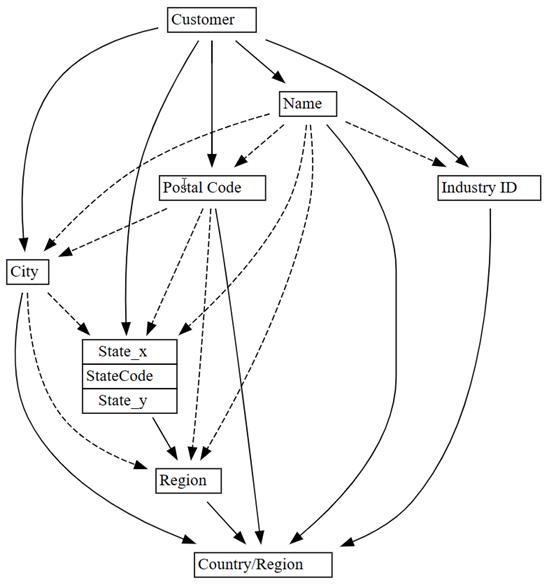
다른 엔터티의 값을 결정하는 엔터티에 대한 도메인 지식을 적용하면 이 종속성 그래프가 정확해 보입니다.
감지된 많은 데이터 품질 문제를 자세히 살펴봅니다. 예를 들어 대시 화살표가
City와Region을 연결하는데, 이는 종속성이 대략적인 수준에 불과하다는 것을 나타냅니다. 이 대략적인 관계는 부분적인 함수 종속성이 있음을 암시할 수 있습니다.customer_state_df.list_dependency_violations('City', 'Region')Region값이 비어 있지 않은 경우 위반이 발생하는 각 사례를 자세히 살펴봅니다.customer_state_df[customer_state_df.City=='Downers Grove']결과는 일리노이와 네브래스카에있는 다우너스 그로브의 도시를 보여줍니다. 그러나 다우너스 그로브는 네브래스카가 아닌 일리노이의 도시입니다.
도시 Fremont를 살펴봅니다.
customer_state_df[customer_state_df.City=='Fremont']California에는 Fremont라는 도시가 있습니다. 그러나 Texas의 경우 검색 엔진이 Fremont가 아니라 Premont를 반환합니다.
또한 종속성 위반의 원래 그래프(빈 값이 있는 행을 삭제하기 전)에서 점선으로 표시된 대로
Name과Country/Region사이의 종속성 위반이 보이는 것도 의심스럽습니다.customer_state_df.list_dependency_violations('Name', 'Country/Region')한 고객인 SDI 디자인이 두 지역(미국 및 캐나다)에 나타납니다. 이 경우는 의미적 위반이 아닐 수 있으며, 단지 흔치 않을 수 있습니다. 그럼에도 불구하고 자세히 살펴볼 만한 가치가 있습니다.
고객 SDI 디자인을 자세히 살펴봅니다.
customer_state_df[customer_state_df.Name=='SDI Design']추가 검사는 동일한 이름을 가진 서로 다른 산업의 두 고객을 보여줍니다.

예비 데이터 분석 및 데이터 정리는 반복적입니다. 찾는 것은 질문과 관점에 따라 달라집니다. 의미 체계 링크는 데이터에서 더 많은 것을 얻을 수 있는 새로운 도구를 제공합니다.
관련 콘텐츠
의미 체계 링크 및 SemPy에 대한 다른 자습서를 확인하세요.