이 자습서에서는 Jupyter Notebook을 사용하여 Power BI와 상호 작용하고 SemPy 라이브러리를 사용하여 테이블 간의 관계를 검색하는 방법을 보여 줍니다.
이 튜토리얼에서는 다음을 배우게 됩니다:
- 의미 체계 링크의 Python 라이브러리(SemPy)를 사용하여 의미 체계 모델(Power BI 데이터 세트)에서 관계를 검색합니다.
- Power BI와 통합하고 데이터 품질 분석을 자동화하는 SemPy 구성 요소를 사용합니다. 이러한 구성 요소는 다음과 같습니다.
-
FabricDataFrame- 의미 체계 정보로 개선된 pandas와 같은 구조 - 패브릭 작업 영역에서 Notebook으로 의미 체계 모델을 끌어오는 함수
- 함수 종속성을 테스트하고 의미 체계 모델에서 관계 위반을 식별하는 함수
-
Prerequisites
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈 페이지의 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

탐색 창에서 작업 영역 으로 이동한 다음 작업 영역을 선택하여 현재 작업 영역으로 설정합니다.
패브릭 샘플 GitHub 리포지토리에서 고객 수익성 샘플.pbix 및 고객 수익성 샘플(auto).pbix 의미 체계 모델을 다운로드한 다음 작업 영역에 업로드합니다.
Notebook에서 팔로우
powerbi_relationships_tutorial.ipynb Notebook을 사용하여 따릅니다.
이 튜토리얼에 포함된 노트북을 열려면, 데이터 과학 튜토리얼을 위한 시스템 준비의 지침을 따라 노트북을 작업 공간으로 가져오세요.
이 페이지에서 코드를 복사하여 붙여 넣으면 새 Notebook을 만들 수 있습니다.
코드 실행을 시작하기 전에 Lakehouse를 Notebook에 연결 해야 합니다.
Notebook 설정
필요한 모듈 및 데이터를 사용하여 Notebook 환경을 설정합니다.
Notebook의
semantic-link인라인 명령을 사용하여%pipPyPI에서 패키지를 설치합니다.%pip install semantic-linksempy나중에 사용할 모듈을 가져옵니다.import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violations라이브러리를
pandas가져오고 출력 서식에 대한 표시 옵션을 설정합니다.import pandas as pd pd.set_option('display.max_colwidth', None)
## Explore semantic models
This tutorial uses the Customer Profitability Sample semantic model [_Customer Profitability Sample.pbix_](https://github.com/microsoft/fabric-samples/blob/main/docs-samples/data-science/datasets/Customer%20Profitability%20Sample.pbix). Learn about the semantic model in [Customer Profitability sample for Power BI](/power-bi/create-reports/sample-customer-profitability).
- Use SemPy's `list_datasets` function to explore semantic models in your current workspace:
```python
fabric.list_datasets()
이 Notebook의 나머지 부분에는 두 가지 버전의 고객 수익성 샘플 의미 체계 모델을 사용합니다.
- 고객 수익성 샘플: 미리 정의된 테이블 관계가 있는 Power BI 샘플에 제공된 의미 체계 모델
- 고객 수익성 샘플(자동): 동일한 데이터이지만 관계는 Power BI가 자동으로 검색하는 데이터로 제한됩니다.
샘플 의미 체계 모델에서 미리 정의된 관계 추출
SemPy
list_relationships의 함수를 사용하여 고객 수익성 샘플 의미 체계 모델에서 미리 정의된 관계를 로드합니다. 이 함수는 TOM(테이블 형식 개체 모델)의 관계를 나열합니다.dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsSemPy의
relationshipsplot_relationship_metadata함수를 사용하여 DataFrame을 그래프로 시각화합니다.plot_relationship_metadata(relationships)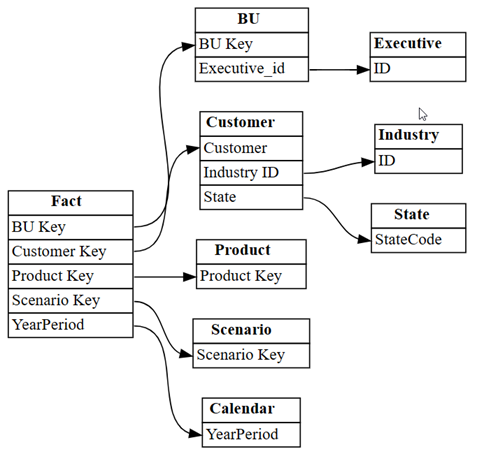
이 그래프는 주제 전문가가 Power BI에 정의한 대로 이 의미 체계 모델의 테이블 간 관계를 보여 줍니다.

추가 관계 검색
Power BI가 자동으로 검색하는 관계로 시작하는 경우 더 작은 집합이 있습니다.
의미 체계 모델에서 Power BI가 자동으로 검색한 관계를 시각화합니다.
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)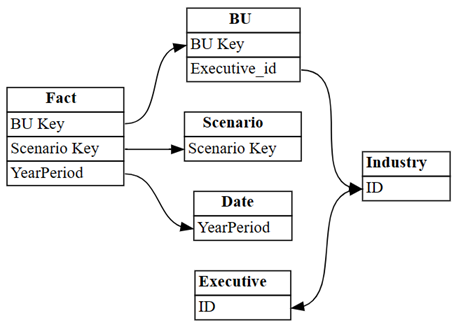
Power BI의 자동 검색은 많은 관계를 누락합니다. 또한 자동 검색된 관계 중 두 가지는 의미상 올바르지 않습니다.
-
Executive[ID]: >Industry[ID] -
BU[Executive_id]: >Industry[ID]
-
관계를 표로 인쇄합니다.
autodetected행 3과 4는 테이블에 대한 잘못된 관계를
Industry표시합니다. 이러한 행을 제거합니다.잘못 식별된 관계를 삭제합니다.
# Remove rows 3 and 4 which point incorrectly to Industry[ID] autodetected = autodetected[~autodetected.index.isin([3, 4])]이제 정확하지만 불완전한 관계가 있습니다. 다음을 사용하여
plot_relationship_metadata불완전한 관계를 시각화합니다.plot_relationship_metadata(autodetected)
SemPy
list_tables와 함수를 사용하여 의미 체계 모델에서 모든 테이블을 로드한read_table다음 다음을 사용하여find_relationships테이블 간의 관계를 찾습니다. 로그 출력을 검토하여 이 함수의 작동 방식에 대한 인사이트를 얻습니다.suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )새로 검색된 관계를 시각화합니다.
plot_relationship_metadata(suggested_relationships_all)
SemPy는 모든 관계를 검색합니다.
매개 변수를
exclude사용하여 검색을 이전에 식별되지 않은 추가 관계로 제한합니다.additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



관계 유효성 검사
먼저 고객 수익성 샘플 의미 체계 모델에서 데이터를 로드합니다.
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()기본 키와 외래 키가 함수와 겹치는지 확인합니다
list_relationship_violations. 함수의 출력을 .에list_relationships전달합니다list_relationship_violations.list_relationship_violations(tables, fabric.list_relationships(dataset))결과는 유용한 인사이트를 표시합니다. 예를 들어 7개 값
Fact[Product Key]중 하나가 존재하지Product[Product Key]않으며 누락된 키는 다음과 같습니다50.예비 데이터 분석 및 데이터 정리는 반복적입니다. 학습하는 내용은 질문과 데이터 탐색 방법에 따라 달라집니다. 의미 체계 링크는 데이터를 사용하여 더 많은 작업을 수행하는 데 도움이 되는 도구를 추가합니다.
관련 콘텐츠
의미 체계 링크 및 SemPy에 대한 다른 자습서를 살펴보세요.
\n\n