다른 쿼리 또는 값에 동일한 변환 집합을 적용해야 하는 경우 필요한 만큼 재사용할 수 있는 파워 쿼리 사용자 지정 함수를 만드는 것이 좋습니다. 파워 쿼리 사용자 지정 함수는 입력 값 집합에서 단일 출력 값으로의 매핑이며 네이티브 M 함수 및 연산자에서 생성됩니다.
파워 쿼리 M 수식 언어를 사용하여 사용자 고유의 파워 쿼리 사용자 지정 함수를 수동으로 만들거나, 사용자 지정 함수를 만들고 관리하는 프로세스를 가속화, 단순화 및 향상시키는 기능을 제공하는 파워 쿼리 사용자 인터페이스를 사용할 수 있습니다.
먼저 UI 코드를 사용하여 사용자 지정 함수를 만드는기본 단계를 설명한 다음, 인터페이스를 사용하여 복잡한 작업을 재사용 가능한 함수 설정하는 데 집중하겠습니다.
중요하다
이 문서에서는 파워 쿼리 사용자 인터페이스에서 액세스할 수 있는 일반적인 변환을 사용하여 파워 쿼리 사용자 지정 함수를 만드는 방법을 간략하게 설명합니다. 이 문서에서 참조하는 특정 변환에 대한 자세한 내용은 사용자 지정 함수를 만드는 핵심 개념과 파워 쿼리 설명서의 다른 문서에 대한 링크에 중점을 둡니다.
UI의 코드에서 사용자 지정 함수 만들기
메모
다음 단계는 Power BI Desktop에서 수행하거나 Windows Excel 있는 파워 쿼리 환경을 사용하여 수행할 수 있습니다.
커넥터 환경을 사용하여 보관된 데이터에 연결합니다. 데이터를 선택한 경우 데이터 변환 또는 편집 단추를 선택합니다. 이렇게 하면 파워 쿼리 환경으로 연결됩니다.
왼쪽의 쿼리 창에서 빈 자리를 마우스 오른쪽 단추로 클릭합니다.
빈 쿼리선택.
새 빈 쿼리 창에서 홈 메뉴를 선택한 다음, 고급 편집기.
템플릿을 사용자 정의 함수로 바꾸세요. 다음은 그 예입니다.
let HelloWorld = () => ("Hello World") in HelloWorld완료선택합니다.
파워 쿼리 M 수식 언어를 사용하여 사용자 지정 함수를 개발하는 방법에 대한 자세한 내용은 이 문서를 참조하세요: 파워 쿼리 M 함수 이해. 다음 섹션에서는 파워 쿼리 사용자 인터페이스를 사용하여 코드를 작성하지 않고 사용자 지정 함수를 개발하는 방법과 쿼리에서 사용자 지정 함수를 호출하는 방법에 대한 지침을 설명하는 자습서가 있습니다.
테이블 참조 자습서에서 사용자 지정 함수 만들기
메모
다음 예제는 Power BI Desktop에서 찾은 데스크톱 환경을 사용하여 만들어졌으며 Windows Excel 있는 파워 쿼리 환경을 사용하여 따를 수도 있습니다.
이 예제를 따르려면 다음 다운로드 링크에서 이 문서에 사용된 샘플 파일을 다운로드하여 따라할 수 있습니다. 간단히 하기 위해 이 문서에서는 폴더 커넥터를 사용합니다. 폴더 커넥터에 대해 자세히 알아보려면 폴더로 이동하세요. 이 예제의 목표는 모든 파일의 모든 데이터를 단일 테이블로 결합하기 전에 해당 폴더의 모든 파일에 적용할 수 있는 사용자 지정 함수를 만드는 것입니다.
폴더 커넥터 환경을 사용하여 파일이 있는 폴더로 이동한 다음, 데이터 변환 또는 편집을 선택하세요. 이러한 단계를 수행하면 파워 쿼리 환경으로 이동합니다. 콘텐츠 필드에서 선택한 이진 값을 마우스 오른쪽 단추로 클릭하고 새 쿼리로 추가 옵션을 선택합니다. 이 예제에서는 리스트에서 첫 번째 파일인 April 2019.csv파일을 선택했습니다.

이 옵션은 해당 파일에 대한 탐색 단계를 이진으로 직접 사용하여 새 쿼리를 효과적으로 만들고, 이 새 쿼리의 이름은 선택한 파일의 파일 경로입니다. 이 쿼리의 이름을 샘플 파일로 변경하십시오.

이름이 파일 매개변수이고 종류가 이진수인 새 매개변수을 만듭니다. 샘플 파일 쿼리를 기본값 및 현재 값로 사용하십시오.

메모
파워 쿼리 매개 변수를 만들고 관리하는 방법을 더 잘 이해하려면 매개 변수 사용 문서를 읽어보는 것이 좋습니다.
모든 매개 변수 형식을 사용하여 사용자 지정 함수를 만들 수 있습니다. 사용자 지정 함수에 이진을 매개 변수로 포함할 필요가 없습니다.
이진 매개 변수 형식은 이진으로 평가되는 쿼리가 있는 경우에만 매개 변수 대화 상자 형식 드롭다운 메뉴 내에 표시됩니다.
매개 변수 없이 사용자 지정 함수를 만들 수 있습니다. 이는 일반적으로 함수가 호출되는 환경에서 입력을 유추할 수 있는 시나리오에서 볼 수 있습니다. 예를 들어 환경의 현재 날짜 및 시간을 사용하고 해당 값에서 특정 텍스트 문자열을 만드는 함수입니다.
쿼리 창에서 파일 매개 변수 마우스 오른쪽 단추로 클릭합니다. 참조 옵션을 선택합니다.
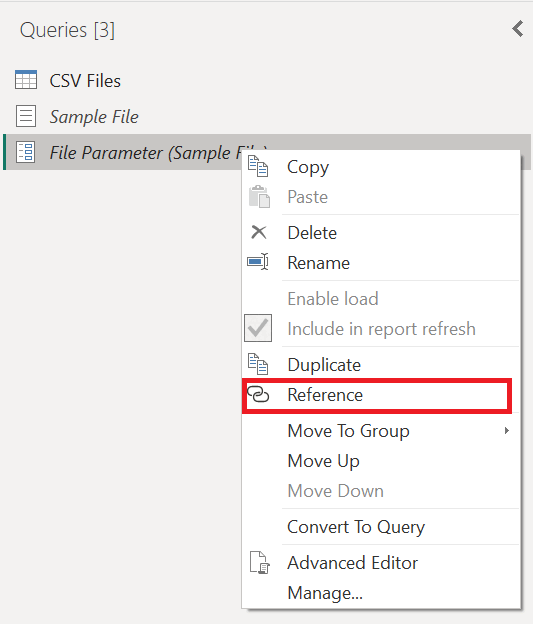
새로 만든 쿼리의 이름을 파일 매개 변수(2)에서 변환 샘플 파일로 변경합니다.

이 새 변환 샘플 파일 쿼리를 마우스 오른쪽 단추로 클릭하고 함수 만들기 옵션을 선택합니다.
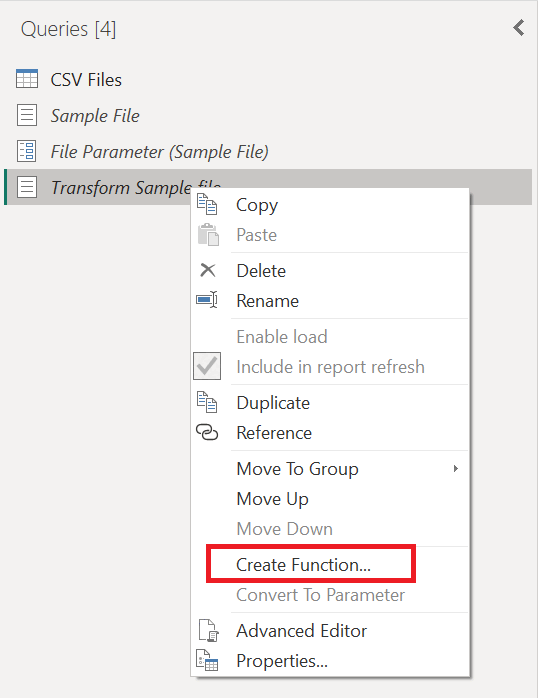
이 작업은 변환 샘플 파일 쿼리와 연결되는 새 함수를 효과적으로 만듭니다. 변환 샘플 파일 쿼리에 대한 변경 내용은 사용자 지정 함수에 자동으로 복제됩니다. 이 새 함수를 만드는 동안 Transform 파일함수 이름으로사용합니다.

함수를 만든 후에는 함수 이름으로 새 그룹이 만들어집니다. 이 새 그룹에는 다음이 포함됩니다.
- 변환 샘플 파일 쿼리에서 참조된 모든 매개 변수입니다.
- 일반적으로 샘플 쿼리이라고 알려진 변환 샘플 파일 쿼리입니다.
- 당신이 새로 만든 함수는, 이 경우 파일을 변환합니다.

샘플 쿼리에 변환 적용
새 함수를 만든 상태에서 이름이 변환 샘플 파일인 쿼리를 선택합니다. 이 쿼리는 이제 Transform 파일 함수와 연결되므로 이 쿼리에 대한 모든 변경 내용이 함수에 반영됩니다. 이 연결은 함수에 연결된 샘플 쿼리의 개념이라고 합니다.
이 쿼리에 대해 수행해야 하는 첫 번째 변환은 이진 파일을 해석하는 변환입니다. 미리 보기 창에서 이진 파일을 마우스 오른쪽 단추로 클릭하고 CSV 옵션을 선택하여 이진 파일을 CSV 파일로 해석할 수 있습니다.
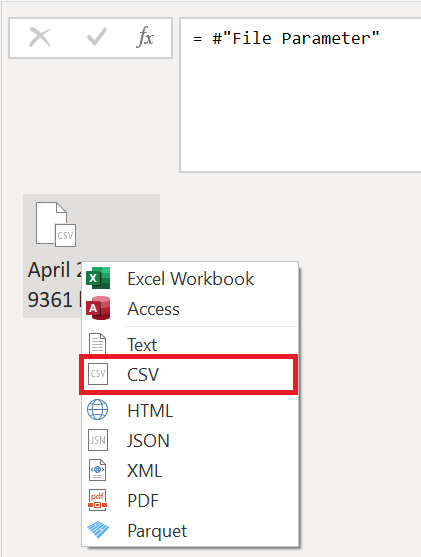
폴더에 있는 모든 CSV 파일의 형식은 동일합니다. 모두 첫 번째 상위 4개 행에 걸쳐 있는 헤더가 있습니다. 열 머리글은 5행에 있으며 데이터는 다음 이미지와 같이 행 6에서 아래쪽으로 시작됩니다.

변환 샘플 파일 적용해야 하는 다음 변환 단계 집합은 다음과 같습니다.
상위 4개 행을 제거합니다. 이 작업은 파일의 머리글 섹션의 일부로 간주되는 행을 제거합니다.
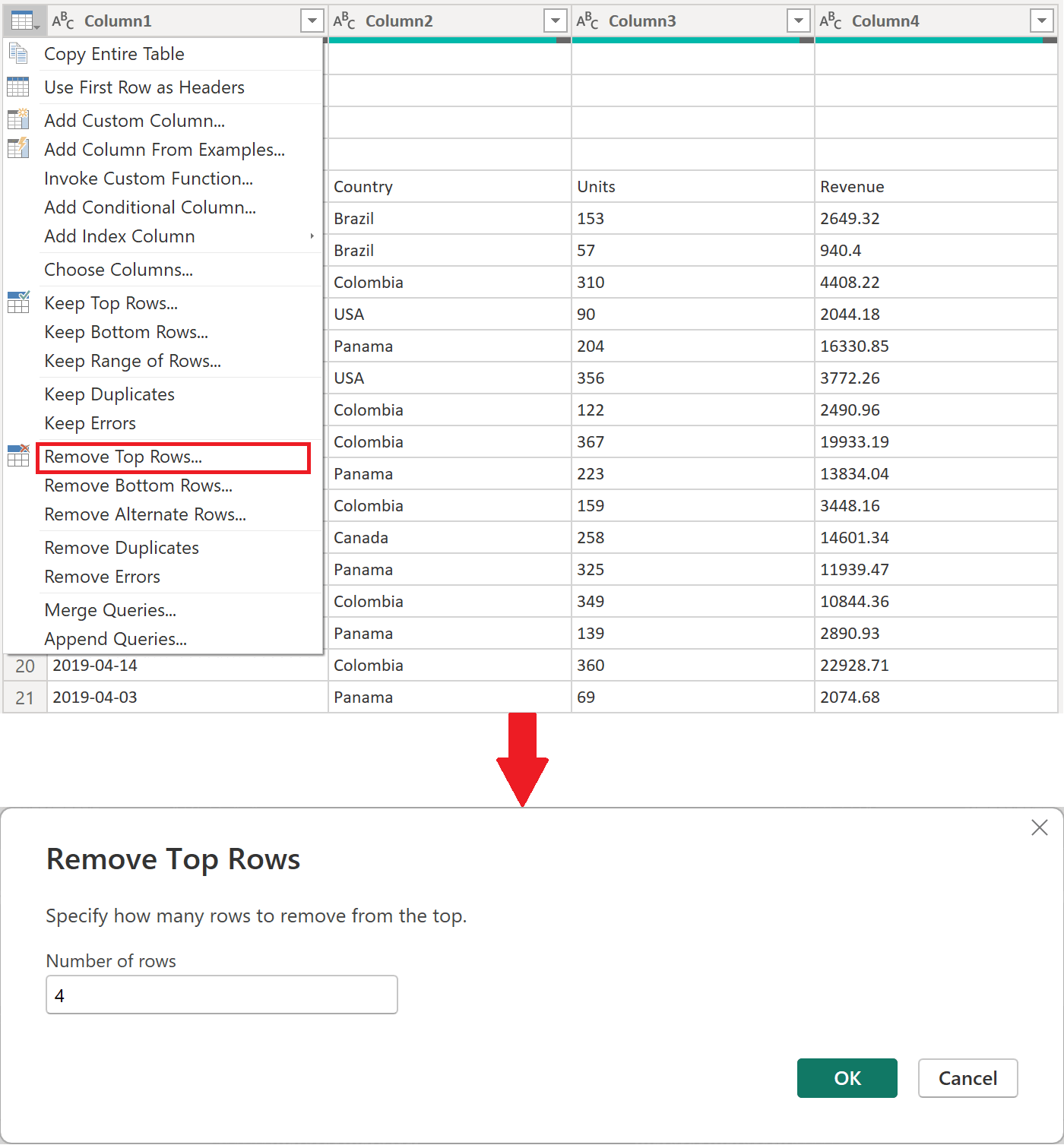
메모
행을 제거하거나 행 위치별로 테이블을 필터링하는 방법에 대해 자세히 알아보려면 행 위치별로 테이블 필터링을 참조하세요.
머리글 승격- 이제 마지막 테이블의 머리글이 테이블의 첫 번째 행에 있습니다. 다음 이미지와 같이 그들을 승격할 수 있습니다.
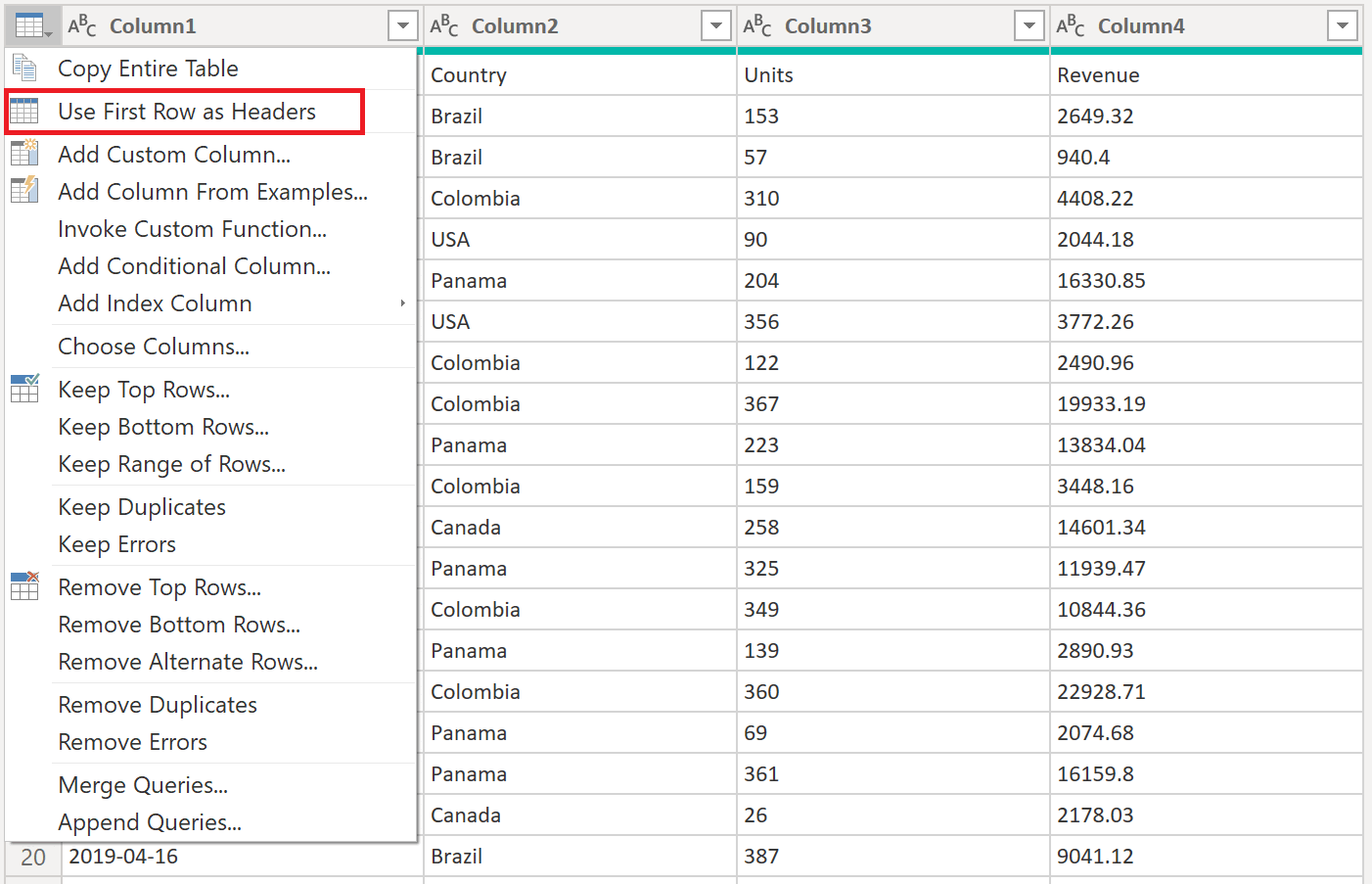


열 머리글을 승격한 후, 파워 쿼리는 기본적으로 각 열의 데이터 형식을 자동으로 감지하여 새 Changed Type 단계를 추가합니다. 변환 샘플 파일 쿼리는 다음 이미지와 같습니다.
메모
머리글을 승격 및 강등하는 방법에 대해 자세히 알아보려면 열 머리글수준 올리기 또는 강등으로 이동합니다.

주의
변환 파일 함수는 변환 샘플 파일 쿼리에서 수행되는 단계에 의존합니다. 그러나 Transform 파일 함수에 대한 코드를 수동으로 수정하려고 하면 The definition of the function 'Transform file' is updated whenever query 'Transform Sample file' is updated. However, updates will stop if you directly modify function 'Transform file'. 경고를 받게 됩니다.
사용자 지정 함수를 새 열로 호출
이제 사용자 지정 함수를 만들고 모든 변환 단계를 통합하면 폴더의 파일 목록이 있는 원래 쿼리로 돌아갈 수 있습니다(이 예제에서는 CSV 파일). 리본 메뉴의 열 추가 탭 내에서 일반 그룹에서 사용자 지정 함수 호출 을 선택합니다. 사용자 지정 함수 호출 창에서 새 열 이름으로 출력 테이블 을 입력합니다. 함수 쿼리 드롭다운 목록에서 함수의 이름인 변환 파일을 선택합니다. 드롭다운 메뉴에서 함수를 선택하면 함수의 매개 변수가 표시되고 테이블에서 이 함수의 인수로 사용할 열을 선택할 수 있습니다. 파일 매개 변수전달할 값/인수로 콘텐츠 열을 선택합니다.

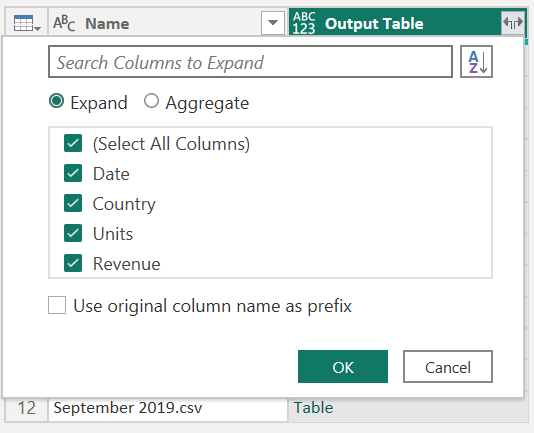
OK 선택하면, '출력 테이블'이라는 새 열이 만들어집니다. 이 열에는 다음 이미지와 같이 셀에 Table 값이 있습니다. 간단히 하기 위해 이 테이블에서 이름 및 출력 테이블을 제외한 모든 열을 제거합니다.

함수는 Content 열의 값을 함수의 인수로 사용하여 테이블의 모든 단일 행에 적용되었습니다. 데이터가 원하는 셰이프로 변환되었으므로 확장 아이콘을 선택하여 출력 테이블 열을 확장할 수 있습니다. 확장된 열에는 접두사를 사용하지 마세요.
이름 또는 날짜 열의 값을 확인하여 폴더에 있는 모든 파일의 데이터가 있는지 확인할 수 있습니다. 이 경우 각 파일에는 지정된 연도의 한 달 동안의 데이터만 포함되므로 날짜 열의 값을 확인할 수 있습니다. 둘 이상이 표시되면 여러 파일의 데이터를 단일 테이블로 성공적으로 결합했음을 의미합니다.

메모
지금까지 읽은 내용은 결합 파일 경험 동안 발생하는 것과 기본적으로 동일한 프로세스지만, 수동으로 수행됩니다.
또한 조합 파일 개요 및 CSV 파일 통합 문서를 참조하여 결합 파일 환경이 파워 쿼리 작동하는 방식과 사용자 지정 함수가 수행하는 역할을 더 자세히 이해하는 것이 좋습니다.
기존 사용자 지정 함수에 새 매개 변수 추가
현재 빌드한 항목 위에 새로운 요구 사항이 있다고 상상해 보십시오. 새 요구 사항은 파일을 결합하기 전에 CountryPanama동일한 행만 가져오기 위해 파일 내의 데이터를 필터링해야 합니다.
이 요구 사항을 수행하려면 텍스트 데이터 형식으로 Market이라는 새 매개 변수를 만듭니다. 현재 값에 파나마값을 입력합니다.

이 새 매개 변수를 사용하여 변환 샘플 파일 쿼리를 선택하고 Market 매개 변수의 값을 사용하여 Country 필드를 필터링합니다.

메모
값을 사용하여 열을 필터링하는 방법에 대해 자세히 알아보려면 열의 값으로 필터링으로 이동하세요.
이 새 단계를 쿼리에 적용하면 Transform 파일 함수가 자동으로 업데이트됩니다. 이제 변환 샘플 파일에서 사용하는 두 매개 변수를 기반으로 두 개의 매개 변수가 필요합니다.

그러나 CSV 파일 쿼리 옆에 경고 기호가 있습니다. 이제 함수가 업데이트되었으므로 두 개의 매개 변수가 필요합니다. 따라서 함수를 호출하는 단계에서는 호출된 사용자 지정 함수 단계에서 인수 중 하나만 Transform 파일 함수에 전달되었기 때문에 오류 값이 발생합니다.

오류를 해결하려면 적용된 단계호출된 사용자 지정 함수 두 번 클릭하여 사용자 지정 함수 호출 창을 엽니다. Market 매개 변수에서 값을 파나마수동으로 입력합니다.

이제 적용된 단계에서 확장 출력 테이블으로 다시 돌아갈 수 있습니다. 쿼리를 확인하여 Country 열이 파나마 인 행만 CSV 파일 쿼리의 최종 결과 집합에 표시되는지 검증하십시오.

재사용 가능한 논리 조각에서 사용자 지정 함수 만들기
동일한 변환 집합이 필요한 여러 쿼리 또는 값이 있는 경우 다시 사용할 수 있는 논리의 역할을 하는 사용자 지정 함수를 만들 수 있습니다. 나중에 선택한 쿼리 또는 값에 대해 이 사용자 지정 함수를 호출할 수 있습니다. 이 사용자 지정 함수는 시간을 절약하고 언제든지 수정할 수 있는 중앙 위치에서 변환 집합을 관리하는 데 도움이 될 수 있습니다.
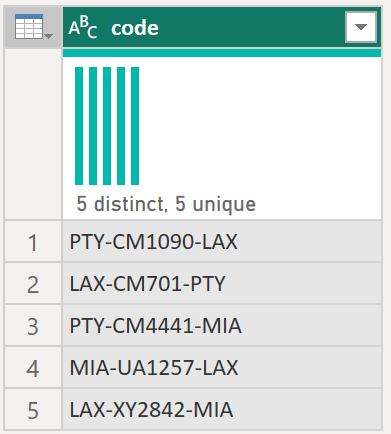
예를 들어 여러 코드가 텍스트 문자열로 있고 다음 샘플 표와 같이 해당 값을 디코딩하는 함수를 만들려고 하는 쿼리를 생각해 보세요.
| 코드 |
|---|
| PTY-CM1090-LAX |
| LAX-CM701-PTY |
| PTY-CM4441-MIA |
| MIA-UA1257-LAX |
| LAX-XY2842-MIA |
먼저 예제로 사용되는 값이 있는 매개 변수를 사용합니다. 이 경우 PTY-CM1090-LAX값입니다.

해당 매개 변수에서 필요한 변환을 적용하는 새 쿼리를 만듭니다. 이 경우 PTY-CM1090-LAX 코드를 여러 구성 요소로 분할하려고 합니다.
- 원본 = PTY
- 목적지 = LAX
- Airline = CM
- FlightID = 1090

다음 M 코드는 해당 변환 집합을 보여 줍니다.
let
Source = code,
SplitValues = Text.Split( Source, "-"),
CreateRow = [Origin= SplitValues{0}, Destination= SplitValues{2}, Airline=Text.Start( SplitValues{1},2), FlightID= Text.End( SplitValues{1}, Text.Length( SplitValues{1} ) - 2) ],
RowToTable = Table.FromRecords( { CreateRow } ),
#"Changed Type" = Table.TransformColumnTypes(RowToTable,{{"Origin", type text}, {"Destination", type text}, {"Airline", type text}, {"FlightID", type text}})
in
#"Changed Type"
메모
파워 쿼리 M 수식 언어에 대한 자세한 내용은 파워 쿼리 M 수식 언어.
그런 다음, 쿼리를 마우스 오른쪽 단추로 클릭하고 함수 만들기 선택하여 해당 쿼리를 함수로 변환할 수 있습니다. 마지막으로 다음 이미지와 같이 쿼리 또는 값으로 사용자 지정 함수를 호출할 수 있습니다.

몇 가지 추가 변환 후에 원하는 출력에 도달하고 사용자 지정 함수에서 이러한 변환에 대한 논리를 적용한 것을 볼 수 있습니다.
