적용 대상:![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
Important
Microsoft SQL Server 2019 빅 데이터 클러스터는 사용 중지되었습니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일부터 종료되었습니다. 자세한 내용은 Microsoft SQL Server 플랫폼의 공지 블로그 게시물 및 빅 데이터 옵션을 참조하세요.
SQL Server는 배포 Notebook을 포함하는 Azure Data Studio에 대한 확장을 제공합니다. 배포 Notebook에는 Azure Data Studio에서 SQL Server 빅 데이터 클러스터를 만드는 데 사용할 수 있는 설명서와 코드가 포함되어 있습니다.
처음에 오픈 소스 프로젝트로 구현된 Notebook은Azure Data Studio에 구현되었습니다. 텍스트 셀의 텍스트에 markdown을 사용하고 사용 가능한 커널 중 하나를 사용하여 코드 셀에 코드를 작성할 수 있습니다.
Notebook을 사용하여 SQL Server 빅 데이터 클러스터를 배포할 수 있습니다.
Prerequisites
Notebook을 시작하려면 다음 필수 구성 요소가 필요합니다.
- 최신 버전의 Azure Data Studio Insiders 빌드 가 설치됨
위 외에도 빅 데이터 클러스터를 배포하려면 다음이 필요합니다.
노트북을 시작하세요
Azure Data Studio를 시작합니다.
연결 탭에서 줄임표(...)를 선택한 다음, SQL Server 배포를 선택합니다.
배포 옵션에서 SQL Server 빅 데이터 클러스터를 선택합니다.
배포 대상의 옵션 아래에서 새 Azure Kubernetes 클러스터 또는 기존 Azure Kubernetes Service 클러스터를 선택합니다.
개인 정보 및 사용 조건에 동의합니다.
이 대화 상자는 선택한 유형의 SQL 배포에 필요한 도구가 호스트에 있는지 여부도 확인합니다. 선택 단추는 도구 확인에 성공할 때까지 사용하도록 설정되지 않습니다.
선택 단추를 선택하십시오. 이 작업은 배포 환경을 시작합니다.
배포 구성 템플릿 설정
아래 지침에 따라 배포 프로필의 설정을 사용자 지정할 수 있습니다.
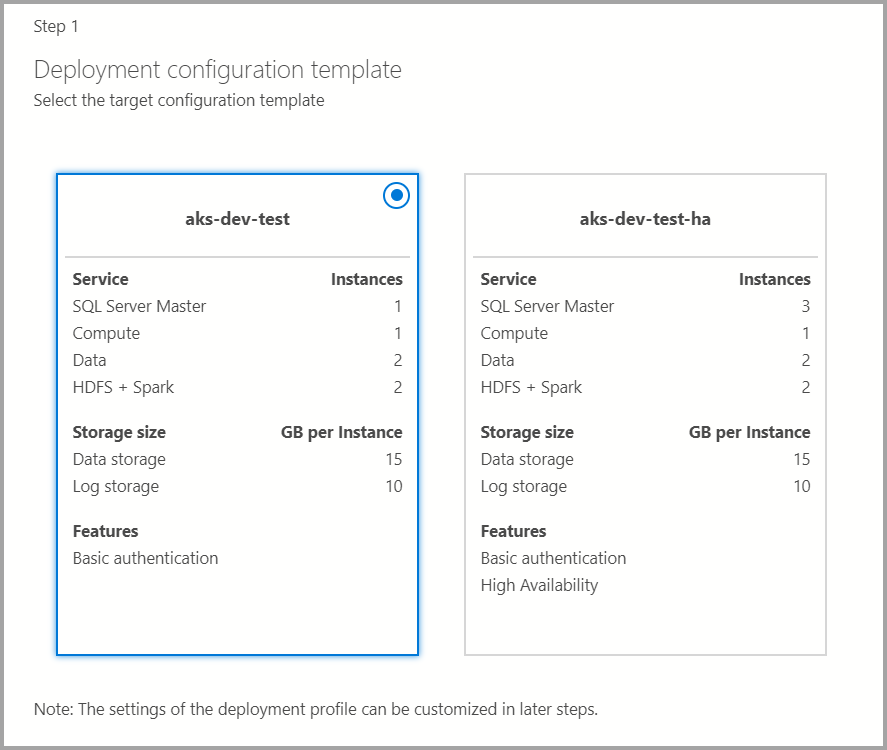
대상 구성 템플릿
사용 가능한 템플릿에서 대상 구성 템플릿을 선택합니다. 사용 가능한 프로필은 이전 대화 상자에서 선택한 배포 대상 유형에 따라 필터링됩니다.
Azure settings
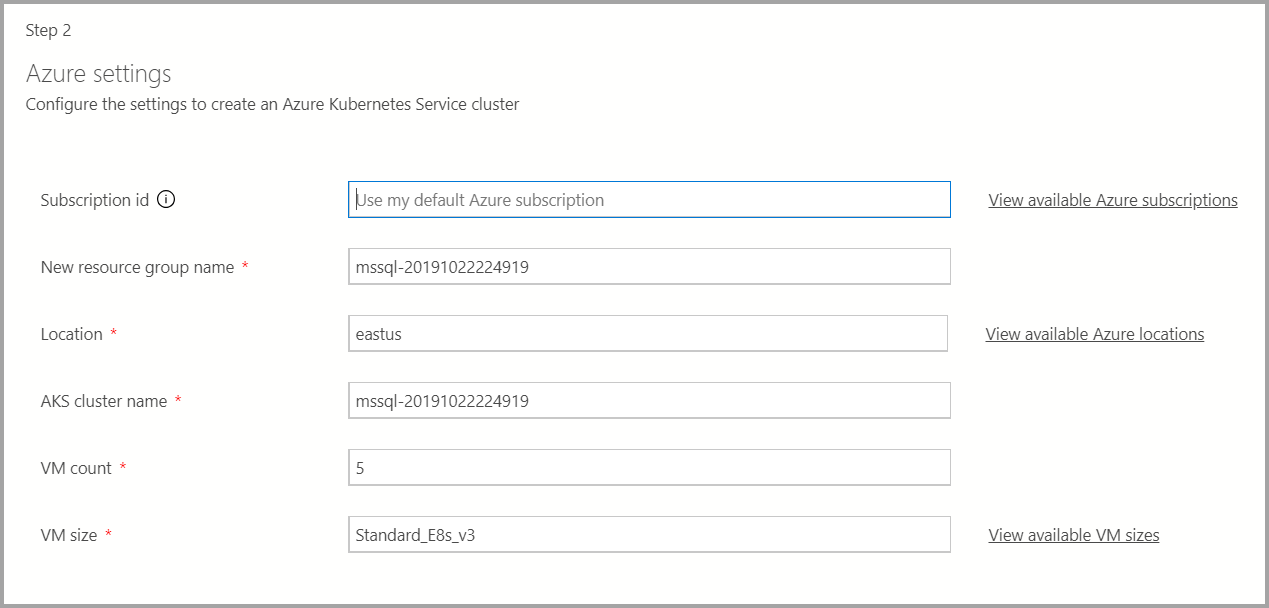
배포 대상이 새 AKS(Azure Kubernetes Service)인 경우 AKS 클러스터를 만들려면 Azure 구독 ID, 리소스 그룹, AKS 클러스터 이름, VM 수, 크기 및 기타 추가 정보와 같은 추가 정보가 필요합니다.
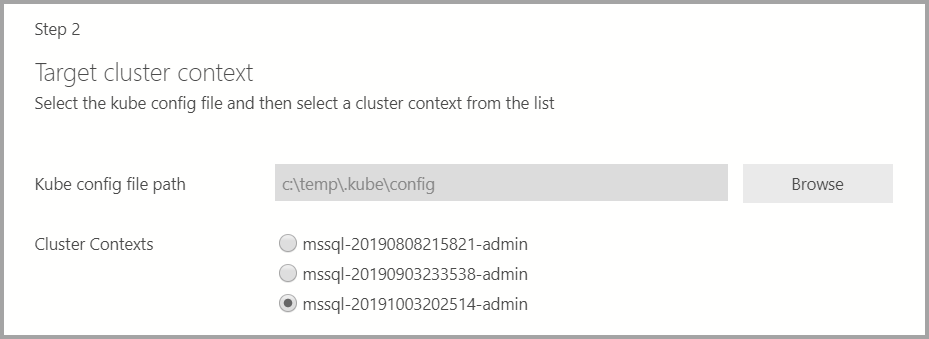
배포 대상이 기존 Kubernetes 클러스터인 경우 마법사는 Kubernetes 클러스터 설정을 가져올 kube 구성 파일의 경로를 묻는 메시지를 표시합니다. SQL Server 2019 빅 데이터 클러스터를 배포할 수 있는 적절한 클러스터 컨텍스트가 선택되어 있는지 확인합니다.
클러스터, docker 및 AD 설정
빅 데이터 클러스터의 클러스터 이름, 관리자 사용자 이름 및 암호를 입력합니다. 이 계정은 컨트롤러 및 SQL Server에 사용됩니다.
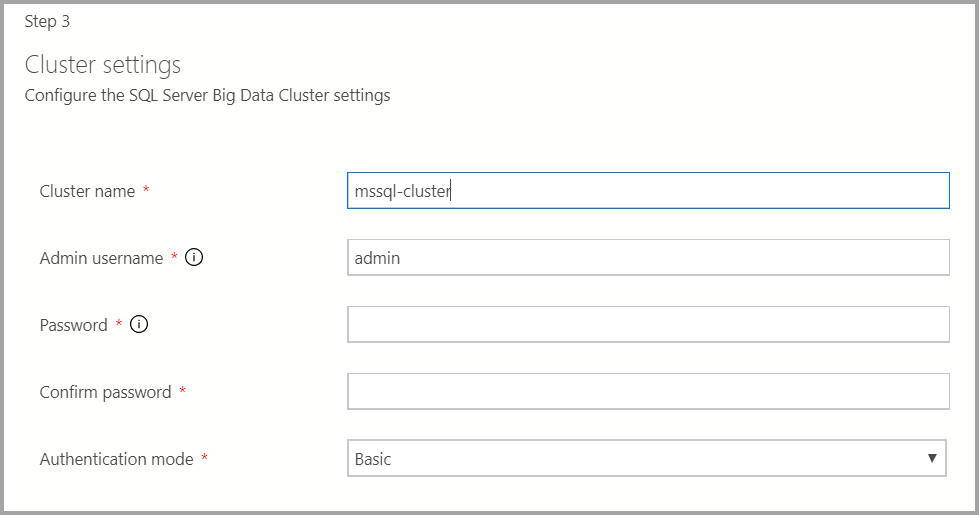
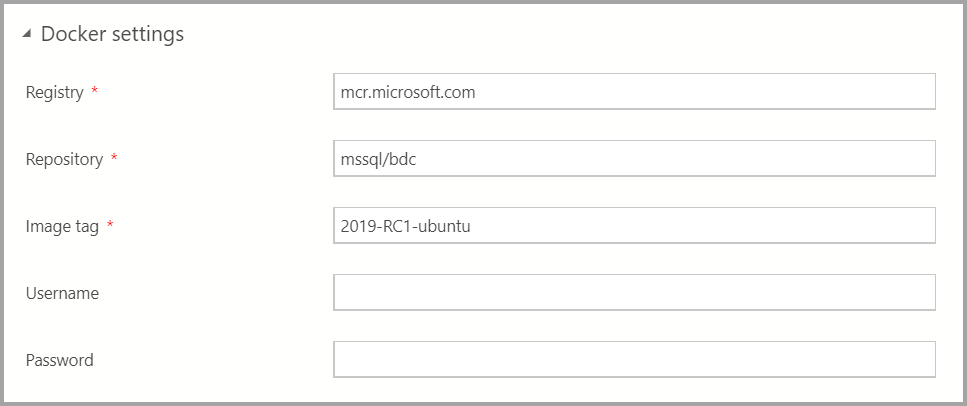
Docker 설정을 적절하게 입력합니다.
Important
이미지 태그 필드가 최신인지 확인합니다. 2019-CU13-ubuntu-20.04
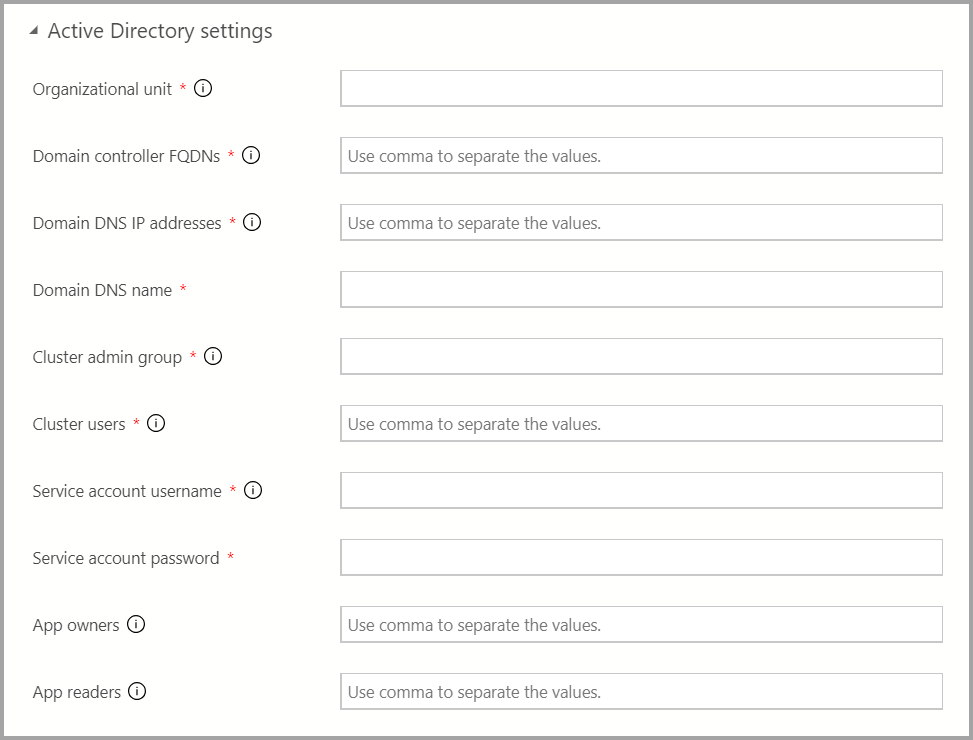
AD 인증을 사용할 수 있는 경우 AD 설정을 입력합니다.
Service settings
이 화면에는 크기 조정, 엔드포인트, 스토리지 및 기타 고급 스토리지 설정과 같은 다양한 설정에 대한 입력이 있습니다. 적절한 값을 입력하고 다음을 선택합니다.
Scale settings
빅 데이터 클러스터에 있는 각 구성 요소의 인스턴스 수를 입력합니다.
Spark 인스턴스는 HDFS와 함께 포함할 수 있습니다. 스토리지 풀에 포함되거나 Spark 풀에 자체적으로 포함됩니다.
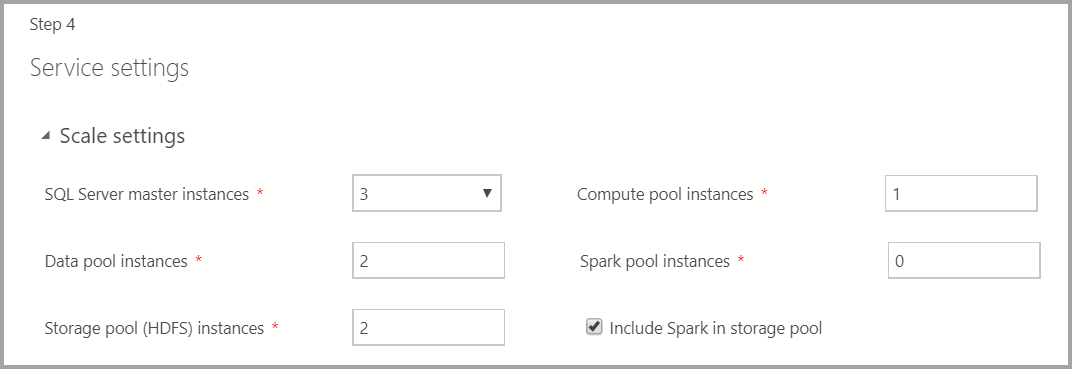
이러한 각 구성 요소에 대한 자세한 내용은 마스터 인스턴스, 데이터 풀, 스토리지 풀 또는 컴퓨팅 풀을 참조할 수 있습니다.
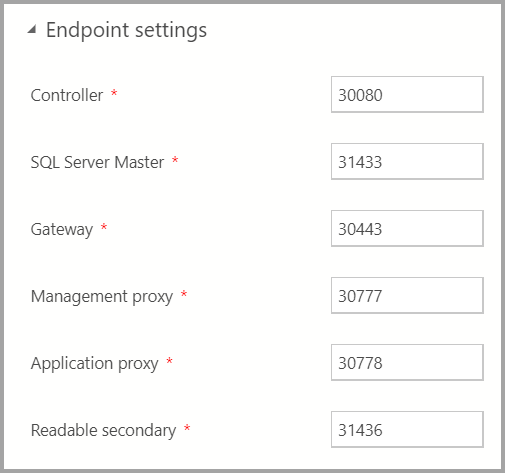
Endpoint settings
기본 엔드포인트가 미리 채워져 있습니다. 그러나 적절하게 변경할 수 있습니다.
Storage settings
스토리지 설정에는 데이터 및 로그에 대한 스토리지 클래스 및 클레임 크기가 포함됩니다. 스토리지, 데이터 및 SQL Server 마스터 풀에서 설정을 적용할 수 있습니다.

고급 스토리지 설정
고급 스토리지 설정에서 추가 스토리지 설정을 추가할 수 있습니다.
스토리지 풀(HDFS)
Data pool
SQL Server 마스터

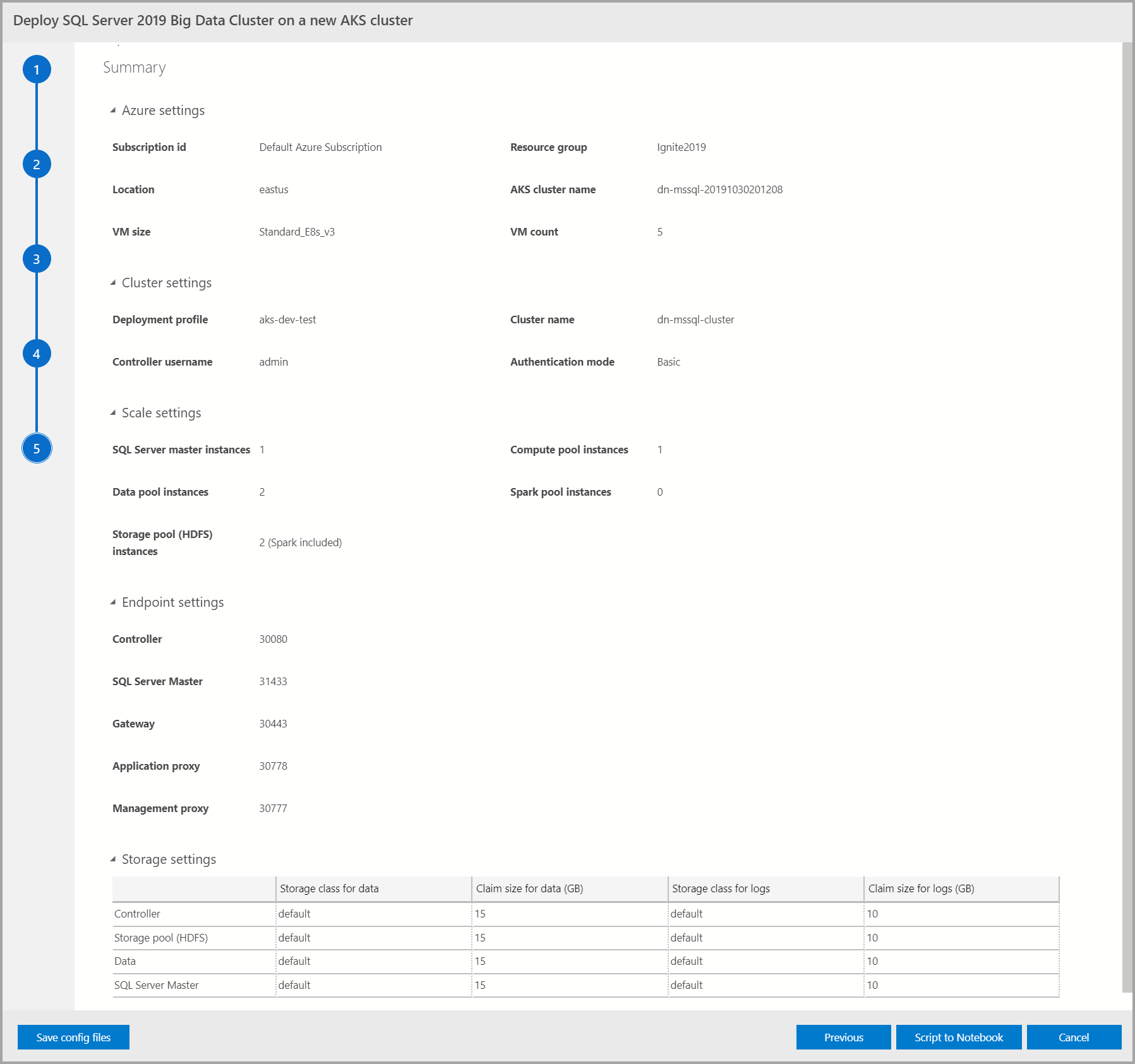
Summary
이 화면에는 빅 데이터 클러스터를 배포하기 위해 제공된 모든 입력이 요약되어 있습니다. 구성 파일 저장 단추를 통해 구성 파일을 다운로드할 수 있습니다. Notebook에 대한 스크립트를 선택하여 전체 배포 구성을 Notebook에 스크립트합니다. Notebook이 열리면 셀 실행을 선택하여 선택한 대상에 빅 데이터 클러스터 배포를 시작합니다.
Next steps
배포에 대한 자세한 내용은 SQL Server 빅 데이터 클러스터에 대한 배포 지침을 참조하세요.