텍스트 음성 변환 API 사용
100 XP
음성 텍스트 변환 API의 경우와 비슷하게, Azure AI 음성 서비스는 음성 합성을 위해 다음과 같은 기타 REST API를 제공합니다.
- 텍스트 음성 변환 API: 음성 합성을 수행하는 기본적인 방법입니다.
- 일괄 합성 API: 다량의 텍스트를 오디오로 변환하는 일괄 처리 작업을 지원합니다(예: 원본 텍스트에서 오디오북 생성).
텍스트 음성 변환 REST API 설명서에서 REST API에 대해 자세히 알아볼 수 있습니다. 실무에서는 대부분의 대화형 음성 지원 애플리케이션이 (프로그래밍) 언어별 SDK를 통해 Azure AI 음성 서비스를 사용합니다.
Azure AI 음성 SDK 사용
음성 인식의 경우와 같이, 실무에서는 대부분의 대화형 음성 지원 애플리케이션이 Azure AI 음성 SDK를 사용하여 빌드됩니다.
음성 합성을 구현하는 패턴은 음성 인식의 경우와 비슷합니다.
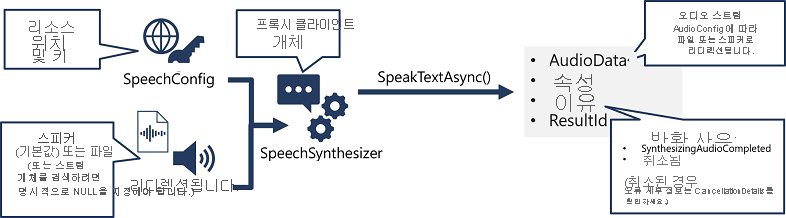
- SpeechConfig 개체를 사용하여 Azure AI 음성 리소스에 연결하는 데 필요한 정보를 캡슐화합니다. 이러한 정보는 구체적으로 해당하는 위치 및 키입니다.
- 선택적으로, AudioConfig를 사용하여 합성할 음성의 출력 디바이스를 정의합니다. 기본적으로 이 디바이스가 기본 시스템 스피커가 되지만, 추가로 오디오 파일을 지정할 수도 있고, 명시적인 방식으로 이 값을 null 값으로 설정하여 직접 반환되는 오디오 스트림 개체를 처리할 수도 있습니다.
- SpeechConfig 및 AudioConfig를 사용하여 SpeechSynthesizer 개체를 만듭니다. 이 개체는 텍스트 음성 변환 API의 프록시 클라이언트입니다.
- SpeechSynthesizer 개체의 메서드를 사용하여 기본 API 함수를 호출합니다. 예를 들어, SpeakTextAsync() 메서드는 Azure AI 음성 서비스를 사용하여 텍스트를 음성 오디오로 변환합니다.
- Azure AI 음성 서비스의 응답을 처리합니다.
SpeakTextAsync 메서드 사용 시의 경우 결과는 다음 속성이 포함된 SpeechSynthesisResult 개체입니다.
- AudioData
- 속성
- 이유
- ResultId
음성이 성공적으로 합성되면 Reason 속성이 SynthesizingAudioCompleted 열거형으로 설정되고 AudioData 속성은 오디오 스트림을 포함합니다(이 오디오 스트림은 AudioConfig에 따라 스피커 또는 파일로 자동 전송되었을 수 있음).