Nata
Norint pasiekti šį puslapį, reikalingas leidimas. Galite pabandyti prisijungti arba pakeisti katalogus.
Norint pasiekti šį puslapį, reikalingas leidimas. Galite pabandyti pakeisti katalogus.
Use the Notebook activity to run notebooks you create in Microsoft Fabric as part of your Data Factory pipelines. Notebooks let you run Apache Spark jobs to bring in, clean up, or transform your data as part of your data workflows. It’s easy to add a Notebook activity to your pipelines in Fabric, and this guide walks you through each step.
Prerequisites
To get started, you must complete the following prerequisites:
- A tenant account with an active subscription. Create an account for free.
- A workspace is created.
- A notebook is created in your workspace. To create a new notebook, refer to How to create Microsoft Fabric notebooks.
Create a notebook activity
Create a new pipeline in your workspace.
Search for Notebook in the pipeline Activities pane, and select it to add it to the pipeline canvas.
Select the new Notebook activity on the canvas if it isn't already selected.
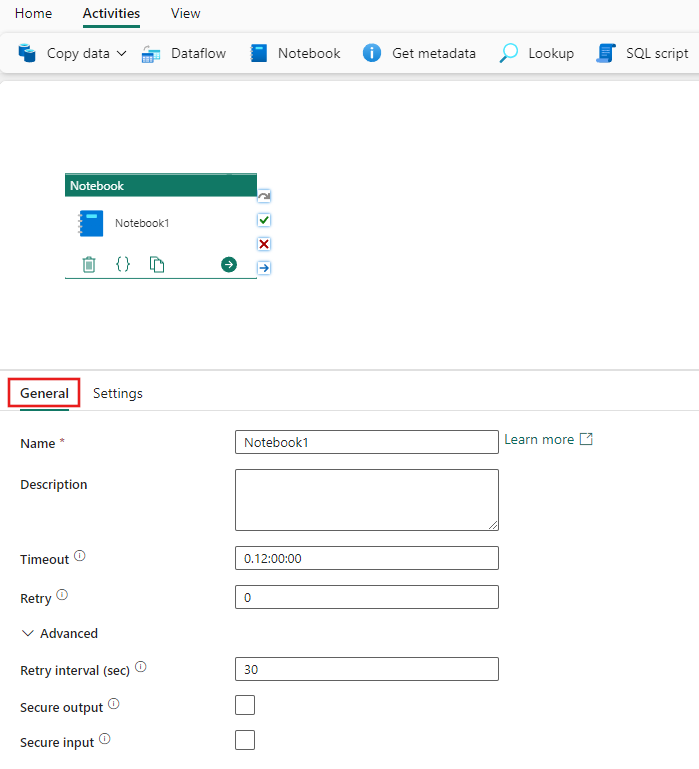
Refer to the General settings guidance to configure the General settings tab.
Configure notebook settings
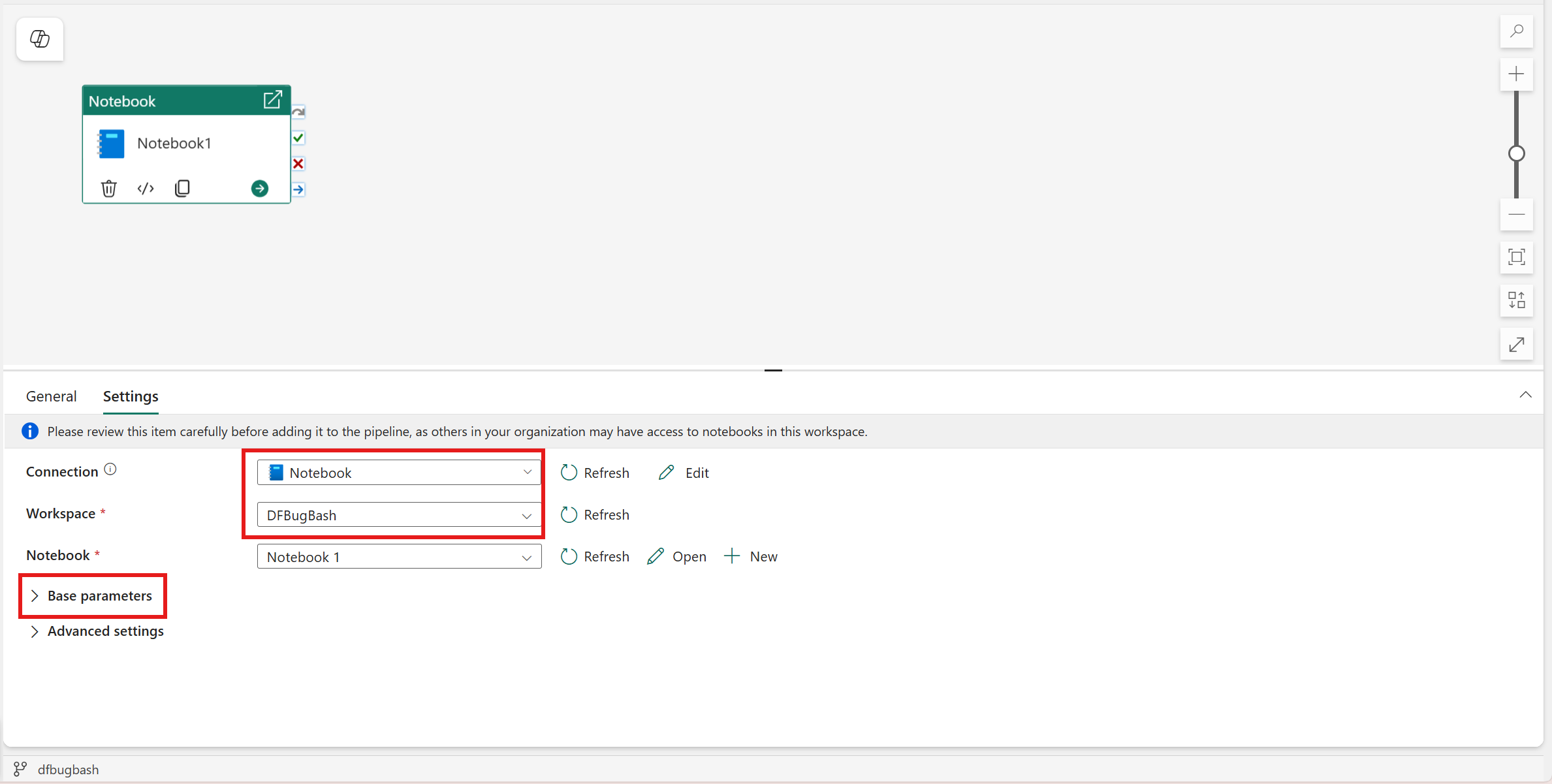
Select the Settings tab.
Under Connection, select the authentication method for the notebook run and provide the required credentials or identity configuration based on your selection:
- Service Principal (SPN) – Recommended for production scenarios to ensure secure, automated execution without relying on user credentials.
- Workspace Identity (WI) – Ideal for managed environments where centralized identity governance is required.
Select an existing notebook from the Notebook dropdown, and optionally specify any parameters to pass to the notebook.
Using Fabric Workspace Identity (WI) in the Notebook activity
Create the Workspace Identity
You must enable WI in your workspace (this may take a moment to load). Create a Workspace Identity in your Fabric workspace. Note that the WI should be created in the same workspace as your Pipeline.
Check out the docs on Workspace Identity.
Enable tenant-level settings
Enable the following tenant setting (it's disabled by default): Service principals can call Fabric public APIs.
You can enable this setting in the Fabric admin portal. For more information about this setting, see the enable service principal authentication for admin APIs article.
Grant workspace permissions to the Workspace Identity
Open the workspace, select Manage access, and assign permissions to the Workspace Identity. Contributor access is sufficient for most scenarios. If your Notebook is not in the same workspace as your Pipeline, you'll need to assign the WI you created in your Pipeline's workspace at least Contributor access to your Notebook's workspace.
Check out the docs on Give users access to workspaces.
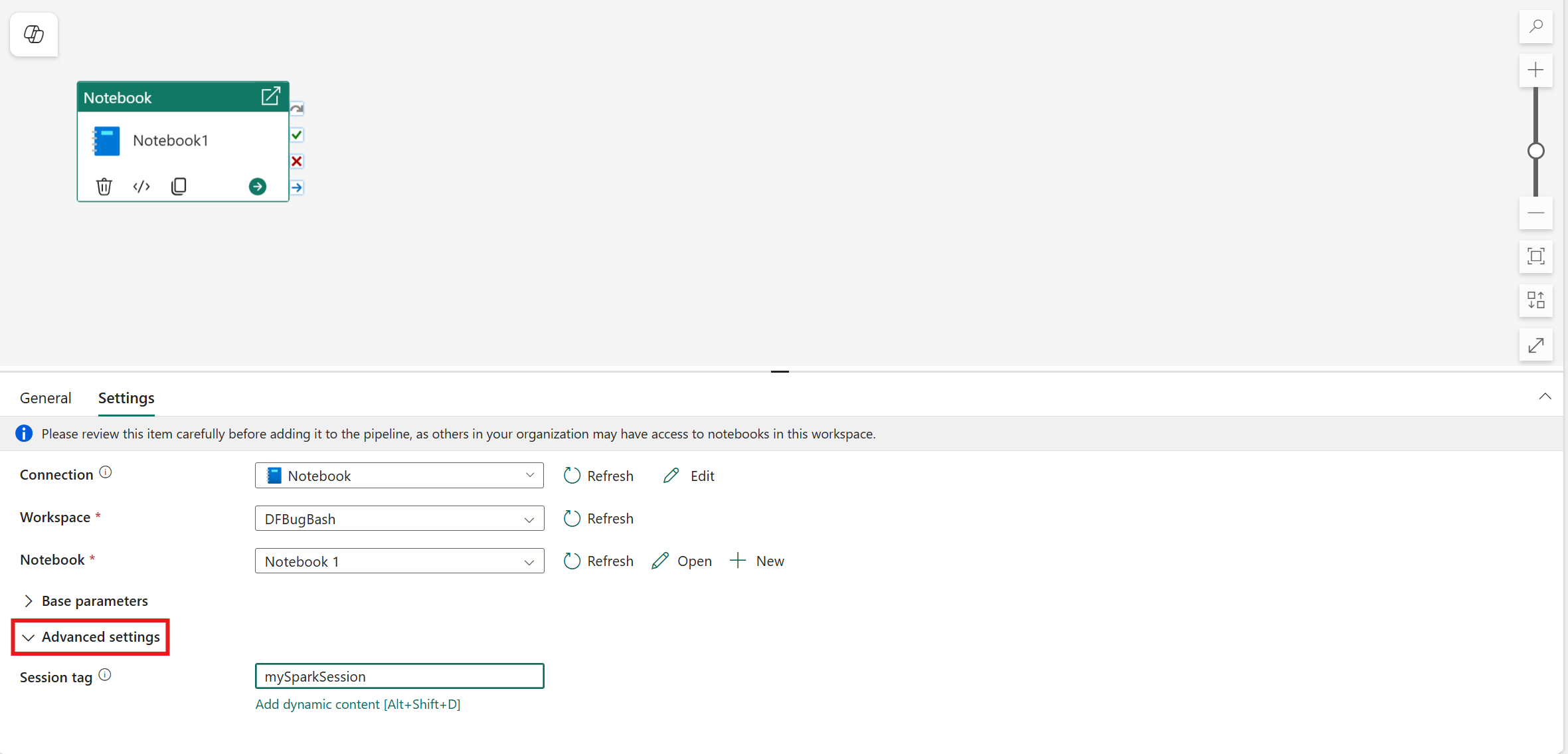
Set session tag
In order to minimize the amount of time it takes to execute your notebook job, you could optionally set a session tag. Setting the session tag instructs Spark to reuse any existing Spark session, minimizing the startup time. Any arbitrary string value can be used for the session tag. If no session exists, a new one would be created using the tag value.
Note
To be able to use the session tag, High concurrency mode for pipeline running multiple notebooks option must be turned on. This option can be found under the High concurrency mode for Spark settings under the Workspace settings

Save and run or schedule the pipeline
Switch to the Home tab at the top of the pipeline editor, and select the save button to save your pipeline. Select Run to run it directly, or Schedule to schedule it. You can also view the run history here or configure other settings.

Known issues
- The WI option in connections settings does not surface in some instances. This is a bug that a fix is being worked on at the moment.