Consistency levels in Azure Cosmos DB
APPLIES TO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Gremlin
Gremlin
![]() Table
Table
Distributed databases that rely on replication for high availability, low latency, or both, must make a fundamental tradeoff between the read consistency, availability, latency, and throughput as defined by the PACELC theorem. The linearizability of the strong consistency model is the gold standard of data programmability. But it adds a steep price from higher write latencies due to data having to replicate and commit across large distances. Strong consistency may also suffer from reduced availability (during failures) because data can't replicate and commit in every region. Eventual consistency offers higher availability and better performance, but it's more difficult to program applications because data may not be consistent across all regions.
Most commercially available distributed NoSQL databases available in the market today provide only strong and eventual consistency. Azure Cosmos DB offers five well-defined levels. From strongest to weakest, the levels are:
For more information on the default consistency level, see configuring the default consistency level or override the default consistency level.
Each level provides availability and performance tradeoffs. The following image shows the different consistency levels as a spectrum.
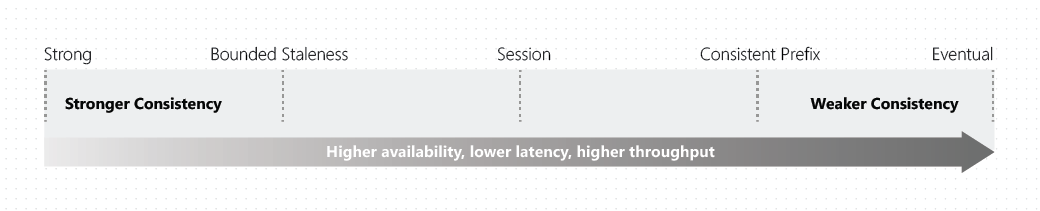
Consistency levels and Azure Cosmos DB APIs
Azure Cosmos DB provides native support for wire protocol-compatible APIs for popular databases. These include MongoDB, Apache Cassandra, Apache Gremlin, and Azure Table Storage. In API for Gremlin or Table, the default consistency level configured on the Azure Cosmos DB account is used. For details on consistency level mapping between Apache Cassandra and Azure Cosmos DB, see API for Cassandra consistency mapping. For details on consistency level mapping between MongoDB and Azure Cosmos DB, see API for MongoDB consistency mapping.
Scope of the read consistency
Read consistency applies to a single read operation scoped within a logical partition. A remote client, a stored procedure, or a trigger can issue the read operation.
Configure the default consistency level
You can configure the default consistency level on your Azure Cosmos DB account at any time. The default consistency level configured on your account applies to all Azure Cosmos DB databases and containers under that account. All reads and queries issued against a container or a database use the specified consistency level by default. As you change your account level consistency, ensure you redeploy your applications and make any necessary code modifications to apply these changes. To learn more, see how to configure the default consistency level. You can also override the default consistency level for a specific request, to learn more, see how to Override the default consistency level article.
Tip
Overriding the default consistency level only applies to reads within the SDK client. An account configured for strong consistency by default will still write and replicate data synchronously to every region in the account. When the SDK client instance or request overrides this with Session or weaker consistency, reads will be performed using a single replica. For more information, see Consistency levels and throughput.
Important
It is required to recreate any SDK instance after changing the default consistency level. This can be done by restarting the application. This ensures the SDK uses the new default consistency level.
Guarantees associated with consistency levels
Azure Cosmos DB guarantees that 100 percent of read requests meet the consistency guarantee for the consistency level chosen. The precise definitions of the five consistency levels in Azure Cosmos DB using the TLA+ specification language are provided in the azure-cosmos-tla GitHub repo.
The semantics of the five consistency levels are described in the following sections.
Strong consistency
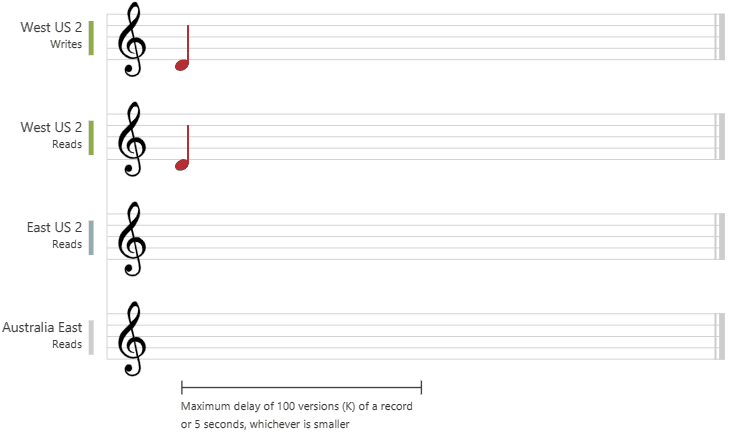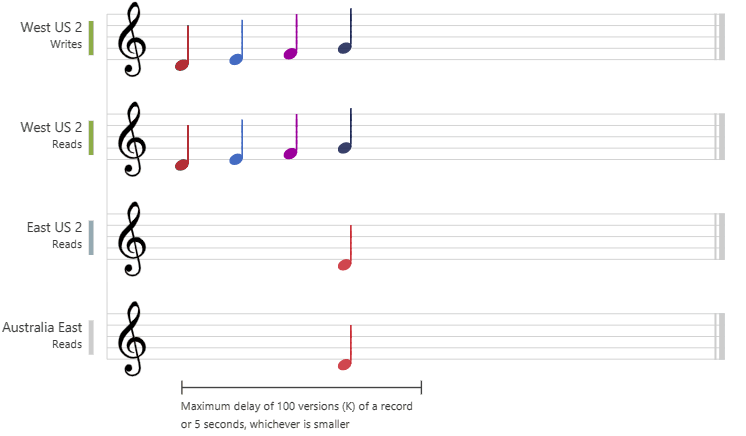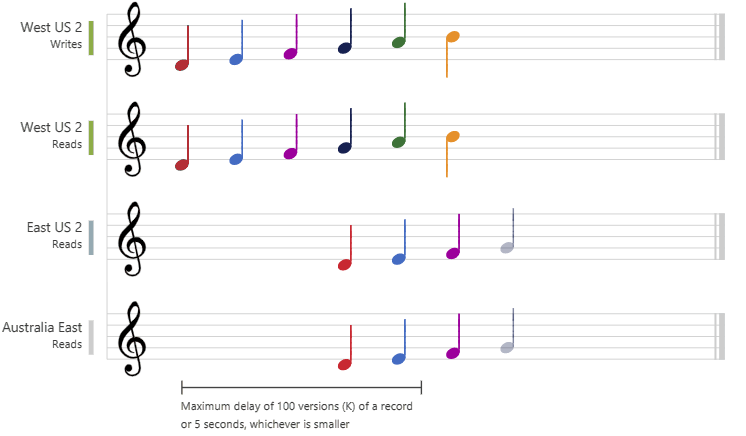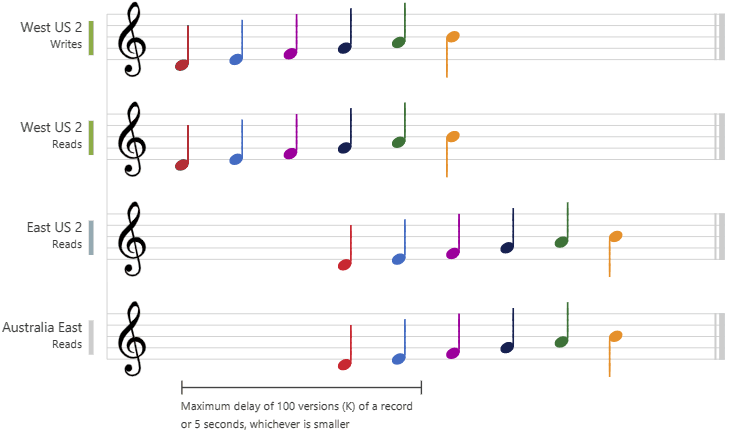
Strong consistency offers a linearizability guarantee. Linearizability refers to serving requests concurrently. The reads are guaranteed to return the most recent committed version of an item. A client never sees an uncommitted or partial write. Users are always guaranteed to read the latest committed write.
The following graphic illustrates the strong consistency with musical notes. After the data is written to the "West US 2" region, when you read the data from other regions, you get the most recent value:

Dynamic quorum
Under normal circumstances, for an account with strong consistency, a write is considered committed when all regions acknowledge that the record has been replicated to it. However, for accounts with 3 regions or more (including the write region), the system can "downshift" the quorum of regions to a global majority in cases where some regions are either unresponsive or responding slowly. At that point, unresponsive regions are taken out of the quorum set of regions in order to preserve strong consistency. They will only be added back once they are consistent with other regions and are performing as expected. The number of regions that can potentially be taken out of the quorum set will depend on the total number of regions. For example, in a 3 or 4 region account, the majority is 2 or 3 regions respectively, so only 1 region can be removed in either case. For a 5 region account, the majority is 3, so up to 2 unresponsive regions can be removed. This capability is known as "dynamic quorum" and can improve both write availability and replication latency for accounts with 3 or more regions.
Note
When regions are removed from the quorum set as part of dynamic quorum, those regions are no longer able to serve reads until re-added into the quorum.
Bounded staleness consistency
For single-region write accounts with two or more regions, data is replicated from the primary region to all secondary (read-only) regions. For multi-region write accounts with two or more regions, data is replicated from the region it was originally written in to all other writable regions. In both scenarios, while not common, there may occasionally be a replication lag from one region to another.
In bounded staleness consistency, the lag of data between any two regions is always less than a specified amount. The amount can be "K" versions (that is, "updates") of an item or by "T" time intervals, whichever is reached first. In other words, when you choose bounded staleness, the maximum "staleness" of the data in any region can be configured in two ways:
- The number of versions (K) of the item
- The time interval (T) reads might lag behind the writes
Bounded Staleness is beneficial primarily to single-region write accounts with two or more regions. If the data lag in a region (determined per physical partition) exceeds the configured staleness value, writes for that partition are throttled until staleness is back within the configured upper bound.
For a single-region account, Bounded Staleness provides the same write consistency guarantees as Session and Eventual Consistency. With Bounded Staleness, data is replicated to a local majority (three replicas in a four replica set) in the single region.
Important
With Bounded Staleness consistency, staleness checks are made only across regions and not within a region. Within a given region, data is always replicated to a local majority (three replicas in a four replica set) regardless of the consistency level.
Reads when using Bounded Staleness returns the latest data available in that region by reading from two available replicas in that region. Since writes within a region always replicate to a local majority (three out of four replicas), consulting two replicas return the most updated data available in that region.
Important
With Bounded Staleness consistency, reads issued against a non-primary region may not necessarily return the most recent version of the data globally, but are guaranteed to return the most recent version of the data in that region, which will be within the maximum staleness boundary globally.
Bounded Staleness works best for globally distributed applications using a single-region write accounts with two or more regions, where near strong consistency across regions is desired. For multi-region write accounts with two or more regions, application servers should direct reads and writes to the same region in which the application servers are hosted. Bounded Staleness in a multi-write account is an anti-pattern. This level would require a dependency on replication lag between regions, which shouldn't matter if data is read from the same region it was written to.
The following graphic illustrates the bounded staleness consistency with musical notes. After the data is written to the "West US 2" region, the "East US 2" and "Australia East" regions read the written value based on the configured maximum lag time or the maximum operations:
Session consistency
In session consistency, within a single client session, reads are guaranteed to honor the read-your-writes, and write-follows-reads guarantees. This guarantee assumes a single “writer” session or sharing the session token for multiple writers.
Like all consistency levels weaker than Strong, writes are replicated to a minimum of three replicas (in a four replica set) in the local region, with asynchronous replication to all other regions.
After every write operation, the client receives an updated Session Token from the server. The client caches the tokens and sends them to the server for read operations in a specified region. If the replica against which the read operation is issued contains data for the specified token (or a more recent token), the requested data is returned. If the replica doesn't contain data for that session, the client retries the request against another replica in the region. If necessary, the client retries the read against extra available regions until data for the specified session token is retrieved.
Important
In Session Consistency, the client’s usage of a session token guarantees that data corresponding to an older session will never be read. However, if the client is using an older session token and more recent updates have been made to the database, the more recent version of the data will be returned despite an older session token being used. The Session Token is used as a minimum version barrier but not as a specific (possibly historical) version of the data to be retrieved from the database.
Session Tokens in Azure Cosmos DB are partition-bound, meaning they are exclusively associated with one partition. In order to ensure you can read your writes, use the session token that was last generated for the relevant item(s).
If the client didn't initiate a write to a physical partition, the client doesn't contain a session token in its cache and reads to that physical partition behave as reads with Eventual Consistency. Similarly, if the client is re-created, its cache of session tokens is also re-created. Here too, read operations follow the same behavior as Eventual Consistency until subsequent write operations rebuild the client’s cache of session tokens.
Important
If Session Tokens are being passed from one client instance to another, the contents of the token should not be modified.
Session consistency is the most widely used consistency level for both single region and globally distributed applications. It provides write latencies, availability, and read throughput comparable to that of eventual consistency. Session consistency also provides the consistency guarantees that suit the needs of applications written to operate in the context of a user. The following graphic illustrates the session consistency with musical notes. The "West US 2 writer" and the "East US 2 reader" are using the same session (Session A) so they both read the same data at the same time. Whereas the "Australia East" region is using "Session B" so, it receives data later but in the same order as the writes.

Consistent prefix consistency
Like all consistency levels weaker than Strong, writes are replicated to a minimum of three replicas (in a four-replica set) in the local region, with asynchronous replication to all other regions.
In consistent prefix, updates made as single document writes see eventual consistency.
Updates made as a batch within a transaction, are returned consistent to the transaction in which they were committed. Write operations within a transaction of multiple documents are always visible together.
Assume two write operations are performed transactionally (all or nothing operations) on document Doc1 followed by document Doc2, within transactions T1 and T2. When client does a read in any replica, the user sees either “Doc1 v1 and Doc2 v1” or “Doc1 v2 and Doc2 v2” or neither document if the replica is lagging, but never “Doc1 v1 and Doc2 v2” or “Doc1 v2 and Doc2 v1” for the same read or query operation.
The following graphic illustrates the consistency prefix consistency with musical notes. In all the regions, the reads never see out of order writes for a transactional batch of writes:

Eventual consistency
Like all consistency levels weaker than Strong, writes are replicated to a minimum of three replicas (in a four replica set) in the local region, with asynchronous replication to all other regions.
In Eventual consistency, the client issues read requests against any one of the four replicas in the specified region. This replica may be lagging and could return stale or no data.
Eventual consistency is the weakest form of consistency because a client may read the values that are older than the ones it read in the past. Eventual consistency is ideal where the application doesn't require any ordering guarantees. Examples include count of Retweets, Likes, or non-threaded comments. The following graphic illustrates the eventual consistency with musical notes.

Consistency guarantees in practice
In practice, you may often get stronger consistency guarantees. Consistency guarantees for a read operation correspond to the freshness and ordering of the database state that you request. Read-consistency is tied to the ordering and propagation of the write/update operations.
If there are no write operations on the database, a read operation with eventual, session, or consistent prefix consistency levels is likely to yield the same results as a read operation with strong consistency level.
If your account is configured with a consistency level other than the strong consistency, you can find out the probability that your clients may get strong and consistent reads for your workloads. You can figure out this probability by looking at the Probabilistically Bounded Staleness (PBS) metric. This metric is exposed in the Azure portal, to learn more, see Monitor Probabilistically Bounded Staleness (PBS) metric.
Probabilistically bounded staleness shows how eventual is your eventual consistency. This metric provides an insight into how often you can get a stronger consistency than the consistency level that you've currently configured on your Azure Cosmos DB account. In other words, you can see the probability (measured in milliseconds) of getting consistent reads for a combination of write and read regions.
Consistency levels and latency
The read latency for all consistency levels is always guaranteed to be less than 10 milliseconds at the 99th percentile. The average read latency, at the 50th percentile, is typically 4 milliseconds or less.
The write latency for all consistency levels is always guaranteed to be less than 10 milliseconds at the 99th percentile. The average write latency, at the 50th percentile, is usually 5 milliseconds or less. Azure Cosmos DB accounts that span several regions and are configured with strong consistency are an exception to this guarantee.
Write latency and Strong consistency
For Azure Cosmos DB accounts configured with strong consistency with more than one region, the write latency is equal to two times round-trip time (RTT) between any of the two farthest regions, plus 10 milliseconds at the 99th percentile. High network RTT between the regions will translate to higher latency for Azure Cosmos DB requests since strong consistency completes an operation only after ensuring that it has been committed to all regions within an account.
The exact RTT latency is a function of speed-of-light distance and the Azure networking topology. Azure networking doesn't provide any latency SLAs for the RTT between any two Azure regions, however it does publish Azure network round-trip latency statistics. For your Azure Cosmos DB account, replication latencies are displayed in the Azure portal. You can use the Azure portal by going to the Metrics section and then selecting the Consistency option. Using the Azure portal, you can monitor the replication latencies between various regions that are associated with your Azure Cosmos DB account.
Important
Strong consistency for accounts with regions spanning more than 5000 miles (8000 kilometers) is blocked by default due to high write latency. To enable this capability please contact support.
Consistency levels and throughput
For strong and bounded staleness, reads are done against two replicas in a four replica set (minority quorum) to provide consistency guarantees. Session, consistent prefix and eventual do single replica reads. The result is that, for the same number of request units, read throughput for strong and bounded staleness is half of the other consistency levels.
For a given type of write operation, such as insert, replace, upsert, and delete, the write throughput for request units is identical for all consistency levels. For strong consistency, changes need to be committed in every region (global majority) while for all other consistency levels, local majority (three replicas in a four replica set) is being used.
| Consistency Level | Quorum Reads | Quorum Writes |
|---|---|---|
| Strong | Local Minority | Global Majority |
| Bounded Staleness | Local Minority | Local Majority |
| Session | Single Replica (using session token) | Local Majority |
| Consistent Prefix | Single Replica | Local Majority |
| Eventual | Single Replica | Local Majority |
Note
The RUs cost of reads for Local Minority reads is twice that of weaker consistency levels because reads are made from two replicas to provide consistency guarantees for the Strong and Bounded Staleness consistency levels.
Consistency levels and data durability
Within a globally distributed database environment, there's a direct relationship between the consistency level and data durability in the presence of a region-wide outage. As you develop your business continuity plan, you need to understand the maximum period of recent data updates the application can tolerate losing when recovering after a disruptive event. The time period of updates that you might afford to lose is known as recovery point objective (RPO).
This table defines the relationship between consistency model and data durability in the presence of a region wide outage.
| Region(s) | Replication mode | Consistency level | RPO |
|---|---|---|---|
| 1 | Single or Multiple write regions | Any Consistency Level | < 240 Minutes |
| >1 | Single write region | Session, Consistent Prefix, Eventual | < 15 minutes |
| >1 | Single write region | Bounded Staleness | K & T |
| >1 | Single write region | Strong | 0 |
| >1 | Multiple write regions | Session, Consistent Prefix, Eventual | < 15 minutes |
| >1 | Multiple write regions | Bounded Staleness | K & T |
K = The number of "K" versions (that is, updates) of an item.
T = The time interval "T" since the last update.
For a single region account, the minimum value of K and T is 10 write operations or 5 seconds. For multi-region accounts the minimum value of K and T is 100,000 write operations or 300 seconds. This value defines the minimum RPO for data when using Bounded Staleness.
Strong consistency and multiple write regions
Azure Cosmos DB accounts configured with multiple write regions can't be configured for strong consistency as it isn't possible for a distributed system to provide an RPO of zero and an RTO of zero. Additionally, there are no write latency benefits on using strong consistency with multiple write regions because a write to any region must be replicated and committed to all configured regions within the account. This scenario results in the same write latency as a single write region account.
More reading
To learn more about consistency concepts, read the following articles:
- High-level TLA+ specifications for the five consistency levels offered by Azure Cosmos DB
- Replicated Data Consistency Explained Through Baseball (video) by Doug Terry
- Replicated Data Consistency Explained Through Baseball (whitepaper) by Doug Terry
- Session guarantees for weakly consistent replicated data
- Consistency Tradeoffs in Modern Distributed Database Systems Design: CAP is Only Part of the Story
- Probabilistic Bounded Staleness (PBS) for Practical Partial Quorums
- Eventually Consistent - Revisited