Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Denne veiledningen tar deg gjennom et komplett dataintegrasjonsscenario på omtrent en time. Du vil lære de viktigste funksjonene til Data Factory i Microsoft Fabric og hvordan du kan bruke dem i vanlige dataflyter.
Hva du skal bygge
Denne veiledningen inkluderer en introduksjon og tre moduler:
- Modul 1 – Ta inn data med en kopijobb: Lag en frittstående kopijobb for å importere rådata fra Blob-lagring til en bronsetabell i et innsjøhus.
- Modul 2 – Transformer data med en dataflyt: Behandle rådata fra bronsetabellen din og flytt dem til en gulltabell i Lakehouse.
- Modul 3 – Orkestrere og automatisere med en pipeline: Lag en pipeline for å orkestrere kopijobben og dataflyten, send en e-postvarsling når jobbene er ferdige, og planlegg hele flyten.
Data Factory i Microsoft Fabric
Microsoft Fabric er en samlet analyseplattform som dekker databevegelse, datalakes, dataingeniørarbeid, dataintegrasjon, datavitenskap, sanntidsanalyse og forretningsintelligens. Du trenger ikke å sette sammen tjenester fra flere leverandører.
Data Factory i Fabric kombinerer brukervennligheten til Power Query med skalaen Azure Data Factory. Det tilbyr lavkode, AI-drevet dataforberedelse, petabyte-skala transformasjon og hundrevis av tilkoblinger med hybrid- og multicloud-tilkobling.
Viktige funksjoner
Data Factory tilbyr tre kjernefunksjoner for dine behov for dataintegrasjon:
- Datainntak med kopijobb: En kopijobb er det anbefalte utgangspunktet for datainntak. Den flytter petabyte-skala data fra hundrevis av datakilder inn i Lakehouse-systemet ditt, med innebygd støtte for bulk-, inkrementell og CDC-basert kopiering – uten å måtte bygge en pipeline.
- Datatransformasjon: Dataflow Gen2 tilbyr et lavkodegrensesnitt for å transformere dataene dine med 300+ transformasjoner. Du kan laste inn resultater til flere destinasjoner som Azure SQL Database, Lakehouse og flere.
- Ende-til-ende-automatisering: Pipelines orkestrerer aktiviteter som kopieringsjobb, dataflyt, notatbok og mer. Kjede sammen aktiviteter for å kjøre sekvensielt eller parallelt. Overvåk hele dataintegrasjonsflyten din på ett sted.
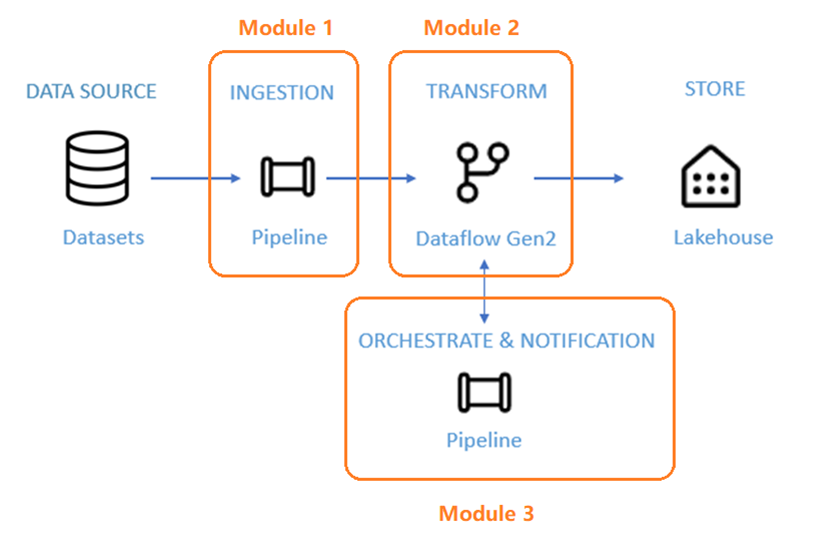
Opplæring arkitektur
Du vil utforske alle tre nøkkelfunksjonene mens du fullfører et helhetlig dataintegrasjonsscenario.
Scenarioet inkluderer tre moduler:
- Ta inn data med en kopijobb: Lag en frittstående kopijobb for å importere rådata fra Blob-lagring til en bronsetabell i et Lakehouse.
- Transformer data med en dataflyt: Behandle rådataene fra bronsetabellen din og flytt dem til en gulltabell .
- Orkestrere og automatiser med en pipeline: Lag en pipeline for å orkestrere kopijobben og dataflyten, send en e-postvarsling, og planlegg hele flyten.
Denne veiledningen bruker NYC-Taxi-eksempeldatasettet . Når du er ferdig, kan du analysere daglige rabatter på taxipriser for en bestemt tidsperiode ved hjelp av Data Factory i Microsoft Fabric.