Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Denne veiledningen presenterer et helhetlig eksempel på en Synapse Data Science-arbeidsflyt i Microsoft Fabric. Scenarioet bygger en modell for online bokanbefalinger.
Denne opplæringen dekker disse trinnene:
- Laste opp dataene til et lakehouse
- Utfør utforskende analyse på dataene
- Kalibrer en modell, og logg den med MLflow
- Last inn modellen og gjør prognoser
Mange typer anbefalingsalgoritmer er tilgjengelige. Denne opplæringen bruker algoritmen for vekslende minst kvadrater (ALS) matrisefaktorisering. ALS er en modellbasert algoritme for filtrering av samarbeid.

ALS prøver å estimere rangeringsmatrisen R som produkt av to matriser med lavere rangering, deg og V. Her, R = U * Vt. Vanligvis kalles disse tilnærmingene faktor matriser.
ALS-algoritmen er iterativ. Hver gjentakelse holder en av faktoren matriser konstant, mens den løser den andre ved hjelp av metoden minst firkanter. Den holder deretter den nylig løste faktormatrisekonstanten mens den løser den andre faktormatrisen.

Forutsetninger
Skaff deg et abonnement Microsoft Fabric. Eller meld deg på en gratis prøveperiode Microsoft Fabric.
Logg inn på Microsoft Fabric.
Bytt til Fabric ved å bruke erfaringsbryteren nederst til venstre på hjemmesiden din.

- Om nødvendig, lag et Microsoft Fabric innsjøhus som beskrevet i Lag et innsjøhus i Microsoft Fabric.
Følg med i en notatblokk
Velg ett av disse alternativene å følge i en notatbok:
- Åpne og kjør den innebygde notatblokken.
- Last opp notatboken din fra GitHub.
Åpne den innebygde notatblokken
Eksemplet Bokanbefaling notatblokk følger med denne opplæringen.
Hvis du vil åpne eksempelnotatblokken for denne opplæringen, følger du instruksjonene i Klargjør systemet for.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Importer notatboken fra GitHub
Notatboken AIsample - Book Recommendation.ipynb følger med denne veiledningen.
Hvis du vil åpne den medfølgende notatblokken for denne opplæringen, følger du instruksjonene i Klargjøre systemet for opplæringer om datavitenskap importere notatblokken til arbeidsområdet.
Hvis du heller vil kopiere og lime inn koden fra denne siden, kan du opprette en ny notatblokk.
Pass på å feste et lakehouse til notatblokken før du begynner å kjøre kode.
Trinn 1: Laste inn dataene
Datasettet for bokanbefalinger i dette scenarioet består av tre separate datasett:
Books.csv: Et internasjonalt standardboknummer (ISBN) identifiserer hver bok, der ugyldige datoer allerede er fjernet. Datasettet inkluderer også tittel, forfatter og publisher. For en bok med flere forfattere viser den Books.csv filen bare den første forfatteren. NETTADRESSER peker på Amazons nettstedsressurser for forsidebildene, i tre størrelser.
ISBN Book-Title Book-Author År-Of-Publication Publisher Bilde-URL-S Bilde-URL-M Bilde-URL-l 0195153448 Klassisk mytologi P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Vurderinger for hver bok er enten eksplisitte (levert av brukere, på en skala fra 1 til 10) eller implisitt (observert uten brukerinndata, og angitt med 0).
User-ID ISBN Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: Bruker-ID-er anonymiseres og tilordnes heltall. Demografiske data – for eksempel sted og alder – oppgis, hvis de er tilgjengelige. Hvis disse dataene ikke er tilgjengelige, er disse verdiene
null.User-ID Plassering Alder 1 "Nyc New York USA" 2 "Stockton California USA" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Definer disse parameterne, slik at du kan bruke denne notatblokken med forskjellige datasett:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Laste ned og lagre dataene i et lakehouse
Denne koden laster ned datasettet, og lagrer det deretter i lakehouse.
Viktig
Pass på å legge til et lakehouse- i notatblokken før du kjører den. Ellers får du en feil.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Konfigurere sporing av MLflow-eksperimenter
Bruk denne koden til å konfigurere sporing av MLflow-eksperimenter. Dette eksemplet deaktiverer autologging. For mer informasjon, se artikkelen Autologging i Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Les data fra lakehouse
Etter at du har plassert riktige data i lakehouse, les de tre datasettene inn i separate Spark DataFrames i notatboken. Filbanene i denne koden bruker parameterne som er definert tidligere.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Trinn 2: Utfør utforskende dataanalyse
Vis rådata
Utforsk DataFrames ved å bruke kommandoen display . Ved å bruke denne kommandoen kan du se høynivå DataFrame-statistikk og forstå hvordan ulike datasettkolonner henger sammen. Før du utforsker datasettene, kan du bruke denne koden til å importere de nødvendige bibliotekene:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Bruk denne koden til å se på DataFrame som inneholder bokdataene:
display(df_items, summary=True)
Legg til en _item_id kolonne for senere bruk. Den _item_id verdien må være et heltall for anbefalingsmodeller. Denne koden bruker StringIndexer til å transformere ITEM_ID_COL til indekser:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Vis datarammen, og kontroller om _item_id-verdien øker monotont og etterfølgende, som forventet:
display(df_items.sort(F.col("_item_id").desc()))
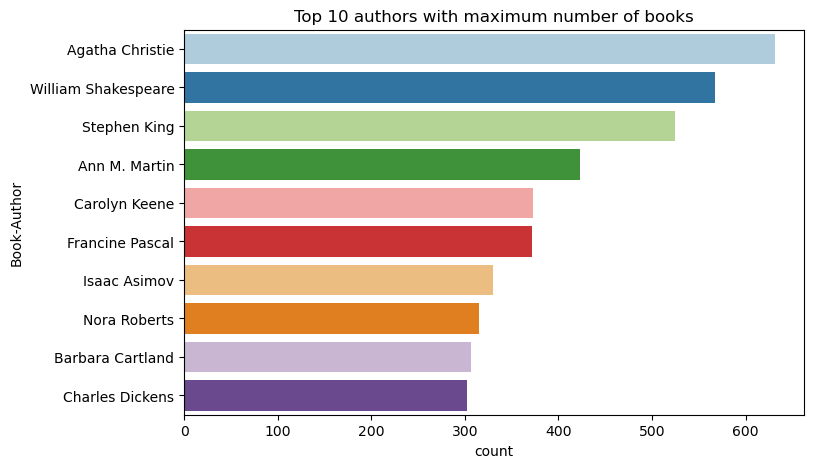
Bruk denne koden til å tegne inn de ti beste forfatterne, etter antall bøker skrevet, i synkende rekkefølge. Agatha Christie er den ledende forfatteren med mer enn 600 bøker, etterfulgt av William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Deretter viser du datarammen som inneholder brukerdataene:
display(df_users, summary=True)
Hvis en rad mangler User-ID verdi, slipper du denne raden. Manglende verdier i et tilpasset datasett forårsaker ikke problemer.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Legg til en _user_id kolonne for senere bruk. For anbefalingsmodeller må _user_id-verdien være et heltall. Følgende kodeeksempel bruker StringIndexer til å transformere USER_ID_COL til indekser.
Bokdatasettet har allerede et heltall User-ID kolonne. Hvis du imidlertid legger til en _user_id kolonne for kompatibilitet med ulike datasett, blir dette eksemplet mer robust. Bruk denne koden til å legge til kolonnen _user_id:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Bruk denne koden til å vise vurderingsdataene:
display(df_ratings, summary=True)
Få de distinkte vurderingene, og lagre dem for senere bruk i en liste med navnet ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
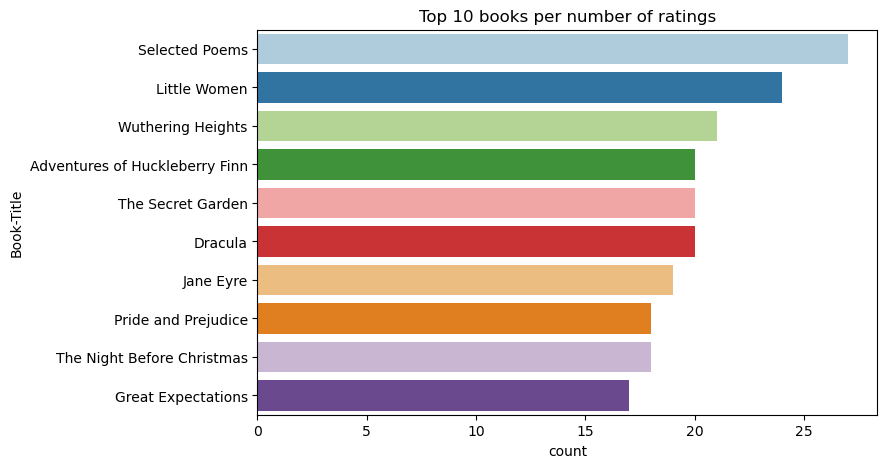
Bruk denne koden til å vise de 10 beste bøkene med høyest rangering:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Ifølge rangeringene er Selected Poems den mest populære boken. Adventures of Huckleberry Finn, The Secret Gardenog Dracula har samme vurdering.
Slå sammen data
Slå sammen de tre datarammene til én DataFrame for en mer omfattende analyse:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Bruk denne koden til å vise antall distinkte brukere, bøker og samhandlinger:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Beregne og tegne inn de mest populære elementene
Bruk denne koden til å beregne og vise de ti mest populære bøkene:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Tips
Bruk <topn>-verdien for Populære eller Øverste kjøpte anbefalingsdeler.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Klargjøre opplærings- og testdatasett
ALS-matrisen krever litt dataforberedelse før opplæring. Bruk dette kodeeksempelet til å klargjøre dataene. Koden utfører disse handlingene:
- Kast vurderingskolonnen til riktig type.
- Ta et utvalg av treningsdataene med brukervurderinger.
- Del dataene opp i trenings- og testdatasett.
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsity refererer til sparsomme tilbakemeldingsdata, som ikke kan identifisere likheter i brukernes interesser. Hvis du vil ha en bedre forståelse av både dataene og det gjeldende problemet, kan du bruke denne koden til å beregne datasettsparsiteten:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Trinn 3: Utvikle og lære opp modellen
Lær opp en ALS-modell for å gi brukerne tilpassede anbefalinger.
Definer modellen
Spark ML gir en praktisk API for bygging av ALS-modellen. Modellen håndterer imidlertid ikke problemer som dataparsitet og kald start på en pålitelig måte (anbefalinger når brukerne eller elementene er nye). Hvis du vil forbedre modellytelsen, kan du kombinere kryssvalidering og automatisk hyperparameterjustering.
Bruk denne koden til å importere bibliotekene som kreves for modellopplæring og evaluering:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Justere modellhyperparametere
Neste kodeeksempel konstruerer et parameterrutenett for å hjelpe til med å søke over hyperparameterne. Koden oppretter også en regresjonsevaluator som bruker rot-middel-kvadratfeilen (RMSE) som evalueringsmetrikk:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
Det neste kodeeksempelet starter ulike modelljusteringsmetoder basert på de forhåndskonfigurerte parameterne. Hvis du vil ha mer informasjon om modelljustering, kan du se ML-justering: modellvalg og hyperparameterjustering på Apache Spark-nettstedet.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Evaluer modellen
Evaluer modellene mot testdataene. En godt trent modell har høye måleparametere på datasettet.
En overtilpasset modell kan trenge mer treningsdata eller en reduksjon av noen overflødige funksjoner. Du må kanskje endre modellarkitekturen eller finjustere parameterne.
Notat
En negativ R-kvadrert metrisk verdi indikerer at den opplærte modellen utfører dårligere enn en vannrett, rett linje. Dette funnet tyder på at den opplærte modellen ikke forklarer dataene.
Bruk denne koden til å definere en evalueringsfunksjon:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Spore eksperimentet ved hjelp av MLflow
Bruk MLflow til å spore alle eksperimentene og til å logge parametere, måledata og modeller. Bruk denne koden for å starte modellopplæring og evaluering:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Velg eksperimentet med navnet aisample-recommendation fra arbeidsområdet for å vise den loggførte informasjonen for opplæringskjøringen. Hvis du endrer eksperimentnavnet, velg eksperimentet som har det nye navnet. Den loggførte informasjonen ligner på dette bildet:

Trinn 4: Last inn den endelige modellen for scoring og forutsigelser
Etter at du er ferdig med å trene modellen og velger den beste modellen, laster du inn modellen for poenggiving (noen ganger kalt inferens). Denne koden laster inn modellen og bruker prognoser til å anbefale de ti mest populære bøkene for hver bruker:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Utdataene ligner på denne tabellen:
| _item_id | _user_id | klassifisering | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Livene til ... |
| 786 | 7 | 6.2255826 | Pianomannens D... |
| 45330 | 7 | 4.980466 | Sinnstilstand |
| 38960 | 7 | 4.980466 | Alt han noensinne har ønsket |
| 125415 | 7 | 4.505084 | Harry Potter og ... |
| 44939 | 7 | 4.3579073 | Taltos: Livene til ... |
| 175247 | 7 | 4.3579073 | Bonesetter's ... |
| 170183 | 7 | 4.228735 | Å leve det enkle ... |
| 88503 | 7 | 4.221206 | Øya Blu... |
| 32894 | 7 | 3.9031885 | Vintersolverv |
Lagre prognosene til lakehouse
Bruk denne koden til å skrive anbefalingene tilbake til lakehouse:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)
Relatert innhold
- Kalibrer og evaluer en tekstklassifiseringsmodell
Machine learning modell i Microsoft Fabric - Train machine learning modeller
- Machine learning eksperimenter i Microsoft Fabric