Direct Lake
Direct Lake-modus er en semantisk modellfunksjonalitet for analyse av svært store datavolumer i Power BI. Direct Lake er basert på innlasting av parkettformaterte filer direkte fra en datainnsjø uten å måtte spørre et lakehouse- eller lagerendepunkt, og uten å måtte importere eller duplisere data til en Power BI-modell. Direct Lake er en rask bane for å laste inn dataene fra innsjøen rett inn i Power BI-motoren, klar for analyse. Diagrammet nedenfor viser hvordan klassiske import- og DirectQuery-moduser sammenlignes med Direct Lake-modus.
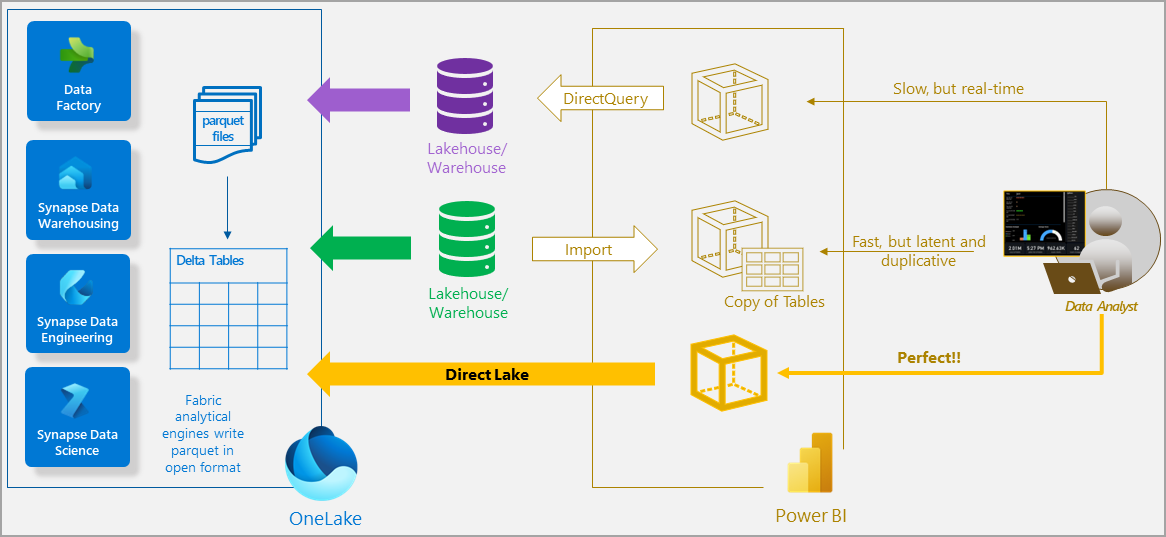
I DirectQuery-modus spør Power BI-motoren dataene på kilden, noe som kan være tregt, men unngår å måtte kopiere dataene som med importmodus. Eventuelle endringer i datakilden gjenspeiles umiddelbart i spørringsresultatene.
Med importmodus kan ytelsen derimot bli bedre fordi dataene bufres og optimaliseres for DAX- og MDX-rapportspørringer uten å måtte oversette og sende SQL eller andre typer spørringer til datakilden. Power BI-motoren må imidlertid først kopiere nye data til modellen under oppdatering. Eventuelle endringer i kilden hentes bare med neste modelloppdatering.
Direct Lake-modus eliminerer importkravet ved å laste inn dataene direkte fra OneLake. I motsetning til DirectQuery er det ingen oversettelse fra DAX eller MDX til andre spørringsspråk eller spørringskjøring på andre databasesystemer, noe som gir ytelse som ligner på importmodus. Fordi det ikke er noen eksplisitt importprosess, er det mulig å plukke opp eventuelle endringer i datakilden etter hvert som de oppstår, og kombinere fordelene med både DirectQuery og importmoduser samtidig som de unngår ulempene. Direct Lake-modus kan være det ideelle valget for å analysere svært store modeller og modeller med hyppige oppdateringer på datakilden.
Direct Lake støtter også sikkerhet på radnivå og sikkerhet på objektnivå , slik at brukerne bare ser dataene de har tillatelse til å se.
Forutsetning
Direct Lake støttes bare på SKU-er for Microsoft Premium (P) og Microsoft Fabric (F).
Viktig
For nye kunder støttes Direct Lake bare på SKU-er for Microsoft Fabric (F). Eksisterende kunder kan fortsette å bruke Direct Lake med Premium (P) SKU-er, men overgang til en SKU for stoffkapasitet anbefales. Se lisensieringskunngjøringen for mer informasjon om Power BI Premium-lisensiering.
Lakehouse
Før du bruker Direct Lake, må du klargjøre et lakehouse (eller et lager) med én eller flere Delta-tabeller i et arbeidsområde som driftes på en støttet Microsoft Fabric-kapasitet. Lakehouse er nødvendig fordi det gir lagringsplass for parkettformaterte filer i OneLake. Lakehouse gir også et tilgangspunkt for å starte nettmodelleringsfunksjonen for å opprette en Direct Lake-modell.
Hvis du vil lære hvordan du klargjør et lakehouse, oppretter du et Delta-bord i lakehouse, og oppretter en grunnleggende modell for lakehouse, kan du se Opprette et lakehouse for Direct Lake.
SQL-endepunkt
Som en del av klargjøringen av et lakehouse opprettes og oppdateres et SQL-endepunkt for SQL-spørring og en standardmodell for rapportering med alle tabeller som er lagt til lakehouse. Selv om Direct Lake-modus ikke spør etter SQL-endepunktet når du laster inn data direkte fra OneLake, er det nødvendig når en Direct Lake-modell sømløst må falle tilbake til DirectQuery-modus, for eksempel når datakilden bruker bestemte funksjoner som avansert sikkerhet eller visninger som ikke kan leses gjennom Direct Lake. Direct Lake-modus spør også SQL-endepunktet for skjema- og sikkerhetsrelatert informasjon.
Datalager
Som et alternativ til et lakehouse med SQL-endepunkt, kan du også klargjøre et lager og legge til tabeller ved hjelp av SQL-setninger eller datasamlebånd. Fremgangsmåten for å klargjøre et frittstående datalager er nesten identisk med prosedyren for et innsjøhus.
Skrivestøtte for modell med XMLA-endepunkt
Direct Lake-modeller støtter skriveoperasjoner gjennom XMLA-endepunktet ved hjelp av verktøy som SQL Server Management Studio (19.1 og nyere), og de nyeste versjonene av eksterne BI-verktøy som Tabular Editor og DAX Studio. Modellskrivingsoperasjoner gjennom XMLA-endepunktstøtte:
Tilpassing, sammenslåing, skripting, feilsøking og testing av metadata for Direct Lake-modellen.
Kilde- og versjonskontroll, kontinuerlig integrasjon og kontinuerlig distribusjon (CI/CD) med Azure DevOps og GitHub.
Automatiseringsoppgaver som oppdatering og bruk av endringer i Direct Lake-modeller ved hjelp av PowerShell- og REST-API-er.
Vær oppmerksom på at Direct Lake-tabeller som er opprettet ved hjelp av XMLA-programmer, i utgangspunktet vil være i en ubehandlet tilstand inntil programmet utsteder en oppdateringskommando. Ubehandlede tabeller faller tilbake til DirectQuery-modus. Når du oppretter en ny semantisk modell, må du passe på å oppdatere den semantiske modellen for å behandle tabellene.
Aktiver skrivetilgang for XMLA
Før du utfører skriveoperasjoner på Direct Lake-modeller gjennom XMLA-endepunktet, må XMLA-leseskriving være aktivert for kapasiteten.
For prøveversjonskapasiteter for Fabric har prøvebrukeren administratorrettigheter som er nødvendige for å aktivere XMLA-leseskriving.
Velg Kapasitetsinnstillinger i administrasjonsportalen.
Klikk på Prøveversjon-fanen .
Velg kapasiteten med prøveversjon og brukernavn i kapasitetsnavnet.
Utvid Power BI-arbeidsbelastninger, og velg deretter Les skrive i INNSTILLINGEN XMLA-endepunkt.
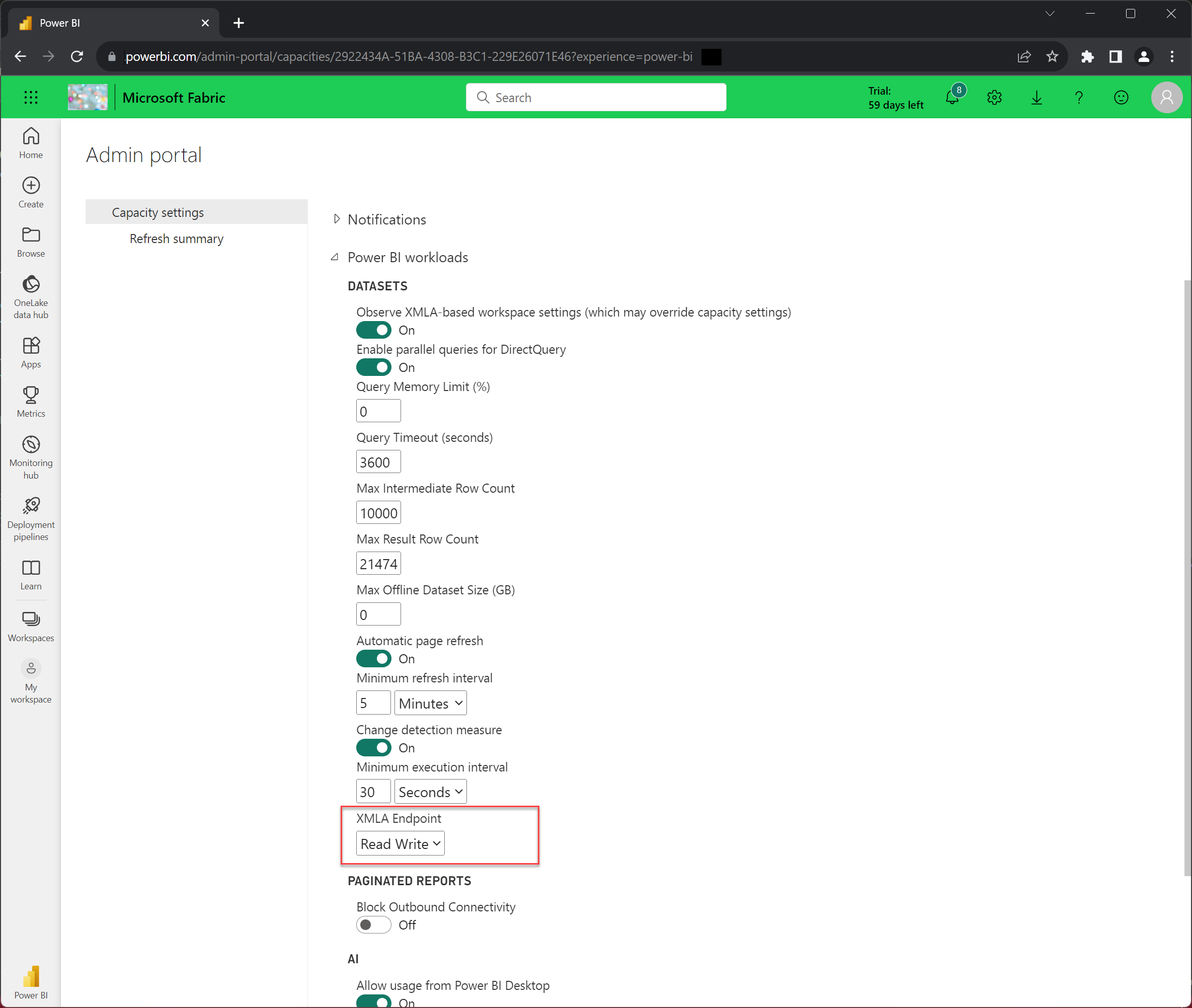
Husk at INNSTILLINGEN XMLA-endepunkt gjelder for alle arbeidsområder og modeller som er tilordnet kapasiteten.
Metadata for Direct Lake-modell
Når du kobler til en frittstående Direct Lake-modell gjennom XMLA-endepunktet, ser metadataene ut som alle andre modeller. Direct Lake-modeller viser imidlertid følgende forskjeller:
Egenskapen
compatibilityLevelfor databaseobjektet er 1604 eller høyere.Egenskapen
Modefor Direct Lake-partisjoner er satt tildirectLake.Direct Lake-partisjoner bruker delte uttrykk til å definere datakilder. Uttrykket peker til SQL-endepunktet for et lakehouse eller lager. Direct Lake bruker SQL-endepunktet til å oppdage skjema- og sikkerhetsinformasjon, men laster inn dataene direkte fra Delta-tabellene (med mindre Direct Lake må falle tilbake til DirectQuery-modus av en eller annen grunn).
Her er et eksempel på XMLA-spørring i SSMS:
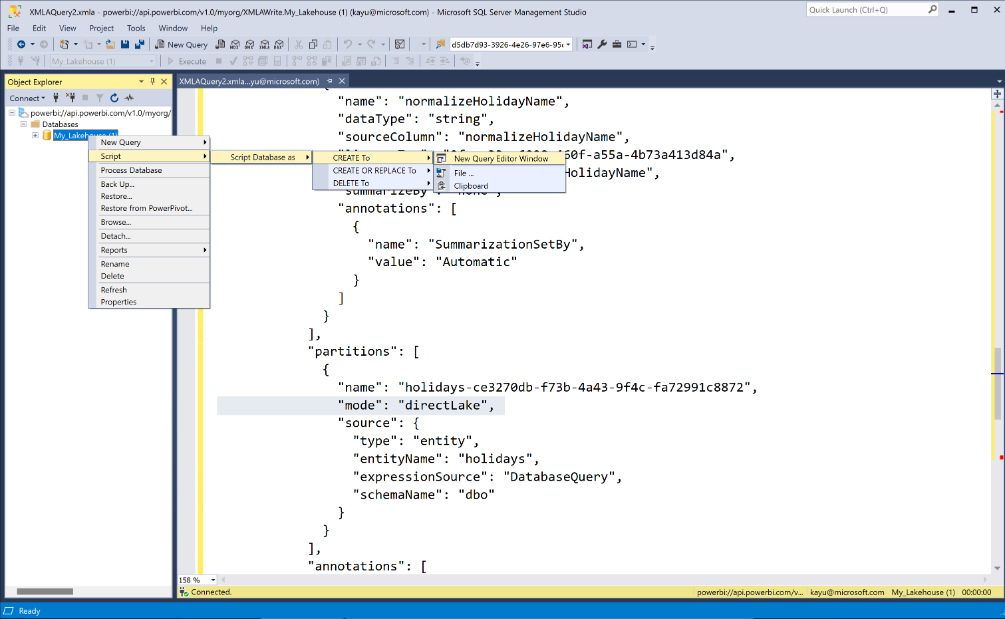
Hvis du vil lære mer om verktøystøtte gjennom XMLA-endepunktet, kan du se semantisk modelltilkobling med XMLA-endepunktet.
Basis
Semantiske Power BI-modeller i Direct Lake-modus leser Delta-tabeller direkte fra OneLake. Hvis en DAX-spørring på en Direct Lake-modell overskrider grensene for SKU-en, eller bruker funksjoner som ikke støtter Direct Lake-modus, for eksempel SQL-visninger i et lager, kan spørringen falle tilbake til DirectQuery-modus. I DirectQuery-modus bruker spørringer SQL til å hente resultatene fra SQL-endepunktet til lakehouse eller lageret, noe som kan påvirke spørringsytelsen. Du kan deaktivere tilbakefall til DirectQuery-modus hvis du bare vil behandle DAX-spørringer i ren Direct Lake-modus. Deaktivering av tilbakefall anbefales hvis du ikke trenger tilbakefall til DirectQuery. Det kan også være nyttig når du analyserer spørringsbehandling for en Direct Lake-modell for å identifisere om og hvor ofte fallbacks oppstår. Hvis du vil lære mer om DirectQuery-modus, kan du se semantiske modellmoduser i Power BI.
Guardrails definerer ressursgrenser for Direct Lake-modus utover det som er nødvendig med en tilbakefall til DirectQuery-modus for å behandle DAX-spørringer. Hvis du vil ha mer informasjon om hvordan du fastslår antall parquetfiler og radgrupper for en Delta-tabell, kan du se referansen for egenskaper for Delta-tabellen.
For semantiske modeller i Direct Lake representerer Max Memory den øvre minneressursgrensen for hvor mye data som kan sidees inn. I praksis er det ikke et rekkverk fordi overskridelse av det ikke forårsaker et fallback til DirectQuery; Det kan imidlertid ha en ytelseseffekt hvis datamengden er stor nok til å forårsake sideveksling inn og ut av modelldataene fra OneLake-dataene.
Tabellen nedenfor viser både ressursrekkverk og maksimalt minne:
| Stoff SKU-er | Parquet-filer per tabell | Radgrupper per tabell | Rader per tabell (millioner) | Maksimal modellstørrelse på disk/OneLake1 (GB) | Maksimalt minne (GB) |
|---|---|---|---|---|---|
| F2 | 1 000 | 1,000 | 300 | 10 | 3 |
| F4 | 1 000 | 1,000 | 300 | 10 | 3 |
| F8 | 1 000 | 1,000 | 300 | 10 | 3 |
| F16 | 1 000 | 1,000 | 300 | 20 | 5 |
| F32 | 1 000 | 1,000 | 300 | 40 | 10 |
| F64/FT1/P1 | 5 000 | 5 000 | 1,500 | Ubegrenset | 25 |
| F128/P2 | 5 000 | 5 000 | 3 000 | Ubegrenset | 50 |
| F256/P3 | 5 000 | 5 000 | 6 000 | Ubegrenset | 100 |
| F512/P4 | 10,000 | 10 000 | 12,000 | Ubegrenset | 200 |
| F1024/P5 | 10,000 | 10,000 | 24,000 | Ubegrenset | 400 |
| F2048 | 10,000 | 10,000 | 24,000 | Ubegrenset | 400 |
1 – Hvis den overskrides, vil maksimal modellstørrelse på disk/Onelake føre til at alle spørringer til modellen faller tilbake til DirectQuery, i motsetning til andre rekkverk som evalueres per spørring.
Avhengig av stoff-SKU-en gjelder også ekstra kapasitetsenhet og maksimalt minne per spørringsgrenser for Direct Lake-modeller. Hvis du vil ha mer informasjon, kan du se Kapasiteter og SKU-er.
Tilbakefallsvirkemåte
Direct Lake-modeller inkluderer DirectLakeBehavior-egenskapen , som har tre alternativer:
Automatisk – (standard) Angir at spørringer faller tilbake til DirectQuery-modus hvis data ikke kan lastes inn i minnet på en effektiv måte.
DirectLakeOnly – Angir bare alle spørringer som bruker Direct Lake-modus. Tilbakefall til DirectQuery-modus er deaktivert. Hvis data ikke kan lastes inn i minnet, returneres en feil. Bruk denne innstillingen til å avgjøre om DAX-spørringer ikke laster inn data i minnet, noe som tvinger en feil til å returneres.
DirectQueryOnly – Angir at alle spørringer bare bruker DirectQuery-modus. Bruk denne innstillingen til å teste tilbakefallsytelsen.
Egenskapen DirectLakeBehavior kan konfigureres ved hjelp av Tabular Object Model (TOM) eller Tabular Model Scripting Language (TMSL).
Følgende eksempel angir at alle spørringer bare bruker Direct Lake-modus:
// Disable fallback to DirectQuery mode.
//
database.Model.DirectLakeBehavior = DirectLakeBehavior.DirectLakeOnly = 1;
database.Model.SaveChanges();
Analyser spørringsbehandling
Hvis du vil finne ut om DAX-spørringer for et rapportvisualobjekt til datakilden gir best ytelse ved hjelp av Direct Lake-modus eller går tilbake til DirectQuery-modus, kan du bruke ytelsesanalyse i Power BI Desktop, SQL Server Profiler eller andre tredjepartsverktøy til å analysere spørringer. Hvis du vil ha mer informasjon, kan du se Analyser spørringsbehandling for Direct Lake-modeller.
Oppdater
Som standard gjenspeiles dataendringer i OneLake automatisk i en Direct Lake-modell. Du kan endre denne virkemåten ved å deaktivere Hold Direct Lake-dataene oppdatert i modellens innstillinger.

Du vil kanskje deaktivere hvis du for eksempel må tillate fullføring av dataforberedelsesjobber før du eksponerer nye data til forbrukere av modellen. Når deaktivert, kan du aktivere oppdatering manuelt eller ved hjelp av oppdaterings-API-ene. Aktivering av en oppdatering for en Direct Lake-modell er en lavprisoperasjon der modellen analyserer metadataene til den nyeste versjonen av Delta Lake-tabellen og oppdateres for å referere til de nyeste filene i OneLake.
Vær oppmerksom på at Power BI kan stanse automatiske oppdateringer av Direct Lake-tabeller midlertidig hvis det oppstår en uopprettelig feil under oppdateringen, så kontroller at den semantiske modellen kan oppdateres. Power BI gjenopptar automatiske oppdateringer når en etterfølgende brukeraktivert oppdatering fullføres uten feil.
Lagvis datatilgangssikkerhet
Direct Lake-modeller som er opprettet på toppen av innsjøer og varehus, overholder den lagdelte sikkerhetsmodellen som lakehouses og varehus støtter ved å utføre tillatelseskontroller gjennom T-SQL Endpoint for å finne ut om identiteten som prøver å få tilgang til dataene, har de nødvendige datatilgangstillatelsene. Som standard bruker Direct Lake-modeller enkel pålogging (SSO), slik at de effektive tillatelsene til den interaktive brukeren bestemmer om brukeren er tillatt eller nektet tilgang til dataene. Hvis Direct Lake-modellen er konfigurert til å bruke en fast identitet, bestemmer den effektive tillatelsen til den faste identiteten om brukere som samhandler med den semantiske modellen, får tilgang til dataene. T-SQL-endepunktet returnerer Tillatt eller Nektet direct Lake-modellen basert på kombinasjonen av OneLake-sikkerhet og SQL-tillatelser.
En lageradministrator kan for eksempel gi en bruker SELECT-tillatelser i en tabell, slik at brukeren kan lese fra tabellen selv om brukeren ikke har sikkerhetstillatelser for OneLake. Brukeren ble godkjent på lakehouse/lagernivå. En lageradministrator kan derimot også nekte en bruker lesetilgang til en tabell. Brukeren vil da ikke kunne lese fra tabellen selv om brukeren har lesetillatelser for OneLake-sikkerhet. DENY-setningen overstyrer alle tildelte OneLake-sikkerhets- eller SQL-tillatelser. Se tabellen nedenfor for de effektive tillatelsene en bruker kan ha gitt en kombinasjon av OneLake-sikkerhets- og SQL-tillatelser.
| OneLake-sikkerhetstillatelser | SQL-tillatelser | Effektive tillatelser |
|---|---|---|
| Tillat | Ingen | Tillat |
| Ingen | Tillat | Tillat |
| Tillat | Avslå | Avslå |
| Ingen | Avslå | Avslå |
Kjente problemer og begrensninger
Etter utforming støtter bare tabeller i semantisk modell avledet fra tabeller i en Lakehouse eller Warehouse Direct Lake-modus. Selv om tabeller i modellen kan avledes fra SQL-visninger i Lakehouse eller Warehouse, vil spørringer som bruker disse tabellene, falle tilbake til DirectQuery-modus.
Direct Lake semantiske modelltabeller kan bare avledes fra tabeller og utsikt fra en enkelt Lakehouse eller Warehouse.
Direct Lake-tabeller kan for øyeblikket ikke blandes med andre tabelltyper, for eksempel Import, DirectQuery eller Dual, i samme modell. Sammensatte modeller støttes for øyeblikket ikke.
DateTime-relasjoner støttes ikke i Direct Lake-modeller.
Beregnede kolonner og beregnede tabeller støttes ikke.
Enkelte datatyper støttes kanskje ikke, for eksempel desimaler med høy presisjon og pengetyper.
Direct Lake-tabeller støtter ikke komplekse kolonnetyper for Delta-tabeller. Binære og GUID-semantiske typer støttes også ikke. Du må konvertere disse datatypene til strenger eller andre datatyper som støttes.
Tabellrelasjoner krever at datatypene i nøkkelkolonnene sammenfaller. Primærnøkkelkolonner må inneholde unike verdier. DAX-spørringer mislykkes hvis dupliserte primærnøkkelverdier oppdages.
Lengden på strengkolonneverdier er begrenset til 32 764 Unicode-tegn.
Den flytende punktverdien NaN (Ikke et tall) støttes ikke i Direct Lake-modeller.
Innebygde scenarioer som er avhengige av innebygde enheter, støttes ikke ennå.
Validering er begrenset for Direct Lake-modeller. Brukervalg antas som riktige, og ingen spørringer validerer kardinalitet og kryssfiltreringsvalg for relasjoner, eller for den valgte datokolonnen i en datotabell.
Direct Lake-fanen i oppdateringsloggen viser bare Direkte lake-relaterte oppdateringsfeil. Vellykkede oppdateringer utelates for øyeblikket.
Kom i gang
Den beste måten å komme i gang med en Direct Lake-løsning i organisasjonen på, er å opprette en Lakehouse, opprette et Delta-bord i den og deretter opprette en grunnleggende semantisk modell for lakehouse i Microsoft Fabric-arbeidsområdet. Hvis du vil ha mer informasjon, kan du se Opprette et lakehouse for Direct Lake.
Relatert innhold
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for