Eksportere Dataverse-data i Delta Lake-format
Bruk Azure Synapse Link for Dataverse til å eksportere Microsoft Dataverse-dataene til Azure Synapse Analytics i Delta Lake-format. Deretter utforsker du dataene og akselererer tid til innsikt. Denne artikkelen inneholder følgende informasjon, og viser deg hvordan du utfører følgende oppgaver:
- Forklarer Delta Lake og Parquet, og hvorfor du bør eksportere data i dette formatet.
- Eksporter Dataverse-dataene til Azure Synapse Analytics-arbeidsområdet i Delta Lake-format med Azure Synapse Link.
- Overvåk Azure Synapse Link og datakonverteringen.
- Vis dataene fra Azure Data Lake Storage Gen2.
- Vis dataene fra Synapse Workspace.
Viktig
- Hvis du oppgraderer fra CSV til Delta Lake med eksisterende egendefinerte visninger, anbefaler vi at du oppdaterer skriptet til å erstatte alle partisjonerte tabeller til non_partitioned. Gjør dette ved å søke etter forekomster av
_partitionedog erstatte dem med en tom streng. - For Dataverse-konfigurasjonen, aktiveres bare tilføying som standard for å eksportere CSV-data i
appendonly-modus. Men Delta Lake-tabellen vil ha en oppdateringsstruktur på stedet fordi Delta Lake-konverteringen kommer med en periodisk sammenslåingsprosess. - Det påløper ingen kostnader ved oppretting av Spark-gruppene. Omkostnader påløper bare når en Spark-jobb er utført i mål-Spark-gruppen, og Spark-forekomsten startes ved behov. Disse kostnadene er relatert til bruk av Azure Synapse workspace Spark og faktureres månedlig. Kostnadene for utførelse av Spark-databehandling avhenger hovedsakelig av tidsintervallet for trinnvis oppdatering og datavolumene. Mer informasjon: Azure Synapse Analytics-priser.
- Det er viktig å ta hensyn til disse ekstrakostnadene når du bestemmer deg for å bruke denne funksjonen, da de ikke er valgfrie og må betales for å kunne fortsette å bruke denne funksjonen.
- Kunngjøring av levetidsslutt for Azure Synapse-kjøretid for Apache Spark 3.3 ble kunngjort 12. juli 2024. I henhold til Synapse-kjøretiden for Apache Spark-livssykluspolicy vil Azure Synapse-kjøretid for Apache Spark 3.3 bli avviklet og deaktivert fra og med 31. mars 2025. Etter datoen for levetidsslutt er ikke de avviklede kjøretidene tilgjengelige for nye Spark-grupper, og eksisterende arbeidsflyter kan ikke kjøres. Metadata beholdes midlertidig i Synapse-arbeidsområdet. Mer informasjon: Azure Synapse-kjøretid for Apache Spark 3.3 (EOSA). Hvis du vil oppgradere Synapse Link for Dataverse med eksport til Delta Lake-format til Spark 3.4, foretar du en direkte oppgradering for de eksisterende profilene. Mer informasjon: Direkte oppgradering til Apache Spark 3.4 med Delta Lake 2.4
- Fra og med 25. desember 2024 støttes bare Spark-gruppe versjon 3.4 når koblingen opprettes for første gang.
Obs!
Azure Synapse Link-statusen i Power Apps (make.powerapps.com) gjenspeiler konverteringsstatusen for Delta Lake:
-
Countviser antall oppføringer i Delta Lake-tabellen. -
Last synchronized onDatetime representerer det siste vellykkede konverteringstidsstempelet. -
Sync statusvises som aktiv når datasynkroniseringen og Delta Lake-konverteringen er fullført, som angir at dataene er klare til bruk.
Delta Lake er et prosjekt med åpen kildekode som gjør det mulig å bygge en lakehouse-arkitektur på toppen av datasjøer. Delta Lake leverer ACID-trasaksjoner (atomicity, consistency, isolation, durability) samt skalerbar metadatahåndtering og forener strømme- og batchdatabehandling på toppen av eksisterende datasjøer. Azure Synapse Analytics er kompatibelt med Linux Foundation Delta Lake. Den gjeldende versjonen av Delta Lake inkludert i Azure Synapse har språkstøtte for Scala, PySpark og .NET. Mer informasjon: Hva er Delta Lake?. Du kan også lære mer fra videoen Introduksjon til i Delta-tabeller.
Apache Parquet er basislinjeformatet for Delta Lake, som gir deg mulighet bruke de effektive kompresjons- og kodingsoppsettet som er innebygget i formatet. Parquet-filformatet bruker kolonnevis kompresjon. Det er effektivt og sparer lagringsplass. Spørringer som henter bestemte kolonneverdier, trenger ikke å lese hele raddataene og dermed forbedre ytelsen. Derfor trenger serverløse SQL-utvalg kortere tid og færre lagringsforespørsler for å lese dataene.
- Skalerbarhet: Delta Lake er bygget på toppen av Apache-lisensen med åpen kilde, som er utformet for å tilfredsstille bransjestandarder for håndtering av arbeidsbelastninger i storskaladatabehandling.
- Pålitelighet: Delta Lake tilbyr ACID-transaksjoner, noe som sørger for at datakonsistens og pålitelighet sikres selv når det gjelder feil eller samtidig tilgang.
- Ytelse: Delta Lake leverer kolonnelagringsformatet Parquet, som gir bedre kompresjons- og kodingsteknikker, noe som kan føre til forbedret spørringsytelse sammenlignet med spørrings-CSV-filer.
- Kostnadseffektivt: Filformatet Delta Lake er en svært komprimert datalagringsteknologi som gir betydelige potensielle lagringsbesparelser for virksomheter. Dette formatet er spesielt utformet for å optimalisere databehandlingen og potensielt redusere den totale mengden data behandlet eller kjøretid som kreves for behovsbasert databehandling.
- Etterlevelse av databeskyttelse: Delta Lake med Azure Synapse Link inneholder verktøy og funksjoner, inkludert myk sletting og sletting for å etterleve ulike personvernforskrifter, inkludert EUs personvernforordning (GDPR).
Når du konfigurerer en Azure Synapse Link for Dataverse, kan du aktivere funksjonen eksporter til Delta Lake og koble til et Synapse-arbeidsområde og Spark-gruppe. Azure Synapse Link eksporterer de valgte Dataverse-tabellene i CSV-format ved angitte tidsintervaller, og behandler dem gjennom en Delta Lake-konvertering Spark-jobb. Når konverteringsprosessen er fullført, ryddes det i CSV-data for lagring. I tillegg skal en rekke vedlikeholdsjobber kjøres på daglig basis, der det automatisk utføres komprimerings- og ryddeprosesser for å flette og rydde opp i data filer for å ytterligere optimalisere lagring og forbedre spørringsytelsen.
- Dataverse: Du må ha sikkerhetsrollen som systemadministrator i Dataverse. I tillegg må tabeller du vil eksportere via Azure Synapse Link, ha egenskapen Spor endringer aktivert. Mer informasjon: Avanserte alternativer
- Azure Data Lake Storage Gen2: Du må ha tilgang til en Azure Data Lake Storage Gen2-konto og rolletilgangen Eier og Storage Blob-databidragsyter. Lagringskontoen må aktivere Hierarkisk navneområde og offentlig nettverkstilgang for både første installasjon og deltasynkronisering. Tillat tilgang til lagringskontonøkkel er bare nødvendig for den første installasjonen.
- Synapse-arbeidsområde: Du må ha et synapse-arbeidsområde og Eier-rollen i tilgangskontroll (IAM) og tilgang til rollen Synapse-administrator i Synapse Studio. Synapse-arbeidsområdet må være i samme område som Azure Data Lake Storage Gen2-kontoen. Lagringskontoen må legges til som en koblet tjeneste i Synapse Studio. Hvis du vil opprette et Synapse-arbeidsområde, går du til Opprette et Synapse-arbeidsområde.
- En Apache Spark-gruppe i det tilkoblede Azure Synapse workspace med Apache Spark versjon 3.3 bruker denne anbefalte Spark-gruppekonfigurasjonen. Hvis du vil ha mer informasjon om hvordan du oppretter en Spark-gruppe, kan du gå til Opprett ny Apache Spark-gruppe.
- Minimumskravet til Microsoft Dynamics 365-versjon for å bruke denne funksjonen er 9.2.22082. Mer informasjon: Velge oppdateringer for tidlig tilgang
Denne konfigurasjonen kan betraktes som et bootstrap-trinn for gjennomsnittlige brukssaker.
- Nodestørrelse: liten (4 vCores / 32 GB)
- Autoskalering: Aktivert
- Antall noder: 5 til 10
- Automatisk pause: Aktivert
- Antall ledige minutter: 5
- Apache Spark: 3.4
- Tildel kjørere dynamisk: aktivert
- Standard antall kjørere: 1 til 9
Viktig
Bruk Spark-gruppen eksklusivt for Delta Lake-konverteringsoperasjonen med Synapse Link for Dataverse. For å få best mulig pålitelighet og ytelse bør du unngå å kjøre andre Spark-jobber som bruker den samme Spark-gruppen.
Logg på Power Apps og velg miljøet du vil ha.
Velg Azure Synapse-kobling i den venstre navigasjonsruten. Hvis elementet ikke finnes i sideruten, velger du ...Mer og deretter elementet du vil ha.
Velg + Ny kobling på kommandolinjen
Velg Koble til Azure Synapse Analytics workspace, og velg deretter Abonnement, Ressursgruppe og Navn på arbeidsområde.
Velg Bruk Spark-gruppe til behandling, og velg deretter det forhåndsopprettede Spark-utvalget og Lagringskonto.
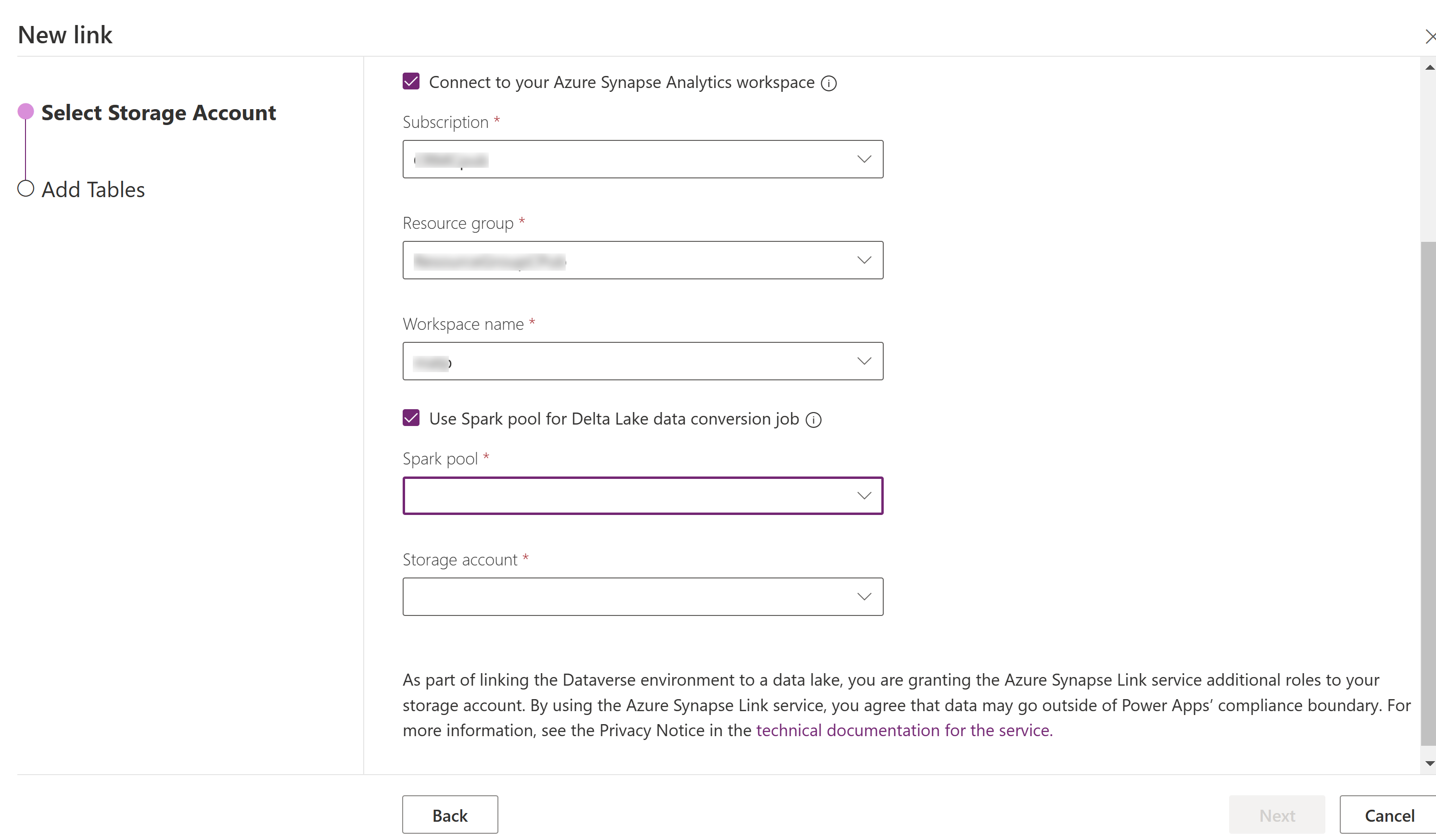
Velg Neste.
Legg til tabellene du vil eksportere, og velg deretter Avansert.
Velg eventuelt Vis avanserte konfigurasjonsinnstillinger og angi tidsintervallet, i minutter, for hvor ofte de trinnvise oppdateringene skal registreres.
Velg Lagre.
- Velg Azure Synapse Link du vil ha, og velg deretter Gå til Azure Synapse Analytics workspace på kommandolinjen.
- Velg Overvåking>Apache Spark-apper. Mer informasjon: Bruk Synapse Studio til å overvåke Apache Spark-apper
- Velg Azure Synapse Link du vil ha, og velg deretter Gå til Azure Synapse Analytics workspace på kommandolinjen.
- Utvid Sjødatabaser i venstre rute, velg dataverse-environmentNameorganizationUniqueName, og utvid deretter Tabeller. Alle Parquet-tabeller er oppført og tilgjengelige for analyse med navnekonvensjonen DataverseTableName.(Non_partitioned-tabell).
Obs!
Ikke bruk tabeller med navnekonvensjonen _partitioned. Når du velger Delta parquet som format, brukes tabeller med navnekonvensjonen _partition som oppsamlingstabeller og fjernes etter at de er brukt av systemet.
- Velg Azure Synapse Link du vil ha, og velg deretter Gå til Azure Data Lake på kommandolinjen.
- Velg beholderne under Datalagring.
- Velg *dataverse- *environmentName-organizationUniqueName. Alle parquet-filer lagres i deltalake-mappen.
- Du må ha en eksisterende Azure Synapse Link for Dataverse Delta Lake-profil som kjører med en Synapse Spark versjon 3.3.
- Du må opprette en ny Synapse Spark-gruppe med Spark versjon 3.4 ved å bruke maskinkonfigurasjon med de samme eller høyere nodene i samme Synapse-arbeidsområde. Hvis du vil ha mer informasjon om hvordan du oppretter en Spark-gruppe, kan du gå til Opprett ny Apache Spark-gruppe. Denne Spark-gruppen må opprettes uavhengig av gjeldende 3.3-gruppe.
- Logg deg på Power Apps, og velg det foretrukne miljøet.
- Velg Azure Synapse-kobling i den venstre navigasjonsruten. Hvis elementet ikke finnes i venstre navigasjonsrute, velger du ...Mer og deretter elementet du vil ha.
- Åpne Azure Synapse Link-profilen, og velg deretter Oppgrader til Apache Spark 3.4 med Delta Lake 2.4.
- Velg den tilgjengelige Spark-gruppen fra listen, og velg deretter Oppdater.
Obs!
Spark-gruppeoppgraderingen forekommer bare når en ny Spark-jobb for Delta Lake-konvertering utløses. Pass på at du har minst én dataendring etter at du har valgt Oppdater.