Tips voor betere prestaties voor Azure Cosmos DB Async Java SDK v2
VAN TOEPASSING OP: ![]() NoSQL
NoSQL
Belangrijk
Dit is niet de nieuwste Java SDK voor Azure Cosmos DB. U moet uw project upgraden naar Azure Cosmos DB Java SDK v4 en vervolgens de handleiding met tips voor prestaties van Azure Cosmos DB Java SDK v4 lezen. Volg de instructies in de handleiding Migreren naar Azure Cosmos DB Java SDK v4 en Reactor vs RxJava-handleiding om een upgrade uit te voeren.
De prestatietips in dit artikel zijn alleen bedoeld voor Azure Cosmos DB Async Java SDK v2. Zie de releaseopmerkingen voor Azure Cosmos DB Async Java SDK v2, Maven-opslagplaats en Azure Cosmos DB Async Java SDK v2 voor meer informatie.
Belangrijk
Op 31 augustus 2024 wordt de Azure Cosmos DB Async Java SDK v2.x buiten gebruik gesteld; de SDK en alle toepassingen die gebruikmaken van de SDK blijven functioneren; Azure Cosmos DB biedt eenvoudigweg geen onderhoud meer en ondersteuning voor deze SDK. U wordt aangeraden de bovenstaande instructies te volgen om te migreren naar Azure Cosmos DB Java SDK v4.
Azure Cosmos DB is een snelle en flexibele gedistribueerde database die naadloos wordt geschaald met gegarandeerde latentie en doorvoer. U hoeft geen belangrijke architectuurwijzigingen aan te brengen of complexe code te schrijven om uw database te schalen met Azure Cosmos DB. Omhoog en omlaag schalen is net zo eenvoudig als het maken van één API-aanroep of SDK-methode-aanroep. Omdat Azure Cosmos DB echter toegankelijk is via netwerkaanroepen, zijn er optimalisaties aan de clientzijde die u kunt uitvoeren om piekprestaties te bereiken wanneer u de Azure Cosmos DB Async Java SDK v2 gebruikt.
Dus als u 'Hoe kan ik de prestaties van mijn database verbeteren?' vraagt, moet u rekening houden met de volgende opties:
Netwerken
Verbindingsmodus: Directe modus gebruiken
Hoe een client verbinding maakt met Azure Cosmos DB heeft belangrijke gevolgen voor de prestaties, met name wat betreft latentie aan de clientzijde. ConnectionMode is een sleutelconfiguratie-instelling die beschikbaar is voor het configureren van de client ConnectionPolicy. Voor Azure Cosmos DB Async Java SDK v2 zijn de twee beschikbare ConnectionModes:
De gatewaymodus wordt ondersteund op alle SDK-platforms en is standaard de geconfigureerde optie. Als uw toepassingen worden uitgevoerd in een bedrijfsnetwerk met strikte firewallbeperkingen, is de gatewaymodus de beste keuze omdat deze gebruikmaakt van de standaard HTTPS-poort en één eindpunt. Het nadeel van de prestaties is echter dat de gatewaymodus een extra netwerkhop omvat telkens wanneer gegevens worden gelezen of naar Azure Cosmos DB worden geschreven. Hierdoor biedt de direct-modus betere prestaties vanwege minder netwerkhops.
De ConnectionMode is geconfigureerd tijdens de bouw van het DocumentClient-exemplaar met de parameter ConnectionPolicy .
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
public ConnectionPolicy getConnectionPolicy() {
ConnectionPolicy policy = new ConnectionPolicy();
policy.setConnectionMode(ConnectionMode.Direct);
policy.setMaxPoolSize(1000);
return policy;
}
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);
Clients in dezelfde Azure-regio plaatsen voor prestaties
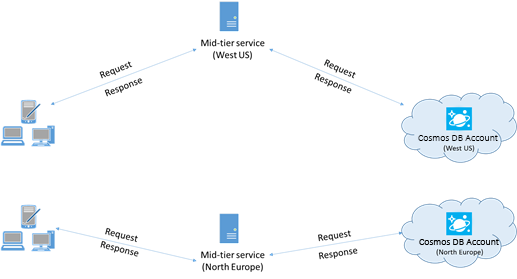
Plaats indien mogelijk toepassingen die Azure Cosmos DB aanroepen in dezelfde regio als de Azure Cosmos DB-database. Voor een geschatte vergelijking zijn aanroepen naar Azure Cosmos DB binnen dezelfde regio voltooid binnen 1-2 ms, maar de latentie tussen de west- en oostkust van de VS is >50 ms. Deze latentie kan waarschijnlijk variëren van aanvraag tot aanvraag, afhankelijk van de route die door de aanvraag wordt genomen, omdat deze wordt doorgegeven van de client naar de grens van het Azure-datacenter. De laagst mogelijke latentie wordt bereikt door ervoor te zorgen dat de aanroepende toepassing zich in dezelfde Azure-regio bevindt als het ingerichte Azure Cosmos DB-eindpunt. Zie Azure-regio's voor een lijst met beschikbare regio's.
SDK-gebruik
De meest recente SDK installeren
De Azure Cosmos DB SDK's worden voortdurend verbeterd om de beste prestaties te bieden. Zie de pagina's met releaseopmerkingen voor Azure Cosmos DB Async Java SDK v2 om de meest recente SDK te bepalen en verbeteringen te bekijken.
Een Singleton Azure Cosmos DB-client gebruiken voor de levensduur van uw toepassing
Elk AsyncDocumentClient-exemplaar is thread-safe en voert efficiënt verbindingsbeheer en adrescaching uit. Om efficiënt verbindingsbeheer en betere prestaties van AsyncDocumentClient mogelijk te maken, is het raadzaam om één exemplaar van AsyncDocumentClient per AppDomain te gebruiken voor de levensduur van de toepassing.
ConnectionPolicy afstemmen
Standaard worden Azure Cosmos DB-aanvragen in de directe modus via TCP uitgevoerd wanneer u de Azure Cosmos DB Async Java SDK v2 gebruikt. Intern maakt de SDK gebruik van een speciale architectuur voor de directe modus om netwerkbronnen dynamisch te beheren en de beste prestaties te krijgen.
In de Azure Cosmos DB Async Java SDK v2 is de directe modus de beste keuze om de databaseprestaties met de meeste workloads te verbeteren.
- Overzicht van de directe modus

De architectuur aan de clientzijde die in de directe modus wordt gebruikt, maakt voorspelbaar netwerkgebruik en multiplexed toegang tot Azure Cosmos DB-replica's mogelijk. In het bovenstaande diagram ziet u hoe clientaanvragen in de directe modus worden gerouteerd naar replica's in de Azure Cosmos DB-back-end. De architectuur voor de directe modus wijst maximaal 10 kanalen toe aan de clientzijde per DB-replica. Een kanaal is een TCP-verbinding die voorafgaat door een aanvraagbuffer, wat 30 aanvragen diep is. De kanalen die deel uitmaken van een replica, worden dynamisch toegewezen aan het service-eindpunt van de replica. Wanneer de gebruiker een aanvraag in de directe modus uitgeeft, stuurt TransportClient de aanvraag naar het juiste service-eindpunt op basis van de partitiesleutel. De aanvraagwachtrij buffert aanvragen vóór het service-eindpunt.
Verbindingspolicy-configuratieopties voor de directe modus
Als eerste stap gebruikt u de volgende aanbevolen configuratie-instellingen hieronder. Neem contact op met het Azure Cosmos DB-team als u problemen ondervindt met dit specifieke onderwerp.
Als u Azure Cosmos DB gebruikt als referentiedatabase (dat wil gezegd, wordt de database gebruikt voor veel puntleesbewerkingen en weinig schrijfbewerkingen), is het mogelijk acceptabel om inactiviteitEndpointTimeout in te stellen op 0 (dat wil gezegd, geen time-out).
Configuratieoptie Standaardinstelling bufferPageSize 8192 connectionTimeout "PT1M" idleChannelTimeout "PT0S" idleEndpointTimeout "PT1M10S" maxBufferCapacity 8388608 maxChannelsPerEndpoint 10 maxRequestsPerChannel 30 receiveHangDetectionTime "PT1M5S" requestExpiryInterval "PT5S" requestTimeout "PT1M" requestTimerResolution "PT0.5S" sendHangDetectionTime "PT10S" shutdownTimeout "PT15S"
Programmeertips voor de directe modus
Raadpleeg het artikel over probleemoplossing voor Azure Cosmos DB Async Java SDK v2 als basislijn voor het oplossen van SDK-problemen.
Enkele belangrijke programmeertips bij het gebruik van de directe modus:
Gebruik multithreading in uw toepassing voor efficiënte TCP-gegevensoverdracht . Nadat u een aanvraag hebt ingediend, moet uw toepassing zich abonneren op het ontvangen van gegevens op een andere thread. Als u dit niet doet, worden onbedoelde 'half-duplex'-bewerkingen geblokkeerd en worden de volgende aanvragen geblokkeerd op het antwoord van de vorige aanvraag.
Rekenintensieve workloads uitvoeren op een toegewezen thread : om vergelijkbare redenen als de vorige tip, kunnen bewerkingen zoals complexe gegevensverwerking het beste in een afzonderlijke thread worden geplaatst. Een aanvraag die gegevens ophaalt uit een ander gegevensarchief (bijvoorbeeld als de thread tegelijkertijd gebruikmaakt van Azure Cosmos DB- en Spark-gegevensarchieven), kan een verhoogde latentie ervaren en het wordt aanbevolen om een extra thread uit te voeren die wacht op een reactie van het andere gegevensarchief.
- De onderliggende netwerk-IO in de Azure Cosmos DB Async Java SDK v2 wordt beheerd door Netty. Zie deze tips voor het voorkomen van coderingspatronen die Netty IO-threads blokkeren.
Gegevensmodellering : in de SLA van Azure Cosmos DB wordt ervan uitgegaan dat de documentgrootte kleiner is dan 1 kB. Het optimaliseren van uw gegevensmodel en programmeren om kleinere documentgrootten te bevorderen, leidt doorgaans tot een verminderde latentie. Als u opslag en het ophalen van documenten nodig hebt die groter zijn dan 1 kB, is de aanbevolen methode om documenten te koppelen aan gegevens in Azure Blob Storage.
Parallelle query's afstemmen voor gepartitioneerde verzamelingen
Azure Cosmos DB Async Java SDK v2 ondersteunt parallelle query's, waarmee u parallel een query kunt uitvoeren op een gepartitioneerde verzameling. Zie codevoorbeelden met betrekking tot het werken met de SDK's voor meer informatie. Parallelle query's zijn ontworpen om de querylatentie en doorvoer te verbeteren ten opzichte van hun seriële tegenhanger.
SetMaxDegreeOfParallelism afstemmen:
Parallelle query's werken door gelijktijdig query's uit te voeren op meerdere partities. Gegevens uit een afzonderlijke gepartitioneerde verzameling worden echter serieel opgehaald met betrekking tot de query. Gebruik dus setMaxDegreeOfParallelism om het aantal partities in te stellen dat de maximale kans heeft om de meest presterende query te bereiken, mits alle andere systeemvoorwaarden hetzelfde blijven. Als u het aantal partities niet weet, kunt u setMaxDegreeOfParallelism gebruiken om een hoog getal in te stellen en kiest het systeem het minimum (aantal partities, door de gebruiker verstrekte invoer) als de maximale mate van parallelle uitvoering.
Het is belangrijk om te weten dat parallelle query's de beste voordelen opleveren als de gegevens gelijkmatig worden verdeeld over alle partities met betrekking tot de query. Als de gepartitioneerde verzameling zodanig is gepartitioneerd dat alle of de meeste gegevens die door een query worden geretourneerd, in een paar partities zijn geconcentreerd (één partitie in het slechtste geval), worden de prestaties van de query knelpunten veroorzaakt door deze partities.
SetMaxBufferedItemCount afstemmen:
Parallelle query is ontworpen om resultaten vooraf te maken terwijl de huidige batch met resultaten door de client wordt verwerkt. De prefetching helpt bij het verbeteren van de algehele latentie van een query. setMaxBufferedItemCount beperkt het aantal vooraf gemaakte resultaten. Als u setMaxBufferedItemCount instelt op het verwachte aantal geretourneerde resultaten (of een hoger getal), kan de query maximaal voordeel krijgen van het vooraf instellen.
Prefetching werkt op dezelfde manier, ongeacht het MaxDegreeOfParallelisme, en er is één buffer voor de gegevens van alle partities.
Uitstel implementeren bij intervallen van getRetryAfterInMilliseconds
Tijdens het testen van de prestaties moet u de belasting verhogen totdat een klein aantal aanvragen wordt beperkt. Als de beperking is beperkt, moet de clienttoepassing uitstel opgeven voor het door de server opgegeven interval voor opnieuw proberen. Het respecteren van de uitstel zorgt ervoor dat u minimale tijd besteedt aan het wachten tussen nieuwe pogingen.
Uw clientworkload uitschalen
Als u test op hoge doorvoerniveaus (>50.000 RU/s), kan de clienttoepassing het knelpunt worden omdat de computer het CPU- of netwerkgebruik beperkt. Als u dit punt bereikt, kunt u het Azure Cosmos DB-account verder pushen door uw clienttoepassingen uit te schalen op meerdere servers.
Adressering op basis van naam gebruiken
Gebruik adressering op basis van namen, waarbij koppelingen de indeling
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentIdhebben, in plaats van SelfLinks (_self), die de indelingdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>hebben om te voorkomen dat resource-id's worden opgehaald van alle resources die worden gebruikt om de koppeling te maken. Omdat deze resources opnieuw worden gemaakt (mogelijk met dezelfde naam), kan het opslaan van resources niet helpen.Het paginaformaat voor query's/leesfeeds afstemmen voor betere prestaties
Wanneer u een bulksgewijs lezen van documenten uitvoert met behulp van de leesfeedfunctionaliteit (bijvoorbeeld readDocuments) of bij het uitgeven van een SQL-query, worden de resultaten op een gesegmenteerde manier geretourneerd als de resultatenset te groot is. Standaard worden resultaten geretourneerd in segmenten van 100 items of 1 MB, afhankelijk van welke limiet het eerst wordt bereikt.
Als u het aantal netwerkrondes wilt verminderen dat nodig is om alle toepasselijke resultaten op te halen, kunt u de paginagrootte verhogen met behulp van de aanvraagheader x-ms-max-item-count tot maximaal 1000. In gevallen waarin u slechts enkele resultaten moet weergeven, bijvoorbeeld als uw gebruikersinterface of toepassings-API slechts 10 resultaten per keer retourneert, kunt u ook het paginaformaat verkleinen tot 10 om de verbruikte doorvoer voor lees- en query's te verminderen.
U kunt ook het paginaformaat instellen met de methode setMaxItemCount.
Geschikte Scheduler gebruiken (vermijd het stelen van Io Netty-threads voor gebeurtenislus)
De Azure Cosmos DB Async Java SDK v2 maakt gebruik van netty voor niet-blokkerende IO. De SDK gebruikt een vast aantal IO Netty EventLoop-threads (zoveel CPU-kernen waarover de computer beschikt) voor het uitvoeren van IO-bewerkingen. Het waarneembare resultaat dat door de API wordt geretourneerd, verzendt het resultaat op een van de gedeelde IO-gebeurtenislus-threads. Het is dus belangrijk om de gedeelde IO Netty EventLoop-threads niet te blokkeren. Het uitvoeren van CPU-intensief werk of het blokkeren van bewerkingen op de IO-gebeurtenislus netty-thread kan een impasse veroorzaken of de SDK-doorvoer aanzienlijk verminderen.
Met de volgende code wordt bijvoorbeeld een cpu-intensief werk uitgevoerd voor de IO netty-thread van de gebeurtenislus:
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribe( resourceResponse -> { //this is executed on eventloop IO netty thread. //the eventloop thread is shared and is meant to return back quickly. // // DON'T do this on eventloop IO netty thread. veryCpuIntensiveWork(); });Nadat het resultaat is ontvangen als u CPU-intensief werk wilt doen aan het resultaat, moet u dit vermijden op io netty-thread voor de gebeurtenislus. U kunt in plaats daarvan uw eigen Scheduler opgeven om uw eigen thread te bieden voor het uitvoeren van uw werk.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
import rx.schedulers; Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribeOn(Schedulers.computation()) subscribe( resourceResponse -> { // this is executed on threads provided by Scheduler.computation() // Schedulers.computation() should be used only when: // 1. The work is cpu intensive // 2. You are not doing blocking IO, thread sleep, etc. in this thread against other resources. veryCpuIntensiveWork(); });Op basis van het type werk moet u de juiste bestaande RxJava Scheduler voor uw werk gebruiken. Lees hier
Schedulers.Zie de GitHub-pagina voor Azure Cosmos DB Async Java SDK v2 voor meer informatie.
Logboekregistratie van Netty uitschakelen
Logboekregistratie van Netty-bibliotheken is chatty en moet worden uitgeschakeld (het onderdrukken van de aanmeldingsconfiguratie is mogelijk niet voldoende) om extra CPU-kosten te voorkomen. Als u zich niet in de foutopsporingsmodus bevindt, schakelt u de logboekregistratie van Netty helemaal uit. Dus als u log4j gebruikt om de extra CPU-kosten te verwijderen die door
org.apache.log4j.Category.callAppenders()Netty worden gemaakt, voegt u de volgende regel toe aan uw codebasis:org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);Resourcelimiet voor openen van besturingssysteembestanden
Sommige Linux-systemen (zoals Red Hat) hebben een bovengrens voor het aantal geopende bestanden en dus het totale aantal verbindingen. Voer het volgende uit om de huidige limieten weer te geven:
ulimit -aHet aantal geopende bestanden (nofile) moet groot genoeg zijn om voldoende ruimte te hebben voor de geconfigureerde verbindingsgroepgrootte en andere geopende bestanden door het besturingssysteem. Het kan worden gewijzigd om een grotere verbindingsgroepgrootte toe te staan.
Open het bestand limits.conf:
vim /etc/security/limits.confVoeg de volgende regels toe/wijzigt:
* - nofile 100000
Indexeringsbeleid
Niet-gebruikte paden uitsluiten van indexering voor snellere schrijfbewerkingen
Met het indexeringsbeleid van Azure Cosmos DB kunt u opgeven welke documentpaden moeten worden opgenomen of uitgesloten van indexering met behulp van indexeringspaden (setIncludedPaths en setExcludedPaths). Het gebruik van indexeringspaden kan betere schrijfprestaties en lagere indexopslag bieden voor scenario's waarin de querypatronen vooraf bekend zijn, omdat indexeringskosten rechtstreeks worden gecorreleerd aan het aantal unieke paden dat is geïndexeerd. De volgende code laat bijvoorbeeld zien hoe u een hele sectie van de documenten (ook wel substructuur genoemd) kunt uitsluiten van indexering met behulp van het jokerteken *.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Zie Het indexeringsbeleid van Azure Cosmos DB voor meer informatie.
Doorvoer
Meten en afstemmen op lagere aanvraageenheden/tweede gebruik
Azure Cosmos DB biedt een uitgebreide set databasebewerkingen, waaronder relationele en hiërarchische query's met UDF's, opgeslagen procedures en triggers, die allemaal werken op de documenten in een databaseverzameling. De kosten die gepaard gaan met elke bewerking hangen af van de CPU, de IO en het geheugen, vereist om de bewerking uit te voeren. In plaats van aan hardwareresources te denken en te beheren, kunt u een aanvraageenheid (RU) beschouwen als één meting voor de resources die nodig zijn voor het uitvoeren van verschillende databasebewerkingen en het uitvoeren van een toepassingsaanvraag.
Doorvoer wordt ingericht op basis van het aantal aanvraageenheden dat is ingesteld voor elke container. Verbruik van aanvraageenheden wordt geëvalueerd als een tarief per seconde. Toepassingen die de ingerichte aanvraageenheidsnelheid voor hun container overschrijden, zijn beperkt totdat de snelheid lager is dan het ingerichte niveau voor de container. Als uw toepassing een hoger doorvoerniveau vereist, kunt u de doorvoer verhogen door extra aanvraageenheden in te richten.
De complexiteit van een query heeft invloed op het aantal aanvraageenheden dat wordt verbruikt voor een bewerking. Het aantal predicaten, de aard van de predicaten, het aantal UDF's en de grootte van de brongegevensset zijn allemaal van invloed op de kosten van querybewerkingen.
Als u de overhead van een bewerking wilt meten (maken, bijwerken of verwijderen), inspecteert u de header x-ms-request-charge om het aantal aanvraageenheden te meten dat door deze bewerkingen wordt verbruikt. U kunt ook de equivalente eigenschap RequestCharge bekijken in ResourceResponse<T> of FeedResponse<T>.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
ResourceResponse<Document> response = asyncClient.createDocument(collectionLink, documentDefinition, null, false).toBlocking.single(); response.getRequestCharge();De aanvraagkosten die in deze header worden geretourneerd, zijn een fractie van uw ingerichte doorvoer. Als u bijvoorbeeld 2000 RU/s hebt ingericht en als de voorgaande query 1000 1 KB-documenten retourneert, zijn de kosten van de bewerking 1000. Daarom eert de server binnen één seconde slechts twee dergelijke aanvragen voordat de frequentie van volgende aanvragen wordt beperkt. Zie Aanvraageenheden en de rekenmachine voor aanvraageenheden voor meer informatie.
Snelheidsbeperking/aanvraagsnelheid te groot verwerken
Wanneer een client de gereserveerde doorvoer voor een account probeert te overschrijden, is er geen prestatievermindering op de server en is er geen gebruik van doorvoercapaciteit buiten het gereserveerde niveau. De server beëindigt de aanvraag met RequestRateTooLarge (HTTP-statuscode 429) en retourneert de header x-ms-retry-after-ms die de hoeveelheid tijd aangeeft, in milliseconden, dat de gebruiker moet wachten voordat de aanvraag opnieuw wordt geïmplementeerd.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100De SDK's vangen dit antwoord impliciet op, respecteren de server opgegeven nieuwe poging na header en probeer de aanvraag opnieuw. Tenzij uw account gelijktijdig wordt geopend door meerdere clients, slaagt de volgende nieuwe poging.
Als u meerdere clients cumulatief boven de aanvraagsnelheid gebruikt, is het standaardaantal nieuwe pogingen dat momenteel is ingesteld op 9 intern door de client mogelijk niet voldoende; In dit geval genereert de client een DocumentClientException met statuscode 429 aan de toepassing. Het standaardaantal nieuwe pogingen kan worden gewijzigd met behulp van setRetryOptions op het ConnectionPolicy-exemplaar. De DocumentClientException met statuscode 429 wordt standaard geretourneerd na een cumulatieve wachttijd van 30 seconden als de aanvraag blijft werken boven de aanvraagsnelheid. Dit gebeurt zelfs wanneer het huidige aantal nieuwe pogingen kleiner is dan het maximumaantal nieuwe pogingen, of het nu de standaardwaarde is van 9 of een door de gebruiker gedefinieerde waarde.
Hoewel het geautomatiseerde gedrag voor opnieuw proberen helpt om de tolerantie en bruikbaarheid voor de meeste toepassingen te verbeteren, kan het even vreemd komen bij het uitvoeren van prestatiebenchmarks, met name bij het meten van latentie. De door de client waargenomen latentie zal pieken als het experiment de server beperkt en ervoor zorgt dat de client-SDK op de achtergrond opnieuw probeert. Als u latentiepieken tijdens prestatieexperimenten wilt voorkomen, meet u de kosten die door elke bewerking worden geretourneerd en zorgt u ervoor dat aanvragen onder de gereserveerde aanvraagsnelheid worden uitgevoerd. Zie Aanvraageenheden voor meer informatie.
Ontwerpen voor kleinere documenten voor hogere doorvoer
De aanvraagkosten (de aanvraagverwerkingskosten) van een bepaalde bewerking worden rechtstreeks gecorreleerd aan de grootte van het document. Bewerkingen op grote documenten kosten meer dan bewerkingen voor kleine documenten.
Volgende stappen
Zie Partitioneren en schalen in Azure Cosmos DB voor meer informatie over het ontwerpen van uw toepassing voor schaalaanpassing en hoge prestaties.