Azure Data Factory gebruiken om gegevens te migreren van uw data lake of datawarehouse naar Azure
VAN TOEPASSING OP: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Als u uw Data Lake of Enterprise Data Warehouse (EDW) wilt migreren naar Microsoft Azure, kunt u overwegen Om Azure Data Factory te gebruiken. Azure Data Factory is geschikt voor de volgende scenario's:
- Migratie van big data-workloads van Amazon Simple Storage Service (Amazon S3) of een on-premises Hadoop Distributed File System (HDFS) naar Azure
- EDW-migratie van Oracle Exadata, Netezza, Teradata of Amazon Redshift naar Azure
Azure Data Factory kan petabytes (PB) aan gegevens verplaatsen voor data lake-migratie en tientallen terabytes (TB) aan gegevens voor datawarehouse-migratie.
Waarom Azure Data Factory kan worden gebruikt voor gegevensmigratie
- Azure Data Factory kan eenvoudig de hoeveelheid verwerkingskracht omhoog schalen om gegevens op een serverloze manier te verplaatsen met hoge prestaties, tolerantie en schaalbaarheid. En je betaalt alleen voor wat je gebruikt. Let ook op het volgende:
- Azure Data Factory heeft geen beperkingen voor het gegevensvolume of het aantal bestanden.
- Azure Data Factory kan uw netwerk- en opslagbandbreedte volledig gebruiken om de hoogste doorvoer van gegevensverplaatsing in uw omgeving te bereiken.
- Azure Data Factory maakt gebruik van een methode voor betalen per gebruik, zodat u alleen betaalt voor de tijd die u daadwerkelijk gebruikt om de gegevensmigratie naar Azure uit te voeren.
- Azure Data Factory kan zowel een eenmalige historische belasting als geplande incrementele belastingen uitvoeren.
- Azure Data Factory maakt gebruik van Azure Integration Runtime (IR) om gegevens te verplaatsen tussen openbaar toegankelijke data lake- en warehouse-eindpunten. Het kan ook zelf-hostende IR gebruiken voor het verplaatsen van gegevens voor data lake- en warehouse-eindpunten in Azure Virtual Network (VNet) of achter een firewall.
- Azure Data Factory heeft beveiliging op bedrijfsniveau: u kunt Windows Installer (MSI) of Service Identity gebruiken voor beveiligde service-naar-service-integratie of Azure Key Vault gebruiken voor referentiebeheer.
- Azure Data Factory biedt een ontwerpervaring zonder code en een uitgebreid, ingebouwd bewakingsdashboard.
Online versus offline gegevensmigratie
Azure Data Factory is een standaardhulpprogramma voor onlinegegevensmigratie om gegevens over te dragen via een netwerk (internet, ER of VPN). Bij offlinegegevensmigratie verzenden gebruikers fysiek gegevensoverdrachtapparaten van hun organisatie naar een Azure-datacentrum.
Er zijn drie belangrijke overwegingen wanneer u kiest tussen een online- en offlinemigratiebenadering:
- Grootte van gegevens die moeten worden gemigreerd
- Netwerkbandbreedte
- Migratievenster
Stel dat u van plan bent om Azure Data Factory te gebruiken om uw gegevensmigratie binnen twee weken te voltooien (uw migratievenster). Let op de roze/blauwe snijlijn in de volgende tabel. In de laagste roze cel voor een bepaalde kolom wordt de gegevensgrootte/netwerkbandbreedte gekoppeld waarvan het migratievenster zich het dichtst bij maar minder dan twee weken bevindt. (Elke grootte/bandbreedtekoppeling in een blauwe cel heeft een onlinemigratievenster van meer dan twee weken.)
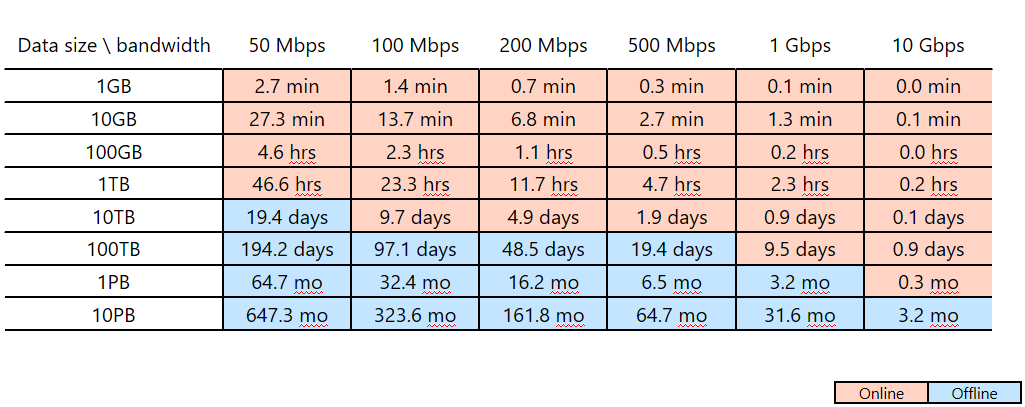 In deze tabel kunt u bepalen of u aan het beoogde migratievenster kunt voldoen via onlinemigratie (Azure Data Factory) op basis van de grootte van uw gegevens en de beschikbare netwerkbandbreedte. Als het venster voor onlinemigratie meer dan twee weken is, wilt u offlinemigratie gebruiken.
In deze tabel kunt u bepalen of u aan het beoogde migratievenster kunt voldoen via onlinemigratie (Azure Data Factory) op basis van de grootte van uw gegevens en de beschikbare netwerkbandbreedte. Als het venster voor onlinemigratie meer dan twee weken is, wilt u offlinemigratie gebruiken.
Notitie
Met behulp van onlinemigratie kunt u zowel historische gegevens laden als incrementele feeds end-to-end bereiken via één hulpprogramma. Via deze methode kunnen uw gegevens tijdens het gehele migratievenster gesynchroniseerd worden gehouden tussen de bestaande opslag en de nieuwe opslag. Dit betekent dat u uw ETL-logica opnieuw kunt bouwen in het nieuwe archief met vernieuwde gegevens.