Stroomlogboeken voor netwerkbeveiligingsgroepen beheren en analyseren met Network Watcher en Grafana
Let op
In dit artikel wordt verwezen naar CentOS, een Linux-distributie die de status End Of Life (EOL) nadert. Overweeg uw gebruik en planning dienovereenkomstig. Zie de Richtlijnen voor het einde van de levensduur van CentOS voor meer informatie.
Stroomlogboeken voor netwerkbeveiligingsgroepen (NSG) bieden informatie die kan worden gebruikt om inzicht te hebben in inkomend en uitgaand IP-verkeer op netwerkinterfaces. Deze stroomlogboeken tonen uitgaande en binnenkomende stromen per NSG-regel, de NIC waarop de stroom van toepassing is, informatie over de stroom met vijf tuples over de stroom (bron/doel-IP, bron-/doelpoort, protocol) en of het verkeer is toegestaan of geweigerd.
U kunt veel NSG's in uw netwerk hebben waarvoor stroomlogboekregistratie is ingeschakeld. Deze hoeveelheid logboekgegevens maakt het lastig om uw logboeken te parseren en inzichten te verkrijgen. Dit artikel biedt een oplossing voor het centraal beheren van deze NSG-stroomlogboeken met Behulp van Grafana, een opensource-hulpprogramma voor grafieken, ElasticSearch, een gedistribueerde zoek- en analyse-engine en Logstash, een open source pijplijn voor gegevensverwerking aan de serverzijde.
Scenario
NSG-stroomlogboeken worden ingeschakeld met Behulp van Network Watcher en worden opgeslagen in Azure Blob Storage. Een Logstash-invoegtoepassing wordt gebruikt om logboeken van blobopslag te verbinden en te verwerken en naar ElasticSearch te verzenden. Zodra de stroomlogboeken zijn opgeslagen in ElasticSearch, kunnen ze worden geanalyseerd en gevisualiseerd in aangepaste dashboards in Grafana.
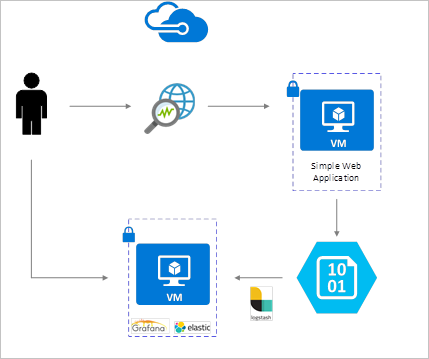
Installatiestappen
Stroomlogboekregistratie van netwerkbeveiligingsgroepen inschakelen
Voor dit scenario moet logboekregistratie van netwerkbeveiligingsgroepen zijn ingeschakeld voor ten minste één netwerkbeveiligingsgroep in uw account. Raadpleeg het volgende artikel Inleiding tot stroomlogboeken voor netwerkbeveiligingsgroepen voor instructies voor het inschakelen van netwerkbeveiligingsstroomlogboeken.
Overwegingen bij het instellen
In dit voorbeeld worden Grafana, ElasticSearch en Logstash geconfigureerd op een Ubuntu LTS-server die is geïmplementeerd in Azure. Deze minimale installatie wordt gebruikt voor het uitvoeren van alle drie de onderdelen. Ze worden allemaal uitgevoerd op dezelfde VIRTUELE machine. Deze installatie mag alleen worden gebruikt voor het testen en niet-kritieke werkbelastingen. Logstash, Elasticsearch en Grafana kunnen allemaal onafhankelijk van elkaar worden geschaald voor veel exemplaren. Zie de documentatie voor elk van deze onderdelen voor meer informatie.
Logstash installeren
U gebruikt Logstash om de met JSON opgemaakte stroomlogboeken plat te maken op een tuple-niveau van een stroom.
De volgende instructies worden gebruikt voor het installeren van Logstash in Ubuntu. Raadpleeg het artikel Installeren vanuit pakketopslagplaatsen - yum voor instructies over het installeren van dit pakket in RHEL/CentOS.
Voer de volgende opdrachten uit om Logstash te installeren:
curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-5.2.0.deb sudo dpkg -i logstash-5.2.0.debConfigureer Logstash om de stroomlogboeken te parseren en naar ElasticSearch te verzenden. Maak een Logstash.conf-bestand met behulp van:
sudo touch /etc/logstash/conf.d/logstash.confVoeg de volgende inhoud toe aan het bestand. Wijzig de naam en toegangssleutel van het opslagaccount zodat deze overeenkomen met de gegevens van uw opslagaccount:
input { azureblob { storage_account_name => "mystorageaccount" storage_access_key => "VGhpcyBpcyBhIGZha2Uga2V5Lg==" container => "insights-logs-networksecuritygroupflowevent" codec => "json" # Refer https://learn.microsoft.com/azure/network-watcher/network-watcher-read-nsg-flow-logs # Typical numbers could be 21/9 or 12/2 depends on the nsg log file types file_head_bytes => 12 file_tail_bytes => 2 # Enable / tweak these settings when event is too big for codec to handle. # break_json_down_policy => "with_head_tail" # break_json_batch_count => 2 } } filter { split { field => "[records]" } split { field => "[records][properties][flows]"} split { field => "[records][properties][flows][flows]"} split { field => "[records][properties][flows][flows][flowTuples]"} mutate { split => { "[records][resourceId]" => "/"} add_field => { "Subscription" => "%{[records][resourceId][2]}" "ResourceGroup" => "%{[records][resourceId][4]}" "NetworkSecurityGroup" => "%{[records][resourceId][8]}" } convert => {"Subscription" => "string"} convert => {"ResourceGroup" => "string"} convert => {"NetworkSecurityGroup" => "string"} split => { "[records][properties][flows][flows][flowTuples]" => "," } add_field => { "unixtimestamp" => "%{[records][properties][flows][flows][flowTuples][0]}" "srcIp" => "%{[records][properties][flows][flows][flowTuples][1]}" "destIp" => "%{[records][properties][flows][flows][flowTuples][2]}" "srcPort" => "%{[records][properties][flows][flows][flowTuples][3]}" "destPort" => "%{[records][properties][flows][flows][flowTuples][4]}" "protocol" => "%{[records][properties][flows][flows][flowTuples][5]}" "trafficflow" => "%{[records][properties][flows][flows][flowTuples][6]}" "traffic" => "%{[records][properties][flows][flows][flowTuples][7]}" "flowstate" => "%{[records][properties][flows][flows][flowTuples][8]}" "packetsSourceToDest" => "%{[records][properties][flows][flows][flowTuples][9]}" "bytesSentSourceToDest" => "%{[records][properties][flows][flows][flowTuples][10]}" "packetsDestToSource" => "%{[records][properties][flows][flows][flowTuples][11]}" "bytesSentDestToSource" => "%{[records][properties][flows][flows][flowTuples][12]}" } add_field => { "time" => "%{[records][time]}" "systemId" => "%{[records][systemId]}" "category" => "%{[records][category]}" "resourceId" => "%{[records][resourceId]}" "operationName" => "%{[records][operationName]}" "Version" => "%{[records][properties][Version]}" "rule" => "%{[records][properties][flows][rule]}" "mac" => "%{[records][properties][flows][flows][mac]}" } convert => {"unixtimestamp" => "integer"} convert => {"srcPort" => "integer"} convert => {"destPort" => "integer"} add_field => { "message" => "%{Message}" } } date { match => ["unixtimestamp" , "UNIX"] } } output { stdout { codec => rubydebug } elasticsearch { hosts => "localhost" index => "nsg-flow-logs" } }
Het opgegeven Logstash-configuratiebestand bestaat uit drie delen: de invoer, het filter en de uitvoer. De invoersectie wijst de invoerbron aan van de logboeken die Logstash gaat verwerken. In dit geval gebruiken we een invoegtoepassing voor het invoeren van azureblob (geïnstalleerd in de volgende stappen) waarmee we toegang krijgen tot de JSON-bestanden van het NSG-stroomlogboek die zijn opgeslagen in blobopslag.
De filtersectie platt vervolgens elk stroomlogboekbestand af, zodat elke afzonderlijke stroom-tuple en de bijbehorende eigenschappen een afzonderlijke Logstash-gebeurtenis worden.
Ten slotte stuurt de uitvoersectie elke Logstash-gebeurtenis door naar de ElasticSearch-server. U kunt het logstash-configuratiebestand aanpassen aan uw specifieke behoeften.
De Logstash-invoerinvoegtoepassing voor Azure Blob Storage installeren
Met deze Logstash-invoegtoepassing kunt u rechtstreeks toegang krijgen tot de stroomlogboeken vanuit hun aangewezen Blob Storage-account. Als u deze invoegtoepassing wilt installeren, voert u de opdracht uit vanuit de standaard-Logstash-installatiemap (in dit geval /usr/share/logstash/bin):
sudo /usr/share/logstash/bin/logstash-plugin install logstash-input-azureblob
Zie de Logstash-invoerinvoegtoepassing voor Azure Storage-blobs voor meer informatie over deze invoegtoepassing.
ElasticSearch installeren
U kunt het volgende script gebruiken om ElasticSearch te installeren. Zie Elastic Stack voor meer informatie over het installeren van ElasticSearch.
sudo apt-get install apt-transport-https openjdk-8-jre-headless uuid-runtime pwgen -y
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb https://packages.elastic.co/elasticsearch/5.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-5.x.list
sudo apt-get update && apt-get install elasticsearch
sudo sed -i s/#cluster.name:.*/cluster.name:\ grafana/ /etc/elasticsearch/elasticsearch.yml
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.service
Grafana installeren
Voer de volgende opdrachten uit om Grafana te installeren en uit te voeren:
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.5.1_amd64.deb
sudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_4.5.1_amd64.deb
sudo service grafana-server start
Zie Installeren op Debian/Ubuntu voor aanvullende installatie-informatie.
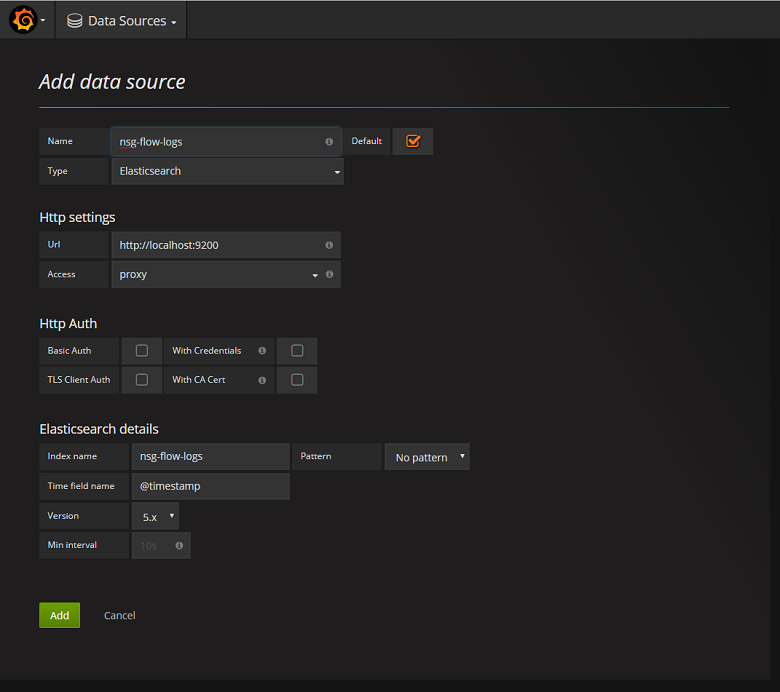
De ElasticSearch-server toevoegen als gegevensbron
Vervolgens moet u de ElasticSearch-index met stroomlogboeken toevoegen als gegevensbron. U kunt een gegevensbron toevoegen door gegevensbron toevoegen te selecteren en het formulier in te vullen met de relevante informatie. Een voorbeeld van deze configuratie vindt u in de volgende schermopname:
Een dashboard maken
Nu u Grafana hebt geconfigureerd om te lezen uit de ElasticSearch-index met NSG-stroomlogboeken, kunt u dashboards maken en personaliseren. Als u een nieuw dashboard wilt maken, selecteert u Uw eerste dashboard maken. In de volgende voorbeeldgrafiekconfiguratie ziet u stromen die zijn gesegmenteerd op NSG-regel:
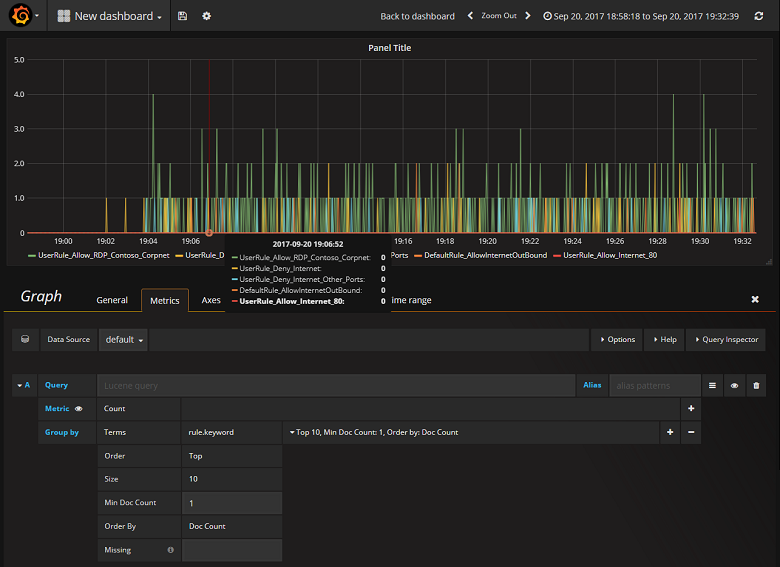
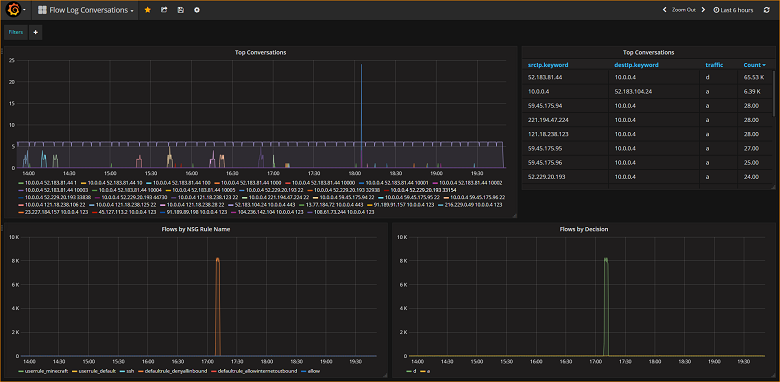
In de volgende schermopname ziet u een grafiek en grafiek met de bovenste stromen en hun frequentie. Stromen worden ook weergegeven door NSG-regel en stromen per beslissing. Grafana is zeer aanpasbaar, dus het is raadzaam dat u dashboards maakt die aansluiten bij uw specifieke bewakingsbehoeften. In het volgende voorbeeld ziet u een typisch dashboard:
Conclusie
Door Network Watcher te integreren met ElasticSearch en Grafana, hebt u nu een handige en gecentraliseerde manier om NSG-stroomlogboeken en andere gegevens te beheren en te visualiseren. Grafana heeft een aantal andere krachtige grafiekfuncties die ook kunnen worden gebruikt om stroomlogboeken verder te beheren en beter inzicht te krijgen in uw netwerkverkeer. Nu u een Grafana-exemplaar hebt ingesteld en verbonden met Azure, kunt u de andere functionaliteit die het biedt, blijven verkennen.
Volgende stappen
- Meer informatie over het gebruik van Network Watcher.