Kennisarchief in Azure AI Search
Kennisarchief is secundaire opslag voor ai-verrijkte inhoud die is gemaakt door een vaardighedenset in Azure AI Search. In Azure AI Search verzendt een indexeringstaak altijd uitvoer naar een zoekindex, maar als u een vaardighedenset koppelt aan een indexeerfunctie, kunt u desgewenst ook ai-verrijkte uitvoer verzenden naar een container of tabel in Azure Storage. Een kennisarchief kan worden gebruikt voor onafhankelijke analyse of downstreamverwerking in niet-zoekscenario's zoals kennisanalyse.
De twee uitvoer van indexering, een zoekindex en kennisarchief, sluiten elkaar wederzijds af van producten van dezelfde pijplijn. Ze worden afgeleid van dezelfde invoer en bevatten dezelfde gegevens, maar hun inhoud is gestructureerd, opgeslagen en gebruikt in verschillende toepassingen.

Fysiek is een kennisarchief Azure Storage, Azure Table Storage, Azure Blob Storage of beide. Elk hulpprogramma of proces dat verbinding kan maken met Azure Storage, kan de inhoud van een kennisarchief gebruiken. Er is geen queryondersteuning in Azure AI Search voor het ophalen van inhoud uit een kennisarchief.
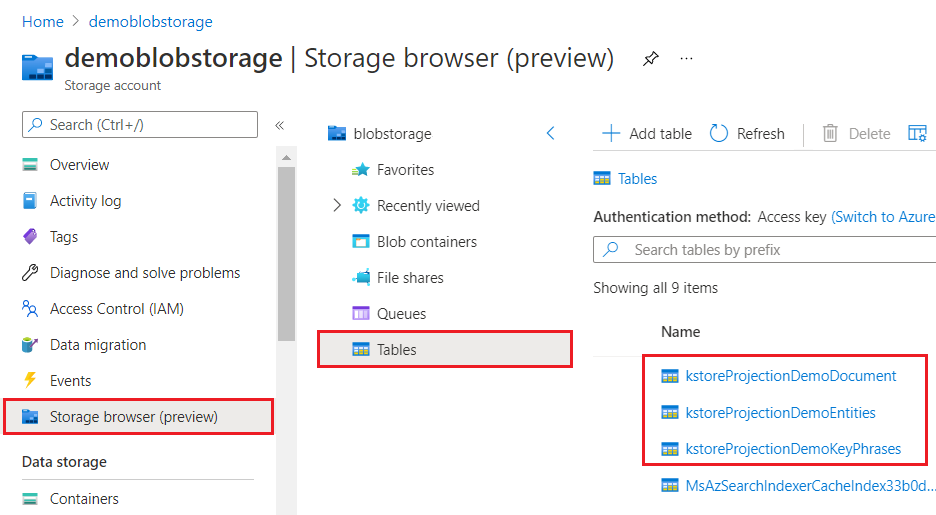
Wanneer u deze bekijkt via Azure Portal, ziet een kennisarchief eruit als elke andere verzameling tabellen, objecten of bestanden. In de volgende schermopname ziet u een kennisarchief dat bestaat uit drie tabellen. U kunt een naamconventie, zoals een kstore voorvoegsel, gebruiken om uw inhoud bij elkaar te houden.
Voordelen van kennisarchief
De belangrijkste voordelen van een kennisarchief zijn tweevoudig: flexibele toegang tot inhoud en de mogelijkheid om gegevens vorm te geven.
In tegenstelling tot een zoekindex die alleen toegankelijk is via query's in Azure AI Search, is een kennisarchief toegankelijk voor elk hulpprogramma, elke app of elk proces dat verbindingen met Azure Storage ondersteunt. Deze flexibiliteit opent nieuwe scenario's voor het gebruik van de geanalyseerde en verrijkte inhoud die wordt geproduceerd door een verrijkingspijplijn.
Dezelfde vaardighedenset waarmee gegevens worden verrijkt, kunnen ook worden gebruikt om gegevens vorm te geven. Sommige hulpprogramma's zoals Power BI werken beter met tabellen, terwijl een data science-workload mogelijk een complexe gegevensstructuur in een blob-indeling vereist. Door een Shaper-vaardigheid toe te voegen aan een vaardighedenset, hebt u controle over de vorm van uw gegevens. U kunt deze shapes vervolgens doorgeven aan projecties, tabellen of blobs, om fysieke gegevensstructuren te maken die overeenkomen met het beoogde gebruik van de gegevens.
In de volgende video worden zowel deze voordelen als meer uitgelegd.
Definitie van kennisarchief
Een kennisarchief wordt gedefinieerd in een definitie van een vaardighedenset en heeft twee onderdelen:
Een verbindingsreeks naar Azure Storage
Projecties die bepalen of het kennisarchief bestaat uit tabellen, objecten of bestanden. Het projectieelement is een matrix. U kunt meerdere sets tabel-object-bestandscombinaties maken binnen één kennisarchief.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
Het type projectie dat u in deze structuur opgeeft, bepaalt het type opslag dat wordt gebruikt door kennisarchief, maar niet de structuur. Velden in tabellen, objecten en bestanden worden bepaald door shaper-uitvoer als u het kennisarchief programmatisch maakt of door de wizard Gegevens importeren als u de portal gebruikt.
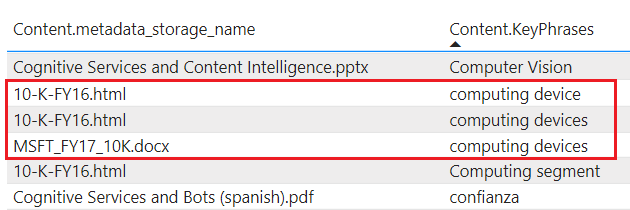
tablesproject verrijkte inhoud in Table Storage. Definieer een tabelprojectie wanneer u tabellaire rapportagestructuren nodig hebt voor invoer in analytische hulpprogramma's of als gegevensframes exporteren naar andere gegevensarchieven. U kunt meerderetablesopgeven binnen dezelfde projectiegroep om een subset of dwarsdoorsnede van verrijkte documenten op te halen. Binnen dezelfde projectiegroep blijven tabelrelaties behouden, zodat u allemaal ermee kunt werken.Geprojecteerde inhoud wordt niet geaggregeerd of genormaliseerd. In de volgende schermopname ziet u een tabel, gesorteerd op sleutelterm, met het bovenliggende document dat wordt aangegeven in de aangrenzende kolom. In tegenstelling tot gegevensopname tijdens het indexeren, is er geen taalkundige analyse of aggregatie van inhoud. Plural forms and differences in casing are considered unique instances.
objectsproject JSON-document in Blob Storage. De fysieke weergave van een eenobjectis een hiërarchische JSON-structuur die een verrijkt document vertegenwoordigt.filesprojectafbeeldingsbestanden in Blob Storage. Afileis een afbeelding die uit een document is geëxtraheerd en intact is overgebracht naar Blob Storage. Hoewel het de naam 'bestanden' heeft, wordt deze weergegeven in Blob Storage, niet in bestandsopslag.
Een Knowledge Store maken
Als u kennisarchief wilt maken, gebruikt u de portal of een API.
U hebt Azure Storage, een vaardighedenset en een indexeerfunctie nodig. Omdat indexeerfuncties een zoekindex vereisen, moet u ook een indexdefinitie opgeven.
Ga met de portalbenadering voor de snelste route naar een voltooid kennisarchief. Of kies de REST API voor een dieper inzicht in hoe objecten worden gedefinieerd en gerelateerd.
Maak uw eerste kennisarchief in vier stappen met behulp van de wizard Gegevens importeren.
Definieer een gegevensbron die de gegevens bevat die u wilt verrijken.
Definieer een vaardighedenset. De vaardighedenset bevat verrijkingsstappen en het kennisarchief.
Definieer een indexschema. U hebt er mogelijk geen nodig, maar indexeerfuncties vereisen dit. De wizard kan een index afleiden.
Voltooi de wizard. Gegevensextractie, verrijking en het maken van kennisarchieven vinden plaats in deze laatste stap.
De wizard automatiseert verschillende taken. In het bijzonder worden zowel het vormgeven als projecties (definities van fysieke gegevensstructuren in Azure Storage) voor u gemaakt.
Verbinding maken met apps
Zodra verrijkte inhoud in de opslag bestaat, kan elk hulpprogramma of elke technologie die verbinding maakt met Azure Storage worden gebruikt om de inhoud te verkennen, analyseren of gebruiken. De volgende lijst is een begin:
Opslagverkenner of Storage-browser (preview) in Azure Portal om verrijkte documentstructuur en -inhoud weer te geven. Beschouw dit als uw basislijnhulpprogramma voor het weergeven van inhoud van het kennisarchief.
Power BI voor rapportage en analyse.
Azure Data Factory voor verdere manipulatie.
Levenscyclus van inhoud
Telkens wanneer u de indexeerfunctie en vaardighedenset uitvoert, wordt het kennisarchief bijgewerkt als de vaardighedenset of onderliggende brongegevens zijn gewijzigd. Wijzigingen die door de indexeerfunctie worden opgehaald, worden via het verrijkingsproces doorgegeven aan de projecties in het kennisarchief, zodat uw verwachte gegevens een huidige weergave van inhoud in de oorspronkelijke gegevensbron zijn.
Notitie
Hoewel u de gegevens in de projecties kunt bewerken, worden alle wijzigingen overschreven tijdens de volgende aanroep van de pijplijn, ervan uitgaande dat het document in de brongegevens wordt bijgewerkt.
Wijzigingen in brongegevens
Voor gegevensbronnen die ondersteuning bieden voor het bijhouden van wijzigingen, verwerkt een indexeerfunctie nieuwe en gewijzigde documenten en slaat u bestaande documenten over die al zijn verwerkt. Tijdstempelgegevens variëren per gegevensbron, maar in een blobcontainer kijkt de indexeerfunctie naar de lastmodified datum om te bepalen welke blobs moeten worden opgenomen.
Wijzigingen in een vaardighedenset
Als u wijzigingen aanbrengt in een vaardighedenset, moet u het opslaan van verrijkte documenten in de cache inschakelen om bestaande verrijkingen waar mogelijk opnieuw te gebruiken.
Zonder incrementele caching verwerkt de indexeerfunctie altijd documenten in volgorde van de hoge watermarkering, zonder achteruit te gaan. Voor blobs verwerkt de indexeerfunctie blobs gesorteerd op lastModified, ongeacht eventuele wijzigingen in de instellingen van de indexeerfunctie of de vaardighedenset. Als u een vaardighedenset wijzigt, worden eerder verwerkte documenten niet bijgewerkt om de nieuwe vaardighedenset weer te geven. Documenten die zijn verwerkt nadat de vaardighedenset is gewijzigd, maken gebruik van de nieuwe vaardighedenset, wat resulteert in indexdocumenten als een combinatie van oude en nieuwe vaardighedensets.
Met incrementele caching en na een update van een vaardighedenset gebruikt de indexeerfunctie eventuele verrijkingen die niet worden beïnvloed door de wijziging van de vaardighedenset. Upstream-verrijkingen worden opgehaald uit de cache, net als alle verrijkingen die onafhankelijk en geïsoleerd zijn van de vaardigheid die is gewijzigd.
verwijderingen
Hoewel een indexeerfunctie structuren en inhoud in Azure Storage maakt en bijwerken, worden deze niet verwijderd. Projecties blijven bestaan, zelfs wanneer de indexeerfunctie of vaardighedenset wordt verwijderd. Als eigenaar van het opslagaccount moet u een projectie verwijderen als deze niet meer nodig is.
Volgende stappen
Kennisarchief biedt persistentie van verrijkte documenten, handig bij het ontwerpen van een vaardighedenset of het maken van nieuwe structuren en inhoud voor gebruik door clienttoepassingen die toegang hebben tot een Azure Storage-account.
De eenvoudigste methode voor het maken van verrijkte documenten is via de portal, maar een REST-client en REST API's kunnen meer inzicht geven in hoe objecten programmatisch worden gemaakt en ernaar verwezen.