Wizard Gegevens importeren in Azure AI Search
Met de wizard Gegevens importeren in Azure Portal worden meerdere objecten gemaakt die worden gebruikt voor indexering en AI-verrijking in een zoekservice. Als u niet bekend bent met Azure AI Search, is dit een van de krachtigste functies die u kunt gebruiken. Met minimale inspanning kunt u een indexerings- of verrijkingspijplijn maken die de meeste functionaliteit van Azure AI Search uitvoert.
Als u de wizard gebruikt voor het testen van proof-of-concept, wordt in dit artikel de interne werking van de wizard uitgelegd, zodat u deze effectiever kunt gebruiken.
Dit artikel is geen stap voor stap. Voor hulp bij het gebruik van de wizard met ingebouwde voorbeeldgegevens raadpleegt u de quickstart: Een zoekindex of quickstart maken: Een vaardighedenset voor tekstomzetting en entiteit maken.
De wizard starten
Open in Azure Portal de zoekservicepagina vanuit het dashboard of zoek uw service in de lijst met services. Selecteer gegevens importeren op de pagina Overzicht van de service bovenaan.

De wizard wordt volledig uitgevouwen in het browservenster, zodat u meer ruimte hebt om te werken.
U kunt ook importgegevens starten uit andere Azure-services, waaronder Azure Cosmos DB, Azure SQL Database, SQL Managed Instance en Azure Blob Storage. Zoek naar Azure AI Search toevoegen in het linkernavigatiedeelvenster op de overzichtspagina van de service.
Objecten die door de wizard zijn gemaakt
De wizard voert de objecten in de volgende tabel uit. Nadat de objecten zijn gemaakt, kunt u hun JSON-definities bekijken in de portal of ze aanroepen vanuit code.
| Object | Beschrijving |
|---|---|
| Indexeerfunctie | Een configuratieobject dat een gegevensbron, doelindex, een optionele vaardighedenset, optionele planning en optionele configuratie-instellingen opgeeft voor fout-handing en base-64-codering. |
| Gegevensbron | Bewaart verbindingsgegevens met een ondersteunde gegevensbron in Azure. Een gegevensbronobject wordt uitsluitend gebruikt met indexeerfuncties. |
| Index | Fysieke gegevensstructuur die wordt gebruikt voor zoeken in volledige tekst en andere query's. |
| Vaardighedenset | Optioneel. Een volledige set instructies voor het bewerken, transformeren en vormgeven van inhoud, waaronder het analyseren en extraheren van informatie uit afbeeldingsbestanden. Tenzij het werkvolume onder de limiet van 20 transacties per indexeerfunctie per dag valt, moet de vaardighedenset een verwijzing bevatten naar een Azure AI-resource voor meerdere services die verrijking biedt. |
| Kennisarchief | Optioneel. Slaat uitvoer op van een AI-verrijkingspijplijn in tabellen en blobs in Azure Storage voor onafhankelijke analyse of downstreamverwerking. |
Voordelen en beperkingen
Voordat u code schrijft, kunt u de wizard gebruiken voor prototypen en testen van proof-of-concept. De wizard maakt verbinding met externe gegevensbronnen, voorbeeldt de gegevens om een initiële index te maken en importeert vervolgens de gegevens als JSON-documenten in een index in Azure AI Search.
Als u vaardighedensets evalueert, verwerkt de wizard alle toewijzingen van uitvoervelden en voegt u helperfuncties toe om bruikbare objecten te maken. Tekstsplitsing wordt toegevoegd als u een parseermodus opgeeft. Tekst samenvoegen wordt toegevoegd als u afbeeldingsanalyse hebt gekozen, zodat de wizard tekstbeschrijvingen opnieuw kan combineren met afbeeldingsinhoud. Shaper-vaardigheden die zijn toegevoegd om geldige projecties te ondersteunen als u de optie voor het kennisarchief hebt gekozen. Alle bovenstaande taken hebben een leercurve. Als u geen ervaring hebt met verrijking, kunt u met de mogelijkheid om deze stappen af te handelen, de waarde van een vaardigheid meten zonder dat u veel tijd en moeite hoeft te investeren.
Steekproeven zijn het proces waarmee een indexschema wordt afgeleid en er zijn enkele beperkingen. Wanneer de gegevensbron wordt gemaakt, kiest de wizard een willekeurig voorbeeld van documenten om te bepalen welke kolommen deel uitmaken van de gegevensbron. Niet alle bestanden worden gelezen, omdat dit mogelijk uren kan duren voor zeer grote gegevensbronnen. Gezien een selectie van documenten, bronmetagegevens, zoals veldnaam of type, wordt gebruikt om een verzameling velden in een indexschema te maken. Afhankelijk van de complexiteit van brongegevens moet u mogelijk het oorspronkelijke schema bewerken voor nauwkeurigheid of deze uitbreiden voor volledigheid. U kunt uw wijzigingen inline aanbrengen op de pagina indexdefinitie.
Over het algemeen zijn de voordelen van het gebruik van de wizard duidelijk: zolang aan de vereisten wordt voldaan, kunt u binnen enkele minuten een prototype maken van een doorzoekbare index. Sommige complexiteiten van het indexeren, zoals het serialiseren van gegevens als JSON-documenten, worden verwerkt door de wizard.
De wizard is niet zonder beperkingen. Beperkingen worden als volgt samengevat:
De wizard biedt geen ondersteuning voor iteratie of hergebruik. Elke pass through de wizard maakt een nieuwe index, vaardighedenset en indexeerfunctieconfiguratie. Alleen gegevensbronnen kunnen worden behouden en opnieuw worden gebruikt in de wizard. Als u andere objecten wilt bewerken of verfijnen, verwijdert u de objecten en begint u opnieuw, of gebruikt u de REST API's of .NET SDK om de structuren te wijzigen.
Broninhoud moet zich in een ondersteunde gegevensbron bevinden.
Steekproeven zijn meer dan een subset van brongegevens. Voor grote gegevensbronnen is het mogelijk dat de wizard velden mist. Mogelijk moet u het schema uitbreiden of de uitgestelde gegevenstypen corrigeren als er onvoldoende steekproeven zijn.
AI-verrijking, zoals weergegeven in de portal, is beperkt tot een subset van ingebouwde vaardigheden.
Een kennisarchief, dat door de wizard kan worden gemaakt, is beperkt tot enkele standaardprojecties en maakt gebruik van een standaardnaamconventie. Als u namen of projecties wilt aanpassen, moet u het kennisarchief maken via REST API of de SDK's.
Openbare toegang tot alle netwerken moet zijn ingeschakeld op de ondersteunde gegevensbron terwijl de wizard wordt gebruikt, omdat de portal tijdens de installatie geen toegang heeft tot de gegevensbron als openbare toegang is uitgeschakeld. Dit betekent dat als uw gegevensbron een firewall heeft ingeschakeld of als u een gedeelde privékoppeling hebt ingesteld, u deze moet uitschakelen, de wizard Gegevens importeren uitvoert en deze vervolgens inschakelt nadat de installatie van de wizard is voltooid. Als dit geen optie is, kunt u azure AI Search-gegevensbron, indexeerfunctie, vaardighedenset en index maken via REST API of de SDK's.
Workflow
De wizard is ingedeeld in vier hoofdstappen:
Verbinding maken naar een ondersteunde Azure-gegevensbron.
Maak een indexschema, afgeleid door steekproefbrongegevens.
Voeg eventueel AI-verrijkingen toe om inhoud en structuur te extraheren of te genereren. In deze stap worden invoer voor het maken van een kennisarchief verzameld.
Voer de wizard uit om objecten te maken, gegevens te laden, een schema en andere configuratieopties in te stellen.
De werkstroom is een pijplijn, dus op één manier. U kunt de wizard niet gebruiken om een van de gemaakte objecten te bewerken, maar u kunt andere portalhulpprogramma's gebruiken, zoals de index- of indexeerfunctieontwerper of de JSON-editors, voor toegestane updates.
Configuratie van gegevensbron in de wizard
De wizard Gegevens importeren maakt verbinding met een externe ondersteunde gegevensbron met behulp van de interne logica van Azure AI Search-indexeerfuncties, die zijn uitgerust om de bron te samplen, metagegevens te lezen, documenten te kraken om inhoud en structuur te lezen en inhoud te serialiseren als JSON voor volgende import naar Azure AI Search.
U kunt een verbinding met een ondersteunde gegevensbron in een ander abonnement of een andere regio plakken, maar de optie Een bestaande verbindingskiezer kiezen is gericht op het actieve abonnement.
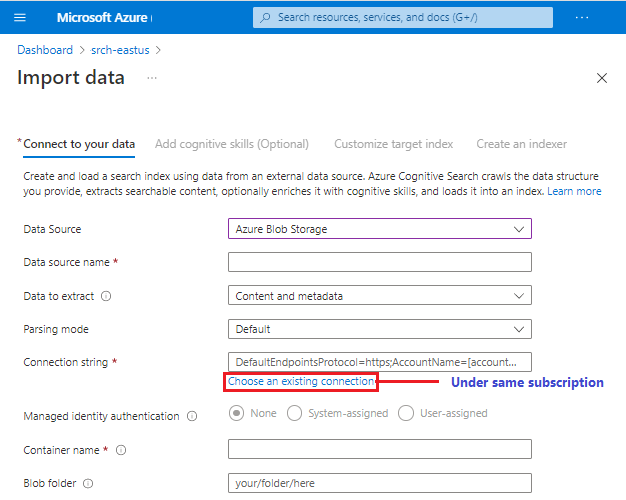
Niet alle voorbeeldgegevensbronnen zijn gegarandeerd beschikbaar in de wizard. Omdat elke gegevensbron de mogelijkheid heeft om andere wijzigingen downstream in te voeren, wordt een voorbeeldgegevensbron alleen toegevoegd aan de lijst met gegevensbronnen als deze volledig ondersteuning biedt voor alle ervaringen in de wizard, zoals definitie van vaardighedenset en indexschemadeductie.
U kunt alleen importeren uit één tabel, databaseweergave of equivalente gegevensstructuur, maar de structuur kan hiërarchische of geneste substructuren bevatten. Zie Complexe typen modelleren voor meer informatie.
Vaardighedensetconfiguratie in de wizard
De configuratie van de vaardighedenset vindt plaats na de definitie van de gegevensbron, omdat het type gegevensbron de beschikbaarheid van bepaalde ingebouwde vaardigheden informeert. Met name als u bestanden indexeert uit Blob Storage, bepaalt uw keuze voor het parseren van deze bestanden of sentimentanalyse beschikbaar is.
De wizard voegt de vaardigheden toe die u kiest, maar er worden ook andere vaardigheden toegevoegd die nodig zijn voor het bereiken van een geslaagd resultaat. Als u bijvoorbeeld een kennisarchief opgeeft, voegt de wizard een Shaper-vaardigheid toe om projecties (of fysieke gegevensstructuren) te ondersteunen.
Vaardighedensets zijn optioneel en er is een knop onder aan de pagina om verder te gaan als u geen AI-verrijking wilt.
Indexschemaconfiguratie in de wizard
De wizard voorbeeldt uw gegevensbron om de velden en het veldtype te detecteren. Afhankelijk van de gegevensbron kan het ook velden bieden voor het indexeren van metagegevens.
Omdat steekproeven een onnauwkeurig oefening zijn, bekijkt u de index voor de volgende overwegingen:
Is de lijst met velden nauwkeurig? Als uw gegevensbron velden bevat die niet zijn opgehaald in steekproeven, kunt u handmatig nieuwe velden toevoegen die een steekproef hebben gemist en die geen waarde toevoegen aan een zoekervaring of die niet worden gebruikt in een filterexpressie of scoreprofiel.
Is het gegevenstype geschikt voor de binnenkomende gegevens? Azure AI Search ondersteunt de gegevenstypen van het entiteitsgegevensmodel (EDM). Voor Azure SQL-gegevens is er een toewijzingsgrafiek waarin equivalente waarden worden vastgelegd. Zie Veldtoewijzingen en -transformaties voor meer achtergrondinformatie.
Hebt u één veld dat als sleutel kan fungeren? Dit veld moet Edm.string zijn en moet een document uniek identificeren. Voor relationele gegevens kan deze worden toegewezen aan een primaire sleutel. Voor blobs kan het de
metadata-storage-path. Als veldwaarden spaties of streepjes bevatten, moet u de optie Base-64-coderingssleutel instellen in de stap Indexeerfunctie maken onder Geavanceerde opties om de validatiecontrole voor deze tekens te onderdrukken.Stel kenmerken in om te bepalen hoe dat veld wordt gebruikt in een index.
Neem uw tijd met deze stap omdat kenmerken de fysieke expressie van velden in de index bepalen. Als u later kenmerken wilt wijzigen, zelfs programmatisch, moet u de index bijna altijd verwijderen en opnieuw opbouwen. Kernkenmerken zoals Doorzoekbaar en Ophaalbaar hebben een te verwaarlozen invloed op de opslag. Het inschakelen van filters en het gebruik van suggesties verhogen de opslagvereisten.
Doorzoekbaar maakt zoeken in volledige tekst mogelijk. Elk veld dat wordt gebruikt in vrije formulierquery's of in query-expressies, moet dit kenmerk hebben. Omgekeerde indexen worden gemaakt voor elk veld dat u als doorzoekbaar markeert.
Ophalen mogelijk retourneert het veld in zoekresultaten. Elk veld dat inhoud aan zoekresultaten levert, moet dit kenmerk hebben. Het instellen van dit veld heeft geen invloed op de indexgrootte.
Met Filterbaar kan naar het veld worden verwezen in filterexpressies. Elk veld dat in een $filter expressie wordt gebruikt, moet dit kenmerk hebben. Filterexpressies zijn bedoeld voor exacte overeenkomsten. Omdat teksttekenreeksen intact blijven, is er meer opslagruimte vereist voor de exacte inhoud.
Facetable maakt het veld mogelijk voor facetnavigatie. Alleen velden die als filterbaar zijn gemarkeerd, kunnen worden gemarkeerd als Facetable.
Sorteerbaar maakt het mogelijk dat het veld in een sortering wordt gebruikt. Elk veld dat in een $Orderby expressie wordt gebruikt, moet dit kenmerk hebben.
Hebt u lexicale analyse nodig? Voor Edm.string-velden die doorzoekbaar zijn, kunt u een Analyzer instellen als u taalverbreeding en query's wilt uitvoeren.
De standaardwaarde is Standard Lucene, maar u kunt Microsoft Engels kiezen als u De analyse van Microsoft wilt gebruiken voor geavanceerde lexicale verwerking, zoals het oplossen van onregelmatige zelfstandig naamwoorden en werkwoordvormen. Alleen taalanalyses kunnen worden opgegeven in de portal. Het gebruik van een aangepaste analyse of een niet-taalanalyse, zoals Trefwoord, Patroon, enzovoort, moet programmatisch worden uitgevoerd. Zie Taalanalyses toevoegen voor meer informatie over analyse.
Hebt u typeaheadfunctionaliteit nodig in de vorm van automatisch aanvullen of voorgestelde resultaten? Schakel het selectievakje Suggestie in om suggesties voor typeaheadquery's in te schakelen en automatisch aan te vullen voor geselecteerde velden. Suggesties voegen toe aan het aantal tokenized termen in uw index en verbruiken dus meer opslagruimte.
Configuratie van indexeerfunctie in de wizard
De laatste pagina van de wizard verzamelt gebruikersinvoer voor de configuratie van de indexeerfunctie. U kunt een planning opgeven en andere opties instellen die variëren per gegevensbrontype.
Intern stelt de wizard ook de volgende definities in, die pas zichtbaar zijn in de indexeerfunctie nadat deze is gemaakt:
- veldtoewijzingen tussen de gegevensbron en index
- uitvoerveldtoewijzingen tussen vaardigheidsuitvoer en een index
Volgende stappen
De beste manier om de voordelen en beperkingen van de wizard te begrijpen, is door deze te doorlopen. In de volgende quickstart wordt elke stap uitgelegd.