Prestaties analyseren in Azure AI Search
In dit artikel worden de hulpprogramma's, gedragingen en benaderingen beschreven voor het analyseren van query- en indexeringsprestaties in Azure AI Search.
Basislijnnummers ontwikkelen
Bij een grote implementatie is het essentieel om een prestatiebenchmarkingtest van uw Azure AI-Search-service uit te voeren voordat u deze in productie neemt. U moet zowel de verwachte belasting van de zoekquery testen, maar ook de verwachte werkbelastingen voor gegevensopname (indien mogelijk beide workloads tegelijk uitvoeren). Met benchmarknummers kunt u de juiste zoeklaag, serviceconfiguratie en verwachte querylatentie valideren.
Voor het ontwikkelen van benchmarks raden we het hulpprogramma azure-search-performance-testing (GitHub) aan.
Als u de effecten van een gedistribueerde servicearchitectuur wilt isoleren, test u de serviceconfiguraties van één replica en één partitie.
Notitie
Voor de lagen Geoptimaliseerd voor opslag (L1 en L2) moet u een lagere querydoorvoer en een hogere latentie verwachten dan de Standard-lagen.
Resourcelogboekregistratie gebruiken
Het belangrijkste diagnostische hulpprogramma tot de beschikking van een beheerder is logboekregistratie van resources. Resourcelogboekregistratie is het verzamelen van operationele gegevens en metrische gegevens over uw zoekservice. Resourcelogboekregistratie is ingeschakeld via Azure Monitor. Er zijn kosten verbonden aan het gebruik van Azure Monitor en het opslaan van gegevens, maar als u deze inschakelt voor uw service, kan het nuttig zijn om prestatieproblemen te onderzoeken.
In de volgende afbeelding ziet u de keten van gebeurtenissen in een queryaanvraag en -antwoord. Latentie kan zich voordoen op een van deze, ongeacht of tijdens een netwerkoverdracht, verwerking van inhoud in de app-serviceslaag of in een zoekservice. Een belangrijk voordeel van resourcelogboekregistratie is dat activiteiten vanuit het perspectief van de zoekservice worden vastgelegd, wat betekent dat het logboek u kan helpen bepalen of het prestatieprobleem wordt veroorzaakt door problemen met de query of indexering, of een ander foutpunt.
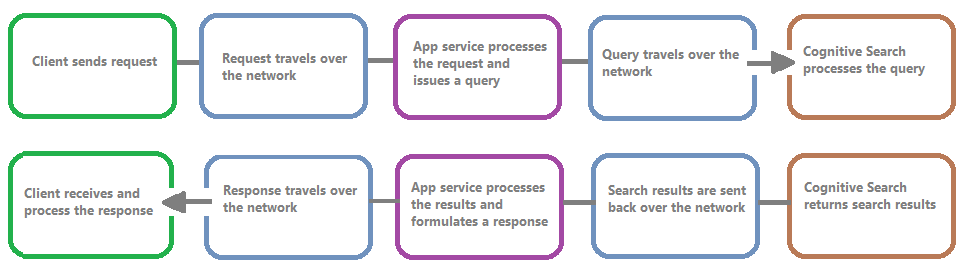
Resourcelogboekregistratie biedt u opties voor het opslaan van vastgelegde gegevens. We raden u aan Log Analytics te gebruiken, zodat u geavanceerde Kusto-query's kunt uitvoeren op basis van de gegevens om veel vragen over gebruik en prestaties te beantwoorden.
Op de portalpagina's van de zoekservice kunt u logboekregistratie via diagnostische instellingen inschakelen en vervolgens Kusto-query's uitgeven op Basis van Log Analytics door Logboeken te kiezen. Zie Logboekgegevens verzamelen en analyseren voor meer informatie over het instellen.
Beperkingsgedrag
Beperking treedt op wanneer de zoekservice capaciteit heeft. Beperking kan optreden tijdens query's of indexering. Aan de clientzijde resulteert een API-aanroep in een HTTP-antwoord van 503 wanneer deze is beperkt. Tijdens het indexeren is er ook de mogelijkheid om een HTTP-antwoord van 207 te ontvangen, wat aangeeft dat een of meer items niet konden worden geïndexerd. Deze fout is een indicator dat de zoekservice bijna in de buurt van de capaciteit komt.
Probeer als vuistregel de hoeveelheid beperking en eventuele patronen te kwantificeren. Als bijvoorbeeld één zoekquery van 500.000 wordt beperkt, is het misschien niet de moeite waard om te onderzoeken. Als een groot percentage query's echter gedurende een periode wordt beperkt, is dit een grotere zorg. Door te kijken naar beperking gedurende een periode, helpt het ook om tijdsbestekken te identificeren waar bandbreedtebeperking waarschijnlijker kan optreden en u te helpen bepalen hoe u dat het beste kunt gebruiken.
Een eenvoudige oplossing voor de meeste beperkingsproblemen is het genereren van meer resources in de zoekservice (meestal replica's voor beperking op basis van query's of partities voor indexering op basis van beperking). Het verhogen van replica's of partities voegt echter kosten toe. Daarom is het belangrijk om te weten waarom beperking helemaal plaatsvindt. Het onderzoeken van de voorwaarden die beperking veroorzaken, wordt in de volgende secties uitgelegd.
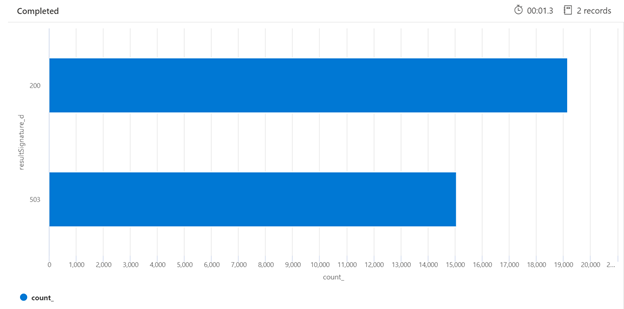
Hieronder ziet u een voorbeeld van een Kusto-query waarmee de uitsplitsing van HTTP-antwoorden van de zoekservice kan worden geïdentificeerd die onder belasting is geplaatst. Gedurende een periode van zeven dagen toont het weergegeven staafdiagram aan dat een relatief groot percentage van de zoekquery's is beperkt, vergeleken met het aantal geslaagde (200) antwoorden.
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
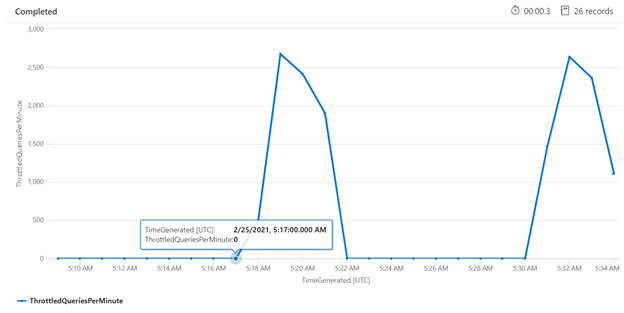
Het onderzoeken van beperking gedurende een specifieke periode kan u helpen bij het identificeren van de tijden waarin bandbreedtebeperking vaker voorkomt. In het onderstaande voorbeeld wordt een tijdreeksdiagram gebruikt om het aantal vertraagde query's weer te geven dat is opgetreden gedurende een opgegeven tijdsbestek. In dit geval zijn de vertraagde query's gecorreleerd met de tijden waarin de prestatiebenchmarking werd uitgevoerd.
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Afzonderlijke query's meten
In sommige gevallen kan het handig zijn om afzonderlijke query's te testen om te zien hoe ze presteren. Om dit te doen, is het belangrijk om te zien hoe lang de zoekservice duurt om het werk te voltooien, en hoe lang het duurt om de retouraanvraag van de client en terug naar de client te maken. De diagnostische logboeken kunnen worden gebruikt om afzonderlijke bewerkingen op te zoeken, maar het kan eenvoudiger zijn om dit allemaal vanuit een REST-client te doen.
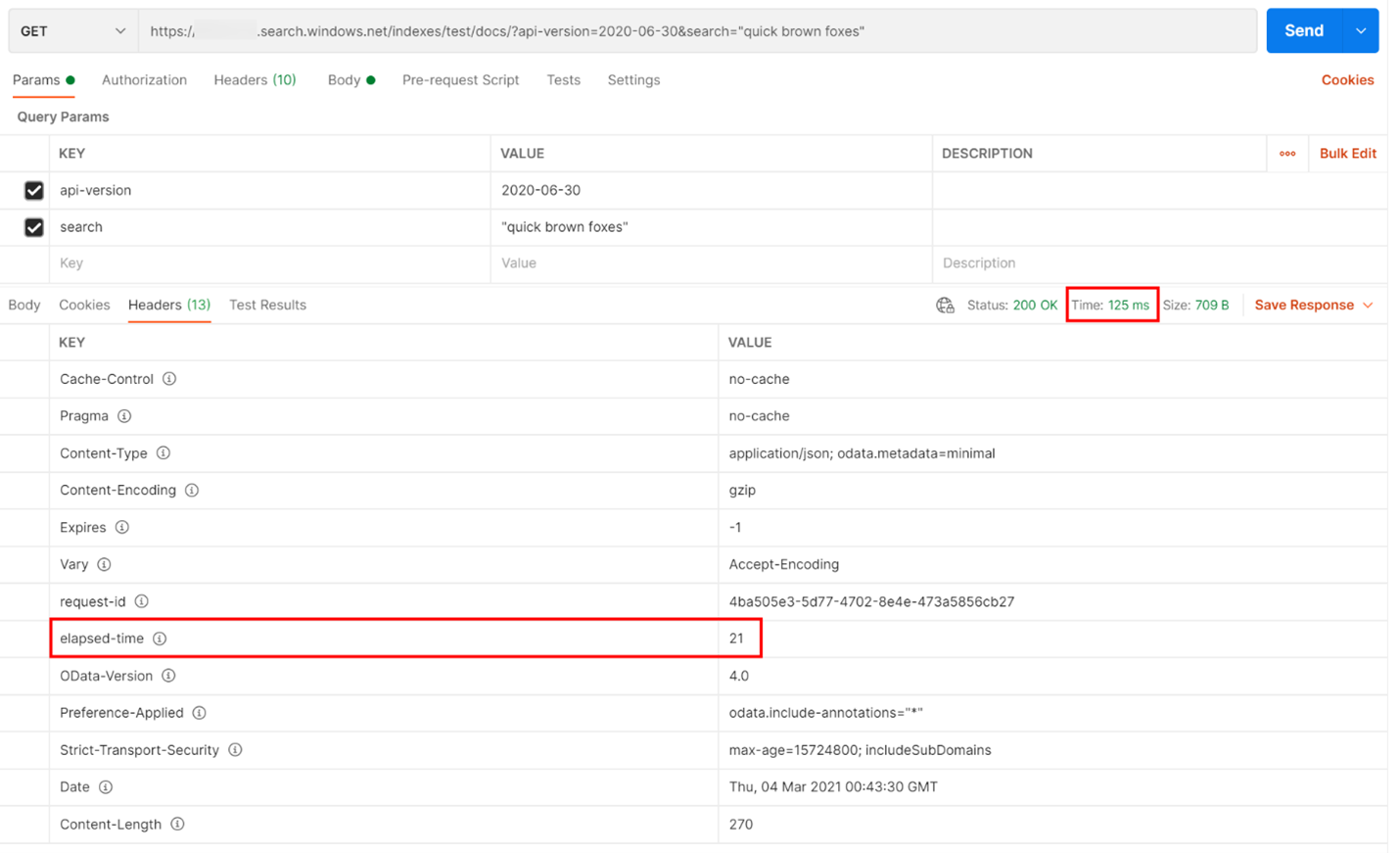
In het onderstaande voorbeeld is een op REST gebaseerde zoekquery uitgevoerd. Azure AI Search bevat in elk antwoord het aantal milliseconden dat nodig is om de query te voltooien, zichtbaar op het tabblad Kopteksten, in 'verstreken tijd'. Naast Status bovenaan het antwoord vindt u de retourduur, in dit geval 418 milliseconden (ms). In de resultatensectie is het tabblad Kopteksten gekozen. Als u deze twee waarden gebruikt, gemarkeerd met een rood vak in de onderstaande afbeelding, zien we dat de zoekservice 21 ms heeft geduurd om de zoekquery te voltooien en dat de volledige retouraanvraag van de client 125 ms heeft geduurd. Door deze twee getallen af te trekken, kunnen we vaststellen dat het 104 ms extra tijd kost om de zoekquery naar de zoekservice te verzenden en de zoekresultaten weer over te dragen naar de client.
Met deze techniek kunt u netwerklatenties isoleren van andere factoren die van invloed zijn op queryprestaties.
Queryfrequenties
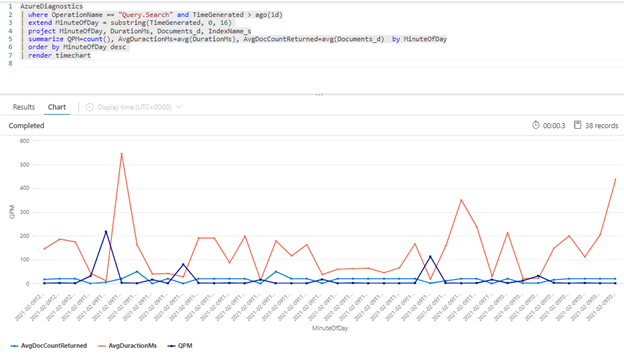
Een mogelijke reden voor uw zoekservice om aanvragen te beperken, is vanwege het enorme aantal query's dat wordt uitgevoerd waar het volume wordt vastgelegd als query's per seconde (QPS) of query's per minuut (QPM). Naarmate uw zoekservice meer QPS ontvangt, duurt het doorgaans langer en langer om op deze query's te reageren totdat deze niet meer kan worden bijgehouden, omdat hiermee een beperking van 503 HTTP-antwoord wordt teruggestuurd.
De volgende Kusto-query toont het queryvolume zoals gemeten in QPM, samen met de gemiddelde duur van een query in milliseconden (AvgDurationMS) en het gemiddelde aantal documenten (AvgDocCountReturned) dat in elke query wordt geretourneerd.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
Tip
Als u de gegevens achter deze grafiek wilt weergeven, verwijdert u de lijn | render timechart en voert u de query opnieuw uit.
Impact van indexering op query's
Een belangrijke factor om rekening mee te houden bij het bekijken van prestaties is dat indexering gebruikmaakt van dezelfde resources als zoekquery's. Als u een grote hoeveelheid inhoud indexeert, kunt u verwachten dat de latentie toeneemt naarmate de service probeert beide workloads te verwerken.
Als query's vertragen, bekijkt u de timing van de indexeringsactiviteit om te zien of deze samenvalt met degradatie van de query. Een indexeerfunctie voert bijvoorbeeld een dagelijkse of uurtaak uit die overeenkomt met de verminderde prestaties van de zoekquery's.
Deze sectie bevat een set query's waarmee u de zoek- en indexeringsfrequenties kunt visualiseren. Voor deze voorbeelden wordt het tijdsbereik ingesteld in de query. Zorg ervoor dat u Instellen in de query aangeeft bij het uitvoeren van de query's in Azure Portal.
Gemiddelde querylatentie
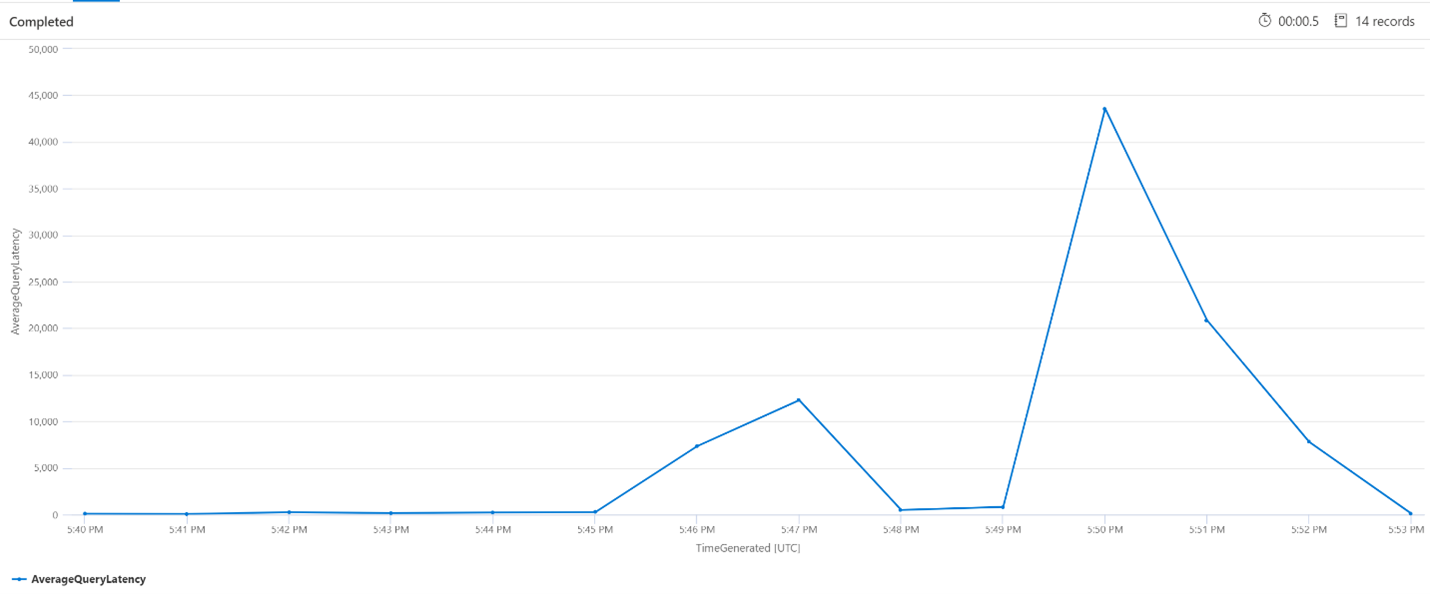
In de onderstaande query wordt een intervalgrootte van 1 minuut gebruikt om de gemiddelde latentie van de zoekquery's weer te geven. In de grafiek zien we dat de gemiddelde latentie tot 17:45 uur laag was en tot 17:53 uur duurde.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
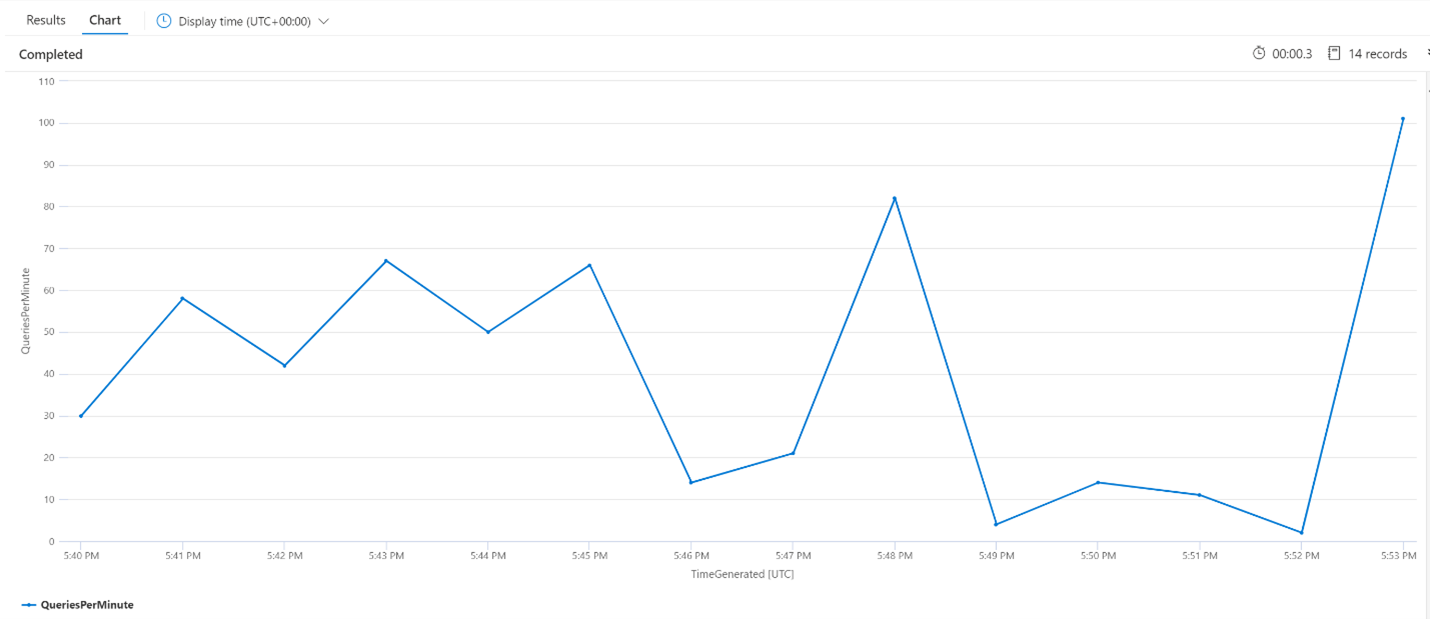
Gemiddelde query's per minuut (QPM)
De volgende query bekijkt het gemiddelde aantal query's per minuut om ervoor te zorgen dat er geen piek in zoekaanvragen is die de latentie mogelijk hebben beïnvloed. In de grafiek kunnen we zien dat er een variantie is, maar niets om een piek in het aantal aanvragen aan te geven.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
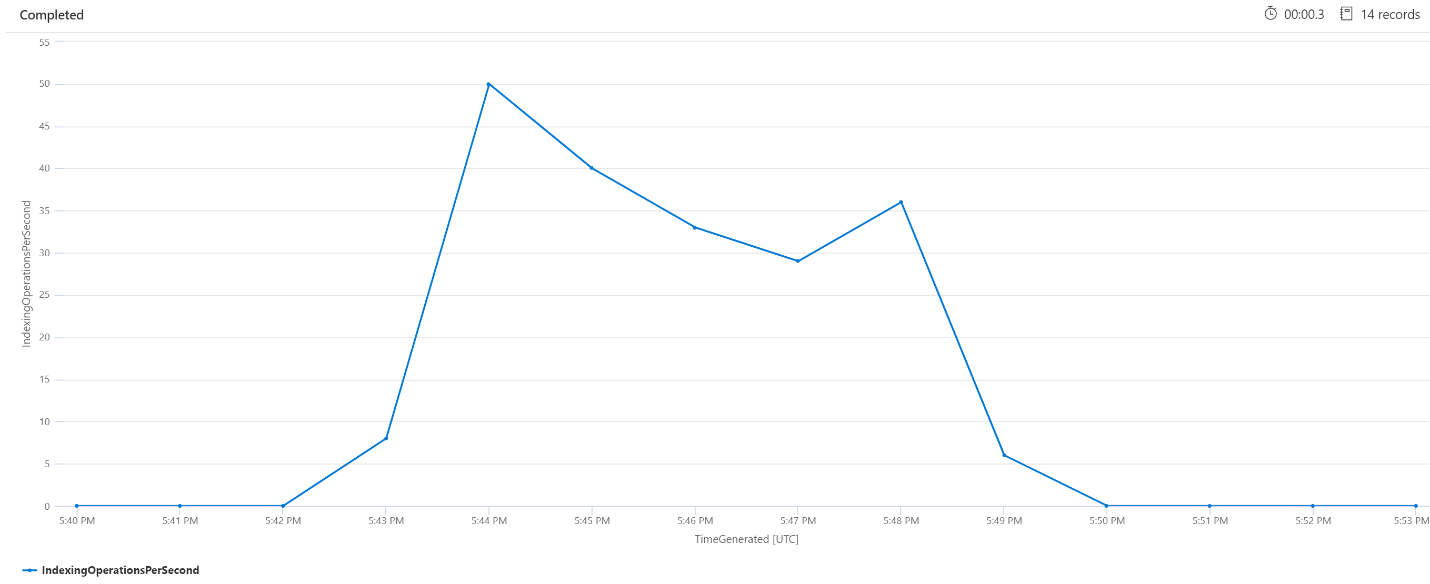
Indexeringsbewerkingen per minuut (OPM)
Hier bekijken we het aantal indexeringsbewerkingen per minuut. In de grafiek zien we dat een grote hoeveelheid gegevens is geïndexeerd om 17:42 uur en om 17:50 is beëindigd. Deze indexering begon 3 minuten voordat de zoekquery's werden latent en eindigde 3 minuten voordat de zoekquery's niet meer latent waren.
Vanuit dit inzicht kunnen we zien dat het ongeveer 3 minuten duurde voordat de zoekservice bezet genoeg was voor indexering om de querylatentie te beïnvloeden. We kunnen ook zien dat na het indexeren nog eens 3 minuten duurde voordat de zoekservice al het werk van de zojuist geïndexeerde inhoud heeft voltooid en dat de querylatentie is opgelost.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Verwerking van achtergrondservice
Het is niet ongebruikelijk om periodieke pieken in query- of indexeringslatentie te zien. Pieken kunnen optreden als reactie op indexering of hoge querysnelheden, maar kunnen ook optreden tijdens samenvoegbewerkingen. Zoekindexen worden opgeslagen in segmenten - of shards. Het systeem voegt regelmatig kleinere shards samen in grote shards, waardoor de serviceprestaties kunnen worden geoptimaliseerd. Met dit samenvoegproces worden ook documenten opgeschoond die eerder zijn gemarkeerd voor verwijdering uit de index, wat resulteert in het herstellen van opslagruimte.
Het samenvoegen van shards is snel, maar ook resourceintensief en heeft dus het potentieel om de serviceprestaties te verminderen. Als u korte bursts van querylatentie ziet en deze bursts overeenkomen met recente wijzigingen in geïndexeerde inhoud, kunt u ervan uitgaan dat de latentie wordt veroorzaakt door shard-samenvoegbewerkingen.
Volgende stappen
Bekijk deze artikelen met betrekking tot het analyseren van serviceprestaties.