Bewaking en diagnose voor Azure Service Fabric
Dit artikel bevat een overzicht van bewaking en diagnose voor Azure Service Fabric. Bewaking en diagnose zijn essentieel voor het ontwikkelen, testen en implementeren van workloads in elke cloudomgeving. U kunt bijvoorbeeld bijhouden hoe uw toepassingen worden gebruikt, de acties die worden uitgevoerd door het Service Fabric-platform, uw resourcegebruik met prestatiemeteritems en de algehele status van uw cluster. U kunt deze informatie gebruiken om problemen vast te stellen en op te lossen en deze in de toekomst te voorkomen. In de volgende secties wordt kort uitgelegd wat elk gebied van Service Fabric-bewaking is om rekening te houden met productieworkloads.
Notitie
Dit artikel is onlangs bijgewerkt waarbij Log Analytics is vervangen door de term Azure Monitor-logboeken. Logboekgegevens worden nog steeds opgeslagen in een Log Analytics-werkruimte, en worden nog steeds verzameld en geanalyseerd met dezelfde Log Analytics-service. De terminologie wordt bijgewerkt om de rol van logboeken in Azure Monitor beter te weerspiegelen. Zie Wijzigingen in Azure Monitor-terminologie voor meer informatie.
Toepassingsbewaking
Toepassingsbewaking houdt bij hoe functies en onderdelen van uw toepassing worden gebruikt. U wilt uw toepassingen controleren om ervoor te zorgen dat er problemen zijn die van invloed zijn op gebruikers. De verantwoordelijkheid van toepassingsbewaking is voor de gebruikers die een toepassing en de bijbehorende services ontwikkelen, omdat deze uniek is voor de bedrijfslogica van uw toepassing. Het bewaken van uw toepassingen kan handig zijn in de volgende scenario's:
- Hoeveel verkeer ondervindt mijn toepassing? - Moet u uw services schalen om te voldoen aan de eisen van gebruikers of om een potentieel knelpunt in uw toepassing aan te pakken?
- Zijn mijn service-naar-service-aanroepen geslaagd en bijgehouden?
- Welke acties worden uitgevoerd door de gebruikers van mijn toepassing? - Het verzamelen van telemetrie kan leiden tot toekomstige functieontwikkeling en betere diagnostische gegevens voor toepassingsfouten
- Werpt mijn toepassing onverwerkte uitzonderingen op?
- Wat gebeurt er in de services die in mijn containers worden uitgevoerd?
Het mooie van toepassingsbewaking is dat ontwikkelaars alle hulpprogramma's en frameworks kunnen gebruiken die ze willen, omdat ze zich in de context van uw toepassing bevinden. Meer informatie over de Azure-oplossing voor toepassingsbewaking met Azure Monitor Application Insights in Gebeurtenisanalyse met Application Insights. We hebben ook een zelfstudie over het instellen hiervan voor .NET-toepassingen. In deze zelfstudie wordt uitgelegd hoe u de juiste hulpprogramma's installeert, een voorbeeld voor het schrijven van aangepaste telemetrie in uw toepassing en het weergeven van de diagnostische gegevens en telemetrie van toepassingen in Azure Portal.
Platformbewaking (cluster)
Een gebruiker heeft controle over welke telemetrie afkomstig is van de toepassing, omdat een gebruiker de code zelf schrijft, maar hoe zit het met de diagnostische gegevens van het Service Fabric-platform? Een van de doelstellingen van Service Fabric is om toepassingen bestand te houden tegen hardwarefouten. Dit doel wordt bereikt door de mogelijkheid van systeemservices van het platform om infrastructuurproblemen en snel failoverworkloads naar andere knooppunten in het cluster te detecteren. Maar in dit specifieke geval, wat als de systeemservices zelf problemen hebben? Of als bij het implementeren of verplaatsen van een workload regels voor de plaatsing van services worden geschonden? Service Fabric biedt diagnostische gegevens voor deze en meer om ervoor te zorgen dat u op de hoogte bent van activiteiten die plaatsvinden in uw cluster. Enkele voorbeeldscenario's voor clusterbewaking zijn:
Service Fabric biedt een uitgebreide set gebeurtenissen uit de doos. Deze Service Fabric-gebeurtenissen kunnen worden geopend via de EventStore of het operationele kanaal (gebeurteniskanaal dat door het platform wordt weergegeven).
Service Fabric-gebeurteniskanalen: in Windows zijn Service Fabric-gebeurtenissen beschikbaar van één ETW-provider met een set relevante
logLevelKeywordFiltersinformatie die wordt gebruikt om te kiezen tussen operationele kanalen en data & messaging-kanalen. Dit is de manier waarop we uitgaande Service Fabric-gebeurtenissen scheiden waarop we waar nodig moeten worden gefilterd. In Linux worden Service Fabric-gebeurtenissen via LTTng geleverd en in één Storage-tabel geplaatst, van waaruit ze naar behoefte kunnen worden gefilterd. Deze kanalen bevatten gecureerde, gestructureerde gebeurtenissen die kunnen worden gebruikt om de status van uw cluster beter te begrijpen. Diagnostische gegevens worden standaard ingeschakeld tijdens het maken van het cluster, waarmee een Azure Storage-tabel wordt gemaakt waarin de gebeurtenissen van deze kanalen in de toekomst naar u worden verzonden om een query uit te voeren.EventStore- De EventStore is een functie die wordt aangeboden door het platform dat Service Fabric-platformgebeurtenissen biedt die beschikbaar zijn in Service Fabric Explorer en via REST API. U ziet een momentopnameweergave van wat er in uw cluster gebeurt voor elke entiteit, zoals knooppunt, service, toepassing en query op basis van het tijdstip van de gebeurtenis. U kunt ook meer lezen over de EventStore in het Overzicht van de EventStore.
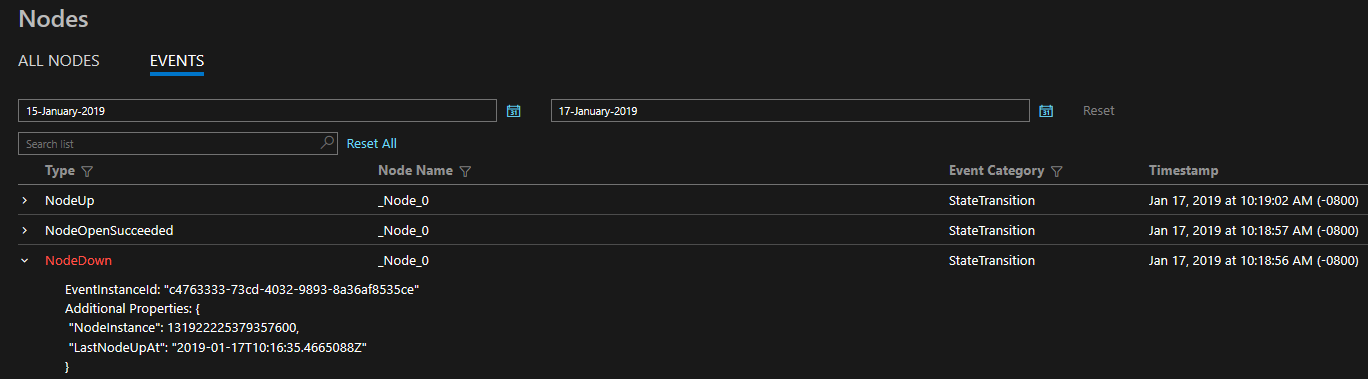
De opgegeven diagnostische gegevens zijn in de vorm van een uitgebreide reeks gebeurtenissen in het vak. Deze Service Fabric-gebeurtenissen illustreren acties die door het platform op verschillende entiteiten worden uitgevoerd, zoals knooppunten, toepassingen, services, partities, enzovoort. In het laatste scenario hierboven, als een knooppunt uitvalt, zou het platform een NodeDown gebeurtenis verzenden en zou u onmiddellijk op de hoogte kunnen worden gesteld door uw controleprogramma van keuze. Andere veelvoorkomende voorbeelden zijn ApplicationUpgradeRollbackStarted of PartitionReconfigured tijdens een failover. Dezelfde gebeurtenissen zijn beschikbaar op zowel Windows- als Linux-clusters.
De gebeurtenissen worden verzonden via standaardkanalen in zowel Windows als Linux en kunnen worden gelezen door elk bewakingsprogramma dat deze ondersteunt. De Azure Monitor-oplossing is Azure Monitor-logboeken. Lees gerust meer over de integratie van Azure Monitor-logboeken, waaronder een aangepast operationeel dashboard voor uw cluster en enkele voorbeeldquery's waaruit u waarschuwingen kunt maken. Er zijn meer concepten voor clusterbewaking beschikbaar op platformniveau voor het genereren van gebeurtenissen en logboeken.
Statuscontrole
Het Service Fabric-platform bevat een statusmodel dat uitbreidbare statusrapportage biedt voor de status van entiteiten in een cluster. Elk knooppunt, elke toepassing, service, partitie, replica of exemplaar heeft een status die continu kan worden bijgewerkt. De status kan 'OK', 'Waarschuwing' of 'Fout' zijn. U kunt Service Fabric-gebeurtenissen beschouwen als werkwoorden die door het cluster worden uitgevoerd naar verschillende entiteiten en status als een bijvoeglijk naamwoord voor elke entiteit. Telkens wanneer de status van een bepaalde entiteit overgaat, wordt er ook een gebeurtenis verzonden. Op deze manier kunt u query's en waarschuwingen instellen voor statusevenementen in uw controleprogramma van uw keuze, net als elke andere gebeurtenis.
Daarnaast laten we gebruikers zelfs de status van entiteiten overschrijven. Als uw toepassing een upgrade uitvoert en er validatietests mislukken, kunt u schrijven naar Service Fabric Health met behulp van de Health-API om aan te geven dat uw toepassing niet meer in orde is en Service Fabric de upgrade automatisch terugdraait. Bekijk de inleiding tot Service Fabric-statuscontrole voor meer informatie over het statusmodel
Waakhonden
Over het algemeen is een watchdog een afzonderlijke service die de status en belasting van services bewaakt, eindpunten pingt en onverwachte status gebeurtenissen in het cluster rapporteert. Dit kan helpen bij het voorkomen van fouten die mogelijk niet alleen worden gedetecteerd op basis van de prestaties van één service. Watchdogs zijn ook een goede plek om code te hosten die herstelacties uitvoert waarvoor geen gebruikersinteractie is vereist, zoals het opschonen van logboekbestanden in de opslag met bepaalde tijdsintervallen. Zie het FabricObserver-project als u een volledig geïmplementeerde open source SF-watchdog-service wilt die een gebruiksvriendelijk uitbreidbaarheidsmodel voor watchdogs bevat en dat wordt uitgevoerd in zowel Windows- als Linux-clusters. FabricObserver is software die gereed is voor productie. We raden u aan FabricObserver te implementeren in uw test- en productieclusters en deze uit te breiden om te voldoen aan uw behoeften via het invoegtoepassingsmodel of door het te forken en uw eigen ingebouwde waarnemers te schrijven. De voormalige (plug-ins) is de aanbevolen aanpak.
Bewaking van infrastructuur (prestaties)
Nu we de diagnostische gegevens in uw toepassing en het platform hebben behandeld, hoe weten we dat de hardware werkt zoals verwacht? Het bewaken van uw onderliggende infrastructuur is een belangrijk onderdeel van het begrijpen van de status van uw cluster en het resourcegebruik. Het meten van systeemprestaties is afhankelijk van veel factoren die subjectief kunnen zijn, afhankelijk van uw workloads. Deze factoren worden doorgaans gemeten via prestatiemeteritems. Deze prestatiemeteritems kunnen afkomstig zijn van verschillende bronnen, waaronder het besturingssysteem, het .NET Framework of het Service Fabric-platform zelf. Sommige scenario's waarin ze nuttig zouden zijn, zijn
- Gebruik ik mijn hardware efficiënt? Wilt u uw hardware gebruiken op 90% CPU of 10% CPU. Dit is handig bij het schalen van uw cluster of het optimaliseren van de processen van uw toepassing.
- Kan ik proactief infrastructuurproblemen voorspellen? - veel problemen worden voorafgegaan door plotselinge wijzigingen (dalingen) in de prestaties, zodat u prestatiemeteritems zoals netwerk-I/O en CPU-gebruik kunt gebruiken om de problemen proactief te voorspellen en diagnosticeren.
Een lijst met prestatiemeteritems die moeten worden verzameld op het niveau van de infrastructuur, vindt u in metrische prestatiegegevens.
Service Fabric biedt ook een set prestatiemeteritems voor de Reliable Services- en Actors-programmeermodellen. Als u een van deze modellen gebruikt, kunnen deze prestatiemeteritems informatie geven om ervoor te zorgen dat uw actoren correct worden ingesteld of dat uw betrouwbare serviceaanvragen snel genoeg worden verwerkt. Zie Monitoring for Reliable Service Remoting and Performance monitoring for Reliable Actors voor meer informatie.
De Azure Monitor-oplossing voor het verzamelen hiervan zijn Azure Monitor-logboeken, net zoals bewaking op platformniveau. U moet de Log Analytics-agent gebruiken om de juiste prestatiemeteritems te verzamelen en weer te geven in Azure Monitor-logboeken.
Aanbevolen installatie
Nu we elk gebied van bewaking en voorbeeldscenario's hebben doorlopen, vindt u hier een overzicht van de Azure-bewakingshulpprogramma's en hebt u deze nodig om alle bovenstaande gebieden te bewaken.
- Toepassingsbewaking met Application Insights
- Clusterbewaking met diagnostische agent en Azure Monitor-logboeken
- Infrastructuurbewaking met Azure Monitor-logboeken
U kunt ook de ARM-voorbeeldsjabloon hier gebruiken en wijzigen om de implementatie van alle benodigde resources en agents te automatiseren.
Andere oplossingen voor logboekregistratie
Hoewel de twee oplossingen die we hebben aanbevolen, hebben Azure Monitor-logboeken en Application Insights ingebouwde integratie met Service Fabric, worden veel gebeurtenissen geschreven via ETW-providers en kunnen ze worden uitgebreid met andere logboekoplossingen. U moet ook kijken naar de Elastic Stack (met name als u een cluster in een offlineomgeving wilt uitvoeren), Dynatrace of een ander platform van uw voorkeur. We hebben hier een lijst met geïntegreerde partners.
De belangrijkste punten voor elk platform dat u kiest, moeten omvatten hoe comfortabel u bent met de gebruikersinterface, de querymogelijkheden, de beschikbare aangepaste visualisaties en dashboards en de extra hulpprogramma's die ze bieden om uw bewakingservaring te verbeteren.
Volgende stappen
- Zie Gebeurtenis- en logboekgeneratie op toepassingsniveau om aan de slag te gaan met het instrumenteren van uw toepassingen.
- Doorloop de stappen voor het instellen van Application Insights voor uw toepassing met Monitor en diagnose van een ASP.NET Core-toepassing in Service Fabric.
- Meer informatie over het bewaken van het platform en de gebeurtenissen die Service Fabric biedt op platformniveau voor het genereren van gebeurtenissen en logboeken.
- De integratie van Azure Monitor-logboeken configureren met Service Fabric bij Het instellen van Azure Monitor-logboeken voor een cluster
- Meer informatie over het instellen van Azure Monitor-logboeken voor het bewaken van containers: bewaking en diagnose voor Windows-containers in Azure Service Fabric.
- Zie voorbeeld van diagnostische problemen en oplossingen met Service Fabric bij het diagnosticeren van veelvoorkomende scenario's
- Bekijk andere diagnostische producten die zijn geïntegreerd met Service Fabric in diagnostische Partners van Service Fabric
- Meer informatie over algemene controleaanbeveling voor Azure-resources - Aanbevolen procedures - Bewaking en diagnose.