Gegevens kopiëren en transformeren in Azure SQL Database met behulp van Azure Data Factory of Azure Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u kopieeractiviteit gebruikt in Azure Data Factory- of Azure Synapse-pijplijnen om gegevens van en naar Azure SQL Database te kopiëren en Gegevensstroom gebruiken om gegevens in Azure SQL Database te transformeren. Lees het inleidende artikel voor Azure Data Factory of Azure Synapse Analytics voor meer informatie.
Ondersteunde mogelijkheden
Deze Azure SQL Database-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR | Beheerd privé-eindpunt |
|---|---|---|
| Copy-activiteit (bron/sink) | (1) (2) | ✓ |
| Toewijzingsgegevensstroom (bron/sink) | (1) | ✓ |
| Activiteit Lookup | (1) (2) | ✓ |
| GetMetadata-activiteit | (1) (2) | ✓ |
| Scriptactiviteit | (1) (2) | ✓ |
| Opgeslagen procedureactiviteit | (1) (2) | ✓ |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Voor Copy-activiteit ondersteunt deze Azure SQL Database-connector deze functies:
- Gegevens kopiëren met behulp van SQL-verificatie en Microsoft Entra Application-tokenverificatie met een service-principal of beheerde identiteiten voor Azure-resources.
- Als bron kunt u gegevens ophalen met behulp van een SQL-query of een opgeslagen procedure. U kunt er ook voor kiezen om parallel te kopiëren vanuit een Azure SQL Database-bron. Zie de sectie Parallel kopiëren uit de SQL-database voor meer informatie.
- Als sink maakt u automatisch een doeltabel als deze niet bestaat op basis van het bronschema; gegevens toevoegen aan een tabel of een opgeslagen procedure aanroepen met aangepaste logica tijdens het kopiëren.
Als u de serverloze laag van Azure SQL Database gebruikt, moet u er rekening mee houden dat wanneer de server is onderbroken, de uitvoering van de activiteit mislukt in plaats van te wachten totdat het automatisch hervatten gereed is. U kunt activiteiten opnieuw proberen of aanvullende activiteiten koppelen om ervoor te zorgen dat de server live is bij de werkelijke uitvoering.
Belangrijk
Als u gegevens kopieert met behulp van de Azure Integration Runtime, configureert u een firewallregel op serverniveau, zodat Azure-services toegang hebben tot de server. Als u gegevens kopieert met behulp van een zelf-hostende Integration Runtime, configureert u de firewall om het juiste IP-bereik toe te staan. Dit bereik omvat het IP-adres van de machine dat wordt gebruikt om verbinding te maken met Azure SQL Database.
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde Azure SQL Database-service maken met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde Azure SQL Database-service te maken in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar SQL en selecteer de Azure SQL Database-connector.

Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.

Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen die worden gebruikt om Azure Data Factory- of Synapse-pijplijnentiteiten te definiëren die specifiek zijn voor een Azure SQL Database-connector.
Eigenschappen van gekoppelde service
De aanbevolen versie van de Azure SQL Database-connector ondersteunt TLS 1.3. Raadpleeg deze sectie om de versie van uw Azure SQL Database-connector te upgraden van verouderde versie. Zie de bijbehorende secties voor de details van de eigenschap.
Tip
Als u een fout krijgt met de foutcode UserErrorFailedToConnectToSqlServer en een bericht zoals 'De sessielimiet voor de database is XXX en is bereikt', voegt u toe Pooling=false aan uw verbindingsreeks en probeert u het opnieuw. Pooling=false wordt ook aanbevolen voor het instellen van de gekoppelde service van het type SHIR(Self Hosted Integration Runtime ). Pooling en andere verbindingsparameters kunnen worden toegevoegd als nieuwe parameternamen en -waarden in het gedeelte Aanvullende verbindingseigenschappen van het formulier voor het maken van gekoppelde services.
Aanbevolen versie
Deze algemene eigenschappen worden ondersteund voor een gekoppelde Azure SQL Database-service wanneer u de aanbevolen versie toepast:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap moet worden ingesteld op AzureSqlDatabase. | Ja |
| server | De naam of het netwerkadres van het SQL Server-exemplaar waarmee u verbinding wilt maken. | Ja |
| database | De naam van de database. | Ja |
| authenticationType | Het type dat wordt gebruikt voor verificatie. Toegestane waarden zijn SQL (standaard), ServicePrincipal, SystemAssignedManagedIdentity, UserAssignedManagedIdentity. Ga naar de relevante verificatiesectie over specifieke eigenschappen en vereisten. | Ja |
| alwaysEncryptedSettings | Geef alwaysencryptedsettings-informatie op die nodig is om Always Encrypted in te schakelen voor het beveiligen van gevoelige gegevens die zijn opgeslagen in SQL Server met behulp van een beheerde identiteit of service-principal. Zie het JSON-voorbeeld na de tabel en de sectie Always Encrypted gebruiken voor meer informatie. Als dit niet is opgegeven, wordt de standaardinstelling altijd versleuteld uitgeschakeld. | Nee |
| encryptie | Geef aan of TLS-versleuteling is vereist voor alle gegevens die worden verzonden tussen de client en de server. Opties: verplicht (voor waar, standaard)/optioneel (voor onwaar)/strikt. | Nee |
| trustServerCertificate | Geef aan of het kanaal wordt versleuteld tijdens het omzeilen van de certificaatketen om de vertrouwensrelatie te valideren. | Nee |
| hostNameInCertificate | De hostnaam die moet worden gebruikt bij het valideren van het servercertificaat voor de verbinding. Wanneer deze niet is opgegeven, wordt de servernaam gebruikt voor certificaatvalidatie. | Nee |
| connectVia | Deze integratieruntime wordt gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Zie de onderstaande tabel voor aanvullende verbindingseigenschappen:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| applicationIntent | Het workloadtype van de toepassing bij het maken van verbinding met een server. Toegestane waarden zijn ReadOnly en ReadWrite. |
Nee |
| connectTimeout | De tijdsduur (in seconden) om te wachten op een verbinding met de server voordat de poging wordt beëindigd en er een fout wordt gegenereerd. | Nee |
| connectRetryCount | Het aantal nieuwe verbindingen dat is geprobeerd na het identificeren van een niet-actieve verbindingsfout. De waarde moet een geheel getal tussen 0 en 255 zijn. | Nee |
| connectRetryInterval | De hoeveelheid tijd (in seconden) tussen elke poging om opnieuw verbinding te maken na het identificeren van een niet-actieve verbindingsfout. De waarde moet een geheel getal tussen 1 en 60 zijn. | Nee |
| loadBalanceTimeout | De minimale tijd (in seconden) voordat de verbinding live in de verbindingsgroep wordt uitgevoerd voordat de verbinding wordt vernietigd. | Nee |
| commandTimeout | De standaardwachttijd (in seconden) voordat de poging om een opdracht uit te voeren eindigt en een fout genereert. | Nee |
| integratedSecurity | De toegestane waarden zijn true of false. Geef bij het opgeven falseaan of gebruikersnaam en wachtwoord zijn opgegeven in de verbinding. Wanneer u opgeeft true, geeft u aan of de referenties van het huidige Windows-account worden gebruikt voor verificatie. |
Nee |
| failoverPartner | De naam of het adres van de partnerserver waarmee verbinding moet worden gemaakt als de primaire server niet beschikbaar is. | Nee |
| maxPoolSize | Het maximum aantal verbindingen dat is toegestaan in de verbindingsgroep voor de specifieke verbinding. | Nee |
| minPoolSize | Het minimale aantal verbindingen dat is toegestaan in de verbindingsgroep voor de specifieke verbinding. | Nee |
| multipleActiveResultSets | De toegestane waarden zijn true of false. Wanneer u opgeeft true, kan een toepassing meerdere actieve resultatensets (MARS) onderhouden. Wanneer u opgeeft false, moet een toepassing alle resultatensets van de ene batch verwerken of annuleren voordat deze andere batches op die verbinding kan uitvoeren. |
Nee |
| multiSubnetFailover | De toegestane waarden zijn true of false. Als uw toepassing verbinding maakt met een AlwaysOn-beschikbaarheidsgroep (AG) op verschillende subnetten, stelt u deze eigenschap in om true sneller te detecteren en verbinding te maken met de momenteel actieve server. |
Nee |
| packetSize | De grootte in bytes van de netwerkpakketten die worden gebruikt om te communiceren met een exemplaar van de server. | Nee |
| Bundeling | De toegestane waarden zijn true of false. Wanneer u opgeeft true, wordt de verbinding gegroepeerd. Wanneer u opgeeft false, wordt de verbinding expliciet geopend telkens wanneer de verbinding wordt aangevraagd. |
Nee |
SQL-verificatie
Als u SQL-verificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| gebruikersnaam | De gebruikersnaam die wordt gebruikt om verbinding te maken met de server. | Ja |
| password | Het wachtwoord voor de gebruikersnaam. Markeer dit veld als SecureString om het veilig op te slaan. U kunt ook verwijzen naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
Voorbeeld: SQL-verificatie gebruiken
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld: wachtwoord in Azure Key Vault
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld: Always Encrypted gebruiken
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verificatie van service-principal
Als u service-principalverificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| servicePrincipalId | Geef de client-id van de toepassing op. | Ja |
| servicePrincipalCredential | De referenties van de service-principal. Geef de sleutel van de toepassing op. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
| tenant | Geef de tenantgegevens op, zoals de domeinnaam of tenant-id, waaronder uw toepassing zich bevindt. Haal deze op door de muis in de rechterbovenhoek van Azure Portal te bewegen. | Ja |
| azureCloudType | Geef voor service-principalverificatie het type Azure-cloudomgeving op waarnaar uw Microsoft Entra-toepassing is geregistreerd. Toegestane waarden zijn AzurePublic, AzureChina, AzureUsGovernment en AzureGermany. Standaard wordt de cloudomgeving van de data factory of Synapse-pijplijn gebruikt. |
Nee |
U moet ook de onderstaande stappen volgen:
Maak een Microsoft Entra-toepassing vanuit Azure Portal. Noteer de naam van de toepassing en de volgende waarden die de gekoppelde service definiëren:
- Toepassings-id
- Toepassingssleutel
- Tenant-id
Richt een Microsoft Entra-beheerder in voor uw server in Azure Portal als u dit nog niet hebt gedaan. De Microsoft Entra-beheerder moet een Microsoft Entra-gebruiker of Microsoft Entra-groep zijn, maar kan geen service-principal zijn. Deze stap wordt uitgevoerd, zodat u in de volgende stap een Microsoft Entra-identiteit kunt gebruiken om een ingesloten databasegebruiker voor de service-principal te maken.
Maak ingesloten databasegebruikers voor de service-principal. Maak verbinding met de database van of waarmee u gegevens wilt kopiëren met behulp van hulpprogramma's zoals SQL Server Management Studio, met een Microsoft Entra-identiteit met ten minste ALTER ANY USER-machtigingen. Voer de volgende T-SQL uit:
CREATE USER [your application name] FROM EXTERNAL PROVIDER;Verdeel de benodigde machtigingen voor de service-principal zoals u normaal gesproken doet voor SQL-gebruikers of anderen. Voer de volgende code uit. Zie dit document voor meer opties.
ALTER ROLE [role name] ADD MEMBER [your application name];Configureer een gekoppelde Azure SQL Database-service in een Azure Data Factory- of Synapse-werkruimte.
Voorbeeld van een gekoppelde service die gebruikmaakt van verificatie van de service-principal
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"hostNameInCertificate": "<host name>",
"authenticationType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Door het systeem toegewezen beheerde identiteitverificatie
Een data factory of Synapse-werkruimte kan worden gekoppeld aan een door het systeem toegewezen beheerde identiteit voor Azure-resources die de service vertegenwoordigt bij verificatie bij andere resources in Azure. U kunt deze beheerde identiteit gebruiken voor Azure SQL Database-verificatie. De aangewezen factory of Synapse-werkruimte kan met behulp van deze identiteit gegevens openen en kopiëren van of naar uw database.
Als u door het systeem toegewezen beheerde identiteitverificatie wilt gebruiken, geeft u de algemene eigenschappen op die in de vorige sectie worden beschreven en volgt u deze stappen.
Richt een Microsoft Entra-beheerder in voor uw server in Azure Portal als u dit nog niet hebt gedaan. De Microsoft Entra-beheerder kan een Microsoft Entra-gebruiker of een Microsoft Entra-groep zijn. Als u de groep met een beheerde identiteit een beheerdersrol verleent, slaat u stap 3 en 4 over. De beheerder heeft volledige toegang tot de database.
Maak ingesloten databasegebruikers voor de beheerde identiteit. Maak verbinding met de database van of waarmee u gegevens wilt kopiëren met behulp van hulpprogramma's zoals SQL Server Management Studio, met een Microsoft Entra-identiteit met ten minste ALTER ANY USER-machtigingen. Voer de volgende T-SQL uit:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Verdeel de beheerde identiteit machtigingen zoals u normaal gesproken doet voor SQL-gebruikers en anderen. Voer de volgende code uit. Zie dit document voor meer opties.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Configureer een gekoppelde Azure SQL Database-service.
Voorbeeld
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Door de gebruiker toegewezen beheerde identiteitverificatie
Een data factory of Synapse-werkruimte kan worden gekoppeld aan een door de gebruiker toegewezen beheerde identiteiten die de service vertegenwoordigen bij het verifiëren van andere resources in Azure. U kunt deze beheerde identiteit gebruiken voor Azure SQL Database-verificatie. De aangewezen factory of Synapse-werkruimte kan met behulp van deze identiteit gegevens openen en kopiëren van of naar uw database.
Als u door de gebruiker toegewezen beheerde identiteitverificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| aanmeldingsgegevens | Geef de door de gebruiker toegewezen beheerde identiteit op als referentieobject. | Ja |
U moet ook de onderstaande stappen volgen:
Richt een Microsoft Entra-beheerder in voor uw server in Azure Portal als u dit nog niet hebt gedaan. De Microsoft Entra-beheerder kan een Microsoft Entra-gebruiker of een Microsoft Entra-groep zijn. Als u de groep met een door de gebruiker toegewezen beheerde identiteit een beheerdersrol verleent, slaat u stap 3 over. De beheerder heeft volledige toegang tot de database.
Maak ingesloten databasegebruikers voor de door de gebruiker toegewezen beheerde identiteit. Maak verbinding met de database van of waarmee u gegevens wilt kopiëren met behulp van hulpprogramma's zoals SQL Server Management Studio, met een Microsoft Entra-identiteit met ten minste ALTER ANY USER-machtigingen. Voer de volgende T-SQL uit:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Maak een of meerdere door de gebruiker toegewezen beheerde identiteiten en ververleent de door de gebruiker toegewezen beheerde identiteit machtigingen zoals u normaal gesproken doet voor SQL-gebruikers en anderen. Voer de volgende code uit. Zie dit document voor meer opties.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Wijs een of meerdere door de gebruiker toegewezen beheerde identiteiten toe aan uw data factory en maak referenties voor elke door de gebruiker toegewezen beheerde identiteit.
Configureer een gekoppelde Azure SQL Database-service.
Voorbeeld
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Verouderde versie
Deze algemene eigenschappen worden ondersteund voor een gekoppelde Azure SQL Database-service wanneer u een verouderde versie toepast:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap moet worden ingesteld op AzureSqlDatabase. | Ja |
| connectionString | Geef informatie op die nodig is om verbinding te maken met het Azure SQL Database-exemplaar voor de eigenschap connectionString . U kunt ook een wachtwoord of service-principalsleutel in Azure Key Vault plaatsen. Als het SQL-verificatie is, haalt u de password configuratie uit de verbindingsreeks. Zie Referenties opslaan in Azure Key Vault voor meer informatie. |
Ja |
| alwaysEncryptedSettings | Geef alwaysencryptedsettings-informatie op die nodig is om Always Encrypted in te schakelen voor het beveiligen van gevoelige gegevens die zijn opgeslagen in SQL Server met behulp van een beheerde identiteit of service-principal. Zie de sectie Always Encrypted gebruiken voor meer informatie. Als dit niet is opgegeven, wordt de standaardinstelling altijd versleuteld uitgeschakeld. | Nee |
| connectVia | Deze integratieruntime wordt gebruikt om verbinding te maken met het gegevensarchief. U kunt de Azure Integration Runtime of een zelf-hostende Integration Runtime gebruiken als uw gegevensarchief zich in een particulier netwerk bevindt. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Raadpleeg voor verschillende verificatietypen respectievelijk de volgende secties over specifieke eigenschappen en vereisten:
- SQL-verificatie voor de verouderde versie
- Verificatie van de service-principal voor de verouderde versie
- Door het systeem toegewezen beheerde identiteitverificatie voor de verouderde versie
- Door de gebruiker toegewezen beheerde identiteitverificatie voor de verouderde versie
SQL-verificatie voor de verouderde versie
Als u SQL-verificatie wilt gebruiken, geeft u de algemene eigenschappen op die in de vorige sectie worden beschreven.
Verificatie van de service-principal voor de verouderde versie
Als u service-principalverificatie wilt gebruiken, geeft u naast de algemene eigenschappen die in de vorige sectie worden beschreven, de volgende eigenschappen op:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| servicePrincipalId | Geef de client-id van de toepassing op. | Ja |
| servicePrincipalKey | Geef de sleutel van de toepassing op. Markeer dit veld als SecureString om het veilig op te slaan of om te verwijzen naar een geheim dat is opgeslagen in Azure Key Vault. | Ja |
| tenant | Geef de tenantgegevens op, zoals de domeinnaam of tenant-id, waaronder uw toepassing zich bevindt. Haal deze op door de muis in de rechterbovenhoek van Azure Portal te bewegen. | Ja |
| azureCloudType | Geef voor service-principalverificatie het type Azure-cloudomgeving op waarnaar uw Microsoft Entra-toepassing is geregistreerd. Toegestane waarden zijn AzurePublic, AzureChina, AzureUsGovernment en AzureGermany. Standaard wordt de cloudomgeving van de data factory of Synapse-pijplijn gebruikt. |
Nee |
U moet ook de stappen in service-principalverificatie volgen om de bijbehorende machtiging te verlenen.
Door het systeem toegewezen beheerde identiteitverificatie voor de verouderde versie
Als u door het systeem toegewezen beheerde identiteitverificatie wilt gebruiken, volgt u dezelfde stap voor de aanbevolen versie in door het systeem toegewezen beheerde identiteitverificatie.
Door de gebruiker toegewezen beheerde identiteitverificatie voor verouderde versie
Als u door de gebruiker toegewezen beheerde identiteitverificatie wilt gebruiken, volgt u dezelfde stap voor de aanbevolen versie in door de gebruiker toegewezen beheerde identiteitverificatie.
Eigenschappen van gegevensset
Zie Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets.
De volgende eigenschappen worden ondersteund voor azure SQL Database-gegevensset:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op AzureSqlTable. | Ja |
| schema | Naam van het schema. | Nee voor bron, Ja voor sink |
| table | Naam van de tabel/weergave. | Nee voor bron, Ja voor sink |
| tableName | Naam van de tabel/weergave met schema. Deze eigenschap wordt ondersteund voor compatibiliteit met eerdere versies. Voor nieuwe workload gebruikt schema u en table. |
Nee voor bron, Ja voor sink |
Voorbeeld van gegevensseteigenschappen
{
"name": "AzureSQLDbDataset",
"properties":
{
"type": "AzureSqlTable",
"linkedServiceName": {
"referenceName": "<Azure SQL Database linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Azure SQL Database-bron en -sink.
Azure SQL Database als bron
Tip
Als u gegevens efficiënt vanuit Azure SQL Database wilt laden met behulp van gegevenspartitionering, vindt u meer informatie over parallelle kopie vanuit SQL Database.
Als u gegevens uit Azure SQL Database wilt kopiëren, worden de volgende eigenschappen ondersteund in de sectie kopieeractiviteitsbron:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op AzureSqlSource. Het type SqlSource wordt nog steeds ondersteund voor achterwaartse compatibiliteit. | Ja |
| sqlReaderQuery | Deze eigenschap maakt gebruik van de aangepaste SQL-query om gegevens te lezen. Een voorbeeld is select * from MyTable. |
Nee |
| sqlReaderStoredProcedureName | De naam van de opgeslagen procedure waarmee gegevens uit de brontabel worden gelezen. De laatste SQL-instructie moet een SELECT-instructie zijn in de opgeslagen procedure. | Nee |
| storedProcedureParameters | Parameters voor de opgeslagen procedure. Toegestane waarden zijn naam- of waardeparen. De namen en hoofdletters van parameters moeten overeenkomen met de namen en hoofdletters van de opgeslagen procedureparameters. |
Nee |
| isolationLevel | Hiermee geeft u het gedrag voor transactievergrendeling voor de SQL-bron op. De toegestane waarden zijn: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Als dit niet is opgegeven, wordt het standaardisolatieniveau van de database gebruikt. Raadpleeg dit document voor meer informatie. | Nee |
| partitionOptions | Hiermee geeft u de opties voor gegevenspartitionering op die worden gebruikt voor het laden van gegevens uit Azure SQL Database. Toegestane waarden zijn: Geen (standaard), PhysicalPartitionsOfTable en DynamicRange. Wanneer een partitieoptie is ingeschakeld (dat wil niet None), wordt de mate van parallelle uitvoering om gegevens uit een Azure SQL Database gelijktijdig te laden, bepaald door de parallelCopies instelling voor de kopieeractiviteit. |
Nee |
| partitionSettings | Geef de groep van de instellingen voor gegevenspartitionering op. Toepassen wanneer de partitieoptie niet Noneis. |
Nee |
Onder partitionSettings: |
||
| partitionColumnName | Geef de naam op van de bronkolom in geheel getal of datum/datum/tijd -type (int, smallint, bigintdate, smalldatetime, , datetimeof datetime2datetimeoffset) dat wordt gebruikt door bereikpartitionering voor parallelle kopie. Als dit niet is opgegeven, wordt de index of de primaire sleutel van de tabel automatisch gedetecteerd en gebruikt als de partitiekolom.Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?DfDynamicRangePartitionCondition aan de WHERE-component. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
| partitionUpperBound | De maximumwaarde van de partitiekolom voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-onderdrukking te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Toepassen wanneer de partitieoptie is DynamicRange. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
| partitionLowerBound | De minimale waarde van de partitiekolom voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-onderdrukking te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Toepassen wanneer de partitieoptie is DynamicRange. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
Houd rekening met de volgende punten:
- Als sqlReaderQuery is opgegeven voor AzureSqlSource, voert de kopieeractiviteit deze query uit op de Azure SQL Database-bron om de gegevens op te halen. U kunt ook een opgeslagen procedure opgeven door sqlReaderStoredProcedureName en storedProcedureParameters op te geven als de opgeslagen procedure parameters gebruikt.
- Wanneer u opgeslagen procedure in de bron gebruikt om gegevens op te halen, moet u er rekening mee houden dat uw opgeslagen procedure is ontworpen als het retourneren van een ander schema wanneer een andere parameterwaarde wordt doorgegeven, mogelijk een fout optreedt of onverwacht resultaat ziet bij het importeren van het schema uit de gebruikersinterface of bij het kopiëren van gegevens naar sql-database met automatisch maken van tabellen.
Voorbeeld van SQL-query
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Voorbeeld van een opgeslagen procedure
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definitie van opgeslagen procedure
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure SQL Database als sink
Tip
Meer informatie over het ondersteunde schrijfgedrag, configuraties en best practices van best practice voor het laden van gegevens in Azure SQL Database.
Als u gegevens naar Azure SQL Database wilt kopiëren, worden de volgende eigenschappen ondersteund in de sectie sink voor kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de sink van de kopieeractiviteit moet worden ingesteld op AzureSqlSink. Het type SqlSink wordt nog steeds ondersteund voor achterwaartse compatibiliteit. | Ja |
| preCopyScript | Geef een SQL-query op voor de kopieeractiviteit die moet worden uitgevoerd voordat u gegevens naar Azure SQL Database schrijft. Het wordt slechts één keer per kopieerbewerking aangeroepen. Gebruik deze eigenschap om de vooraf geladen gegevens op te schonen. | Nee |
| tableOption | Hiermee geeft u op of de sinktabel automatisch moet worden gemaakt als deze niet bestaat op basis van het bronschema. Automatisch tabel maken wordt niet ondersteund wanneer sink opgeslagen procedure opgeeft. Toegestane waarden zijn: none (standaard), autoCreate. |
Nee |
| sqlWriterStoredProcedureName | De naam van de opgeslagen procedure waarmee wordt gedefinieerd hoe brongegevens in een doeltabel moeten worden toegepast. Deze opgeslagen procedure wordt per batch aangeroepen. Gebruik de preCopyScript eigenschap voor bewerkingen die slechts eenmaal worden uitgevoerd en die niets te maken hebben met brongegevens, bijvoorbeeld verwijderen of afkappen.Zie het voorbeeld van Een opgeslagen procedure aanroepen vanuit een SQL-sink. |
Nee |
| storedProcedureTableTypeParameterName | De parameternaam van het tabeltype dat is opgegeven in de opgeslagen procedure. | Nee |
| sqlWriterTableType | De naam van het tabeltype dat moet worden gebruikt in de opgeslagen procedure. De kopieeractiviteit maakt de gegevens die worden verplaatst in een tijdelijke tabel beschikbaar met dit tabeltype. Opgeslagen procedurecode kan vervolgens de gegevens samenvoegen die worden gekopieerd met bestaande gegevens. | Nee |
| storedProcedureParameters | Parameters voor de opgeslagen procedure. Toegestane waarden zijn naam- en waardeparen. Namen en hoofdletters van parameters moeten overeenkomen met de namen en hoofdletters van de opgeslagen procedureparameters. |
Nee |
| writeBatchSize | Aantal rijen dat moet worden ingevoegd in de SQL-tabel per batch. De toegestane waarde is een geheel getal (aantal rijen). Standaard bepaalt de service dynamisch de juiste batchgrootte op basis van de rijgrootte. |
Nee |
| writeBatchTimeout | De wachttijd voor de invoegbewerking, upsert en opgeslagen procedure die moet worden voltooid voordat er een time-out optreedt. Toegestane waarden zijn voor de periode. Een voorbeeld is '00:30:00' gedurende 30 minuten. Als er geen waarde is opgegeven, wordt de time-out standaard ingesteld op '00:30:00'. |
Nee |
| disableMetricsCollection | De service verzamelt metrische gegevens, zoals DTU's van Azure SQL Database voor optimalisatie van kopieerprestaties en aanbevelingen, waarmee extra toegang tot hoofddatabases wordt geïntroduceerd. Als u zich zorgen maakt over dit gedrag, geeft u true op om dit uit te schakelen. |
Nee (standaard is false) |
| maxConcurrentConnections | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | Nee |
| WriteBehavior | Geef het schrijfgedrag op voor kopieeractiviteit om gegevens in Azure SQL Database te laden. De toegestane waarde is Invoegen en Upsert. De service maakt standaard gebruik van Insert om gegevens te laden. |
Nee |
| upsertSettings | Geef de groep van de instellingen voor schrijfgedrag op. Toepassen wanneer de optie WriteBehavior is Upsert. |
Nee |
Onder upsertSettings: |
||
| useTempDB | Geef op of de globale tijdelijke tabel of fysieke tabel moet worden gebruikt als de tussentijdse tabel voor upsert. De service maakt standaard gebruik van een globale tijdelijke tabel als tussentijdse tabel. waarde is true. |
Nee |
| interimSchemaName | Geef het tussentijdse schema op voor het maken van een tussentijdse tabel als de fysieke tabel wordt gebruikt. Opmerking: de gebruiker moet over de machtiging beschikken voor het maken en verwijderen van een tabel. De tussentijdse tabel deelt standaard hetzelfde schema als de sinktabel. Toepassen wanneer de optie useTempDB is False. |
Nee |
| keys | Geef de kolomnamen op voor unieke rijidentificatie. U kunt één sleutel of een reeks sleutels gebruiken. Als deze niet is opgegeven, wordt de primaire sleutel gebruikt. | Nee |
Voorbeeld 1: Gegevens toevoegen
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Voorbeeld 2: Een opgeslagen procedure aanroepen tijdens het kopiëren
Meer informatie over het aanroepen van een opgeslagen procedure vanuit een SQL-sink.
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Voorbeeld 3: Upsert-gegevens
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Parallel kopiëren uit SQL-database
De Azure SQL Database-connector in kopieeractiviteit biedt ingebouwde gegevenspartitionering om gegevens parallel te kopiëren. U vindt opties voor gegevenspartitionering op het tabblad Bron van de kopieeractiviteit.
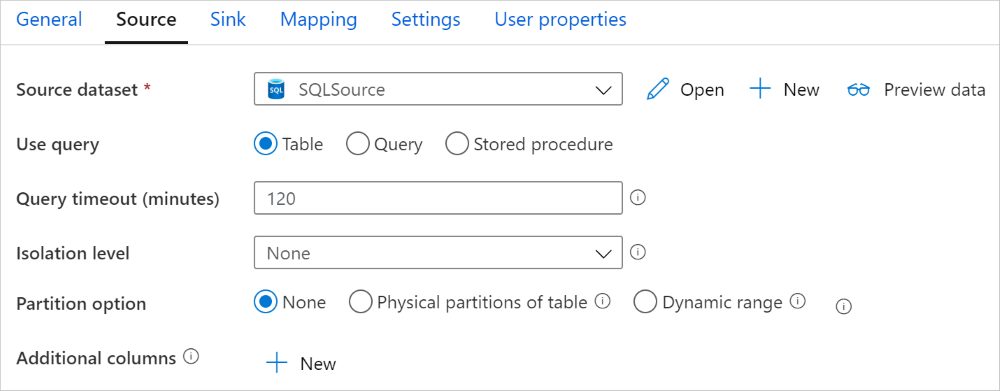
Wanneer u gepartitioneerde kopie inschakelt, voert de kopieeractiviteit parallelle query's uit op uw Azure SQL Database-bron om gegevens te laden op partities. De parallelle graad wordt bepaald door de parallelCopies instelling voor de kopieeractiviteit. Als u bijvoorbeeld instelt op parallelCopies vier, genereert de service gelijktijdig vier query's en voert deze uit op basis van de opgegeven partitieoptie en -instellingen en haalt elke query een deel van de gegevens op uit uw Azure SQL Database.
U wordt aangeraden parallelle kopie met gegevenspartitionering in te schakelen, met name wanneer u grote hoeveelheden gegevens uit uw Azure SQL Database laadt. Hier volgen voorgestelde configuraties voor verschillende scenario's. Wanneer u gegevens kopieert naar een bestandsgegevensarchief, is het raadzaam om naar een map te schrijven als meerdere bestanden (alleen mapnaam opgeven), in welk geval de prestaties beter zijn dan schrijven naar één bestand.
| Scenario | Voorgestelde instellingen |
|---|---|
| Volledige belasting van grote tabellen, met fysieke partities. | Partitieoptie: fysieke partities van de tabel. Tijdens de uitvoering detecteert de service automatisch de fysieke partities en kopieert de gegevens per partitie. Als u wilt controleren of uw tabel een fysieke partitie heeft of niet, kunt u naar deze query verwijzen. |
| Volledige belasting van grote tabellen, zonder fysieke partities, terwijl met een geheel getal of datum/tijd-kolom voor gegevenspartitionering. | Partitieopties: partitie dynamisch bereik. Partitiekolom (optioneel): Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Als deze niet is opgegeven, wordt de index- of primaire-sleutelkolom gebruikt. Bovengrens en partitieondergrens partitioneren (optioneel): Geef op of u de partitie-onderdrukking wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel, alle rijen in de tabel worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, worden de waarden automatisch gedetecteerd door de kopieeractiviteit. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, met parallelle kopie als 4, haalt de service gegevens op met 4 partities - id's in bereik <=20, [21, 50], [51, 80] en >=81. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query, zonder fysieke partities, terwijl u een geheel getal of een datum/datum/tijd-kolom gebruikt voor gegevenspartitionering. | Partitieopties: partitie dynamisch bereik. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitiekolom: Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Bovengrens en partitieondergrens partitioneren (optioneel): Geef op of u de partitie-onderdrukking wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel, alle rijen in het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, waarbij de parallelle kopie als 4 is, haalt de service gegevens op met 4 partities- id's in het bereik <=20, [21, 50], [51, 80] en >=81. Hier volgen meer voorbeeldquery's voor verschillende scenario's: 1. Voer een query uit op de hele tabel: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Query's uitvoeren uit een tabel met kolomselectie en aanvullende where-componentfilters: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Query uitvoeren met subquery's: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Query uitvoeren met partitie in subquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Aanbevolen procedures voor het laden van gegevens met partitieoptie:
- Kies een onderscheidende kolom als partitiekolom (zoals primaire sleutel of unieke sleutel) om scheeftrekken van gegevens te voorkomen.
- Als de tabel een ingebouwde partitie heeft, gebruikt u de partitieoptie Fysieke partities van de tabel om betere prestaties te krijgen.
- Als u Azure Integration Runtime gebruikt om gegevens te kopiëren, kunt u grotere 'Data-Integratie eenheden (DIU)' (>4) instellen om meer rekenresources te gebruiken. Controleer de toepasselijke scenario's daar.
- "Mate van kopieerparallellisme" bepaalt de partitienummers, stelt dit getal een beetje te groot voor de prestaties, raadt u aan dit getal in te stellen als (DIU of het aantal zelf-hostende IR-knooppunten) * (2 tot 4).
Voorbeeld: volledige belasting van grote tabellen met fysieke partities
"source": {
"type": "AzureSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Voorbeeld: query met partitie dynamisch bereik
"source": {
"type": "AzureSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Voorbeeldquery om fysieke partitie te controleren
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Als de tabel een fysieke partitie heeft, ziet u HasPartition als ja, zoals hieronder.

Best practice voor het laden van gegevens in Azure SQL Database
Wanneer u gegevens kopieert naar Azure SQL Database, hebt u mogelijk een ander schrijfgedrag nodig:
- Toevoegen: Mijn brongegevens bevatten alleen nieuwe records.
- Upsert: Mijn brongegevens bevatten zowel invoegingen als updates.
- Overschrijven: ik wil elke keer een hele dimensietabel opnieuw laden.
- Schrijven met aangepaste logica: ik heb extra verwerking nodig voordat de uiteindelijke invoeging in de doeltabel wordt ingevoegd.
Raadpleeg de betreffende secties over het configureren in de service en aanbevolen procedures.
Gegevens toevoegen
Het toevoegen van gegevens is het standaardgedrag van deze Azure SQL Database-sinkconnector. De service voert een bulksgewijze invoegbewerking uit om efficiënt naar uw tabel te schrijven. U kunt de bron en sink dienovereenkomstig configureren in de kopieeractiviteit.
Upsert-gegevens
Copy-activiteit biedt nu ondersteuning voor het systeemeigen laden van gegevens in een tijdelijke databasetabel en werkt u vervolgens de gegevens in de sinktabel bij als de sleutel bestaat en voegt u andere nieuwe gegevens in. Zie Azure SQL Database als sink voor meer informatie over upsert-instellingen in kopieeractiviteiten.
De hele tabel overschrijven
U kunt de preCopyScript-eigenschap configureren in de sink van de kopieeractiviteit. In dit geval voert de service voor elke kopieeractiviteit het script eerst uit. Vervolgens wordt de kopie uitgevoerd om de gegevens in te voegen. Als u bijvoorbeeld de hele tabel met de meest recente gegevens wilt overschrijven, geeft u een script op om eerst alle records te verwijderen voordat u de nieuwe gegevens bulksgewijs uit de bron laadt.
Gegevens schrijven met aangepaste logica
De stappen voor het schrijven van gegevens met aangepaste logica zijn vergelijkbaar met de stappen die worden beschreven in de sectie Upsert-gegevens . Wanneer u extra verwerking moet toepassen voordat de uiteindelijke invoeging van brongegevens in de doeltabel wordt uitgevoerd, kunt u laden naar een faseringstabel en vervolgens opgeslagen procedureactiviteit aanroepen, of een opgeslagen procedure aanroepen in de sink voor kopieeractiviteiten om gegevens toe te passen, of toewijzings-Gegevensstroom gebruiken.
Een opgeslagen procedure aanroepen vanuit een SQL-sink
Wanneer u gegevens kopieert naar Azure SQL Database, kunt u ook een door de gebruiker opgegeven opgeslagen procedure configureren en aanroepen met aanvullende parameters voor elke batch van de brontabel. De functie voor opgeslagen procedures maakt gebruik van parameters met tabelwaarden.
U kunt een opgeslagen procedure gebruiken wanneer ingebouwde kopieermechanismen niet het doel dienen. Een voorbeeld is wanneer u extra verwerking wilt toepassen voordat de uiteindelijke invoeging van brongegevens in de doeltabel wordt ingevoegd. Enkele extra verwerkingsvoorbeelden zijn wanneer u kolommen wilt samenvoegen, extra waarden wilt opzoeken en in meer dan één tabel wilt invoegen.
In het volgende voorbeeld ziet u hoe u een opgeslagen procedure gebruikt om een upsert uit te voeren in een tabel in Azure SQL Database. Stel dat de invoergegevens en de sink-tabel Marketing elk drie kolommen hebben: ProfileID, State en Category. Voer de upsert uit op basis van de kolom ProfileID en pas deze alleen toe op een specifieke categorie met de naam ProductA.
Definieer in uw database het tabeltype met dezelfde naam als sqlWriterTableType. Het schema van het tabeltype is hetzelfde als het schema dat wordt geretourneerd door uw invoergegevens.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )Definieer in uw database de opgeslagen procedure met dezelfde naam als sqlWriterStoredProcedureName. Hiermee worden invoergegevens van de opgegeven bron verwerkt en samengevoegd in de uitvoertabel. De parameternaam van het tabeltype in de opgeslagen procedure is hetzelfde als tableName die in de gegevensset is gedefinieerd.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDDefinieer in uw Azure Data Factory- of Synapse-pijplijn de sectie SQL-sink in de kopieeractiviteit als volgt:
"sink": { "type": "AzureSqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Wanneer u gegevens naar Azure SQL Database schrijft met behulp van een opgeslagen procedure, splitst de sink de brongegevens op in minibatches en voert u de invoegbewerking uit, zodat de extra query in de opgeslagen procedure meerdere keren kan worden uitgevoerd. Als u de query voor de kopieeractiviteit hebt die moet worden uitgevoerd voordat u gegevens naar Azure SQL Database schrijft, wordt het afgeraden deze toe te voegen aan de opgeslagen procedure. Voeg deze toe in het vak Script vooraf kopiëren.
Eigenschappen van toewijzingsgegevensstroom
Wanneer u gegevens transformeert in de toewijzingsgegevensstroom, kunt u tabellen lezen en schrijven vanuit Azure SQL Database. Zie de brontransformatie en sinktransformatie in toewijzingsgegevensstromen voor meer informatie.
Brontransformatie
Instellingen die specifiek zijn voor Azure SQL Database zijn beschikbaar op het tabblad Bronopties van de brontransformatie.
Invoer: Selecteer of u de bron naar een tabel (equivalent van Select * from <table-name>) verwijst of een aangepaste SQL-query invoert.
Query: Als u Query selecteert in het invoerveld, voert u een SQL-query voor uw bron in. Met deze instelling wordt elke tabel overschreven die u in de gegevensset hebt gekozen. Order By-componenten worden hier niet ondersteund, maar u kunt een volledige SELECT FROM-instructie instellen. U kunt ook door de gebruiker gedefinieerde tabelfuncties gebruiken. select * from udfGetData() is een UDF in SQL die een tabel retourneert. Met deze query wordt een brontabel geproduceerd die u in uw gegevensstroom kunt gebruiken. Het gebruik van query's is ook een uitstekende manier om rijen te verminderen voor testen of opzoekacties.
Tip
De algemene tabelexpressie (CTE) in SQL wordt niet ondersteund in de querymodus toewijzingsgegevensstroom, omdat de vereiste voor het gebruik van deze modus is dat query's kunnen worden gebruikt in de SQL-query-FROM-component, maar CTE's kunnen dit niet doen. Als u CTE's wilt gebruiken, moet u een opgeslagen procedure maken met behulp van de volgende query:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Gebruik vervolgens de modus Opgeslagen procedure in de brontransformatie van de toewijzingsgegevensstroom en stel het @query voorbeeld als volgt in with CTE as (select 'test' as a) select * from CTE. Vervolgens kunt u CTE's gebruiken zoals verwacht.
Opgeslagen procedure: kies deze optie als u een projectie en brongegevens wilt genereren op basis van een opgeslagen procedure die wordt uitgevoerd vanuit uw brondatabase. U kunt het schema, de procedurenaam en de parameters typen of op Vernieuwen klikken om de service te vragen de schema's en procedurenamen te detecteren. Klik vervolgens op Importeren om alle procedureparameters te importeren met behulp van het formulier @paraName.

- SQL-voorbeeld:
Select * from MyTable where customerId > 1000 and customerId < 2000 - Voorbeeld van geparameteriseerde SQL:
"select * from {$tablename} where orderyear > {$year}"
Batchgrootte: Voer een batchgrootte in om grote gegevens te segmenteren in leesbewerkingen.
Isolatieniveau: de standaardinstelling voor SQL-bronnen in de toewijzingsgegevensstroom wordt niet-verzonden. U kunt hier het isolatieniveau wijzigen in een van deze waarden:
- Vastgelegd lezen
- Niet-verzonden lezen
- Herhaalbare leesbewerking
- Serialiseerbaar
- Geen (isolatieniveau negeren)

Incrementeel extraheren inschakelen: gebruik deze optie om ADF te laten weten dat alleen rijen moeten worden verwerkt die zijn gewijzigd sinds de laatste keer dat de pijplijn is uitgevoerd. Als u incrementeel extraheren met schemadrift wilt inschakelen, kiest u tabellen op basis van incrementele/watermerkkolommen in plaats van tabellen die zijn ingeschakeld voor systeemeigen wijzigingsgegevens vastleggen.
Incrementele kolom: Wanneer u de functie incrementeel extraheren gebruikt, moet u de datum/tijd of numerieke kolom kiezen die u wilt gebruiken als het watermerk in de brontabel.
Systeemeigen wijzigingsgegevens vastleggen inschakelen (preview): gebruik deze optie om ADF te laten weten dat alleen deltagegevens moeten worden verwerkt die zijn vastgelegd door sql-technologie voor wijzigingsgegevensopname sinds de laatste keer dat de pijplijn is uitgevoerd. Met deze optie worden de deltagegevens, waaronder het invoegen, bijwerken en verwijderen van rijen, automatisch geladen zonder dat er incrementele kolommen vereist zijn. U moet wijzigingsgegevens vastleggen in Azure SQL DB inschakelen voordat u deze optie in ADF gebruikt. Zie systeemeigen wijzigingsgegevens vastleggen voor meer informatie over deze optie in ADF.
Begin met lezen: Als u deze optie instelt met incrementeel uitpakken, wordt ADF geïnstrueerd om alle rijen te lezen bij de eerste uitvoering van een pijplijn, waarbij incrementeel extract is ingeschakeld.
Sinktransformatie
Instellingen die specifiek zijn voor Azure SQL Database, zijn beschikbaar op het tabblad Instellingen van de sinktransformatie.
Updatemethode: bepaalt welke bewerkingen zijn toegestaan op uw databasebestemming. De standaardinstelling is om alleen invoegingen toe te staan. Als u rijen wilt bijwerken, upsert of verwijderen, is een transformatie met alter-row vereist om rijen voor deze acties te taggen. Voor updates, upserts en verwijderingen moet een sleutelkolom of -kolommen worden ingesteld om te bepalen welke rij moet worden gewijzigd.

De kolomnaam die u hier als sleutel kiest, wordt door de service gebruikt als onderdeel van de volgende update, upsert, delete. Daarom moet u een kolom kiezen die bestaat in de sinktoewijzing. Als u de waarde niet naar deze sleutelkolom wilt schrijven, klikt u op Schrijven van sleutelkolommen overslaan.
U kunt de sleutelkolom die hier wordt gebruikt, parameteriseren voor het bijwerken van uw Azure SQL Database-doeltabel. Als u meerdere kolommen voor een samengestelde sleutel hebt, klikt u op 'Aangepaste expressie' en kunt u dynamische inhoud toevoegen met behulp van de expressietaal voor de gegevensstroom, die een matrix met tekenreeksen met kolomnamen voor een samengestelde sleutel kan bevatten.
Tabelactie: bepaalt of alle rijen opnieuw moeten worden gemaakt of verwijderd uit de doeltabel voordat u gaat schrijven.
- Geen: Er wordt geen actie uitgevoerd voor de tabel.
- Opnieuw maken: de tabel wordt verwijderd en opnieuw gemaakt. Vereist als u dynamisch een nieuwe tabel maakt.
- Afkappen: alle rijen uit de doeltabel worden verwijderd.
Batchgrootte: bepaalt hoeveel rijen er in elke bucket worden geschreven. Grotere batchgrootten verbeteren compressie en geheugenoptimalisatie, maar risico op geheugenuitzonderingen bij het opslaan van gegevens in de cache.
TempDB gebruiken: de service gebruikt standaard een globale tijdelijke tabel om gegevens op te slaan als onderdeel van het laadproces. U kunt ook de optie TempDB gebruiken uitschakelen en in plaats daarvan de service vragen om de tijdelijke holdingtabel op te slaan in een gebruikersdatabase die zich in de database bevindt die voor deze sink wordt gebruikt.

Pre- en post-SQL-scripts: voer SQL-scripts met meerdere regels in die worden uitgevoerd vóór (voorverwerking) en na (naverwerking) gegevens naar uw Sink-database worden geschreven

Tip
- Het is raadzaam om scripts met één batch met meerdere opdrachten in meerdere batches te splitsen.
- Alleen DDL-instructies (Data Definition Language) en DML-instructies (Data Definition Language) die een eenvoudig aantal updates retourneren, kunnen worden uitgevoerd als onderdeel van een batch. Meer informatie over het uitvoeren van batchbewerkingen
Verwerking van foutrijen
Bij het schrijven naar Azure SQL DB kunnen bepaalde rijen met gegevens mislukken vanwege beperkingen die zijn ingesteld door de bestemming. Enkele veelvoorkomende fouten zijn:
- Tekenreeks- of binaire gegevens worden afgekapt in tabel
- Kan de waarde NULL niet invoegen in kolom
- De INSERT-instructie is conflicterend met de CHECK-beperking
Standaard mislukt een uitvoering van een gegevensstroom bij de eerste fout die deze krijgt. U kunt ervoor kiezen om door te gaan op een fout waarmee uw gegevensstroom kan worden voltooid, zelfs als afzonderlijke rijen fouten hebben. De service biedt verschillende opties voor het afhandelen van deze foutrijen.
Transactiedoorvoering: kies of uw gegevens worden geschreven in één transactie of in batches. Eén transactie biedt slechtere prestaties, maar er zijn geen gegevens zichtbaar voor anderen totdat de transactie is voltooid.
Geweigerde uitvoergegevens: als deze optie is ingeschakeld, kunt u de foutrijen uitvoeren in een CSV-bestand in Azure Blob Storage of een Azure Data Lake Storage Gen2-account van uw keuze. Hiermee worden de foutrijen met drie extra kolommen geschreven: de SQL-bewerking zoals INSERT of UPDATE, de foutcode van de gegevensstroom en het foutbericht in de rij.
Geslaagd melden bij fout: als deze optie is ingeschakeld, wordt de gegevensstroom gemarkeerd als geslaagd, zelfs als er foutrijen worden gevonden.

Toewijzing van gegevenstypen voor Azure SQL Database
Wanneer gegevens worden gekopieerd van of naar Azure SQL Database, worden de volgende toewijzingen gebruikt van Azure SQL Database-gegevenstypen naar tussentijdse gegevenstypen van Azure Data Factory. Dezelfde toewijzingen worden gebruikt door de Synapse-pijplijnfunctie, waarmee Azure Data Factory rechtstreeks wordt geïmplementeerd. Zie Schema- en gegevenstypetoewijzingen voor meer informatie over hoe de kopieeractiviteit het bronschema en het gegevenstype toewijst aan de sink.
| Azure SQL Database-gegevenstype | Tussentijds gegevenstype Data Factory |
|---|---|
| bigint | Int64 |
| binair | Byte[] |
| bit | Booleaanse waarde |
| char | Tekenreeks, Teken[] |
| datum | Datum en tijd |
| Datum/tijd | DateTime |
| datetime2 | Datum en tijd |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM-kenmerk (varbinary(max)) | Byte[] |
| Float | Dubbel |
| image | Byte[] |
| int | Int32 |
| money | Decimal |
| nchar | Tekenreeks, Teken[] |
| ntekst | Tekenreeks, Teken[] |
| numeriek | Decimal |
| nvarchar | Tekenreeks, Teken[] |
| werkelijk | Eén |
| rowversion | Byte[] |
| smalldatetime | Datum en tijd |
| smallint | Int16 |
| smallmoney | Decimal |
| sql_variant | Object |
| sms verzenden | Tekenreeks, Teken[] |
| tijd | TimeSpan |
| timestamp | Byte[] |
| tinyint | Byte |
| uniqueidentifier | Guid |
| varbinary | Byte[] |
| varchar | Tekenreeks, Teken[] |
| xml | String |
Notitie
Voor gegevenstypen die zijn toegewezen aan het tussentijdse type Decimaal, biedt Copy-activiteit ondersteuning voor precisie tot 28. Als u gegevens hebt met een precisie die groter is dan 28, kunt u overwegen om te converteren naar een tekenreeks in sql-query.
Eigenschappen van opzoekactiviteit
Als u meer wilt weten over de eigenschappen, controleert u de lookup-activiteit.
Eigenschappen van GetMetadata-activiteit
Als u meer wilt weten over de eigenschappen, controleert u de Activiteit GetMetadata
Always Encrypted gebruiken
Wanneer u gegevens kopieert van/naar Azure SQL Database met Always Encrypted, volgt u de onderstaande stappen:
Sla de Kolomhoofdsleutel (CMK) op in een Azure Key Vault. Meer informatie over het configureren van Always Encrypted met behulp van Azure Key Vault
Zorg ervoor dat u toegang krijgt tot de sleutelkluis waar de CMK (Column Master Key) is opgeslagen. Raadpleeg dit artikel voor vereiste machtigingen.
Maak een gekoppelde service om verbinding te maken met uw SQL-database en schakel de functie Always Encrypted in met behulp van een beheerde identiteit of service-principal.
Notitie
Azure SQL Database Always Encrypted ondersteunt onderstaande scenario's:
- Bron- of sinkgegevensarchieven maken gebruik van beheerde identiteit of service-principal als verificatietype van de sleutelprovider.
- Zowel bron- als sinkgegevensarchieven gebruiken beheerde identiteit als verificatietype sleutelprovider.
- Zowel bron- als sinkgegevensarchieven gebruiken dezelfde service-principal als het verificatietype van de sleutelprovider.
Notitie
Momenteel wordt Azure SQL Database Always Encrypted alleen ondersteund voor brontransformatie in toewijzingsgegevensstromen.
Systeemeigen wijzigingsgegevens vastleggen
Azure Data Factory kan systeemeigen mogelijkheden voor het vastleggen van gegevens van wijzigingen ondersteunen voor SQL Server, Azure SQL DB en Azure SQL MI. De gewijzigde gegevens, waaronder het invoegen, bijwerken en verwijderen van rijen in SQL-archieven, kunnen automatisch worden gedetecteerd en geëxtraheerd door de ADF-toewijzingsgegevensstroom. Met de code-ervaring in de toewijzingsgegevensstroom kunnen gebruikers eenvoudig gegevensreplicatiescenario's uit SQL-archieven bereiken door een database toe te voegen als doelarchief. Bovendien kunnen gebruikers ook elke logica voor gegevenstransformatie opstellen om incrementeel ETL-scenario uit SQL-archieven te bereiken.
Zorg ervoor dat u de naam van de pijplijn en activiteit ongewijzigd laat, zodat het controlepunt kan worden vastgelegd door ADF zodat u automatisch gewijzigde gegevens van de laatste uitvoering kunt ophalen. Als u de naam of activiteitsnaam van uw automatisering wijzigt, wordt het controlepunt opnieuw ingesteld. Dit leidt ertoe dat u weer vanaf het begin begint of dat u vanaf nu wijzigingen krijgt in de volgende uitvoering. Als u de naam van de pijplijn of activiteit wilt wijzigen, maar het controlepunt toch wilt behouden om automatisch gewijzigde gegevens op te halen uit de laatste uitvoering, gebruikt u uw eigen controlepuntsleutel in de gegevensstroomactiviteit om dat te bereiken.
Wanneer u fouten in de pijplijn opssport, werkt deze functie hetzelfde. Houd er rekening mee dat het controlepunt opnieuw wordt ingesteld wanneer u uw browser vernieuwt tijdens de uitvoering van foutopsporing. Nadat u tevreden bent met het resultaat van de foutopsporingsuitvoering, kunt u doorgaan met het publiceren en activeren van de pijplijn. Op het moment dat u de gepubliceerde pijplijn voor het eerst activeert, wordt deze automatisch opnieuw opgestart vanaf het begin of worden er vanaf nu wijzigingen doorgevoerd.
In de sectie Bewaking hebt u altijd de mogelijkheid om een pijplijn opnieuw uit te voeren. Wanneer u dit doet, worden de gewijzigde gegevens altijd vastgelegd vanaf het vorige controlepunt van de geselecteerde pijplijnuitvoering.
Voorbeeld 1:
Wanneer u een brontransformatie waarnaar wordt verwezen naar een gegevensset met SQL CDC rechtstreeks koppelt aan een sinktransformatie waarnaar wordt verwezen naar een database in een toewijzingsgegevensstroom, worden de wijzigingen die zijn aangebracht op de SQL-bron automatisch toegepast op de doeldatabase, zodat u eenvoudig een scenario voor gegevensreplicatie tussen databases krijgt. U kunt de updatemethode in sinktransformatie gebruiken om te selecteren of u invoegen, bijwerken wilt toestaan of verwijderen wilt toestaan voor de doeldatabase. Het voorbeeldscript in de toewijzingsgegevensstroom is zoals hieronder.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Voorbeeld 2:
Als u ETL-scenario wilt inschakelen in plaats van gegevensreplicatie tussen de database via SQL CDC, kunt u expressies gebruiken in de toewijzingsgegevensstroom, inclusief isInsert(1), isUpdate(1) en isDelete(1) om de rijen met verschillende bewerkingstypen te onderscheiden. Hier volgt een van de voorbeeldscripts voor het toewijzen van gegevensstroom voor het afleiden van één kolom met de waarde: 1 om ingevoegde rijen aan te geven, 2 om bijgewerkte rijen aan te geven en 3 om verwijderde rijen aan te geven voor downstreamtransformaties om de deltagegevens te verwerken.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Bekende beperking:
- Alleen nettowijzigingen van SQL CDC worden via cdc.fn_cdc_get_net_changes_ door ADF geladen.
De versie van Azure SQL Database upgraden
Als u de Versie van Azure SQL Database wilt bijwerken, selecteert u Aanbevolen onder Versie en configureert u de gekoppelde service op de pagina Gekoppelde service bewerken door te verwijzen naar de eigenschappen van de gekoppelde service voor de aanbevolen versie.
Verschillen tussen de aanbevolen en de verouderde versie
In de onderstaande tabel ziet u de verschillen tussen Azure SQL Database met behulp van de aanbevolen en de verouderde versie.
| Aanbevolen versie | Verouderde versie |
|---|---|
Ondersteuning voor TLS 1.3 via encrypt as strict. |
TLS 1.3 wordt niet ondersteund. |
Gerelateerde inhoud
Zie Ondersteunde gegevensarchieven en -indelingen voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door de kopieeractiviteit.