Pijplijnen en activiteiten in Azure Data Factory en Azure Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Belangrijk
Ondersteuning voor Azure Machine Learning Studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden op die datum over te stappen naar Azure Machine Learning .
Vanaf 1 december 2021 kunt u geen nieuwe Machine Learning Studio-resources (klassiek) maken (werkruimte- en webserviceplan). Tot en met 31 augustus 2024 kunt u de bestaande Experimenten en webservices van Machine Learning Studio (klassiek) blijven gebruiken. Zie voor meer informatie:
- Migreren naar Azure Machine Learning vanuit Machine Learning Studio (klassiek)
- Wat is Azure Machine Learning?
Machine Learning Studio -documentatie (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet bijgewerkt.
Dit artikel helpt u bij het begrijpen van pijplijnen en activiteiten in Azure Data Factory en Azure Synapse Analytics en deze gebruiken om end-to-end gegevensgestuurde werkstromen te maken voor uw scenario's voor gegevensverplaatsing en gegevensverwerking.
Overzicht
Een Data Factory- of Synapse-werkruimte kan een of meer pijplijnen hebben. Een pijplijn is een logische groep activiteiten die samen een taak uitvoeren. Een pijplijn kan bijvoorbeeld een set activiteiten bevatten die logboekgegevens opnemen en verwijderen, en vervolgens een toewijzingsgegevensstroom in gang zetten voor het analyseren van de logboekgegevens. Met de pijplijn kunt u de activiteiten beheren als een set in plaats van elk afzonderlijk. U implementeert en plant de pijplijn in plaats van de afzonderlijke activiteiten.
De activiteiten in een pijplijn bepalen acties die moeten worden uitgevoerd op uw gegevens. U kunt bijvoorbeeld een kopieeractiviteit gebruiken om gegevens van een SQL Server naar Azure Blob Storage te kopiëren. Gebruik vervolgens een gegevensstroomactiviteit of een Databricks Notebook-activiteit om gegevens van de blobopslag te verwerken en te transformeren naar een Azure Synapse Analytics-pool waarop business intelligence-rapportageoplossingen worden gebouwd.
Azure Data Factory en Azure Synapse Analytics hebben drie groeperingen van activiteiten: activiteiten voor gegevensverplaatsing, activiteiten voor gegevenstransformatie en controleactiviteiten. Een activiteit kan nul of meer invoergegevenssets hebben en een of meer uitvoergegevenssets produceren. In het volgende diagram ziet u de relatie tussen pijplijn, activiteit en gegevensset:

Een invoergegevensset vertegenwoordigt de invoer voor een activiteit in de pijplijn en een uitvoergegevensset vertegenwoordigt de uitvoer voor de activiteit. Met gegevenssets worden gegevens binnen andere gegevensarchieven geïdentificeerd, waaronder tabellen, bestanden, mappen en documenten. Nadat u een gegevensset hebt gemaakt, kunt u deze gebruiken voor activiteiten in een pijplijn. Een gegevensset kan bijvoorbeeld een gegevensset voor invoer/uitvoer van een kopieeractiviteit of een HDInsightHive-activiteit zijn. Zie het artikel Gegevenssets in Azure Data Factory voor meer informatie over gegevenssets.
Notitie
Er is een standaard zachte limiet van maximaal 80 activiteiten per pijplijn, waaronder interne activiteiten voor containers.
Activiteiten voor gegevensverplaatsing
De kopieeractiviteit in Data Factory kopieert gegevens van een brongegevensarchief naar een sinkgegevensarchief. Data Factory ondersteunt de gegevensarchieven die worden vermeld in deze sectie. Gegevens vanuit elke willekeurige bron kunnen naar een sink worden geschreven.
Zie het artikel Kopieeractiviteit - overzicht voor meer informatie.
Klik op een gegevensarchief voor informatie over het kopiëren van gegevens naar en van dat archief.
Notitie
Als een connector is gemarkeerd met preview, kunt u deze proberen en ons feedback geven. Neem contact op met de ondersteuning van Azure als u een afhankelijkheid van preview-connectors wilt opnemen in uw oplossing.
Activiteiten voor gegevenstransformatie
Azure Data Factory en Azure Synapse Analytics ondersteunen de volgende transformatieactiviteiten die afzonderlijk kunnen worden toegevoegd of gekoppeld aan een andere activiteit.
Zie het artikel Activiteiten voor gegevenstransformatie voor meer informatie.
| Activiteiten voor gegevenstransformatie | Compute-omgeving |
|---|---|
| Gegevensstroom | Apache Spark-clusters die worden beheerd door Azure Data Factory |
| Azure-functie | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Hadoop Streaming | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| ML Studio-activiteiten (klassiek): Batch-uitvoering en resource bijwerken | Azure VM |
| Opgeslagen procedure | Azure SQL, Azure Synapse Analytics of SQL Server |
| U-SQL | Azure Data Lake Analytics |
| Aangepaste activiteit | Azure Batch |
| Databricks Notebook | Azure Databricks |
| Databricks Jar-activiteit | Azure Databricks |
| Databricks Python-activiteit | Azure Databricks |
| Synapse Notebook-activiteit | Azure Synapse Analytics |
Controlestroomactiviteiten
De volgende controlestroomactiviteiten worden ondersteund:
| Controleactiviteit | Beschrijving |
|---|---|
| Variabele toevoegen | Voeg een waarde toe aan een bestaande matrixvariabele. |
| Pijplijn uitvoeren | Met de activiteit Pijplijn uitvoeren kan een Data Factory- of Synapse-pijplijn een andere pijplijn aanroepen. |
| Filteren | Een filterexpressie toepassen op een invoermatrix |
| Voor elke | De ForEachActivity definieert een herhalende controlestroom in de pijplijn. Deze activiteit wordt gebruikt om een verzameling te herhalen en voert opgegeven activiteiten uit in een lus. De lusimplementatie van deze activiteit is vergelijkbaar met Foreach-lusstructuur in computertalen. |
| Metagegevens ophalen | GetMetadata-activiteit kan worden gebruikt om metagegevens van alle gegevens in een Data Factory- of Synapse-pijplijn op te halen. |
| If Condition Activity | De If Condition kan worden gebruikt als vertakking onder de voorwaarde dat deze resulteert in waar of onwaar. De If Condition Activity biedt dezelfde functionaliteit als een If-instructie in een programmeertaal. Het evalueert een reeks activiteiten wanneer de voorwaarde evalueert op true en een andere set activiteiten wanneer de voorwaarde resulteert in false. |
| Lookup Activity | De Lookup Activity kan worden gebruikt om een record/tabelnaam/waarde van een externe bron te lezen of op te zoeken. Er kan naar deze uitvoer worden verwezen door volgende activiteiten. |
| Variabele instellen | Stel de waarde van een bestaande variabele in. |
| Until Activity | Hiermee implementeert u een Doen totdat-lus die vergelijkbaar is met een Doen totdat-lusstructuur in computertalen. Er wordt een reeks activiteiten uitgevoerd totdat de voorwaarde die aan de activiteit is gekoppeld, resulteert in waar. U kunt een time-outwaarde opgeven voor de activiteit tot de activiteit. |
| Validatieactiviteit | Zorg ervoor dat een pijplijn alleen wordt uitgevoerd als er een referentiegegevensset bestaat, voldoet aan een opgegeven criteria of dat er een time-out is bereikt. |
| Wait Activity | Wanneer u een wachtactiviteit in een pijplijn gebruikt, wacht de pijplijn op de opgegeven tijd voordat u verdergaat met de uitvoering van volgende activiteiten. |
| Webactiviteit | Webactiviteit kan worden gebruikt om een aangepast REST-eindpunt aan te roepen vanuit een pijplijn. U kunt gegevenssets en gekoppelde services doorgeven die moten worden verbruikt door en die toegankelijk zijn voor de activiteit. |
| Webhook-activiteit | Roep met behulp van de webhookactiviteit een eindpunt aan en geef een callback-URL door. De pijplijnuitvoering wacht totdat de callback is aangeroepen voordat u doorgaat met de volgende activiteit. |
Een pijplijn maken met de gebruikersinterface
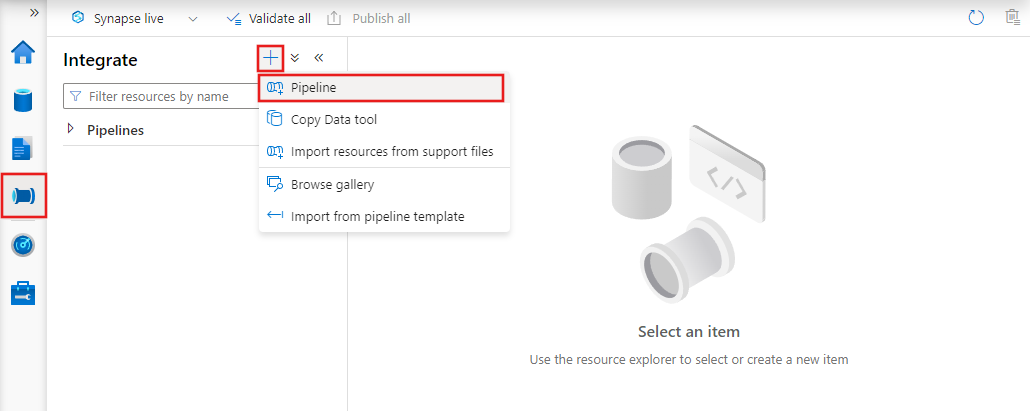
Als u een nieuwe pijplijn wilt maken, gaat u naar het tabblad Auteur in Data Factory Studio (vertegenwoordigd door het potloodpictogram), klikt u op het plusteken en kiest u Pijplijn in het menu en kiest u Pijplijn opnieuw in het submenu.
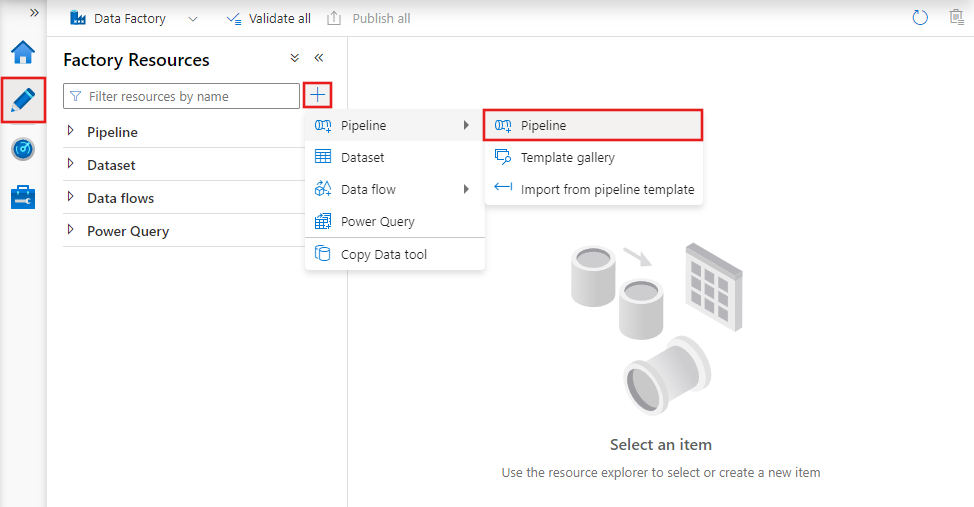
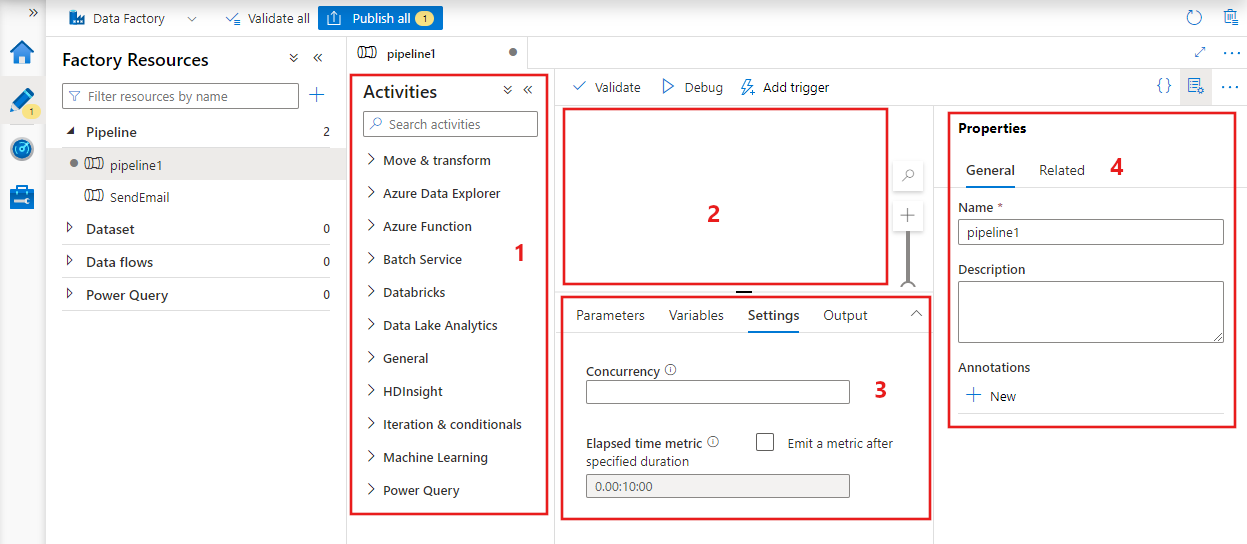
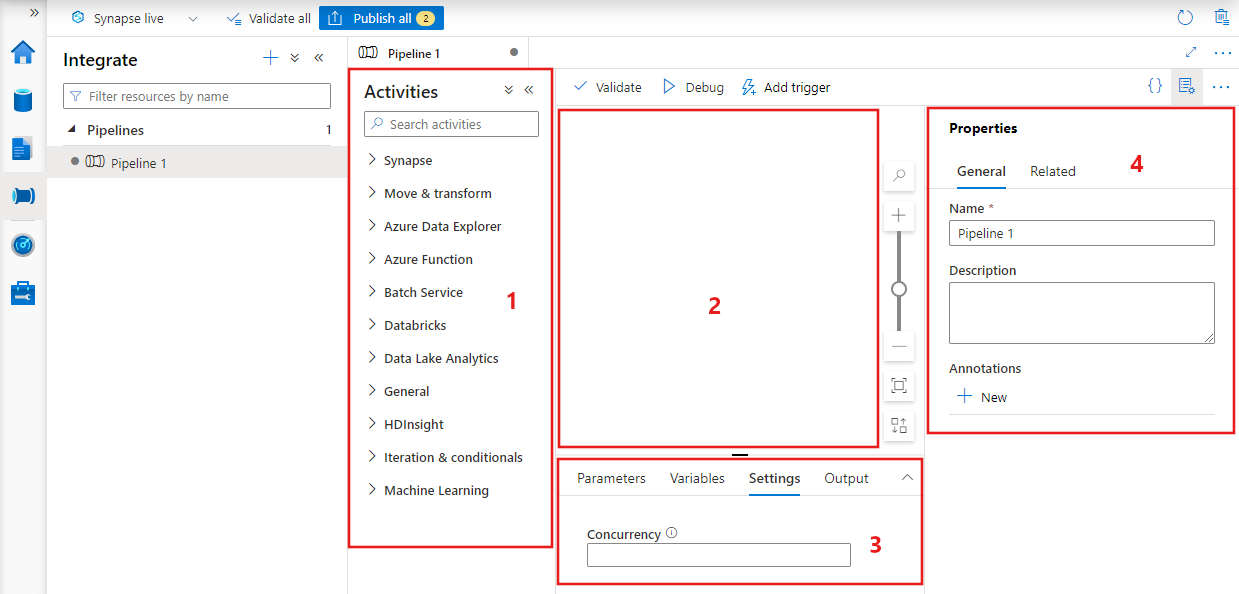
Data factory geeft de pijplijneditor weer waar u het volgende kunt vinden:
- Alle activiteiten die in de pijplijn kunnen worden gebruikt.
- Het canvas van de pijplijneditor, waar activiteiten worden weergegeven wanneer ze worden toegevoegd aan de pijplijn.
- Het deelvenster pijplijnconfiguraties, inclusief parameters, variabelen, algemene instellingen en uitvoer.
- Het deelvenster met pijplijneigenschappen, waarin de naam van de pijplijn, optionele beschrijving en aantekeningen kunnen worden geconfigureerd. In dit deelvenster worden ook gerelateerde items weergegeven aan de pijplijn in de data factory.
JSON-pijplijn
Een pijplijn wordt als volgt in de JSON-indeling gedefinieerd:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Code | Beschrijving | Type | Vereist |
|---|---|---|---|
| naam | Naam van de pijplijn. Geef een naam op die staat voor de actie die de pijplijn uitvoert.
|
String | Ja |
| beschrijving | Voer een beschrijving in van het doel waarvoor de pijplijn wordt gebruikt. | String | Nee |
| activities | De sectie activities kan één of meer activiteiten bevatten die zijn gedefinieerd binnen de activiteit. Zie de sectie Activity in JSON voor meer informatie over het JSON-element activities. | Matrix | Ja |
| parameters | De sectie parameters kan één of meer parameters bevatten die zijn gedefinieerd in de pijplijn, waardoor uw pijplijn kan worden hergebruikt. | List | Nee |
| Concurrency | Het maximum aantal gelijktijdige uitvoeringen dat de pijplijn kan hebben. Standaard is er geen maximum. Als de gelijktijdigheidslimiet is bereikt, worden er extra pijplijnuitvoeringen in de wachtrij geplaatst totdat eerdere uitvoeringen zijn voltooid | Aantal | Nee |
| Aantekeningen | Een lijst met tags die zijn gekoppeld aan de pijplijn | Matrix | Nee |
Activity in JSON
De sectie activities kan één of meer activiteiten bevatten die zijn gedefinieerd binnen de activiteit. Er zijn twee soorten activiteiten: uitvoerings- en controleactiviteiten.
Uitvoeringsactiviteiten
Uitvoeringsactiviteiten zijn activiteiten voor gegevensverplaatsing en activiteiten voor gegevenstransformatie. Ze hebben de volgende structuur op het hoogste niveau:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
De volgende tabel beschrijft de eigenschappen in de JSON-definitie activity:
| Code | Beschrijving | Vereist |
|---|---|---|
| naam | De naam van de activiteit. Geef een naam op die staat voor de actie die de activiteit uitvoert.
|
Ja |
| beschrijving | Beschrijving van het doel waarvoor de activiteit of wordt gebruikt | Ja |
| type | Type activiteit. Bekijk de secties Activiteiten voor gegevensverplaatsing, Activiteiten voor gegevenstransformatie en Controleactiviteiten voor andere typen activiteiten. | Ja |
| linkedServiceName | De naam van de gekoppelde service die door de activiteit wordt gebruikt. Voor een activiteit moet u mogelijk de gekoppelde service opgeven die is gekoppeld aan de vereiste rekenomgeving. |
Ja voor HDInsight Activity, ML Studio (klassiek) Batch Scoring Activity, Stored Procedure Activity. Nee voor alle andere |
| typeProperties | Eigenschappen in de sectie typeProperties zijn afhankelijk van elk type activiteit. Klik op koppelingen naar de activiteiten in de vorige sectie om typeProperties voor een activiteit te bekijken. | Nee |
| policy | Beleidsregels die van invloed zijn op het runtimegedrag van de activiteit. Deze eigenschap bevat een time-out en gedrag voor opnieuw proberen. Als dit niet is opgegeven, worden standaardwaarden gebruikt. Zie voor meer informatie de sectie Beleidsregels voor activiteiten. | Nee |
| dependsOn | Deze eigenschap wordt gebruikt voor het definiëren van afhankelijkheden van de activiteit, en hoe de volgende activiteiten afhankelijk zijn van vorige activiteiten. Zie voor meer informatie de sectie Afhankelijkheid van activiteiten | Nee |
Beleid voor activiteiten
Beleidsregels zijn van invloed op het runtimegedrag van een activiteit, waardoor configuratieopties worden gegeven. Beleidsregels voor activiteiten zijn alleen beschikbaar voor uitvoeringsactiviteiten.
JSON-definitie van beleidsregels voor activiteiten
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| JSON-naam | Beschrijving | Toegestane waarden | Vereist |
|---|---|---|---|
| timeout | Hiermee geeft u de time-out op voor de activiteit die moet worden uitgevoerd. | Periode | Nee De standaardtime-out is 12 uur, minimaal 10 minuten. |
| Probeer het opnieuw | Maximaal aantal nieuwe pogingen | Geheel getal | Nee De standaardwaarde is 0 |
| retryIntervalInSeconds | De vertraging tussen nieuwe pogingen in seconden | Geheel getal | Nee De standaardwaarde is 30 seconden |
| secureOutput | Als deze optie is ingesteld op waar, wordt de uitvoer van de activiteit beschouwd als veilig en wordt deze niet geregistreerd voor bewaking. | Booleaanse waarde | Nee Standaard ingesteld op onwaar. |
Controleactiviteit
Controleactiviteiten hebben de volgende structuur op het hoogste niveau:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Code | Beschrijving | Vereist |
|---|---|---|
| naam | De naam van de activiteit. Geef een naam op die staat voor de actie die de activiteit uitvoert.
|
Ja |
| beschrijving | Beschrijving van het doel waarvoor de activiteit of wordt gebruikt | Ja |
| type | Type activiteit. Bekijk de secties Activiteiten voor gegevensverplaatsing, Activiteiten voor gegevenstransformatie en Controleactiviteiten voor andere typen activiteiten. | Ja |
| typeProperties | Eigenschappen in de sectie typeProperties zijn afhankelijk van elk type activiteit. Klik op koppelingen naar de activiteiten in de vorige sectie om typeProperties voor een activiteit te bekijken. | Nee |
| dependsOn | Deze eigenschap wordt gebruikt voor het definiëren van afhankelijkheden van de activiteit, en hoe de volgende activiteiten afhankelijk zijn van vorige activiteiten. Zie voor meer informatie de sectie Afhankelijkheid van activiteiten. | Nee |
Afhankelijkheid van activiteiten
Activiteitsafhankelijkheid bepaalt hoe volgende activiteiten afhankelijk zijn van eerdere activiteiten, waarbij wordt bepaald of de volgende taak moet worden uitgevoerd. Een activiteit kan afhankelijk zijn van een of meer eerdere activiteiten met verschillende afhankelijkheidsvoorwaarden.
De verschillende afhankelijkheidsvoorwaarden zijn: Succeeded, Failed, Skipped, Completed.
Als een pijplijn bijvoorbeeld Activiteit A -> Activiteit B heeft, zijn de verschillende scenario's die kunnen optreden:
- Activiteit B heeft de afhankelijkheidsvoorwaarde succeeded ten opzichte van Activiteit A. Dit houdt in dat Activiteit B alleen kan worden uitgevoerd als Activiteit A de definitieve status succeeded heeft
- Activiteit B heeft de afhankelijkheidsvoorwaarde failed ten opzichte van Activiteit A. Dit houdt in dat Activiteit B alleen kan worden uitgevoerd als Activiteit A de definitieve status failed heeft
- Activiteit B heeft de afhankelijkheidsvoorwaarde completed ten opzichte van Activiteit A. Dit houdt in dat Activiteit B wordt uitgevoerd als Activiteit A de definitieve status succeeded of failed heeft
- Activiteit B heeft een afhankelijkheidsvoorwaarde voor Activiteit A met overgeslagen: Activiteit B wordt uitgevoerd als Activiteit A de uiteindelijke status van overgeslagen heeft. Overgeslagen vindt plaats in het scenario van Activiteit X -> Activiteit Y -> Activiteit Z, waarbij elke activiteit alleen wordt uitgevoerd als de vorige activiteit slaagt. Als Activiteit X mislukt, heeft Activiteit Y de status 'Overgeslagen' omdat deze nooit wordt uitgevoerd. Op dezelfde manier heeft Activiteit Z ook de status 'Overgeslagen'.
Voorbeeld: Activiteit 2 is afhankelijk van het slagen van Activiteit 1
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
Voorbeeld van kopieerpijplijn
De volgende voorbeeldpijplijn bevat een activiteit van het type Copy in de sectie activities. In dit voorbeeld kopieert de kopieeractiviteit gegevens van een Azure Blob-opslag naar een database in Azure SQL Database.
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
Let op de volgende punten:
- In het gedeelte Activiteiten is er slechts één activiteit waarvan type is ingesteld op Copy.
- De invoer voor de activiteit is ingesteld op InputDataset en de uitvoer voor de activiteit is ingesteld op OutputDataset. Zie het artikel Gegevenssets voor informatie over het definiëren van gegevenssets in JSON.
- In het gedeelte typeProperties is BlobSource opgegeven als het brontype en SqlSink als het sink-type. Klik in de sectie Activiteiten voor gegevensverplaatsing op het gegevensarchief dat u wilt gebruiken als een bron of een sink voor meer informatie over het verplaatsen van gegevens naar/van het betreffende gegevensarchief.
Zie quickstart: een Data Factory maken voor een volledig overzicht van het maken van deze pijplijn.
Voorbeeld van pijplijn voor transformatie
De volgende voorbeeldpijplijn bevat een activiteit van het type HDInsightHive in de sectie activities. In dit voorbeeld transformeert de HDInsight Hive-activiteit gegevens uit een Azure-blobopslag door een Hive-scriptbestand uit te voeren op een Azure HDInsight Hadoop-cluster.
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.windows.net/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
Let op de volgende punten:
- In het gedeelte activities is er slechts één activiteit waarvan type is ingesteld op HDInsightHive.
- Het Hive-scriptbestand partitionweblogs.hql wordt opgeslagen in het Azure Storage-account (opgegeven door de scriptLinkedService, AzureStorageLinkedService) en in de scriptmap in de container
adfgetstarted. - De sectie
defineswordt gebruikt om de runtime-instellingen op te geven die worden doorgegeven aan het Hive-script, zoals Hive-configuratiewaarden (bijvoorbeeld ${hiveconf:inputtable},${hiveconf:partitionedtable}).
De sectie typeProperties verschilt voor elke transformatieactiviteit. Voor meer informatie over ondersteunde typeProperties voor een transformatieactiviteit, klikt u op de transformatieactiviteit in Activiteiten voor gegevenstransformatie.
Zie Zelfstudie: Gegevens transformeren met Sparkvoor een volledige procedure voor het maken van deze pijplijn.
Meerdere activiteiten in een pijplijn
De vorige twee voorbeeldpijplijnen bevatten slechts één activiteit. Een pijplijn kan echter meer dan één activiteit hebben. Als u meerdere activiteiten in een pijplijn hebt en volgende activiteiten niet afhankelijk zijn van eerdere activiteiten, kunnen de activiteiten parallel worden uitgevoerd.
U kunt twee activiteiten koppelen met de afhankelijkheid van activiteiten, waarmee u definieert hoe latere activiteiten afhankelijk zijn van vorige activiteiten. Op basis hiervan wordt bepaald of de volgende taak kan worden uitgevoerd. Een activiteit kan één of meerdere vorige activiteiten beschermen met verschillende afhankelijkheidsvoorwaarden.
Pijplijnen plannen
Pijplijnen worden door triggers gepland. Er zijn verschillende soorten triggers (Scheduler-trigger, waarmee pijplijnen kunnen worden geactiveerd volgens een wandklokschema, evenals de handmatige trigger, waarmee pijplijnen op aanvraag worden geactiveerd). Zie het artikel Pijplijnen uitvoeren en triggersvoor meer informatie over triggers.
Als u wilt dat de trigger een pijplijnuitvoering activeert, moet u een verwijzing naar de betreffende pijplijn opnemen in de definitie van de trigger. Pijplijnen en triggers hebben een 'n-m-relatie'. Meerdere triggers kunnen één pijplijn starten en één trigger kan meerdere pijplijnen starten. Als de trigger is gedefinieerd, moet u de trigger starten zodat deze de pijplijn kan activeren. Zie het artikel Pijplijnen uitvoeren en triggersvoor meer informatie over triggers.
Stel dat u een Scheduler-trigger hebt, 'Trigger A', die ik wil starten met mijn pijplijn, 'MyCopyPipeline'. U definieert de trigger, zoals wordt weergegeven in het volgende voorbeeld:
Definitie van Trigger A
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}