Gegevens kopiëren uit Netezza met behulp van Azure Data Factory of Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u kopieeractiviteit gebruikt in Azure Data Factory- of Synapse Analytics-pijplijnen om gegevens uit Netezza te kopiëren. Het artikel bouwt voort op kopieeractiviteit, waarin een algemeen overzicht van de kopieeractiviteit wordt weergegeven.
Tip
Voor gegevensmigratiescenario's van Netezza naar Azure vindt u meer informatie over het migreren van gegevens van een on-premises Netezza-server naar Azure.
Ondersteunde mogelijkheden
Deze Netezza-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/-) | (1) (2) |
| Activiteit Lookup | (1) (2) |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Zie Ondersteunde gegevensarchieven en -indelingen voor een lijst met gegevensarchieven die door de kopieeractiviteit worden ondersteund als bronnen en sinks.
Netezza-connector biedt ondersteuning voor parallelle kopieerbewerkingen vanuit de bron. Zie de sectie Parallel kopiëren uit Netezza voor meer informatie.
De service biedt een ingebouwd stuurprogramma om connectiviteit mogelijk te maken. U hoeft geen stuurprogramma handmatig te installeren om deze connector te gebruiken.
Vereisten
Als uw gegevensarchief zich in een on-premises netwerk, een virtueel Azure-netwerk of een virtuele particuliere cloud van Amazon bevindt, moet u een zelf-hostende Integration Runtime configureren om er verbinding mee te maken.
Als uw gegevensarchief een beheerde cloudgegevensservice is, kunt u De Azure Integration Runtime gebruiken. Als de toegang is beperkt tot IP-adressen die zijn goedgekeurd in de firewallregels, kunt u IP-adressen van Azure Integration Runtime toevoegen aan de acceptatielijst.
U kunt ook de beheerde functie voor integratieruntime voor virtuele netwerken in Azure Data Factory gebruiken om toegang te krijgen tot het on-premises netwerk zonder een zelf-hostende Integration Runtime te installeren en te configureren.
Zie Strategieën voor gegevenstoegang voor meer informatie over de netwerkbeveiligingsmechanismen en -opties die door Data Factory worden ondersteund.
Aan de slag
U kunt een pijplijn maken die gebruikmaakt van een kopieeractiviteit met behulp van de .NET SDK, de Python SDK, Azure PowerShell, de REST API of een Azure Resource Manager-sjabloon. Zie de zelfstudieKopieeractiviteit voor stapsgewijze instructies voor het maken van een pijplijn met een kopieeractiviteit.
Een gekoppelde service maken met Netezza met behulp van de gebruikersinterface
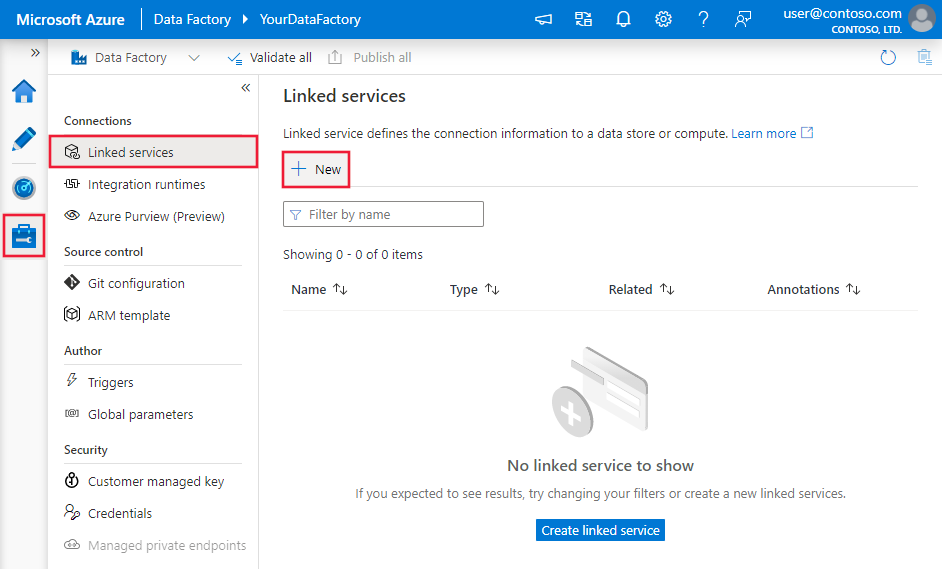
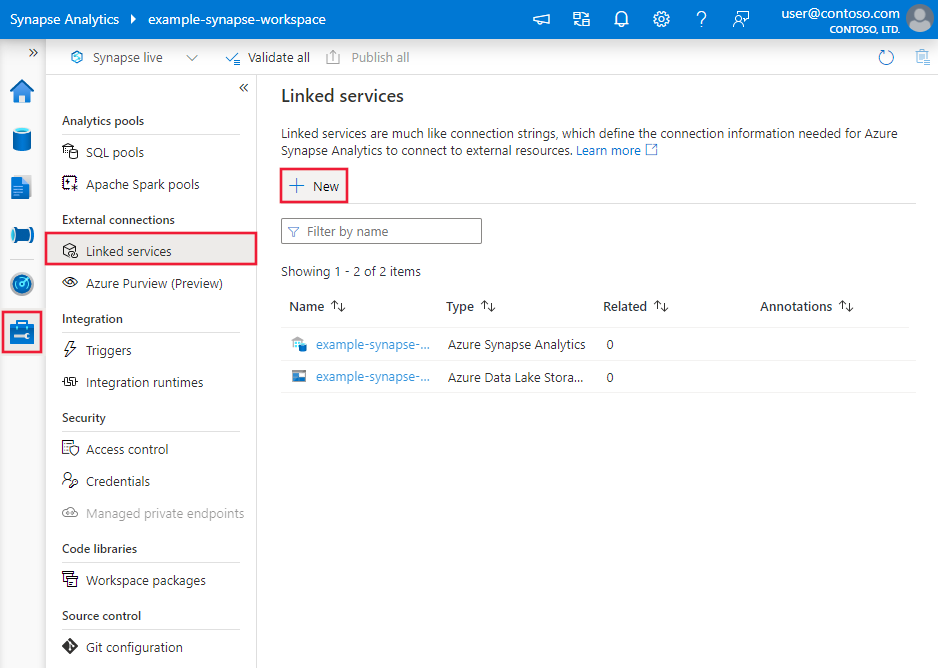
Gebruik de volgende stappen om een gekoppelde service te maken voor Netezza in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Netezza en selecteer de Netezza-connector.

Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.

Configuratiedetails van connector
De volgende secties bevatten details over eigenschappen die u kunt gebruiken om entiteiten te definiëren die specifiek zijn voor de Netezza-connector.
Eigenschappen van gekoppelde service
De volgende eigenschappen worden ondersteund voor de gekoppelde Netezza-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op Netezza. | Ja |
| connectionString | Een ODBC-verbindingsreeks om verbinding te maken met Netezza. U kunt ook een wachtwoord in Azure Key Vault plaatsen en de pwd configuratie uit de verbindingsreeks halen. Raadpleeg de volgende voorbeelden en sla referenties op in het Artikel over Azure Key Vault met meer informatie. |
Ja |
| connectVia | De Integration Runtime die moet worden gebruikt om verbinding te maken met het gegevensarchief. Meer informatie vindt u in de sectie Vereisten . Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee |
Een typische verbindingsreeks is Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>. In de volgende tabel worden meer eigenschappen beschreven die u kunt instellen:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| SecurityLevel | Het beveiligingsniveau dat het stuurprogramma gebruikt voor de verbinding met het gegevensarchief. Voorbeeld: SecurityLevel=preferredUnSecured. Ondersteunde waarden zijn:- Alleen onbeveiligd (alleenUnSecured): het stuurprogramma maakt geen gebruik van SSL. - Voorkeur onbeveiligd (preferredUnSecured) (standaard):als de server een keuze biedt, gebruikt het stuurprogramma geen SSL. |
Nee |
Voorbeeld
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld: wachtwoord opslaan in Azure Key Vault
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;",
"pwd": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Eigenschappen van gegevensset
Deze sectie bevat een lijst met eigenschappen die door de Netezza-gegevensset worden ondersteund.
Zie Gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets.
Als u gegevens van Netezza wilt kopiëren, stelt u de typeeigenschap van de gegevensset in op NetezzaTable. De volgende eigenschappen worden ondersteund:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op: NetezzaTable | Ja |
| schema | Naam van het schema. | Nee (als 'query' in de activiteitsbron is opgegeven) |
| table | Naam van de tabel. | Nee (als 'query' in de activiteitsbron is opgegeven) |
| tableName | Naam van de tabel met schema. Deze eigenschap wordt ondersteund voor compatibiliteit met eerdere versies. Gebruik schema en table voor nieuwe workload. |
Nee (als 'query' in de activiteitsbron is opgegeven) |
Voorbeeld
{
"name": "NetezzaDataset",
"properties": {
"type": "NetezzaTable",
"linkedServiceName": {
"referenceName": "<Netezza linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Eigenschappen van kopieeractiviteit
Deze sectie bevat een lijst met eigenschappen die door de Netezza-bron worden ondersteund.
Zie Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten.
Netezza als bron
Tip
Als u gegevens efficiënt vanuit Netezza wilt laden met behulp van gegevenspartitionering, vindt u meer informatie uit de sectie Parallel kopiëren vanuit Netezza .
Als u gegevens van Netezza wilt kopiëren, stelt u het brontype in Kopieeractiviteit in op NetezzaSource. De volgende eigenschappen worden ondersteund in de sectie Bron van kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op NetezzaSource. | Ja |
| query | Gebruik de aangepaste SQL-query om gegevens te lezen. Voorbeeld: "SELECT * FROM MyTable" |
Nee (als 'tableName' in de gegevensset is opgegeven) |
| partitionOptions | Hiermee geeft u de opties voor gegevenspartitionering op die worden gebruikt voor het laden van gegevens uit Netezza. Toegestane waarden zijn: Geen (standaard), DataSlice en DynamicRange. Wanneer een partitieoptie is ingeschakeld (dat wil gezegd, niet None), wordt de mate van parallelle uitvoering om gegevens uit een Netezza-database gelijktijdig te laden, bepaald door parallelCopies het instellen van de kopieeractiviteit. |
Nee |
| partitionSettings | Geef de groep van de instellingen voor gegevenspartitionering op. Toepassen wanneer de partitieoptie niet Noneis. |
Nee |
| partitionColumnName | Geef de naam op van de bronkolom in het type geheel getal dat wordt gebruikt door bereikpartitionering voor parallelle kopie. Als deze niet is opgegeven, wordt de primaire sleutel van de tabel automatisch gedetecteerd en gebruikt als de partitiekolom. Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?AdfRangePartitionColumnName in WHERE-component. Zie het voorbeeld in de sectie Parallel kopiëren vanuit Netezza . |
Nee |
| partitionUpperBound | De maximale waarde van de partitiekolom om gegevens te kopiëren. Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om brongegevens op te halen, koppelt ?AdfRangePartitionUpbound u deze in de WHERE-component. Zie de sectie Parallel kopiëren uit Netezza voor een voorbeeld. |
Nee |
| partitionLowerBound | De minimale waarde van de partitiekolom om gegevens te kopiëren. Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?AdfRangePartitionLowbound aan de WHERE-component. Zie de sectie Parallel kopiëren uit Netezza voor een voorbeeld. |
Nee |
Voorbeeld:
"activities":[
{
"name": "CopyFromNetezza",
"type": "Copy",
"inputs": [
{
"referenceName": "<Netezza input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Parallelle kopie van Netezza
De Data Factory Netezza-connector biedt ingebouwde gegevenspartitionering om gegevens parallel vanuit Netezza te kopiëren. U vindt opties voor gegevenspartitionering in de brontabel van de kopieeractiviteit.

Wanneer u gepartitioneerde kopieën inschakelt, voert de service parallelle query's uit op uw Netezza-bron om gegevens te laden op partities. De parallelle graad wordt bepaald door de parallelCopies instelling voor de kopieeractiviteit. Als u bijvoorbeeld instelt op parallelCopies vier, genereert de service gelijktijdig vier query's op basis van de opgegeven partitieoptie en -instellingen en haalt elke query een deel van de gegevens op uit uw Netezza-database.
U wordt aangeraden parallelle kopie met gegevenspartitionering in te schakelen, met name wanneer u grote hoeveelheden gegevens uit uw Netezza-database laadt. Hier volgen voorgestelde configuraties voor verschillende scenario's. Wanneer u gegevens kopieert naar een bestandsgegevensarchief, wordt u gevraagd om naar een map te schrijven als meerdere bestanden (alleen mapnaam opgeven), in welk geval de prestaties beter zijn dan schrijven naar één bestand.
| Scenario | Voorgestelde instellingen |
|---|---|
| Volledige belasting van grote tabel. | Partitieoptie: Gegevenssegment. Tijdens de uitvoering worden de gegevens automatisch gepartitioneerd op basis van de ingebouwde gegevenssegmenten van Netezza en worden gegevens gekopieerd op partities. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query. | Partitieoptie: Gegevenssegment. Query: SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>.Tijdens de uitvoering vervangt ?AdfPartitionCount de service (door het parallelle kopieernummer dat is ingesteld op kopieeractiviteit) en ?AdfDataSliceCondition met de partitielogica voor gegevenssegmenten en verzendt deze naar Netezza. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query, met een kolom met een geheel getal met gelijkmatig verdeelde waarde voor bereikpartitionering. | Partitieopties: partitie dynamisch bereik. Query: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Partitiekolom: Geef de kolom op die wordt gebruikt om gegevens te partitioneren. U kunt partitioneren op basis van de kolom met een gegevenstype geheel getal. Bovengrens en partitieondergrens partitioneren: geef op of u wilt filteren op basis van de partitiekolom om alleen gegevens op te halen tussen het onderste en bovenste bereik. Tijdens de uitvoering vervangt ?AdfRangePartitionColumnNamede service, ?AdfRangePartitionUpbounden ?AdfRangePartitionLowbound door de werkelijke kolomnaam en waardebereiken voor elke partitie en verzendt deze naar Netezza. Als de partitiekolom 'ID' bijvoorbeeld is ingesteld met de ondergrens 1 en de bovengrens als 80, waarbij parallelle kopie is ingesteld als 4, haalt de service gegevens op met 4 partities. Hun id's liggen tussen [1.20], [21, 40], [41, 60] en [61, 80], respectievelijk. |
Voorbeeld: query's uitvoeren met gegevenssegmentpartitie
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>",
"partitionOption": "DataSlice"
}
Voorbeeld: query met partitie dynamisch bereik
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Eigenschappen van opzoekactiviteit
Als u meer wilt weten over de eigenschappen, controleert u de lookup-activiteit.
Gerelateerde inhoud
Zie Ondersteunde gegevensarchieven en -indelingen voor een lijst met gegevensarchieven die door de kopieeractiviteit worden ondersteund als bronnen en sinks.