Gegevens kopiëren van Azure Blob-opslag naar een database in Azure SQL Database met Azure Data Factory
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie maakt u een data factory met behulp van de Azure Data Factory-gebruikersinterface. Met de pijplijn in deze data factory worden gegevens gekopieerd van Azure Blob Storage naar een database in Azure SQL Database. Het configuratiepatroon in deze zelfstudie geldt voor het kopiëren van een gegevensarchief op basis van bestanden naar een relationeel gegevensarchief. Zie de tabel Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bron en als sink.
Notitie
Zie Inleiding tot Azure Data Factory als u niet bekend bent met Azure Data Factory.
In deze zelfstudie voert u de volgende stappen uit:
- Een data factory maken.
- Een pijplijn met kopieeractiviteit maken.
- De uitvoering van de pijplijn testen.
- De pijplijn handmatig activeren.
- De pijplijn activeren volgens een schema.
- De uitvoering van de pijplijn en van de activiteit controleren.
Vereisten
- Azure-abonnement. Als u nog geen abonnement op Azure hebt, maakt u een gratis Azure-account voordat u begint.
- Azure-opslagaccount. U gebruikt de blobopslag als bron-gegevensopslag. Als u geen opslagaccount hebt, raadpleegt u het artikel Een opslagaccount maken om een account te maken.
- Azure SQL-database. U gebruikt de database als sink-gegevensopslag. Als u geen database in Azure SQL Database hebt, raadpleegt u Een database in Azure SQL Database maken om er een te maken.
Een blob en een SQL-tabel maken
Voer nu de volgende stappen uit om uw blobopslag en SQL database voor te bereiden voor gebruik in deze zelfstudie.
Een bron-blob maken
Start Kladblok. Kopieer de volgende tekst en sla deze op uw schijf op in het bestand emp.txt:
FirstName,LastName John,Doe Jane,DoeMaak in de blobopslag een container met de naam adftutorial. Maak een map aan met de naam invoer in deze container. Vervolgens kunt u het bestand emp.txt uploaden naar de map invoer. Gebruik de Azure-portal of hulpprogramma's zoals Azure Storage Explorer voor deze taken.
Een SQL-sink-tabel maken
Gebruik het volgende SQL-script om de tabel dbo.emp te maken in uw database:
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);Geef Azure-services toegang tot SQL Server. Zorg ervoor dat Toegang tot Azure-services toestaan is ingeschakeld voor SQL Server, zodat Data Factory gegevens naar SQL Server kan schrijven. Als u deze instelling wilt controleren en inschakelen, gaat u naar de firewall van de logische SQL-serveroverzichtssetserver > >> met de optie Toegang tot Azure-services toestaan op AAN.
Een data factory maken
In deze stap maakt u een data factory en start u de Data Factory-gebruikersinterface om een pijplijn te maken in de data factory.
Open Microsoft Edge of Google Chrome. Op dit moment wordt de Data Factory-gebruikersinterface alleen ondersteund in de webbrowsers Microsoft Edge en Google Chrome.
Selecteer in het linkermenu Een resource maken>Integratie>Data Factory.
Selecteer op de pagina Data factory maken op het tabblad Basisbeginselen het Azure-abonnement waarin u de data factory wilt maken.
Voer een van de volgende stappen uit voor Resourcegroep:
a. Selecteer een bestaande resourcegroep in de vervolgkeuzelijst.
b. Selecteer Nieuwe maken en voer de naam van een nieuwe resourcegroep in.
Zie Resourcegroepen gebruiken om Azure-resources te beheren voor meer informatie.
Selecteer onder Regio een locatie voor de data factory. In de vervolgkeuzelijst worden alleen ondersteunde locaties weergegeven. De gegevensarchieven (bijvoorbeeld Azure Storage en SQL Database) en berekenservices (bijvoorbeeld Azure HDInsight) die door de data factory worden gebruikt, kunnen zich in andere regio's bevinden.
Voer bij Naam in: ADFTutorialDataFactory.
De naam van de Azure-gegevensfactory moet wereldwijd uniek zijn. Als u een foutbericht ontvangt dat betrekking heeft op de waarde die bij de naam is ingevuld, voert u een andere naam in voor de data factory. (Gebruik dan bijvoorbeeld uwnaamADFTutorialDataFactory). Zie Data Factory naming rules (Naamgevingsregels Data Factory) voor meer informatie over naamgevingsregels voor Data Factory-artefacten.
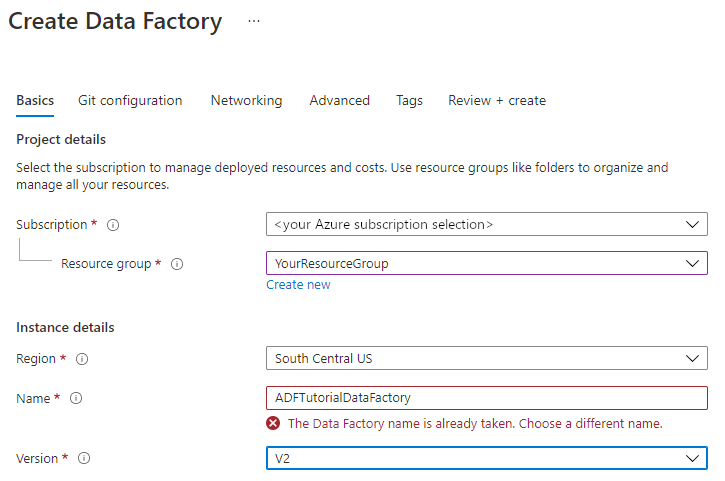
Selecteer V2 onder Versie.
Selecteer het tabblad Git-configuratie bovenaan en selecteer het selectievakje Git later configureren.
Selecteer Controleren en maken, en selecteer Maken nadat de validatie is voltooid.
Als het maken is voltooid, ziet u de melding in het meldingencentrum. Selecteer Naar resource gaan om naar de pagina Data factory te gaan.
Selecteer Openen op de tegel Azure Data Factory Studio openen om de Gebruikersinterface van Azure Data Factory op een afzonderlijk tabblad te starten.
Een pipeline maken
In deze stap maakt u een pijplijn met kopieeractiviteit in de data factory. De kopieeractiviteit kopieert gegevens van de blobopslag naar SQL Database. In de Quickstart hebt u een pijplijn gemaakt met de volgende stappen:
- Maak een gekoppelde service.
- Maak invoer- en uitvoergegevenssets.
- Een pipeline maken.
In deze zelfstudie begint u met het maken van de pijplijn. Vervolgens maakt u gekoppelde services en gegevenssets wanneer u deze nodig hebt om de pijplijn te configureren.
Selecteer Orchestrate op de startpagina.
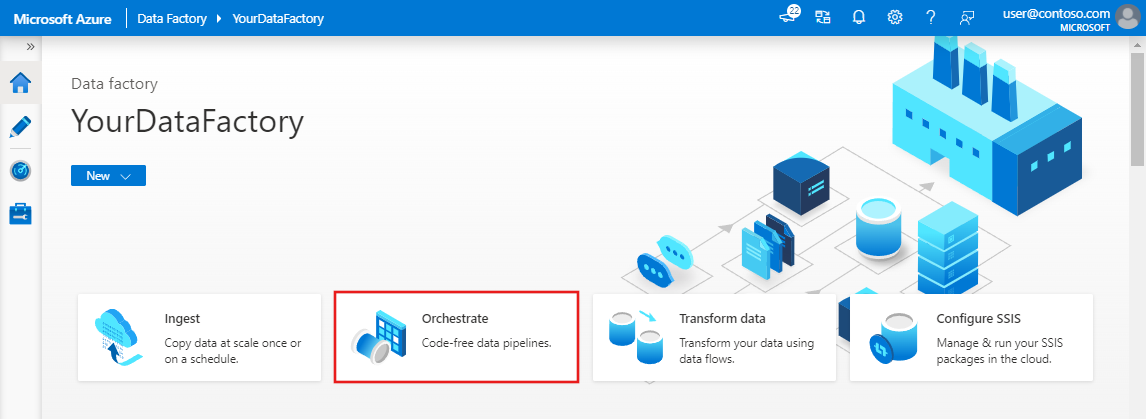
Geef bij Eigenschappen op het tabblad Algemeen CopyPipeline op als Naam. Vouw het paneel vervolgens samen door in de rechterbovenhoek op het pictogram Eigenschappen te klikken.
Breid in de werkset Activiteiten de categorie Verplaatsen en transformeren uit. Sleep de activiteit Gegevens kopiëren uit de werkset en zet deze neer op het ontwerpoppervlak voor pijplijnen. Geef CopyFromBlobToSql op bij Naam.
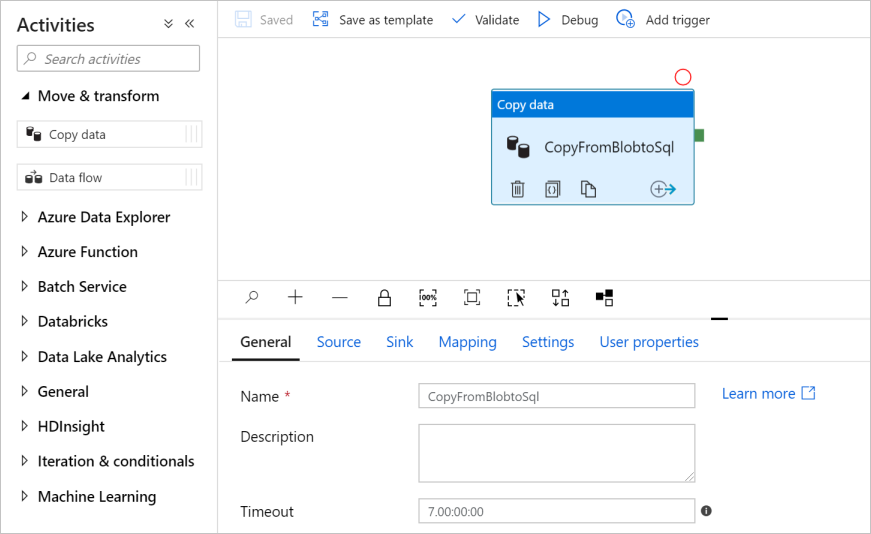
Bron configureren
Tip
In deze zelfstudie gebruikt u accountsleutel als verificatietype voor uw brongegevensarchief, maar u kunt indien nodig andere ondersteunde verificatiemethoden kiezen: SAS-URI, service-principal en beheerde identiteit. Raadpleeg de bijbehorende secties in dit artikel voor meer informatie. Het ook raadzaam om een Azure Key Vault te gebruiken om geheimen voor gegevensarchieven veilig op te slaan. Raadpleeg dit artikel voor gedetailleerde illustraties.
Ga naar het tabblad Bron . Selecteer + Nieuw om een brongegevensset te maken.
Selecteer in het dialoogvenster Nieuwe gegevensset de optie Azure Blob Storage en selecteer vervolgens Doorgaan. De brongegevens bevinden zich in een blobopslag, daarom selecteert u Azure Blob-opslag voor de brongegevensset.
Selecteer in het dialoogvenster Indeling selecteren het indelingstype van uw gegevens en selecteer vervolgens Doorgaan.
Voer in het dialoogvenster Eigenschappen instellen als naam SourceBlobDataset in. Schakel het selectievakje voor Eerste rij als header in. Selecteer onder het tekstvak Gekoppelde service de optie + Nieuw.
Voer in het dialoogvenster Nieuwe gekoppelde service als naam AzureStorageLinkedService in en selecteer uw opslagaccount in de lijst Naam van opslagaccount. Test de verbinding en selecteer Maken om de gekoppelde service te implementeren.
Nadat de gekoppelde service is gemaakt, wordt u teruggeleid naar de pagina Eigenschappen instellen. Selecteer naast Bestandspad de knop Bladeren.
Navigeer naar de map adftutorial/input, selecteer het bestand emp.txt en klik vervolgens op OK.
Selecteer OK. U wordt automatisch naar de pijplijnpagina geleid. Controleer op het tabblad Bron of SourceBlobDataset is geselecteerd. Selecteer Gegevens vooraf bekijken om een voorbeeld van de gegevens op deze pagina te bekijken.
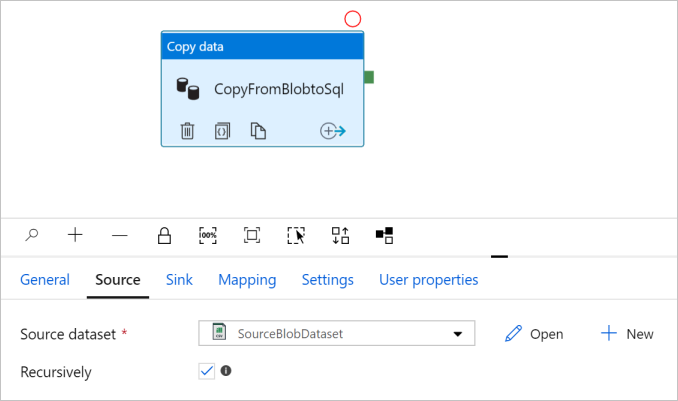
Sink configureren
Tip
In deze zelfstudie gebruikt u SQL-verificatie als verificatietype voor uw sinkgegevensarchief, maar u kunt indien nodig andere ondersteunde verificatiemethoden kiezen: service-principal en beheerde identiteit . Raadpleeg de bijbehorende secties in dit artikel voor meer informatie. Het ook raadzaam om een Azure Key Vault te gebruiken om geheimen voor gegevensarchieven veilig op te slaan. Raadpleeg dit artikel voor gedetailleerde illustraties.
Ga naar het tabblad Sink en selecteer +Nieuw om een sink-gegevensset te maken.
Voer in het dialoogvenster Nieuwe gegevensset 'SQL' in het zoekvak in om de connectoren te filteren, selecteer Azure SQL Database en selecteer vervolgens Doorgaan. In deze zelfstudie kopieert u gegevens naar een SQL database.
Voer in het dialoogvenster Eigenschappen instellen als naam OutputSqlDataset in. Selecteer + Nieuw in de vervolgkeuzelijst Gekoppelde service. Een gegevensset moet worden gekoppeld aan een gekoppelde service. De gekoppelde service beschikt over de verbindingsreeks die door Data Factory wordt gebruikt om tijdens runtime een verbinding met SQL Database tot stand te brengen. De dataset geeft informatie over de container, map en het bestand (optioneel) met de brongegevens.
Voer in het dialoogvenster Nieuwe gekoppelde service (Azure SQL Database) de volgende stappen uit:
a. Geef AzureSqlDatabaseLinkedService op als Naam.
b. Selecteer bij Servernaam uw SQL Server-exemplaar.
c. Selecteer uw database bij Databasenaam.
d. Voer bij Gebruikersnaam de naam van de gebruiker in.
e. Geef bij Wachtwoord het wachtwoord van de gebruiker op.
f. Als u de verbinding wilt testen, selecteert u Verbinding testen.
g. Selecteer Maken om de gekoppelde service te implementeren.
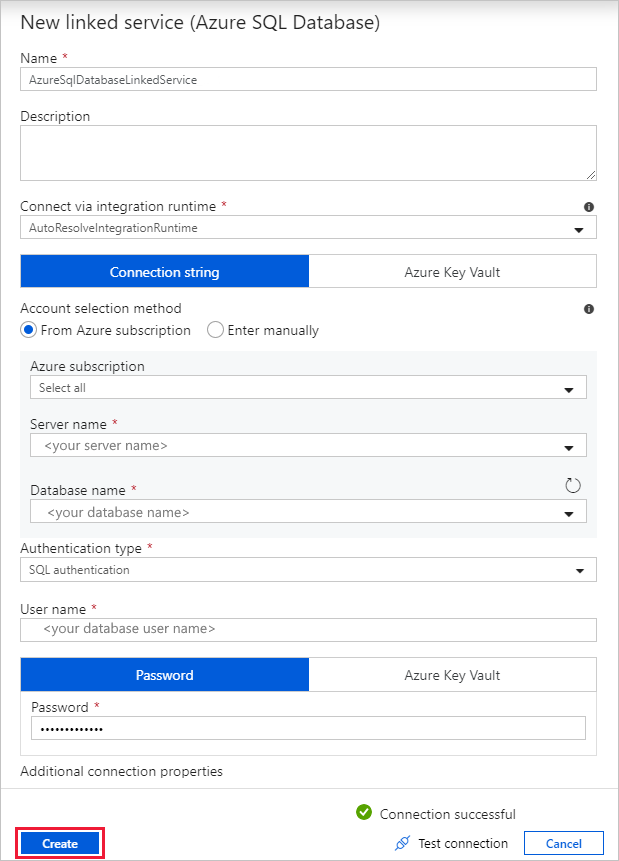
U wordt automatisch naar het dialoogvenster Eigenschappen instellen geleid. Selecteer bij Tabel[dbo].[emp]. Selecteer vervolgens OK.
Ga naar het tabblad met de pijplijn en controleer bij Sink-gegevensset of OutputSqlDataset is geselecteerd.
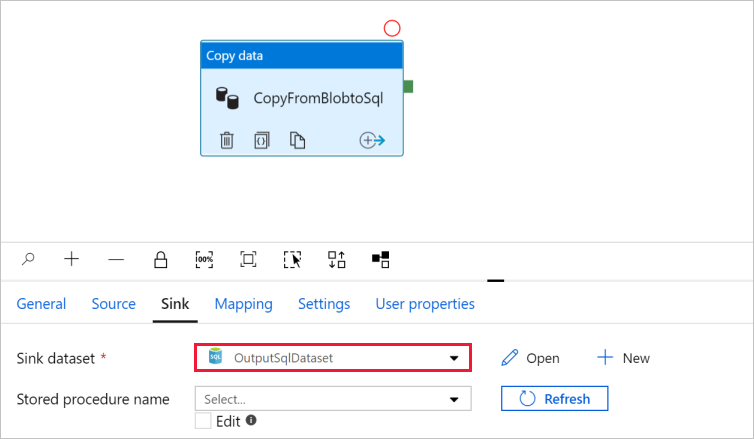
U kunt optioneel het schema van de bron toewijzen aan het overeenkomstige schema van het doel door Schematoewijzing in kopieeractiviteit te volgen.
De pijplijn valideren
Selecteer in de werkbalk Valideren om de pijplijn te valideren.
U ziet de JSON-code die is gekoppeld aan de pijplijn door te klikken op Code in de rechterbovenhoek.
Fouten opsporen in de pijplijn en de pijplijn publiceren
U kunt fouten opsporen in een pijplijn voordat u artefacten (gekoppelde services, gegevenssets en pijplijn) publiceert naar Data Factory of uw eigen Azure Repos Git-opslagplaats.
Selecteer Fouten opsporen om fouten op te sporen in de pijplijn. De status van de pijplijnuitvoering wordt weergegeven op het tabblad Uitvoer onder in het venster.
Zodra de pijplijn kan worden uitgevoerd, selecteert u Alles publiceren in de bovenste werkbalk. Met deze actie publiceert u entiteiten (gegevenssets en pijplijnen) die u hebt gemaakt met Data Factory.
Wacht totdat het bericht Successfully published wordt weergegeven. Om meldingsberichten te zien, klikt u op Meldingen weergeven rechts bovenin (belknop).
De pijplijn handmatig activeren
In deze stap moet u handmatig de pijplijn activeren, die u in de vorige stap heeft gepubliceerd.
Selecteer op de werkbalk de optie Activeren en selecteer vervolgens Nu activeren. Klik op de pagina Pijplijnuitvoering op OK.
Ga naar het tabblad Controleren aan de linkerkant. U ziet een pijplijn die wordt geactiveerd door een handmatige trigger. U kunt via koppelingen in de kolom NAAM PIJPLIJN details van activiteiten bekijken en de pijplijn opnieuw uitvoeren.

Selecteer de koppeling CopyPipeline in de kolom NAAM PIJPLIJN om de uitvoering van activiteiten te zien die zijn gekoppeld aan de pijplijnuitvoering. Omdat er in dit voorbeeld slechts één activiteit is, ziet u slechts één vermelding in de lijst. Selecteer de koppeling Details (pictogram van een bril) in de kolom NAAM ACTIVITEIT om details van de kopieerbewerking te zien. Selecteer Alle pijplijnuitvoeringen bovenaan om terug te gaan naar de weergave Pijplijnuitvoeringen. Selecteer Vernieuwen om de weergave te vernieuwen.

Controleer of er twee extra rijen zijn toegevoegd aan de emp-tabel in de database.

De pijplijn activeren volgens een schema
In dit schema maakt u een planningstrigger voor de pijplijn. De trigger voert de pijplijn uit volgens de opgegeven planning, bijvoorbeeld elk uur of dagelijks. Hier stelt u de trigger in om de pijplijn elke minuut uit te voeren tot en met de opgegeven einddatum/-tijd.
Ga naar het tabblad Auteur links boven op het tabblad Monitor.
Ga naar uw pijplijn, klik op Activeren in de werkbalk en selecteer Nieuw/Bewerken.
Selecteer in het dialoogvenster Triggers toevoegen de optie + Nieuw voor het gebied Trigger kiezen.
Voer in het venster Nieuwe trigger de volgende stappen uit:
a. Geef RunEveryMinute op bij Naam.
b. Werk de Startdatum voor de trigger bij. Als de datum vóór de huidige datum/tijd ligt, wordt de trigger van kracht zodra de wijziging is gepubliceerd.
c. Selecteer de vervolgkeuzelijst onder Tijdzone.
d. Stel Terugkeerpatroon in op Elke minuut.
e. Schakel het selectievakje voor Einddatum opgeven in, en werk het gedeelte Eindigen op bij naar enkele minuten na de huidige datum/tijd. De trigger wordt pas geactiveerd nadat u de wijzigingen publiceert. Als u deze slechts enkele minuten uit elkaar instelt en u voor die tijd niet publiceert, ziet u geen triggeruitvoering.
f. Selecteer voor de optie Geactiveerd Ja.
g. Selecteer OK.
Belangrijk
Er zijn kosten verbonden aan elke pijplijnuitvoering, dus stel een geschikte einddatum in.
Lees de waarschuwing op de pagina Trigger bewerken en selecteer vervolgens Opslaan. De pijplijn in dit voorbeeld gebruikt geen parameters.
Klik op Alles publiceren om de wijziging te publiceren.
Ga naar het tabblad Controleren aan de linkerkant om de geactiveerde pijplijnuitvoeringen te bekijken.

Als u wilt overschakelen van de weergave Pijplijnuitvoeringen naar de weergave Triggeruitvoeringen, selecteert u Triggeruitvoeringen aan de linkerkant van het venster.
U ziet de triggeruitvoeringen in een lijst.
Controleer of er twee rijen per minuut (voor elke pijplijnuitvoering) tot de opgegeven eindtijd in de emp-tabel worden ingevoegd.
Gerelateerde inhoud
Met de pijplijn in dit voorbeeld worden gegevens gekopieerd van de ene locatie naar een andere locatie in een blobopslag. U hebt geleerd hoe u:
- Een data factory maken.
- Een pijplijn met kopieeractiviteit maken.
- De uitvoering van de pijplijn testen.
- De pijplijn handmatig activeren.
- De pijplijn activeren volgens een schema.
- De uitvoering van de pijplijn en van de activiteit controleren.
Ga verder met de volgende zelfstudie als u wilt weten hoe u on-premises gegevens kopieert naar de cloud: