Van toepassing op: ✔️ Virtuele Linux-machines voor Windows-VM's ✔️ ✔️ Flexibele schaalsets Uniform-schaalsets ✔️
Azure Virtual Machine-grootten (VM's) zijn ontworpen om een breed scala aan opties te bieden voor het hosten van uw servers en hun workloads in de cloud. Grootten worden onderverdeeld in verschillende families en typen, elk geoptimaliseerd voor specifieke doeleinden. Gebruikers kunnen de meest geschikte VM-grootte kiezen op basis van hun vereisten, zoals CPU, geheugen, opslag en netwerkbandbreedte.
In dit artikel wordt beschreven welke grootten er zijn, wordt een overzicht van de beschikbare grootten weergegeven en worden verschillende opties weergegeven voor exemplaren van virtuele Azure-machines die u kunt gebruiken om uw apps en workloads uit te voeren.
Tip
Probeer de selectorfunctie voor virtuele machines om andere grootten te vinden die het beste bij uw workload passen.
Naamgeving van VM-grootte en -reeks
Azure VM-grootten volgen specifieke naamconventies om verschillende functies en specificaties aan te geven. Elk teken in de naam vertegenwoordigt verschillende aspecten van de VIRTUELE machine. Deze omvatten de VM-familie, het aantal vCPU's en extra functies, zoals Premium Storage of opgenomen accelerators.
Naamgeving van vm's wordt verder onderverdeeld in de naam 'Reeks' en de naam 'Grootte'. Namen van grootten bevatten extra tekens die het aantal vCPU's, het type opslag, enzovoort vertegenwoordigen.
Categorie
Beschrijving
Koppelingen
Type
Basiscategorisatie op basis van de beoogde werkbelasting.
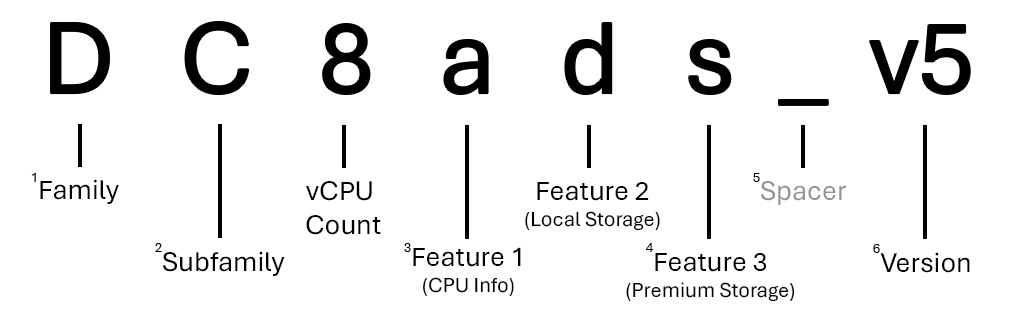
Hier volgt een uitsplitsing van de groottereeks Algemeen gebruik, DCads_v5-serie.
1 De meeste families worden weergegeven met één letter, maar andere, zoals GPU-grootten (ND-series, NV-seriesenzovoort), gebruiken twee.
2 De meeste subfamilies worden weergegeven met één hoofdletter, maar andere (zoals Ebsv5-series) worden nog steeds beschouwd als subfamilies van hun bovenliggende familie vanwege functieverschillen.
3 Als er geen functieletter voor een CPU wordt vermeld, gebruikt de serie Intel x86-64 CPU's. Als de CPU AMD is, wordt deze vermeld als a. Als de CPU arm is (Microsoft Cobalt of Ampere Altra), wordt deze vermeld als p.
4 Er kan een willekeurig aantal extra functies in een groottenaam zijn. Er kunnen geen (Dv5-series) of drie (Dplds_v6-series) zijn.
5 Versienummers worden alleen weergegeven in de groottenaam als er meerdere versies van dezelfde reeks zijn. Als u de eerste versie van een reeks (HB-series, enzovoort) gebruikt, B-serieswordt deze vaak niet opgenomen in de naam van de grootte.
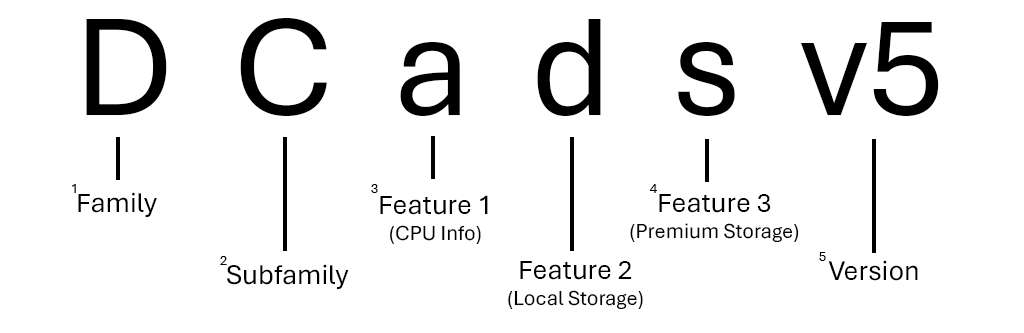
Hier volgt een uitsplitsing van een 'Standard_DC8ads_v5' in de DCadsv5-serie
1 De meeste families worden weergegeven met één letter, maar andere, zoals GPU-grootten (ND-series, NV-seriesenzovoort), gebruiken twee.
2 De meeste subfamilies worden weergegeven met één hoofdletter, maar andere (zoals Ebsv5-series) worden nog steeds beschouwd als subfamilies van hun bovenliggende familie vanwege functieverschillen.
3 Als er geen functieletter voor een CPU wordt vermeld, gebruikt de serie Intel x86-64 CPU's. Als de CPU AMD is, wordt deze vermeld als a. Als de CPU arm is (Microsoft Cobalt of Ampere Altra), wordt deze vermeld als p.
4 Er kan een willekeurig aantal extra functies in een groottenaam zijn. Er kunnen geen (Dv5-series) of drie (Dplds_v6-series) zijn.
5 spatiebalken kunnen meerdere keren worden weergegeven in een groottenaam, zoals in de ND_H100_v5-series. In dit geval scheiden ze de GPU-id van de rest van de naam van de grootte.
6 Versienummers worden alleen weergegeven in de groottenaam als er meerdere versies van dezelfde reeks zijn. Als u de eerste versie van een reeks (HB-series, enzovoort) gebruikt, B-serieswordt deze vaak niet opgenomen in de naam van de grootte.
Deze sectie bevat een lijst met alle reeksen huidige generatiegrootten met tabbladen die zijn toegewezen aan elke groottefamilie. Elke groep heeft een kolom Reekslijst met een gekoppelde lijst met alle beschikbare groottereeksen. Deze koppelingen brengen u naar de gezinspagina voor die reeks, waar u gedetailleerde informatie over elke grootte in die reeks kunt vinden of naar de pagina van de reeks gaat voor een lijst met grootten in die reeks.
Als u meer wilt weten over een groottefamilie, klikt u op het tabblad Gezin onder elk typesectie. Daar kunt u een samenvatting van het gezin lezen, de werkbelastingen bekijken waarvoor het wordt aanbevolen en de volledige gezinspagina weergeven met specificaties voor alle reeksen in die familie.
Algemeen gebruik
VM-grootten voor algemeen gebruik bieden een evenwichtige CPU-geheugenverhouding. Dit is ideaal voor testen en ontwikkelen, voor kleine tot middelgrote databases, en webservers met weinig tot gemiddeld verkeer.
De A-serie VM-groottereeksen is een van de VM-exemplaren voor algemeen gebruik van Azure. Ze zijn ontworpen voor workloads op invoerniveau, zoals ontwikkel- en testomgevingen, kleine tot middelgrote databases en webservers met weinig verkeer.
Kostenefficiëntie: VM's uit de A-serie zijn enkele van de meest budgetvriendelijke opties die beschikbaar zijn in Azure, waardoor ze een goede keuze zijn voor projecten met beperkte financiële resources of vm's die geen krachtige rekenmogelijkheden nodig hebben.
Algemene workloads: VM's uit de A-serie zijn zeer geschikt voor het verwerken van basistoepassingen, lichte webservers en kleine databases waarvoor geen uitgebreide CPU-, geheugen- of I/O-prestaties nodig zijn.
Toepassingen op invoerniveau: VM's uit de A-serie kunnen fungeren als een goed uitgangspunt voor het implementeren van toepassingen die naar verwachting niet aanzienlijk worden geschaald. Ze bieden een platform voor toepassingen en services waarvoor minder verwerkingskracht nodig is.
B-gezin
De B-serie VM-groottereeksen is een van de VM-exemplaren voor algemeen gebruik van Azure. Hoewel traditionele virtuele Azure-machines vaste CPU-prestaties bieden, zijn virtuele machines uit de B-serie het enige VM-type dat tegoeden gebruikt voor het inrichten van CPU-prestaties. VM's uit de B-serie maken gebruik van een CPU-tegoedmodel om bij te houden hoeveel CPU wordt verbruikt: de virtuele machine verzamelt CPU-tegoed wanneer een werkbelasting onder de drempelwaarde voor basis-CPU-prestaties werkt en gebruikt tegoeden wanneer deze boven de drempelwaarde voor de basis-CPU-prestaties worden uitgevoerd totdat al het tegoed wordt verbruikt. Bij het verbruik van alle CPU-tegoeden wordt een virtuele machine uit de B-serie teruggeperkeerd naar de basis-CPU-prestaties totdat het tegoed opnieuw wordt verzameld naar CPU-burst.
Flexibiliteit van gebruik: B-serie-VM's zijn het meest geschikt voor workloads die geen constante volledige CPU-prestaties vereisen.
Ideale toepassingen: B-family-VM's zijn ideale toepassingen zijn webservers, proof of concepts, kleine databases en ontwikkelomgevingen.
Prestatiebehoeften: sommige workloads hebben vaak burstable prestatievereisten, wat betekent dat ze slechts sporadisch hoge prestaties nodig hebben. B-family-VM's zijn perfect voor deze use-case.
D-familie
De D-serie VM-grootten is een van de VM-grootten voor algemeen gebruik van Azure. Ze zijn ontworpen voor diverse veeleisende workloads, zoals bedrijfstoepassingen, web- en toepassingsservers, ontwikkel- en testomgevingen en batchverwerkingstaken. Uitgerust met snellere processors en meer geheugen per kern dan de vm's uit de A-serie, bieden VM's uit de D-serie een sterke prestatiebalans, waardoor ze geschikt zijn voor toepassingen die zowel een hoge rekenkracht als aanzienlijke geheugenresources vereisen. Ze zijn met name geschikt voor het uitvoeren van hoogwaardige toepassingen, het ondersteunen van gemiddelde tot hoge verkeerswebservers en het uitvoeren van gegevensintensieve batchverwerking.
Evenwichtige prestaties: VM's uit de D-serie bieden een solide balans tussen CPU-mogelijkheden en geheugengrootte, waardoor ze geschikt zijn voor de meeste productieworkloads. Ze zijn uitgerust met snellere processors vergeleken met de A-serie en bieden meer geheugen per kern.
Bedrijfstoepassingen: ze zijn zeer geschikt voor het uitvoeren van bedrijfstoepassingen zoals SAP, Microsoft Dynamics of grote relationele databases waarvoor zowel een hoge rekenkracht als een aanzienlijk geheugen is vereist.
Ontwikkel- en testomgevingen: Met hun evenwichtige resources zijn VM's uit de D-serie ideaal voor ontwikkel- en testomgevingen waar ontwikkelaars productieomstandigheden nauwkeurig moeten simuleren.
Web- en toepassingsservers: ze bieden de benodigde resources voor het hosten van webservers en toepassingsservers die gemiddeld tot zwaar verkeer ervaren, waardoor soepele en responsieve gebruikerservaringen worden gegarandeerd.
Batchverwerking: VM's uit de D-serie zijn efficiënt voor het verwerken van batchverwerkingstaken waarvoor grote hoeveelheden gegevens snel moeten worden verwerkt, dankzij hun snelle processors en voldoende geheugen.
GamingServers: de krachtige mogelijkheden van vm's uit de D-serie maken ze geschikt voor gamingservers waarbij latentie en snelheid essentieel zijn voor een goede gebruikerservaring.
DC-serie
De serie 'DC' is een van de beveiligingsgerichte VM-exemplaren voor algemeen gebruik van Azure. Ze zijn ontworpen voor confidential computing en bieden verbeterde gegevensbescherming en integriteit met verschillende hardwaregebaseerde Trusted Execution Environments (TEE's). Deze VM's werken goed voor veel algemene rekenworkloads, e-commercesystemen, web-front-ends, bureaubladvirtualisatieoplossingen, gevoelige databases, andere bedrijfstoepassingen en meer.
Gegevensbescherming: VM's uit de DC-serie zijn ideaal voor toepassingen die gevoelige gegevens beheren, opslaan en verwerken, zoals persoonlijke gegevens (PII), financiële gegevens, gezondheidsrecords en andere typen vertrouwelijke informatie. De op hardware gebaseerde versleuteling zorgt ervoor dat gegevens in rust en tijdens de verwerking worden beveiligd.
Naleving van regelgeving: Voor bedrijven die moeten voldoen aan strenge wettelijke vereisten voor gegevensprivacy en -beveiliging (zoals AVG, HIPAA of regelgeving in de financiële sector), bieden VM's uit de DC-serie een omgeving met hardwarezekerheid die kan helpen voldoen aan deze nalevingsvereisten.
Geoptimaliseerde rekenkracht
Voor rekenkracht geoptimaliseerde VM-grootten hebben een hoge CPU-geheugenverhouding. Deze grootten zijn geschikt voor webservers met gemiddeld verkeer, netwerkapparaten, batchprocessen en toepassingsservers.
Als u meer wilt weten over een specifieke groottefamilie of reeks, klikt u op het tabblad voor die familie en bladert u naar de gewenste groottereeks.
F-familie
De 'F'-serie vm-grootte is een van de vm-exemplaren die zijn geoptimaliseerd voor rekenkracht van Azure. Ze zijn ontworpen voor workloads die hoge CPU-prestaties vereisen, zoals batchverwerking, webservers, analyses en gaming. Vm's uit de F-serie hebben een hoge CPU-geheugenverhouding en zijn uitgerust met krachtige processors voor het verwerken van toepassingen die meer CPU-capaciteit vragen ten opzichte van het geheugen. Dit maakt ze met name effectief voor scenario's waarbij snelle en efficiënte verwerking essentieel is, waardoor bedrijven hun rekengebonden toepassingen efficiënt en rendabel kunnen uitvoeren.
Webservers: VM's uit de F-serie zijn uitstekend geschikt voor het hosten van webservers en toepassingen waarvoor een aanzienlijke rekencapaciteit nodig is om webverkeer efficiënt te verwerken zonder dat er grote hoeveelheden geheugen nodig zijn.
Batchverwerking: VM's uit de F-serie zijn ideaal voor batchtaken en andere verwerkingstaken die betrekking hebben op het verwerken van grote hoeveelheden gegevens of taken in een wachtrij, maar die meer CPU-intensief zijn dan geheugenintensief.
Toepassingsservers: toepassingen die snelle verwerking vereisen en geen hoge geheugenvereisten hebben, kunnen profiteren van VM's uit de F-serie. Dit kunnen onder andere toepassingsservers voor gemiddeld verkeer, back-endservers voor bedrijfstoepassingen en andere vergelijkbare taken zijn.
GamingServers: Vanwege hun hoge CPU-prestaties zijn VM's uit de F-serie ook geschikt voor gamingservers waarbij snelle verwerking essentieel is voor een goede gaming-ervaring.
Analyse: VM's uit de F-serie kunnen worden gebruikt voor gegevensanalysetoepassingen waarvoor verwerkingssnelheid nodig is om getallen te kraken en berekeningen meer uit te voeren dan een grote hoeveelheid geheugen nodig is.
FX-familie
De 'FX'-serie VM-grootten is een van de gespecialiseerde VM-exemplaren die zijn geoptimaliseerd voor rekenkracht van Azure, die voornamelijk zijn ontworpen voor workloads waarvoor aanzienlijke CPU-mogelijkheden zijn vereist. Deze VM's maken gebruik van de nieuwste Intel Ice Lake-processors en zijn geoptimaliseerd voor rekenintensieve taken, zoals financiële modellering, wetenschappelijke simulaties en zware berekeningen. Met een hoge frequentie en een grote cache per kern bieden VM's uit de FX-serie uitzonderlijke rekenkracht, waardoor ze ideaal zijn voor scenario's die veel verwerkingsresources eisen en snelle uitvoering van complexe bewerkingen.
Electronic Design Automation (EDA): VM's uit de FX-serie zijn geschikt voor EDA-workloads, waarvoor hoge CPU-kloksnelheden en hoge geheugen-naar-CPU-verhoudingen nodig zijn. Deze workloads profiteren van de hoge prestaties van één kern en een grote geheugencapaciteit van VM's uit de FX-serie.
Batchverwerking: VM's uit de FX-serie zijn uitstekend geschikt voor batchverwerkingstaken met hoge doorvoer, zoals machines met grootschalige gegevensanalyse en -transformatie, waarbij snelle verwerking essentieel is.
Data Analytics: VM's uit de FX-serie zijn geschikt voor intensieve data analytics-toepassingen, met name voor toepassingen die snelle iteratie en verwerking van grote gegevenssets vereisen.
Geoptimaliseerd voor geheugen
Voor geheugen geoptimaliseerde VM-grootten bieden een hoge geheugen-naar-CPU-verhouding die ideaal is voor relationele databaseservers, middelgrote tot grote caches en analyse in het geheugen.
Als u meer wilt weten over een specifieke groottefamilie of reeks, klikt u op het tabblad voor die familie en bladert u naar de gewenste groottereeks.
E-gezin
De serie 'E' van VM-grootten is een van de vm-exemplaren die zijn geoptimaliseerd voor geheugen in Azure. Ze zijn ontworpen voor geheugenintensieve workloads, zoals grote databases, big data-analyses en bedrijfstoepassingen waarvoor aanzienlijke hoeveelheden RAM nodig zijn om hoge prestaties te behouden. Vm's uit de E-serie bieden ondersteuning voor toepassingen en services die profiteren van snellere gegevenstoegang en efficiëntere mogelijkheden voor gegevensverwerking. Dit maakt ze bijzonder geschikt voor scenario's met betrekking tot in-memory databases en uitgebreide gegevensverwerkingstaken waarbij voldoende geheugen cruciaal is voor optimale prestaties.
Geheugenintensieve workloads: E-family-VM's zijn bedoeld voor workloads die een grote geheugenvoetafdruk nodig hebben om taken efficiënt te verwerken, zoals simulaties, grootschalige berekeningen in wetenschappelijk onderzoek of modellering van financiële risico's.
Grote databases en SQL-servers: E-family-VM's zijn ideaal voor het hosten van grote relationele databases, zoals SQL Server- en NoSQL-databases die profiteren van hoge geheugencapaciteiten voor verbeterde prestaties in gegevensverwerking en transactieafhandeling.
Bedrijfstoepassingen: E-family-VM's zijn geschikt voor resource-intensieve bedrijfstoepassingen, waaronder grootschalige ERP- en CRM-systemen, waarbij de beschikbaarheid van voldoende geheugen cruciaal is voor het beheren van complexe transacties en gebruikersbelastingen.
Big Data-toepassingen: E-family-VM's zijn effectief voor big data-analysetoepassingen die grote hoeveelheden gegevens in het geheugen moeten verwerken om de analyse en het genereren van inzichten te versnellen.
In-Memory Computing: E-family-VM's zijn ideaal voor in-memory databases (bijvoorbeeld SAP HANA) waarvoor grote hoeveelheden RAM nodig zijn om de volledige gegevensset in het geheugen te houden, waardoor ultrasnelle gegevensverwerking en queryreacties mogelijk zijn.
Databeheersysteem: E-family-VM's bieden de benodigde resources voor datawarehousingoplossingen die grote gegevenssets verwerken en analyseren, queryprestaties verbeteren en reactietijden verminderen.
Eb-familie
De eb-serie vm-grootte is een van de vm-exemplaren die zijn geoptimaliseerd voor geheugen. Ze zijn ontworpen voor geheugenintensieve workloads met hoge prestaties van externe opslag, zoals grote databases, big data-analyses en bedrijfstoepassingen waarvoor aanzienlijke hoeveelheden RAM nodig zijn om hoge prestaties te behouden. Vm's uit de Eb-serie bieden ondersteuning voor toepassingen en services die profiteren van snellere gegevenstoegang en efficiëntere mogelijkheden voor gegevensverwerking. Dit maakt ze bijzonder geschikt voor scenario's met betrekking tot in-memory databases en uitgebreide gegevensverwerkingstaken waarbij voldoende geheugen cruciaal is voor optimale prestaties.
Geheugenintensieve workloads: Eb-family-VM's zijn bedoeld voor workloads die een grote geheugenvoetafdruk nodig hebben om taken efficiënt te verwerken, zoals simulaties, grootschalige berekeningen in wetenschappelijk onderzoek of modellering van financiële risico's.
Grote databases en SQL-servers: Eb-family-VM's zijn ideaal voor het hosten van grote relationele databases, zoals SQL Server- en NoSQL-databases die profiteren van hoge geheugencapaciteiten voor verbeterde prestaties in gegevensverwerking en transactieafhandeling.
Bedrijfstoepassingen: Eb-family-VM's zijn geschikt voor resource-intensieve bedrijfstoepassingen, waaronder grootschalige ERP- en CRM-systemen, waarbij de beschikbaarheid van voldoende geheugen cruciaal is voor het beheren van complexe transacties en gebruikersbelastingen.
Big Data Applications: Eb-family-VM's zijn effectief voor big data-analysetoepassingen die grote hoeveelheden gegevens in het geheugen moeten verwerken om analyse en inzichten te versnellen.
In-Memory Computing: Eb-family-VM's zijn ideaal voor in-memory databases (bijvoorbeeld SAP HANA) waarvoor grote hoeveelheden RAM nodig zijn om de volledige gegevensset in het geheugen te houden, waardoor ultrasnelle gegevensverwerking en queryreacties mogelijk zijn.
Databeheersysteem: Eb-family-VM's bieden de benodigde resources voor datawarehousingoplossingen die grote gegevenssets verwerken en analyseren, queryprestaties verbeteren en reactietijden verminderen.
EC-familie
De 'EC'-subfamilie van VM-groottereeksen is een van de door het geheugen geoptimaliseerde VM-exemplaren van Azure. Ze zijn ontworpen voor vertrouwelijke computing met verbeterde gegevensbescherming en integriteit, met verschillende hardwaregebaseerde Trusted Execution Environments (TEE's). Deze exemplaren zijn ideaal voor geheugenintensieve workloads, zoals grote databases, big data-analyses en bedrijfstoepassingen waarvoor aanzienlijke hoeveelheden RAM nodig zijn om hoge prestaties te behouden.
Geheugenintensieve workloads: elke workload die een grote geheugenvoetafdruk vereist voor het efficiënt verwerken van taken, zoals simulaties, grootschalige berekeningen in wetenschappelijk onderzoek of modellering van financiële risico's.
Grote databases en SQL-servers: ze zijn ideaal voor het hosten van grote relationele databases, zoals SQL Server- en NoSQL-databases die profiteren van hoge geheugencapaciteiten voor verbeterde prestaties bij gegevensverwerking en transactieafhandeling.
Bedrijfstoepassingen: Geschikt voor resource-intensieve bedrijfstoepassingen, waaronder grootschalige ERP- en CRM-systemen, waarbij de beschikbaarheid van voldoende geheugen cruciaal is voor het beheren van complexe transacties en gebruikersbelastingen.
Big Data-toepassingen: effectief voor big data-analysetoepassingen die grote hoeveelheden gegevens in het geheugen moeten verwerken om het genereren van analyses en inzichten te versnellen.
In-Memory Computing: zoals in-memory databases (bijvoorbeeld SAP HANA) waarvoor grote hoeveelheden RAM nodig zijn om de volledige gegevensset in het geheugen te houden, waardoor ultrasnelle gegevensverwerking en queryreacties mogelijk zijn.
Databeheersysteem: Biedt de benodigde resources voor datawarehousingoplossingen die grote gegevenssets verwerken en analyseren, queryprestaties verbeteren en reactietijden verminderen.
M-familie
De 'M'-serie vm-grootte is een van de voor ultrageheugen geoptimaliseerde VM-exemplaren van Azure die zijn ontworpen voor extreem geheugenintensieve workloads, zoals grote in-memory databases, datawarehousing en HPC (High Performance Computing). Uitgerust met aanzienlijke RAM-capaciteiten en hoge vCPU-mogelijkheden, ondersteunen de M-family-VM's toepassingen en services die enorme hoeveelheden geheugen en aanzienlijke rekenkracht vereisen. Hoge resourcetoewijzing maakt de M-serie bijzonder geschikt voor het verwerken van taken zoals zware SQL Server- en andere RDBMS-workloads, complexe wetenschappelijke simulaties, realtime gegevensverwerking en grootschalige ERP-systemen (Enterprise Resource Planning), waardoor piekprestaties worden gegarandeerd voor de meest veeleisende gegevensgerichte toepassingen.
SQL Server-workloads met hoge geheugenbehoeften: de M-serie is met name effectief voor het uitvoeren van SQL Server-machines met hoge geheugenvereisten, zoals voor online transactieverwerking (OLTP) of gegevensanalyse.
In-memory databases: de M-serie is met name effectief voor het uitvoeren van in-memory databases waarvoor grote hoeveelheden RAM-geheugen nodig zijn, zoals SQL Server of SAP HANA.
Big data-toepassingen: de M-serie is ideaal voor het verwerken van big data-toepassingen die enorme gegevenssets in het geheugen moeten verwerken en analyseren, de prestaties verbeteren en de tijd tot inzichten verminderen.
Datawarehousing: VM's uit de M-serie bieden de prestaties en het geheugen die nodig zijn voor datawarehousingtoepassingen , waardoor snellere query's en betere verwerking van grote hoeveelheden gegevens worden vergemakkelijkt.
Bedrijfstoepassingen: De M-serie ondersteunt grootschalige bedrijfstoepassingen, waaronder ERP- en CRM-systemen, die profiteren van meer geheugen om grotere gegevenssets en complexere transacties efficiënt te beheren.
Zware workloads in gevirtualiseerde omgevingen: de M-serie is goed uitgerust voor het verwerken van zware gevirtualiseerde omgevingen, met aanzienlijk geheugen voor het hosten van meerdere virtuele machines en toepassingen op één fysieke server.
Geoptimaliseerd voor opslag
Voor opslag geoptimaliseerde VM-grootten bieden hoge schijfdoorvoer en IO en zijn ideaal voor Big Data, SQL, NoSQL-databases, datawarehousing en grote transactionele databases. Voorbeelden hiervan zijn Cassandra, MongoDB, Cloudera en Redis.
Als u meer wilt weten over een specifieke groottefamilie of reeks, klikt u op het tabblad voor die familie en bladert u naar de gewenste groottereeks.
L familie
De serie 'L' van VM-grootten is een van de voor opslag geoptimaliseerde VM-exemplaren van Azure. Ze zijn ontworpen voor workloads die hoge schijfdoorvoer en I/O vereisen, zoals databases, big data-toepassingen en datawarehousing. Vm's uit de L-serie bieden ondersteuning voor toepassingen en services die profiteren van lage latentie en hoge lees- en schrijfsnelheden. Hierdoor zijn ze bijzonder geschikt voor het verwerken van taken zoals grootschalige logboekverwerking, realtime big data-analyses en scenario's met betrekking tot grote databases die frequente schijfbewerkingen uitvoeren, waardoor efficiënte prestaties voor toepassingen met veel opslag worden gegarandeerd.
Big Data-toepassingen: VM's uit de L-serie zijn perfect voor big data-toepassingen die grote gegevenssets moeten verwerken, analyseren en manipuleren die rechtstreeks op lokale schijven zijn opgeslagen, en die profiteren van de hoge I/O-prestaties.
Databaseservers: VM's uit de L-serie bieden de benodigde lokale schijfprestaties voor SQL Server, MySQL, PostgreSQL en andere databaseservers die profiteren van snelle toegang tot schijfopslag.
Bestandsservers: VM's van de L-serie kunnen effectief worden gebruikt als bestandsservers binnen een netwerk, het verwerken van grote bestanden en het leveren van grote doorvoer, met name handig in omgevingen met grote mediabestanden.
Videobewerking en rendering: de hoge schijfdoorvoer en -capaciteit van VM's uit de L-serie zijn nuttig voor videobewerkings- en renderingtaken, waarbij grote videobestanden regelmatig worden gelezen en naar schijf worden geschreven.
GPU versneld
VM-grootten die zijn geoptimaliseerd voor GPU zijn gespecialiseerde virtuele machines die beschikbaar zijn met gpu's met één, meerdere of fractionele GPU's. Deze grootten zijn ontworpen voor rekenintensieve, grafische en visualisatieworkloads.
Als u meer wilt weten over een specifieke groottefamilie of reeks, klikt u op het tabblad voor die familie en bladert u naar de gewenste groottereeks.
NC-familie
De subfamilie NC van vm-groottereeksen is een van de VOOR GPU geoptimaliseerde VM-exemplaren van Azure. Ze zijn ontworpen voor rekenintensieve workloads, zoals ai- en machine learning-modeltraining, high-performance computing (HPC) en grafisch-intensieve toepassingen. Vm's uit de NC-serie zijn uitgerust met krachtige NVIDIA GPU's en bieden aanzienlijke versnelling voor processen waarvoor zware rekenkracht is vereist, waaronder deep learning, wetenschappelijke simulaties en 3D-rendering. Dit maakt ze bijzonder geschikt voor industrieën zoals technologieonderzoek, entertainment en engineering, waarbij rendering- en verwerkingssnelheid essentieel zijn voor productiviteit en innovatie.
AI en Machine Learning: VM's uit de NC-serie zijn ideaal voor het trainen van complexe machine learning-modellen en het uitvoeren van AI-toepassingen. De NVIDIA GPU's bieden aanzienlijke versnelling voor berekeningen die doorgaans betrokken zijn bij deep learning en andere intensieve trainingstaken.
HPC (High Performance Computing): deze VM's zijn geschikt voor wetenschappelijke simulaties, rendering en andere HPC-workloads die kunnen worden versneld door GPU's. Velden zoals engineering, medisch onderzoek en financiële modellering gebruiken vaak VM's uit de NC-serie om hun rekenbehoeften efficiënt af te handelen.
Graphics Rendering: VM's uit de NC-serie worden ook gebruikt voor grafisch-intensieve toepassingen, waaronder videobewerking, 3D-rendering en realtime grafische verwerking. Ze zijn vooral nuttig in branches zoals gameontwikkeling en filmproductie.
Externe visualisatie: Voor toepassingen waarvoor geavanceerde visualisatiemogelijkheden zijn vereist, zoals CAD- en visuele effecten, kunnen VM's uit de NC-serie de benodigde GPU-kracht op afstand leveren, zodat gebruikers aan complexe grafische taken kunnen werken zonder krachtige lokale hardware nodig te hebben.
Simulatie en analyse: Deze VM's zijn ook geschikt voor gedetailleerde simulaties en analyses op gebieden zoals autocrashtests, rekenkundige vloeistofdynamica en weermodellering, waarbij GPU-mogelijkheden de verwerkingstijden aanzienlijk kunnen versnellen.
ND-familie
De 'ND'-serie VM-grootte is een van de MET GPU versnelde VM-exemplaren van Azure. Ze zijn ontworpen voor deep learning, AI-onderzoek en high-performance computingtaken die profiteren van krachtige GPU-versnelling. Vm's uit de ND-serie zijn uitgerust met NVIDIA GPU's en bieden gespecialiseerde mogelijkheden voor training en deductie van complexe machine learning-modellen, waardoor snellere berekeningen en efficiënte verwerking van grote gegevenssets worden vergemakkelijkt. Dit maakt ze bijzonder geschikt voor academische en commerciële toepassingen in AI-ontwikkeling en -simulatie, waarbij geavanceerde GPU-technologie cruciaal is voor het bereiken van snelle en nauwkeurige resultaten in neurale netwerkverwerking en andere rekenintensieve taken.
AI en Deep Learning: VM's uit de ND-serie zijn ideaal voor het trainen en implementeren van complexe Deep Learning-modellen. Uitgerust met krachtige NVIDIA GPU's bieden ze de rekenkracht die nodig is voor het verwerken van uitgebreide neurale netwerktraining met grote gegevenssets, waardoor de trainingstijden aanzienlijk worden verminderd.
High Performance Computing (HPC): VM's uit de ND-serie zijn geschikt voor HPC-toepassingen waarvoor GPU-versnelling is vereist. Velden zoals wetenschappelijk onderzoek, technische simulaties (bijvoorbeeld rekenkundige vloeistofdynamiek) en genomische verwerking kunnen profiteren van de rekenmogelijkheden met hoge doorvoer van VM's uit de ND-serie.
NG-familie
De 'NG'-serie VM-grootten is een van de VOOR GPU geoptimaliseerde VM-exemplaren van Azure, speciaal ontworpen voor cloud gaming en extern bureaublad-toepassingen. Ze maken gebruik van krachtige AMD Amd Pro™ GPU's om hoogwaardige, interactieve gaming-ervaringen in de cloud te leveren, geoptimaliseerd voor het weergeven van complexe graphics en het streamen van high-definition video. Dit zorgt ervoor dat gamers genieten van een naadloze, responsieve gamingomgeving die toegankelijk is vanaf elk apparaat. Daarnaast bieden VM's uit de NG-serie een hoogwaardige, responsieve extern bureaublad-ervaring, waardoor ze ideaal zijn voor gebruikers die betrouwbare, krachtige toegang tot bureaubladtoepassingen overal ter wereld nodig hebben.
Cloud Gaming: NG-family-VM's maken gebruik van krachtige AMD Intune™ PRO GPU's om hoogwaardige, interactieve game-ervaringen in de cloud te bieden.
Remote Destkop: VM's van de NG-familie kunnen worden gebruikt voor extern bureaublad-toepassingen, zodat gebruikers een hoogwaardige, responsieve gebruikerservaring hebben.
NV-familie
De 'NV'-serie vm-grootte is een van de GPU-versnelde VM-exemplaren van Azure, speciaal ontworpen voor grafische intensieve toepassingen, zoals grafische rendering, simulatie en virtuele bureaubladen. Vm's uit de NV-serie zijn uitgerust met NVIDIA GPU's en bieden een robuust platform voor het weergeven en verwerken van zware grafische taken, waardoor ze ideaal zijn voor organisaties die virtuele werkstations met krachtige grafische mogelijkheden nodig hebben. Deze VM's ondersteunen scenario's waarbij externe visualisatie, realtime samenwerking en 3D-visualisatie nodig zijn, zodat gebruikers grafische intensieve toepassingen rechtstreeks vanuit de cloudomgeving van Azure kunnen uitvoeren.
Virtual Desktop Infrastructure (VDI): VM's van de NV-serie zijn geschikt voor virtuele bureaubladen waarvoor GPU-mogelijkheden zijn vereist voor taken zoals grafisch ontwerp, videobewerking en CAD-toepassingen. Ze bieden de grafische prestaties die nodig zijn voor een soepele werking in scenario's met extern bureaublad.
3D-visualisatie: VM's uit de NV-serie zijn ideaal voor het uitvoeren van 3D-toepassingen waarvoor high performance rendering is nodig, zoals architectuurvisualisaties, medische imaging en andere professionele grafische taken.
Remote Graphics Work: VM's uit de NV-serie zijn gunstig voor branches die afhankelijk zijn van grafisch-intensieve software, zodat professionals toepassingen zoals Adobe Photoshop, Autodesk AutoCAD of Dassault SOLIDWORKS op afstand kunnen gebruiken met bijna systeemeigen prestaties.
High-Resolution Image Processing: VM's uit de NV-serie zijn ideaal voor het verwerken van extreem grote vRAM-toepassingen, zoals afbeeldingsverwerking en -analyse met hoge resolutie. Dit omvat taken in velden zoals georuimtelijke analyse, satellietafbeeldingsverwerking en professionele fotobewerking, waarbij het verwerken van enorme afbeeldingsbestanden en het uitvoeren van complexe manipulaties in realtime cruciaal zijn voor productiviteit en prestaties.
Videostreaming: VM's van de NV-serie zijn geschikt voor het streamen van video-inhoud met hoge resolutie, waaronder trainingsvideo's en virtuele gebeurtenissen, waardoor levering van hoge kwaliteit zonder lokale hardwarebeperkingen mogelijk is.
FPGA versneld
FPGA geoptimaliseerde VM-grootten zijn gespecialiseerde virtuele machines die beschikbaar zijn met één of meerdere FPGA's. Deze grootten zijn ontworpen voor rekenintensieve workloads. Dit artikel bevat informatie over het aantal en het type FPGA's, vCPU's, gegevensschijven en NIC's. Opslagdoorvoer en netwerkbandbreedte worden ook opgenomen voor elke grootte in deze groepering.
Als u meer wilt weten over een specifieke groottefamilie of reeks, klikt u op het tabblad voor die familie en bladert u naar de gewenste groottereeks.
NP-familie
De subfamilie NP van vm-groottereeksen is een van de voor opslag geoptimaliseerde VM-exemplaren van Azure. Ze zijn ontworpen voor workloads die hoge schijfdoorvoer en I/O vereisen, zoals databases, big data-toepassingen en datawarehousing. Hoge schijfdoorvoer en grote lokale schijfopslagcapaciteiten op VM's uit de L-serie ondersteunen toepassingen en services die profiteren van lage latentie en hoge sequentiële lees- en schrijfsnelheden. Hierdoor zijn ze zeer geschikt voor het verwerken van taken zoals grootschalige logboekverwerking, realtime big data-analyses en scenario's met betrekking tot grote databases die frequente schijfbewerkingen uitvoeren, waardoor efficiënte prestaties voor toepassingen met veel opslag worden gegarandeerd.
Realtime gegevensverwerking: NP-familie-VM's excelleren in omgevingen waarin gegevens in realtime moeten worden verwerkt met minimale latentie, zoals in financiële handel, realtime analyses en netwerkgegevensverwerking.
Aangepaste AI en Machine Learning: NP-serie-VM's zijn geschikt voor het versnellen van AI- en machine learning-deductietaken, waarbij de FPGA kan worden geprogrammeerd om specifieke algoritmen soms sneller uit te voeren dan typische CPU- of GPU-oplossingen.
Genomics en Life Sciences: NP-family VM's kunnen genomische sequentiële taken en andere life sciences-toepassingen die profiteren van aangepaste hardwareversnelling aanzienlijk versnellen.
Videotranscodering en -streaming: FPGA's kunnen worden gebruikt om videoverwerkingstaken zoals transcodering en realtime videostreaming te versnellen, prestaties te optimaliseren en verwerkingstijden te verminderen.
Signaalverwerking: NP-serie VM's zijn ideaal voor toepassingen in telecommunicatie en signaalverwerking waarbij snelle manipulatie en analyse van signalen noodzakelijk zijn.
Databaseversnelling: NP-familie-VM's kunnen databasebewerkingen verbeteren, met name voor aangepaste zoekbewerkingen en grootschalige databasequery's, door deze taken naar de FPGA te offloaden.
Krachtig rekenvermogen
Azure High Performance Compute-VM's zijn geoptimaliseerd voor verschillende HPC-workloads, zoals rekenkundige vloeistofdynamiek, analyse van eindige elementen, front-end- en back-end-EDA, rendering, moleculaire dynamiek, rekenkundige geowetenschappen, weersimulatie en financiële risicoanalyse.
Als u meer wilt weten over een specifieke groottefamilie of reeks, klikt u op het tabblad voor die familie en bladert u naar de gewenste groottereeks.
De 'HB'-subfamilie van vm-groottereeksen is een van de HPC-exemplaren (High Performance Computing) van Azure. Ze zijn ontworpen voor rekenintensieve workloads, zoals rekenkundige vloeistofdynamiek, analyse van eindige elementen en grootschalige wetenschappelijke simulaties. Krachtige AMD EPYC-processors en snel geheugen op VM's uit de HB-serie bieden uitzonderlijke CPU- en geheugenbandbreedte, waardoor ze ideaal zijn voor toepassingen waarvoor uitgebreide rekenbronnen nodig zijn om grootschalige berekeningen en gegevensverwerking uit te voeren. Dit maakt ze zeer geschikt voor branches zoals engineering, wetenschappelijk onderzoek en gegevensanalyse, waarbij verwerkingssnelheid en nauwkeurigheid essentieel zijn voor productiviteit en innovatie.
Computational Fluid Dynamics (CFD): HB-family VM's zijn ideaal voor simulaties in velden zoals lucht- en ruimtevaart, automobielontwerp en productie, waarbij vloeistofdynamische berekeningen intensief zijn.
Eindige elementanalyse (FEA): VM's uit de HB-serie zijn geschikt voor technische analyses die fysieke verschijnselen simuleren, waarvoor intensieve rekenkracht nodig is om complexe systemen en materialen te modelleren.
Weersvoorspelling: VM's uit de HB-serie kunnen de enorme gegevenssets en complexe simulaties verwerken die nodig zijn voor het modelleren en voorspellen van hoge resolutie.
Seismic Processing: Wordt gebruikt in de olie- en gasindustrie, HB-serie VM's kunnen seismische gegevens verwerken om te helpen bij het toewijzen en begrijpen van ondergrondse structuren.
Wetenschappelijk onderzoek: HB-serie VM's ondersteunen een breed scala aan wetenschappelijk onderzoek dat grootschalige wiskundige modellering vereist, waaronder fysica- en rekenkundige chemiesimulaties.
Genomics en Bioinformatics: HB-family VM's worden ook gebruikt in levenswetenschappen voor genomische analyse, waarbij grote hoeveelheden gegevens snel moeten worden verwerkt om genetische informatie te decoderen.
De 'HC'-serie van VM-groottereeksen is een van de voor HPC geoptimaliseerde VM-exemplaren van Azure (High Performance Computing). Ze zijn ontworpen voor rekenintensieve workloads waarvoor aanzienlijke CPU-kracht is vereist, zoals genomische sequencing, technische simulaties en financiële modellering. Krachtige Intel Xeon Scalable-processors en snel geheugen op VM's uit de HC-serie bieden uitzonderlijke rekenmogelijkheden en geheugenbandbreedte, waardoor ze ideaal zijn voor toepassingen die intensieve verwerkingskracht vereisen voor het efficiënt verwerken van complexe berekeningen en enorme gegevenssets. Deze VM's zijn ontworpen voor sectoren zoals gezondheidszorg, financiën en engineering, waarbij snelle gegevensverwerking en simulatiennauwkeurigheid essentieel zijn voor geavanceerd onderzoek en ontwikkeling.
Genomic Sequencing: VM's uit de HC-serie bieden de rekenkracht die nodig is voor genomische sequencing, waardoor onderzoekers grote genetische gegevenssets snel kunnen verwerken en analyseren.
Technische simulaties: Ideaal voor het uitvoeren van complexe simulaties op gebieden zoals automotive, luchtvaart- en werktuigbouwkunde. Deze simulaties omvatten vaak eindige elementanalyse (FEA) en computational fluid dynamics (CFD).
Financiële modellering: deze VM's kunnen de hoge eisen van financiële toepassingen afhandelen, waaronder risicoanalyse en kwantitatieve simulaties, waarvoor enorme rekenbronnen nodig zijn om snel veel berekeningen uit te voeren.
Wetenschappelijk onderzoek: VM's uit de HC-serie ondersteunen een breed scala aan wetenschappelijke computingbehoeften, met name in natuurkunde en chemie, waarbij grootschalige berekeningen en gegevensanalyse cruciaal zijn.
Weersvoorspelling en klimaatsimulatie: ze worden gebruikt in meteorologie voor het modelleren van hoge resolutie en klimaatsimulaties, waarvoor grote gegevenssets moeten worden verwerkt en complexe simulaties moeten worden uitgevoerd.
De HX-serie vm-grootten is een van de voor HPC geoptimaliseerde VM-exemplaren (High-Performance Computing) van Azure. Ze zijn ontworpen voor geheugenintensieve workloads waarvoor zowel grote hoeveelheden RAM-geheugen als aanzienlijke CPU-prestaties nodig zijn, zoals in-memory databases, big data-analyses en complexe wetenschappelijke simulaties. Uitgebreid geheugen en krachtige CPU's op VM's uit de HX-serie bieden de benodigde resources voor het efficiënt verwerken van grote gegevenssets en het uitvoeren van snelle gegevensverwerking. Deze VM's zijn ontworpen voor sectoren zoals financiële diensten, wetenschappelijk onderzoek en bedrijfsresourceplanning, waarbij het beheren en analyseren van grote hoeveelheden gegevens in realtime cruciaal is voor operationeel succes en innovatie.
In-Memory Databases: VM's uit de HX-serie zijn uitstekend geschikt voor het hosten van in-memory databases, waarvoor uitgebreid geheugen nodig is om grote gegevenssets in RAM te onderhouden voor ultrasnelle verwerking en toegang.
Big Data Analytics: ze kunnen big data-analysetoepassingen verwerken die grote hoeveelheden gegevens in het geheugen moeten verwerken om de analyse te versnellen, wat essentieel is voor realtime besluitvorming.
Genomisch onderzoek: Genomics-onderzoek omvat vaak grootschalige gegevensanalyse, waarbij een hoge geheugencapaciteit de prestaties aanzienlijk kan verbeteren door meer van de gegevensset in het geheugen te houden, waardoor de analyse sneller wordt uitgevoerd.
Financiële simulaties: Financiële instellingen gebruiken VM's uit de HX-serie voor high-frequency trading platforms en risicobeheersimulaties waarvoor snelle verwerking van grote gegevensvolumes nodig is om voorraadtrends te voorspellen of kredietrisico's in realtime te berekenen.
ERP-systemen: ERP-systemen (Large Enterprise Resource Planning) profiteren van de hoge geheugen- en verwerkingskracht van VM's uit de HX-serie om uitgebreide bedrijfsgegevens te beheren en te verwerken en grote aantallen gelijktijdige gebruikers effectief te ondersteunen.
Inhoud van platformgrootten leren
Zie de pagina's met prijzen voor Linux of Windows voor informatie over prijzen van de verschillende grootten.

 1 De meeste families worden weergegeven met één letter, maar andere, zoals GPU-grootten (
1 De meeste families worden weergegeven met één letter, maar andere, zoals GPU-grootten (