BI-oplossingsarchitectuur in het Center of Excellence
Dit artikel is gericht op IT-professionals en IT-managers. U leert meer over BI-oplossingsarchitectuur in de COE en de verschillende technologieën die worden gebruikt. Technologieën zijn onder andere Azure, Power BI en Excel. Samen kunnen ze worden gebruikt om een schaalbaar en gegevensgestuurd cloud BI-platform te leveren.
Het ontwerpen van een robuust BI-platform lijkt enigszins op het bouwen van een brug; een brug die getransformeerde en verrijkte brongegevens verbindt met gegevensgebruikers. Het ontwerp van een dergelijke complexe structuur vereist een technische mindset, hoewel het een van de meest creatieve en belonende IT-architecturen kan zijn die u kunt ontwerpen. In een grote organisatie kan een BI-oplossingsarchitectuur bestaan uit:
- Gegevensbronnen
- Gegevensopname
- Big data/data-voorbereiding
- Datawarehouse
- Semantische BI-modellen
- Rapporten
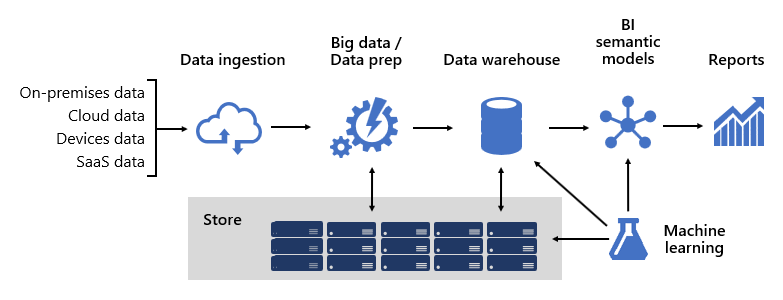
Het platform moet specifieke vereisten ondersteunen. Het moet met name worden geschaald en uitgevoerd om te voldoen aan de verwachtingen van zakelijke services en gegevensgebruikers. Tegelijkertijd moet het vanaf de grond veilig zijn. En het moet voldoende tolerant zijn om zich aan te passen aan verandering, omdat het een zekerheid is dat nieuwe gegevens en onderwerpen op tijd online moeten worden gebracht.
Frameworks
Bij Microsoft hebben we vanaf het begin een systeemachtige benadering aangenomen door te investeren in frameworkontwikkeling. Technische en bedrijfsprocesframeworks vergroten het hergebruik van ontwerp en logica en bieden een consistent resultaat. Ze bieden ook flexibiliteit in architectuur die gebruikmaakt van veel technologieën en ze stroomlijnen en verminderen technische overhead via herhaalbare processen.
We hebben geleerd dat goed ontworpen frameworks de zichtbaarheid vergroten van gegevensherkomst, impactanalyse, onderhoud van bedrijfslogica, het beheren van taxonomie en stroomlijning van governance. Ook werd de ontwikkeling sneller en werd de samenwerking tussen grote teams responsiever en effectiever.
In dit artikel wordt een aantal van onze frameworks beschreven.
Gegevensmodellen
Gegevensmodellen bieden u controle over de structuur en toegang tot gegevens. Voor zakelijke services en gegevensgebruikers zijn gegevensmodellen hun interface met het BI-platform.
Een BI-platform kan drie verschillende typen modellen leveren:
- Bedrijfsmodellen
- Semantische BI-modellen
- Machine Learning-modellen (ML)
Bedrijfsmodellen
Bedrijfsmodellen worden gebouwd en onderhouden door IT-architecten. Ze worden soms dimensionale modellen of datamarts genoemd. Gegevens worden doorgaans opgeslagen in relationele indeling als dimensie- en feitentabellen. In deze tabellen worden opgeschoonde en verrijkte gegevens van veel systemen opgeslagen en ze vertegenwoordigen een gezaghebbende bron voor rapportage en analyse.
Bedrijfsmodellen bieden een consistente en één gegevensbron voor rapportage en BI. Ze worden eenmaal gebouwd en gedeeld als bedrijfsstandaard. Governancebeleid zorgt ervoor dat gegevens veilig zijn, dus toegang tot gevoelige gegevenssets, zoals klantgegevens of financiële gegevens, wordt beperkt op basis van behoeften. Ze nemen naamconventies aan die consistentie garanderen, waardoor de geloofwaardigheid van gegevens en kwaliteit verder wordt vastgesteld.
In een cloud BI-platform kunnen bedrijfsmodellen worden geïmplementeerd in een Synapse SQL-pool in Azure Synapse. De Synapse SQL-pool wordt vervolgens de enige versie van waarheid waarop de organisatie kan rekenen voor snelle en robuuste inzichten.
Semantische BI-modellen
Semantische BI-modellen vertegenwoordigen een semantische laag ten opzichte van bedrijfsmodellen. Ze worden gebouwd en onderhouden door BI-ontwikkelaars en zakelijke gebruikers. BI-ontwikkelaars maken kern-Semantische BI-modellen die gegevens uit bedrijfsmodellen ophalen. Zakelijke gebruikers kunnen kleinere, onafhankelijke modellen maken of kern-semantische BI-modellen uitbreiden met afdelings- of externe bronnen. Semantische BI-modellen richten zich meestal op één onderwerpgebied en worden vaak op grote schaal gedeeld.
Bedrijfsmogelijkheden worden niet alleen ingeschakeld door gegevens, maar door semantische BI-modellen die concepten, relaties, regels en standaarden beschrijven. Op deze manier vertegenwoordigen ze intuïtieve en eenvoudig te begrijpen structuren die gegevensrelaties definiëren en bedrijfsregels inkapselen als berekeningen. Ze kunnen ook verfijnde gegevensmachtigingen afdwingen, zodat de juiste personen toegang hebben tot de juiste gegevens. Belangrijk is dat ze de prestaties van query's versnellen en uiterst responsieve interactieve analyses bieden, zelfs over terabytes aan gegevens. Net als bij bedrijfsmodellen gebruiken semantische BI-modellen naamconventies die consistentie garanderen.
In een cloud BI-platform kunnen BI-ontwikkelaars semantische BI-modellen implementeren in Azure Analysis Services, Power BI Premium-capaciteiten van Microsoft Fabric-capaciteiten.
Belangrijk
Soms verwijst dit artikel naar Power BI Premium of de capaciteitsabonnementen (P-SKU's). Houd er rekening mee dat Microsoft momenteel aankoopopties consolideert en de Power BI Premium-SKU's per capaciteit buiten gebruik stelt. Nieuwe en bestaande klanten moeten overwegen om in plaats daarvan F-SKU's (Fabric-capaciteitsabonnementen) aan te schaffen.
Zie Belangrijke update voor Power BI Premium-licenties en veelgestelde vragen over Power BI Premium voor meer informatie.
U wordt aangeraden te implementeren in Power BI wanneer deze wordt gebruikt als uw rapportage- en analyselaag. Deze producten ondersteunen verschillende opslagmodi, waardoor tabellen in gegevensmodellen hun gegevens in de cache kunnen opslaan of DirectQuery kunnen gebruiken. Dit is een technologie die query's doorgeeft aan de onderliggende gegevensbron. DirectQuery is een ideale opslagmodus wanneer modeltabellen grote gegevensvolumes vertegenwoordigen of als er bijna realtime resultaten moeten worden geleverd. De twee opslagmodi kunnen worden gecombineerd: samengestelde modellen combineren tabellen die gebruikmaken van verschillende opslagmodi in één model.
Voor sterk opgevraagde modellen kan Azure Load Balancer worden gebruikt om de querybelasting gelijkmatig over modelreplica's te verdelen. Hiermee kunt u ook uw toepassingen schalen en maximaal beschikbare Semantische BI-modellen maken.
Machine Learning-modellen
Machine Learning-modellen (ML) worden gebouwd en onderhouden door gegevenswetenschappers. Ze zijn voornamelijk ontwikkeld op basis van onbewerkte bronnen in de data lake.
Getrainde ML-modellen kunnen patronen in uw gegevens onthullen. In veel gevallen kunnen deze patronen worden gebruikt om voorspellingen te doen die kunnen worden gebruikt om gegevens te verrijken. Aankoopgedrag kan bijvoorbeeld worden gebruikt om klantverloop of segmentklanten te voorspellen. Voorspellingsresultaten kunnen worden toegevoegd aan bedrijfsmodellen om analyse per klantsegment mogelijk te maken.
In een cloud BI-platform kunt u Azure Machine Learning gebruiken om ML-modellen te trainen, implementeren, automatiseren, beheren en bij te houden.
Datawarehouse
De kern van een BI-platform is het datawarehouse, dat als host fungeert voor uw bedrijfsmodellen. Het is een bron van opgegeven gegevens, als een recordsysteem en als hub, die bedrijfsmodellen voor rapportage, BI en gegevenswetenschap biedt.
Veel zakelijke services, waaronder LOB-toepassingen (Line-Of-Business), kunnen afhankelijk zijn van het datawarehouse als gezaghebbende en beheerde bron van bedrijfskennis.
Bij Microsoft wordt ons datawarehouse gehost in Azure Data Lake Storage Gen2 (ADLS Gen2 ) en Azure Synapse Analytics.
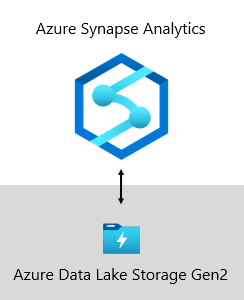
- ADLS Gen2 maakt Azure Storage de basis voor het bouwen van zakelijke data lakes in Azure. Het is ontworpen om meerdere petabytes aan informatie te gebruiken terwijl honderden gigabits aan doorvoer worden ondersteund. En het biedt goedkope opslagcapaciteit en transacties. Bovendien biedt het ondersteuning voor hadoop-compatibele toegang, waarmee u gegevens kunt beheren en openen, net zoals u zou doen met een Hadoop Distributed File System (HDFS). Azure HDInsight, Azure Databricks en Azure Synapse Analytics hebben in feite toegang tot gegevens die zijn opgeslagen in ADLS Gen2. In een BI-platform is het dus een goede keuze om onbewerkte brongegevens, semi-verwerkte of gefaseerde gegevens en productieklare gegevens op te slaan. We gebruiken het om al onze bedrijfsgegevens op te slaan.
- Azure Synapse Analytics is een analyseservice die zakelijke datawarehousing en big data-analyses combineert. Deze geeft u de vrijheid om op schaal gegevens op te vragen over uw voorwaarden, met behulp van serverloze on-demand of ingerichte resources. Synapse SQL, een onderdeel van Azure Synapse Analytics, biedt ondersteuning voor volledige analyse op basis van T-SQL. Het is dus ideaal om bedrijfsmodellen te hosten die bestaan uit uw dimensie- en feitentabellen. Tabellen kunnen efficiënt worden geladen vanuit ADLS Gen2 met behulp van eenvoudige Polybase T-SQL-query's . Vervolgens beschikt u over de kracht van MPP om analyses met hoge prestaties uit te voeren.
Framework voor de engine voor bedrijfsregels
We hebben een BRE-framework (Business Rules Engine ) ontwikkeld om elke bedrijfslogica te catalogiseren die in de datawarehouselaag kan worden geïmplementeerd. Een BRE kan veel dingen betekenen, maar in de context van een datawarehouse is het handig voor het maken van berekende kolommen in relationele tabellen. Deze berekende kolommen worden meestal weergegeven als wiskundige berekeningen of expressies met behulp van voorwaardelijke instructies.
De bedoeling is om bedrijfslogica te splitsen op basis van BI-kerncode. Normaal gesproken worden bedrijfsregels vastgelegd in opGESLAGEN SQL-procedures, waardoor het vaak veel moeite kost om ze te onderhouden wanneer de bedrijfsbehoeften veranderen. In een BRE worden bedrijfsregels eenmaal gedefinieerd en meerdere keren gebruikt wanneer ze worden toegepast op verschillende datawarehouse-entiteiten. Als de berekeningslogica moet worden gewijzigd, hoeft deze slechts op één plaats en niet in talloze opgeslagen procedures te worden bijgewerkt. Er is ook een voordeel: een BRE-framework stimuleert transparantie en zichtbaarheid in geïmplementeerde bedrijfslogica, die kan worden weergegeven via een set rapporten die zelf bijwerkende documentatie maken.
Gegevensbronnen
Een datawarehouse kan gegevens uit vrijwel elke gegevensbron consolideren. Het is voornamelijk gebaseerd op LOB-gegevensbronnen, die vaak relationele databases zijn waarin onderwerpspecifieke gegevens worden opgeslagen voor verkoop, marketing, financiën, enzovoort. Deze databases kunnen worden gehost in de cloud of ze kunnen zich on-premises bevinden. Andere gegevensbronnen kunnen op bestanden zijn gebaseerd, met name weblogboeken of IOT-gegevens die afkomstig zijn van apparaten. Bovendien kunnen gegevens worden opgehaald uit SaaS-leveranciers (Software-as-a-Service).
Bij Microsoft leveren sommige van onze interne systemen operationele gegevens rechtstreeks naar ADLS Gen2 met behulp van onbewerkte bestandsindelingen. Naast onze Data Lake bestaan andere bronsystemen uit relationele LOB-toepassingen, Excel-werkmappen, andere bronnen op basis van bestanden en MDM (Master Gegevensbeheer) en aangepaste gegevensopslagplaatsen. Met MDM-opslagplaatsen kunnen we onze hoofdgegevens beheren om gezaghebbende, gestandaardiseerde en gevalideerde versies van gegevens te garanderen.
Gegevensopname
Op periodieke basis en volgens de ritmes van het bedrijf worden gegevens opgenomen uit bronsystemen en in het datawarehouse geladen. Het kan één keer per dag of met frequentere intervallen zijn. Gegevensopname houdt zich bezig met het extraheren, transformeren en laden van gegevens. Of misschien andersom: gegevens extraheren, laden en vervolgens transformeren. Het verschil komt neer op waar de transformatie plaatsvindt. Transformaties worden toegepast om gegevens op te schonen, te conformeren, te integreren en te standaardiseren. Zie ETL (Extraheren, transformeren en laden) voor meer informatie.
Uiteindelijk is het doel om de juiste gegevens zo snel en efficiënt mogelijk in uw bedrijfsmodel te laden.
Bij Microsoft gebruiken we Azure Data Factory (ADF). De services worden gebruikt voor het plannen en organiseren van gegevensvalidaties, transformaties en bulksgewijs laden van externe bronsystemen in onze data lake. Het wordt beheerd door aangepaste frameworks om gegevens parallel en op schaal te verwerken. Daarnaast wordt uitgebreide logboekregistratie uitgevoerd ter ondersteuning van probleemoplossing, prestatiebewaking en het activeren van waarschuwingsmeldingen wanneer aan specifieke voorwaarden wordt voldaan.
Ondertussen voert Azure Databricks, een op Apache Spark gebaseerd analyseplatform dat is geoptimaliseerd voor het Azure-cloudservicesplatform, transformaties uit die specifiek zijn voor gegevenswetenschap. Het bouwt en voert ML-modellen ook uit met behulp van Python-notebooks. Scores van deze ML-modellen worden geladen in het datawarehouse om voorspellingen te integreren met bedrijfstoepassingen en -rapporten. Omdat Azure Databricks rechtstreeks toegang heeft tot de Data Lake-bestanden, elimineert of minimaliseert u de noodzaak om gegevens te kopiëren of te verkrijgen.
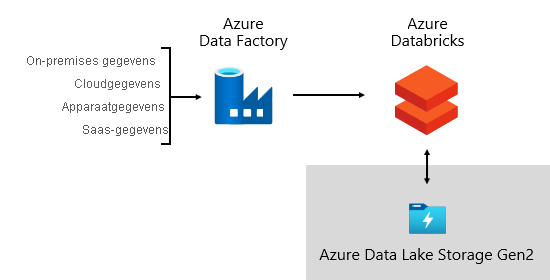
Opnameframework
We hebben een opnameframework ontwikkeld als een set configuratietabellen en -procedures. Het biedt ondersteuning voor een gegevensgestuurde benadering voor het verkrijgen van grote hoeveelheden gegevens met hoge snelheid en met minimale code. Kortom, dit framework vereenvoudigt het proces van gegevensverwerving om het datawarehouse te laden.
Het framework is afhankelijk van configuratietabellen die gegevensbron- en gegevensdoelgegevens opslaan, zoals brontype, server, database, schema en tabelgerelateerde gegevens. Deze ontwerpbenadering betekent dat we geen specifieke ADF-pijplijnen of SSIS-pakketten (SQL Server Integration Services) hoeven te ontwikkelen. In plaats daarvan worden procedures geschreven in de taal van onze keuze om ADF-pijplijnen te maken die dynamisch worden gegenereerd en uitgevoerd tijdens runtime. Gegevensverwerving wordt dus een configuratie-oefening die eenvoudig operationeel is. Normaal gesproken zijn er uitgebreide ontwikkelbronnen nodig om in code vastgelegde ADF- of SSIS-pakketten te maken.
Het opnameframework is ontworpen om het proces voor het verwerken van upstream-bronschemawijzigingen ook te vereenvoudigen. Het is eenvoudig om configuratiegegevens bij te werken, handmatig of automatisch, wanneer schemawijzigingen worden gedetecteerd om zojuist toegevoegde kenmerken in het bronsysteem te verkrijgen.
Indelingsframework
We hebben een indelingsframework ontwikkeld om onze gegevenspijplijnen operationeel te maken en te organiseren. Het maakt gebruik van een gegevensgestuurd ontwerp dat afhankelijk is van een set configuratietabellen. In deze tabellen worden metagegevens opgeslagen die pijplijnafhankelijkheden beschrijven en hoe brongegevens worden toegewezen aan doelgegevensstructuren. De investering in het ontwikkelen van dit adaptieve framework heeft sindsdien voor zichzelf betaald; er is geen vereiste meer om elke gegevensverplaatsing in code te coden.
Gegevensopslag
Een data lake kan grote hoeveelheden onbewerkte gegevens opslaan voor later gebruik, samen met faseringsgegevenstransformaties.
Bij Microsoft gebruiken we ADLS Gen2 als onze enige bron van waarheid. Onbewerkte gegevens worden opgeslagen naast gefaseerde gegevens en gegevens die gereed zijn voor productie. Het biedt een zeer schaalbare en rendabele data lake-oplossing voor big data-analyses. Door de kracht van een bestandssysteem met hoge prestaties te combineren met grootschalige schaal, is het geoptimaliseerd voor gegevensanalyseworkloads, waardoor de tijd om inzicht te krijgen wordt versneld.
ADLS Gen2 biedt het beste van twee werelden: het is BLOB-opslag en een krachtige bestandssysteemnaamruimte, die we configureren met verfijnde toegangsmachtigingen.
Verfijnde gegevens worden vervolgens opgeslagen in een relationele database om een krachtige, zeer schaalbare gegevensopslag te bieden voor bedrijfsmodellen, met beveiliging, governance en beheerbaarheid. Onderwerpspecifieke datamarts worden opgeslagen in Azure Synapse Analytics, die worden geladen door Azure Databricks- of Polybase T-SQL-query's.
Gegevensverbruik
Op de rapportagelaag gebruiken zakelijke services zakelijke gegevens die afkomstig zijn uit het datawarehouse. Ze hebben ook rechtstreeks toegang tot gegevens in de data lake voor ad-hocanalyse- of data science-taken.
Fijnmazige machtigingen worden afgedwongen op alle lagen: in de data lake, bedrijfsmodellen en semantische BI-modellen. De machtigingen zorgen ervoor dat gegevensgebruikers alleen de gegevens kunnen zien die ze toegangsrechten hebben.
Bij Microsoft gebruiken we Power BI-rapporten en -dashboards en gepagineerde Power BI-rapporten. Sommige rapportages en ad-hocanalyses worden uitgevoerd in Excel, met name voor financiële rapportage.
We publiceren gegevenswoordenlijsten, die referentie-informatie bieden over onze gegevensmodellen. Ze worden beschikbaar gesteld aan onze gebruikers, zodat ze informatie over ons BI-platform kunnen ontdekken. Documentmodelontwerpen voor woordenlijsten, met beschrijvingen over entiteiten, indelingen, structuur, gegevensherkomst, relaties en berekeningen. We gebruiken Azure Data Catalog om onze gegevensbronnen gemakkelijk te detecteren en begrijpelijk te maken.
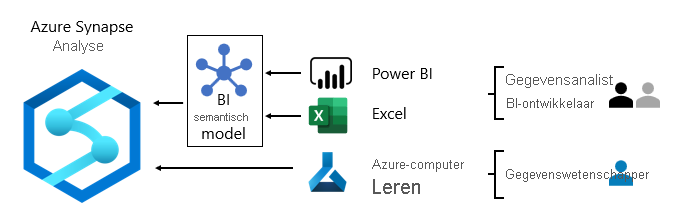
Normaal gesproken verschillen gegevensverbruikspatronen op basis van rol:
- Gegevensanalisten maken rechtstreeks verbinding met semantische BI-kernmodellen. Wanneer kern-BI-semantische modellen alle gegevens en logica bevatten die ze nodig hebben, gebruiken ze liveverbindingen om Power BI-rapporten en -dashboards te maken. Wanneer ze de modellen met afdelingsgegevens moeten uitbreiden, maken ze samengestelde Power BI-modellen. Als er behoefte is aan rapporten in spreadsheetstijl, gebruiken ze Excel om rapporten te produceren op basis van semantische BI-basismodellen of semantische BI-basismodellen van de afdeling.
- BI-ontwikkelaars en auteurs van operationele rapporten maken rechtstreeks verbinding met bedrijfsmodellen. Ze gebruiken Power BI Desktop om analytische rapporten voor liveverbindingen te maken. Ze kunnen ook BI-rapporten van het operationele type maken als gepagineerde Power BI-rapporten, waarbij systeemeigen SQL-query's worden geschreven voor toegang tot gegevens uit de Bedrijfsmodellen van Azure Synapse Analytics met behulp van T-SQL of semantische Power BI-modellen met behulp van DAX of MDX.
- Gegevenswetenschappers maken rechtstreeks verbinding met gegevens in de data lake. Ze gebruiken Azure Databricks- en Python-notebooks om ML-modellen te ontwikkelen, die vaak experimenteel zijn en speciale vaardigheden vereisen voor productiegebruik.
Gerelateerde inhoud
Raadpleeg de volgende bronnen voor meer informatie over dit artikel:
- Roadmap voor acceptatie van infrastructuur: Center of Excellence
- Enterprise BI in Azure met Azure Synapse Analytics
- Vragen? Vraag het Power BI-community
- Suggesties? Ideeën bijdragen om Power BI te verbeteren
Zakelijke dienstverlening
Gecertificeerde Power BI-partners zijn beschikbaar om uw organisatie te helpen slagen bij het instellen van een COE. Ze kunnen u voorzien van kosteneffectieve training of een audit van uw gegevens. Als u een Power BI-partner wilt betrekken, gaat u naar de Power BI-partnerportal.
U kunt ook contact opnemen met ervaren adviespartners. Ze kunnen u helpen bij het beoordelen, evalueren of implementeren van Power BI.
Feedback
Binnenkort: Gedurende 2024 worden GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor