In dit voorbeeldscenario ziet u hoe gegevens kunnen worden opgenomen in een cloudomgeving vanuit een on-premises datawarehouse en vervolgens kunnen worden geleverd met behulp van een BI-model (Business Intelligence). Deze benadering kan een einddoel zijn of een eerste stap in de richting van volledige modernisering met cloudonderdelen.
De volgende stappen zijn gebaseerd op het end-to-end-scenario van Azure Synapse Analytics. Azure Pipelines maakt gebruik van Azure Pipelines om gegevens op te nemen uit een SQL-database in Azure Synapse SQL-pools en transformeert vervolgens de gegevens voor analyse.
Architectuur

Een Visio-bestand van deze architectuur downloaden.
Workflow
Gegevensbron
- De brongegevens bevinden zich in een SQL Server-database in Azure. Als u de on-premises omgeving wilt simuleren, richt u implementatiescripts voor dit scenario een Azure SQL-database in. De AdventureWorks-voorbeelddatabase wordt gebruikt als het brongegevensschema en voorbeeldgegevens. Zie gegevens kopiëren en transformeren van en naar SQL Server voor informatie over het kopiëren en transformeren van gegevens uit een on-premises database.
Opname en gegevensopslag
Azure Data Lake Gen2 wordt gebruikt als een tijdelijk faseringsgebied tijdens gegevensopname. Vervolgens kunt u PolyBase gebruiken om gegevens te kopiëren naar een toegewezen SQL-pool van Azure Synapse.
Azure Synapse Analytics is een gedistribueerd systeem dat is ontworpen om analyses uit te voeren op grote gegevens. Het biedt ondersteuning voor massive parallel processing (MPP), waardoor het geschikt is voor het uitvoeren van analyses met hoge prestaties. Toegewezen SQL-pool van Azure Synapse is een doel voor continue opname vanuit on-premises. Het kan worden gebruikt voor verdere verwerking en het leveren van de gegevens voor Power BI via DirectQuery.
Azure Pipelines wordt gebruikt om gegevensopname en transformatie in uw Azure Synapse-werkruimte in te delen.
Analyse en rapportage
- De benadering voor gegevensmodellering in dit scenario wordt gepresenteerd door het bedrijfsmodel en het Semantische BI-model te combineren. Het bedrijfsmodel wordt opgeslagen in een toegewezen SQL-pool van Azure Synapse en het Semantische BI-model wordt opgeslagen in Power BI Premium-capaciteiten. Power BI heeft toegang tot de gegevens via DirectQuery.
Onderdelen
In dit scenario worden de volgende onderdelen gebruikt:
Vereenvoudigde architectuur
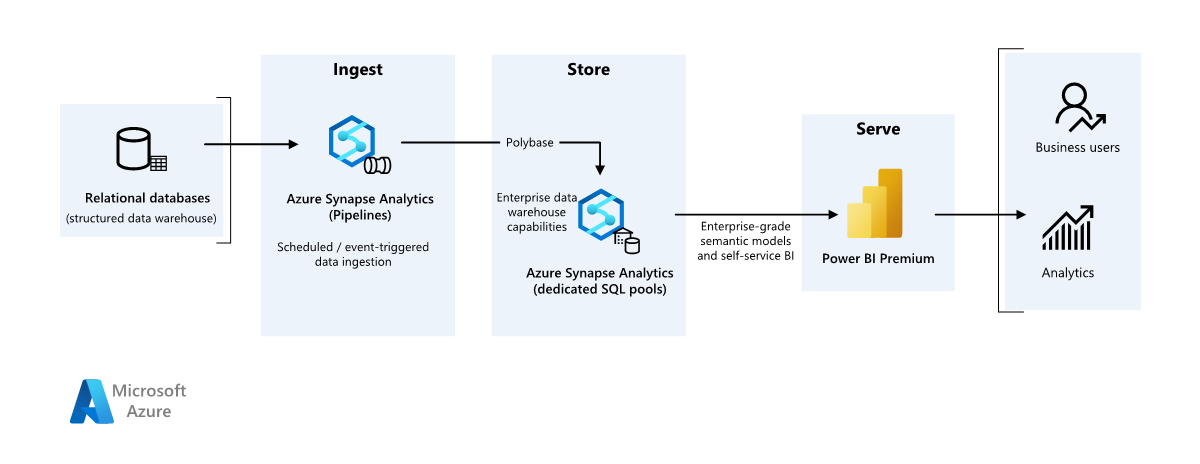
Scenariodetails
Een organisatie heeft een groot on-premises datawarehouse dat is opgeslagen in een SQL-database. De organisatie wil Azure Synapse gebruiken om analyses uit te voeren en deze inzichten vervolgens te leveren met behulp van Power BI.
Verificatie
Microsoft Entra verifieert gebruikers die verbinding maken met Power BI-dashboards en -apps. Eenmalige aanmelding wordt gebruikt om verbinding te maken met de gegevensbron in de ingerichte pool van Azure Synapse. Autorisatie vindt plaats op de bron.
Incrementeel laden
Wanneer u een geautomatiseerd etl-proces (extraheren, transformeren, laden, laden, transformeren) uitvoert, is het meest efficiënt om alleen de gegevens te laden die zijn gewijzigd sinds de vorige uitvoering. Dit wordt een incrementele belasting genoemd, in plaats van een volledige belasting waarmee alle gegevens worden geladen. Als u een incrementele belasting wilt uitvoeren, hebt u een manier nodig om te bepalen welke gegevens zijn gewijzigd. De meest voorkomende benadering is het gebruik van een hoge watermarkeringswaarde , waarmee de meest recente waarde van een kolom in de brontabel wordt bijgehouden, ofwel een datum/tijd-kolom of een unieke geheel getalkolom.
Vanaf SQL Server 2016 kunt u tijdelijke tabellen gebruiken. Dit zijn systeemtabellen die een volledige geschiedenis van gegevenswijzigingen behouden. De database-engine registreert automatisch de geschiedenis van elke wijziging in een afzonderlijke geschiedenistabel. U kunt een query uitvoeren op de historische gegevens door een FOR SYSTEM_TIME component toe te voegen aan een query. Intern voert de database-engine een query uit op de geschiedenistabel, maar deze is transparant voor de toepassing.
Notitie
Voor eerdere versies van SQL Server kunt u CDC (Change Data Capture) gebruiken. Deze methode is minder handig dan tijdelijke tabellen, omdat u een query moet uitvoeren op een afzonderlijke wijzigingstabel en wijzigingen worden bijgehouden door een logboekreeksnummer, in plaats van een tijdstempel.
Tijdelijke tabellen zijn handig voor dimensiegegevens, die na verloop van tijd kunnen worden gewijzigd. Feitentabellen vertegenwoordigen meestal een onveranderbare transactie, zoals een verkoop, waarbij het bewaren van de systeemversiegeschiedenis niet zinvol is. In plaats daarvan hebben transacties meestal een kolom die de transactiedatum vertegenwoordigt, die kan worden gebruikt als de grenswaarde. In het AdventureWorks Data Warehouse hebben de SalesLT.* tabellen bijvoorbeeld een LastModified veld.
Dit is de algemene stroom voor de ELT-pijplijn:
Houd voor elke tabel in de brondatabase de cutoff-tijd bij waarop de laatste ELT-taak is uitgevoerd. Sla deze informatie op in het datawarehouse. Bij de eerste installatie worden alle tijden ingesteld op
1-1-1900.Tijdens de gegevensexportstap wordt de cutoff-tijd doorgegeven als een parameter aan een set opgeslagen procedures in de brondatabase. Deze opgeslagen procedures voeren een query uit op records die zijn gewijzigd of gemaakt na de cutoff-tijd. Voor alle tabellen in het voorbeeld kunt u de
ModifiedDatekolom gebruiken.Wanneer de gegevensmigratie is voltooid, werkt u de tabel bij waarin de afsluittijden worden opgeslagen.
Gegevenspijplijn
In dit scenario wordt de AdventureWorks-voorbeelddatabase gebruikt als gegevensbron. Het patroon voor incrementele gegevensbelasting wordt geïmplementeerd om ervoor te zorgen dat we alleen gegevens laden die zijn gewijzigd of toegevoegd na de meest recente pijplijnuitvoering.
Hulpprogramma voor kopiëren op basis van metagegevens
Met het ingebouwde hulpprogramma voor kopiëren op basis van metagegevens in Azure Pipelines worden alle tabellen in onze relationele database incrementeel geladen. Door door de wizard te navigeren, kunt u het hulpprogramma Gegevens kopiëren verbinden met de brondatabase en incrementeel of volledig laden configureren voor elke tabel. Het hulpprogramma Copy Data maakt vervolgens zowel de pijplijnen als SQL-scripts om de besturingstabel te genereren die nodig is voor het opslaan van gegevens voor het incrementele laadproces, bijvoorbeeld de hoge grenswaarde/kolom voor elke tabel. Zodra deze scripts zijn uitgevoerd, is de pijplijn klaar om alle tabellen in het brondatawarehouse te laden in de toegewezen Synapse-pool.
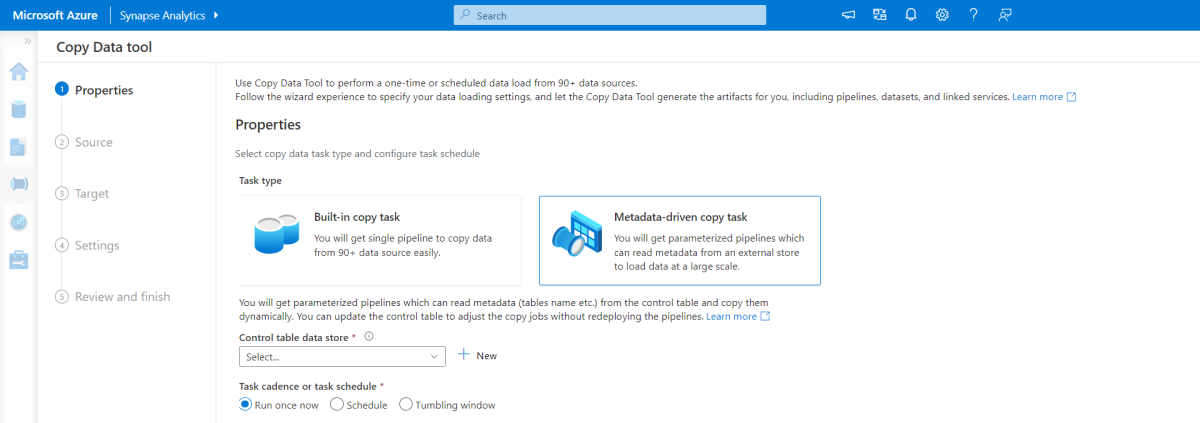
Het hulpprogramma maakt drie pijplijnen om alle tabellen in de database te herhalen voordat de gegevens worden geladen.
De pijplijnen die door dit hulpprogramma worden gegenereerd:
- Tel het aantal objecten, zoals tabellen, dat moet worden gekopieerd in de pijplijnuitvoering.
- Herhaal elk object dat moet worden geladen/gekopieerd en vervolgens:
- Controleer of een deltabelasting vereist is; anders voltooit u een normale volledige belasting.
- Haal de hoge grenswaarde op uit de besturingstabel.
- Kopieer gegevens uit de brontabellen naar het faseringsaccount in ADLS Gen2.
- Laad gegevens in de toegewezen SQL-pool via de geselecteerde kopieermethode, bijvoorbeeld de opdracht Polybase, Kopiëren.
- Werk de waarde van het hoge watermerk in de besturingstabel bij.
Gegevens laden in Azure Synapse SQL-pool
Met de kopieeractiviteit worden gegevens uit de SQL-database gekopieerd naar de Azure Synapse SQL-pool. In dit voorbeeld, omdat onze SQL-database zich in Azure bevindt, gebruiken we de Azure Integration Runtime om gegevens uit de SQL-database te lezen en de gegevens naar de opgegeven faseringsomgeving te schrijven.
De kopieerinstructie wordt vervolgens gebruikt om gegevens uit de faseringsomgeving te laden in de toegewezen Synapse-pool.
Azure Pipelines gebruiken
Pijplijnen in Azure Synapse worden gebruikt om de geordende set activiteiten te definiëren om het incrementele belastingspatroon te voltooien. Triggers worden gebruikt om de pijplijn te starten, die handmatig of tegelijk kan worden geactiveerd.
De gegevens transformeren
Omdat de voorbeelddatabase in onze referentiearchitectuur niet groot is, hebben we gerepliceerde tabellen zonder partities gemaakt. Voor productieworkloads is het waarschijnlijk dat het gebruik van gedistribueerde tabellen de prestaties van query's verbetert. Zie Richtlijnen voor het ontwerpen van gedistribueerde tabellen in Azure Synapse. In de voorbeeldscripts worden de query's uitgevoerd met behulp van een statische resourceklasse.
Overweeg in een productieomgeving faseringstabellen te maken met round robin-distributie. Transformeer en verplaats de gegevens vervolgens naar productietabellen met geclusterde columnstore-indexen, die de beste algehele queryprestaties bieden. Columnstore-indexen zijn geoptimaliseerd voor query's die veel records scannen. Columnstore-indexen presteren niet zo goed voor singleton lookups, dat wil gezegd, het opzoeken van één rij. Als u frequente singletonzoekacties wilt uitvoeren, kunt u een niet-geclusterde index toevoegen aan een tabel. Singleton-zoekopdrachten kunnen veel sneller worden uitgevoerd met behulp van een niet-geclusterde index. Singleton-zoekopdrachten zijn echter doorgaans minder gebruikelijk in datawarehouse-scenario's dan OLTP-workloads. Zie Indexeringstabellen in Azure Synapse voor meer informatie.
Notitie
Geclusterde columnstore-tabellen ondersteunen varchar(max)geen gegevenstypen.varbinary(max) nvarchar(max) In dat geval kunt u een heap- of geclusterde index overwegen. U kunt deze kolommen in een afzonderlijke tabel plaatsen.
Power BI Premium gebruiken om gegevens te openen, te modelleren en te visualiseren
Power BI Premium ondersteunt verschillende opties voor het maken van verbinding met gegevensbronnen in Azure, met name de ingerichte Pool van Azure Synapse:
- Importeren: de gegevens worden geïmporteerd in het Power BI-model.
- DirectQuery: gegevens worden rechtstreeks opgehaald uit relationele opslag.
- Samengesteld model: Import combineren voor sommige tabellen en DirectQuery voor anderen.
Dit scenario wordt geleverd met het DirectQuery-dashboard omdat de hoeveelheid gebruikte gegevens en modelcomplexiteit niet hoog zijn, zodat we een goede gebruikerservaring kunnen bieden. DirectQuery delegeert de query naar de krachtige rekenengine eronder en maakt gebruik van uitgebreide beveiligingsmogelijkheden op de bron. Bovendien zorgt het gebruik van DirectQuery ervoor dat de resultaten altijd consistent zijn met de meest recente brongegevens.
De importmodus biedt de snelste reactietijd voor query's en moet worden overwogen wanneer het model volledig in het geheugen van Power BI past, de gegevenslatentie tussen vernieuwingen kan worden getolereerd en er kunnen enkele complexe transformaties zijn tussen het bronsysteem en het uiteindelijke model. In dit geval willen de eindgebruikers volledige toegang tot de meest recente gegevens zonder vertragingen bij het vernieuwen van Power BI en alle historische gegevens, die groter zijn dan wat een Power BI-gegevensset kan verwerken, afhankelijk van de capaciteitsgrootte. Omdat het gegevensmodel in de toegewezen SQL-pool zich al in een stervormig schema bevindt en geen transformatie nodig heeft, is DirectQuery een geschikte keuze.
Power BI Premium Gen2 biedt u de mogelijkheid om grote modellen, gepagineerde rapporten, implementatiepijplijnen en ingebouwd Analysis Services-eindpunt te verwerken. U kunt ook toegewezen capaciteit hebben met een unieke waardepropositie.
Wanneer het BI-model groeit of de complexiteit van het dashboard toeneemt, kunt u overschakelen naar samengestelde modellen en delen van opzoektabellen importeren, via hybride tabellen en enkele vooraf geaggregeerde gegevens. Het inschakelen van querycaching in Power BI voor geïmporteerde gegevenssets is een optie en het gebruik van dubbele tabellen voor de eigenschap opslagmodus.
Binnen het samengestelde model fungeren gegevenssets als een virtuele passthrough-laag. Wanneer de gebruiker interactie heeft met visualisaties, genereert Power BI SQL-query's naar Synapse SQL-pools met dubbele opslag: in het geheugen of de directe query, afhankelijk van welke efficiënter is. De engine bepaalt wanneer u wilt overschakelen van in-memory naar directe query's en de logica naar de Synapse SQL-pool pusht. Afhankelijk van de context van de querytabellen kunnen ze fungeren als in de cache opgeslagen (geïmporteerd) of niet als samengestelde modellen in de cache. Kies en kies welke tabel u in het geheugen wilt opslaan, combineer gegevens uit een of meer DirectQuery-bronnen en/of combineer gegevens uit een combinatie van DirectQuery-bronnen en geïmporteerde gegevens.
Aanbevelingen: Wanneer u DirectQuery gebruikt via een ingerichte pool van Azure Synapse Analytics:
- Gebruik azure Synapse-resultatensetcache om queryresultaten in de cache op te cachen in de gebruikersdatabase voor herhaaldelijk gebruik, verbeter de queryprestaties tot milliseconden en verminder het rekenresourcegebruik. Query's met behulp van resultatensets in de cache gebruiken geen gelijktijdigheidssites in Azure Synapse Analytics en tellen dus niet mee voor bestaande gelijktijdigheidslimieten.
- Gebruik gerealiseerde weergaven van Azure Synapse om gegevens vooraf te berekenen, op te slaan en te onderhouden, net als een tabel. Query's die gebruikmaken van alle of een subset van de gegevens in gerealiseerde weergaven kunnen sneller presteren en ze hoeven geen directe verwijzing te maken naar de gedefinieerde gerealiseerde weergave om deze te gebruiken.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die kunnen worden gebruikt om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Beveiliging
Beveiliging biedt garanties tegen opzettelijke aanvallen en misbruik van uw waardevolle gegevens en systemen. Zie Overzicht van de beveiligingspijler voor meer informatie.
Frequente koppen over gegevensschendingen, malware-infecties en schadelijke code-injectie behoren tot een uitgebreide lijst met beveiligingsproblemen voor bedrijven die op zoek zijn naar modernisering van de cloud. Zakelijke klanten hebben een cloudprovider of serviceoplossing nodig die hun zorgen kan oplossen, omdat ze het zich niet kunnen veroorloven om het verkeerd te krijgen.
In dit scenario worden de meest veeleisende beveiligingsproblemen aangepakt met behulp van een combinatie van gelaagde beveiligingscontroles: netwerk, identiteit, privacy en autorisatie. Het grootste deel van de gegevens wordt opgeslagen in de ingerichte Pool van Azure Synapse, met Power BI met behulp van DirectQuery via eenmalige aanmelding. U kunt De Microsoft Entra-id gebruiken voor verificatie. Er zijn ook uitgebreide beveiligingscontroles voor gegevensautorisatie van ingerichte pools.
Enkele veelvoorkomende beveiligingsvragen zijn onder meer:
- Hoe kan ik bepalen wie welke gegevens kan zien?
- Organisaties moeten hun gegevens beschermen om te voldoen aan federale, lokale en bedrijfsrichtlijnen om de risico's van gegevenslekken te beperken. Azure Synapse biedt meerdere mogelijkheden voor gegevensbeveiliging om naleving te bereiken.
- Wat zijn de opties voor het verifiëren van de identiteit van een gebruiker?
- Azure Synapse biedt ondersteuning voor een breed scala aan mogelijkheden om te bepalen wie toegang heeft tot welke gegevens via toegangsbeheer en verificatie.
- Welke netwerkbeveiligingstechnologie kan ik gebruiken om de integriteit, vertrouwelijkheid en toegang tot mijn netwerken en gegevens te beschermen?
- Voor het beveiligen van Azure Synapse zijn er diverse netwerkbeveiligingsopties beschikbaar om rekening mee te houden.
- Wat zijn de hulpprogramma's die bedreigingen detecteren en mij op de hoogte stellen van bedreigingen?
- Azure Synapse biedt veel mogelijkheden voor bedreigingsdetectie , zoals: SQL-controle, SQL-bedreigingsdetectie en evaluatie van beveiligingsproblemen om databases te controleren, te beveiligen en te bewaken.
- Wat kan ik doen om gegevens in mijn opslagaccount te beveiligen?
- Azure Storage-accounts zijn ideaal voor workloads die snelle en consistente reactietijden vereisen of die een groot aantal IOP-bewerkingen (Input-Output Operations) per seconde hebben. Opslagaccounts bevatten al uw Azure Storage-gegevensobjecten en hebben veel opties voor beveiliging van opslagaccounts.
Kostenoptimalisatie
Kostenoptimalisatie gaat over manieren om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren. Zie Overzicht van de pijler kostenoptimalisatie voor meer informatie.
Deze sectie bevat informatie over prijzen voor verschillende services die betrokken zijn bij deze oplossing en vermeldt beslissingen voor dit scenario met een voorbeeldgegevensset.
Azure Synapse
Met de serverloze architectuur van Azure Synapse Analytics kunt u uw reken- en opslagniveaus onafhankelijk schalen. Rekenresources worden in rekening gebracht op basis van gebruik en u kunt deze resources op aanvraag schalen of onderbreken. Opslagresources worden gefactureerd per terabyte, zodat uw kosten toenemen naarmate u meer gegevens opneemt.
Azure-pipelines
Prijsinformatie voor pijplijnen in Azure Synapse vindt u op het tabblad Data-Integratie op de pagina met prijzen van Azure Synapse. Er zijn drie hoofdonderdelen die van invloed zijn op de prijs van een pijplijn:
- Activiteiten voor gegevenspijplijnen en runtime-uren voor integratie
- Clustergrootte en uitvoering van gegevensstromen
- Kosten van bewerkingen
De prijs is afhankelijk van de onderdelen of activiteiten, frequentie en het aantal integratieruntime-eenheden.
Voor de voorbeeldgegevensset wordt de standaard door Azure gehoste integration runtime, kopieergegevensactiviteit voor de kern van de pijplijn, geactiveerd volgens een dagelijks schema voor alle entiteiten (tabellen) in de brondatabase. Het scenario bevat geen gegevensstromen. Er zijn geen operationele kosten omdat er minder dan 1 miljoen bewerkingen met pijplijnen per maand zijn.
Toegewezen Azure Synapse-pool en -opslag
Prijsinformatie voor een toegewezen Azure Synapse-pool vindt u op het tabblad Databeheersysteem op de pagina met prijzen van Azure Synapse. Onder het toegewezen verbruiksmodel worden klanten gefactureerd per DWU-eenheden (Data Warehouse Unit) ingericht, per uur van uptime. Een andere bijdragefactor is de kosten voor gegevensopslag: grootte van uw data-at-rest + momentopnamen + georedundantie, indien van toepassing.
Voor de voorbeeldgegevensset kunt u 500DWU inrichten, wat een goede ervaring garandeert voor analytische belasting. U kunt berekeningen blijven uitvoeren gedurende kantooruren van rapportage. Als u in productie gaat, is gereserveerde datawarehousecapaciteit een aantrekkelijke optie voor kostenbeheer. Er moeten verschillende technieken worden gebruikt om metrische gegevens over kosten/prestaties te maximaliseren, die in de vorige secties worden behandeld.
Blob-opslag
Overweeg om de gereserveerde capaciteitsfunctie van Azure Storage te gebruiken om de opslagkosten te verlagen. Met dit model krijgt u korting als u een vaste opslagcapaciteit reserveert voor een of drie jaar. Zie Kosten optimaliseren voor Blob Storage met gereserveerde capaciteit voor meer informatie.
In dit scenario is er geen permanente opslag.
Power BI Premium
De prijsgegevens van Power BI Premium vindt u op de pagina met prijzen van Power BI.
In dit scenario worden Power BI Premium-werkruimten gebruikt met een reeks prestatieverbeteringen die zijn ingebouwd om tegemoet te komen aan veeleisende analytische behoeften.
Operationele uitmuntendheid
Operationele uitmuntendheid omvat de operationele processen die een toepassing implementeren en deze in productie houden. Zie Overzicht van de operationele uitmuntendheidpijler voor meer informatie.
DevOps-aanbevelingen
Maak afzonderlijke resourcegroepen voor productie-, ontwikkelings- en testomgevingen. Met afzonderlijke resourcegroepen kunt u eenvoudiger implementaties beheren, testimplementaties verwijderen en toegangsrechten verlenen.
Plaats elke workload in een afzonderlijke implementatiesjabloon en sla de resources op in broncodebeheersystemen. U kunt de sjablonen samen of afzonderlijk implementeren als onderdeel van een CI/CD-proces (continue integratie en continue levering), waardoor het automatiseringsproces eenvoudiger wordt. In deze architectuur zijn er vier hoofdworkloads:
- De datawarehouse-server en gerelateerde resources
- Azure Synapse-pijplijnen
- Power BI-assets: dashboards, apps, gegevenssets
- Een gesimuleerd on-premises scenario voor cloud
Doel is om een afzonderlijke implementatiesjabloon te hebben voor elk van de workloads.
Overweeg om uw workloads te faseren, waar praktisch. Implementeer in verschillende fasen en voer validatiecontroles uit in elke fase voordat u naar de volgende fase gaat. Op die manier kunt u updates naar uw productieomgevingen pushen op een gecontroleerde manier en onverwachte implementatieproblemen minimaliseren. Gebruik blauwgroene implementatie en canary-releasestrategieën voor het bijwerken van live productieomgevingen.
Zorg voor een goede terugdraaistrategie voor het afhandelen van mislukte implementaties. U kunt bijvoorbeeld automatisch een eerdere, geslaagde implementatie opnieuw implementeren vanuit uw implementatiegeschiedenis. Bekijk de
--rollback-on-errorvlag in Azure CLI.Azure Monitor is de aanbevolen optie voor het analyseren van de prestaties van uw datawarehouse en het volledige Azure Analytics-platform voor een geïntegreerde bewakingservaring. Azure Synapse Analytics biedt een bewakingservaring in Azure Portal om inzicht te krijgen in uw datawarehouse-workload. Azure Portal is het aanbevolen hulpprogramma bij het bewaken van uw datawarehouse, omdat het configureerbare bewaarperioden, waarschuwingen, aanbevelingen en aanpasbare grafieken en dashboards voor metrische gegevens en logboeken biedt.
Snel starten
- Portal: Azure Synapse proof of concept (POC)
- Azure CLI: Een Azure Synapse-werkruimte maken met Azure CLI
- Terraform: Moderne datawarehousing met Terraform en Microsoft Azure
Prestatie-efficiëntie
Prestatie-efficiëntie is de mogelijkheid om op efficiënte wijze uw werkbelasting te schalen om te voldoen aan de vereisten die gebruikers eraan stellen. Zie overzicht van de pijler Prestatie-efficiëntie voor meer informatie.
In deze sectie vindt u informatie over het bepalen van de grootte van beslissingen voor deze gegevensset.
Ingerichte Pool van Azure Synapse
Er is een reeks datawarehouseconfiguraties waaruit u kunt kiezen.
| Datawarehouse-eenheden | Aantal rekenknooppunten | Aantal distributies per knooppunt |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Als u de prestatievoordelen van uitschalen wilt zien, met name voor grotere datawarehouse-eenheden, gebruikt u ten minste een gegevensset van 1 TB. Als u het beste aantal datawarehouse-eenheden voor uw toegewezen SQL-pool wilt vinden, kunt u omhoog en omlaag schalen. Voer enkele query's uit met verschillende aantallen datawarehouse-eenheden na het laden van uw gegevens. Omdat schalen snel is, kunt u in een uur of minder verschillende prestatieniveaus proberen.
Het beste aantal datawarehouse-eenheden zoeken
Voor een toegewezen SQL-pool in ontwikkeling selecteert u eerst een kleiner aantal datawarehouse-eenheden. Een goed startpunt is DW400c of DW200c. Bewaak de prestaties van uw toepassing, waarbij u het aantal geselecteerde datawarehouse-eenheden bekijkt in vergelijking met de prestaties die u ziet. Stel een lineaire schaal in en bepaal hoeveel u nodig hebt om de datawarehouse-eenheden te verhogen of te verlagen. Ga door met het aanbrengen van aanpassingen totdat u een optimaal prestatieniveau voor uw bedrijfsvereisten bereikt.
Synapse SQL-pool schalen
- Rekenkracht schalen voor Synapse SQL-pool met Azure Portal
- Rekenkracht schalen voor toegewezen SQL-pool met Azure PowerShell
- Rekenkracht schalen voor toegewezen SQL-pool in Azure Synapse Analytics met behulp van T-SQL
- Onderbreken, bewaken en automatiseren
Azure-pipelines
Raadpleeg de handleiding voor Copy-activiteit prestaties en schaalbaarheid voor functies van pijplijnen in Azure Synapse en de gebruikte kopieeractiviteit voor schaalbaarheid en prestaties.
Power BI Premium
In dit artikel wordt Power BI Premium Gen 2 gebruikt om BI-mogelijkheden te demonstreren. Capaciteits-SKU's voor Power BI Premium variëren momenteel van P1 (acht v-cores) tot P5 (128 v-cores). De beste manier om de benodigde capaciteit te selecteren, is door de evaluatie van capaciteitsbelasting te ondergaan, de metrische gen 2-app te installeren voor doorlopende bewaking en om automatische schaalaanpassing met Power BI Premium te gebruiken.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- Galina Polyakova | Senior Cloud Solution Architect
- Noah Costar | Cloud Solution Architect
- George Stevens | Cloud Solution Architect
Andere Inzenders:
- Jim McLeod | Cloud Solution Architect
- Miguel Myers | Senior Program Manager
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
- Wat is Power BI Premium?
- Wat is Microsoft Entra ID?
- Toegang tot Azure Data Lake Storage Gen2 en Blob Storage met Azure Databricks
- Wat is Azure Synapse Analytics?
- Pijplijnen en activiteiten in Azure Data Factory en Azure Synapse Analytics
- Wat is Azure SQL?