Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Met Power BI-gegevensstromen kunt u verbinding maken met, transformeren, combineren en distribueren van gegevens voor downstreamanalyses. Een belangrijk element in gegevensstromen is het vernieuwingsproces, dat de transformatiestappen toepast die u hebt gemaakt in de gegevensstromen en de gegevens in de items zelf bijwerkt.
Om inzicht te krijgen in de uitvoeringstijden, prestaties en of u het meeste uit uw dataflow haalt, kunt u de vernieuwingsgeschiedenis downloaden nadat u een dataflow hebt vernieuwd.
Inzicht in vernieuwingen
Er zijn twee typen vernieuwingen die van toepassing zijn op gegevensstromen:
Volledig, waarmee uw gegevens volledig worden leeggemaakt en opnieuw geladen.
Incrementeel (alleen Premium), dat een subset van uw gegevens verwerkt op basis van regels op basis van tijd, uitgedrukt als een filter, die u configureert. Met het filter op de datumkolom worden de gegevens dynamisch gepartitioneerd in intervallen binnen de Power BI-service. Nadat u de incrementele vernieuwing hebt geconfigureerd, verandert de gegevensstroom uw query automatisch zodat deze wordt gefilterd op datum. U kunt de automatisch gegenereerde query bewerken met behulp van de geavanceerde editor in Power Query om uw vernieuwing te verfijnen of aan te passen. Als u uw eigen Azure Data Lake Storage gebruikt, kunt u tijdsegmenten van uw gegevens zien op basis van het vernieuwingsbeleid dat u hebt ingesteld.
Opmerking
Zie Incrementeel vernieuwen gebruiken met gegevensstromen voor meer informatie over incrementeel vernieuwen en hoe het werkt.
Incrementeel vernieuwen maakt grote gegevensstromen in Power BI mogelijk met de volgende voordelen:
Vernieuwingen zijn sneller na de eerste vernieuwing, vanwege de volgende feiten:
- Power BI vernieuwt de laatste N-partities die zijn opgegeven door de gebruiker (waarbij de partitie dag/week/maand is, enzovoort), of
- Power BI vernieuwt alleen gegevens die moeten worden vernieuwd. Vernieuw bijvoorbeeld alleen de laatste vijf dagen van een semantisch model van tien jaar.
- Power BI vernieuwt alleen gegevens die zijn gewijzigd, zolang u de kolom opgeeft die u wilt controleren op wijzigingen.
Vernieuwingen zijn betrouwbaarder. Het is niet langer nodig om langdurige verbindingen met vluchtige bronsystemen te onderhouden.
Resourceverbruik wordt verminderd: minder gegevens om te vernieuwen vermindert het totale verbruik van geheugen en andere resources.
Waar mogelijk maakt Power BI gebruik van parallelle verwerking op partities, wat kan leiden tot snellere vernieuwingen.
In een van deze vernieuwingsscenario's, als een vernieuwing mislukt, worden de gegevens niet bijgewerkt. Uw gegevens zijn mogelijk verlopen totdat de meest recente vernieuwing is voltooid, of u kunt deze handmatig vernieuwen en deze vervolgens zonder fouten kunnen voltooien. Vernieuwen vindt plaats op een partitie of entiteit, dus als een incrementele vernieuwing mislukt of een entiteit een fout heeft, wordt de hele vernieuwingstransactie niet uitgevoerd. Een andere manier gezegd, als een partitie (incrementeel vernieuwingsbeleid) of entiteit mislukt voor een gegevensstroom, mislukt de volledige vernieuwingsbewerking en worden er geen gegevens bijgewerkt.
Vernieuwingen begrijpen en optimaliseren
Raadpleeg de vernieuwingsgeschiedenis voor de gegevensstroom door naar een van uw gegevensstromen te navigeren om beter te begrijpen hoe een gegevensstroomvernieuwingsbewerking wordt uitgevoerd. Selecteer Meer opties (...) voor de gegevensstroom. Kies vervolgens Instellingen > Geschiedenis vernieuwen. U kunt ook de gegevensstroom in de werkruimte selecteren. Kies vervolgens Meer opties (...) > Vernieuwingsgeschiedenis.
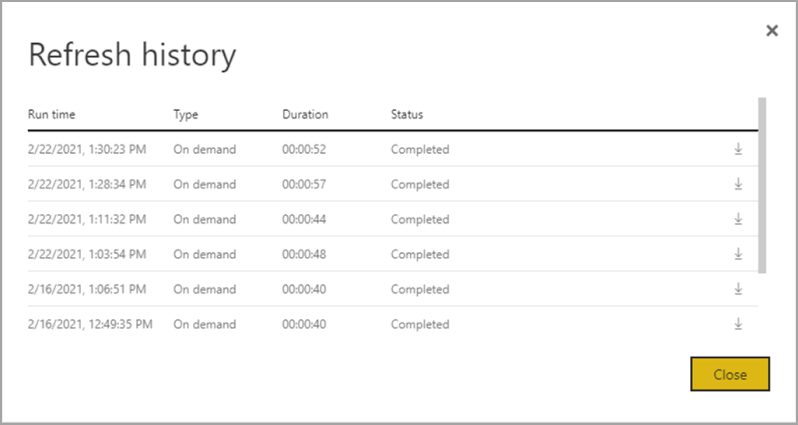
De vernieuwingsgeschiedenis biedt een overzicht van vernieuwingen, waaronder het type : op aanvraag of gepland, de duur en de uitvoeringsstatus. Als u details in de vorm van een CSV-bestand wilt zien, selecteert u het downloadpictogram uiterst rechts van de rij van de beschrijving van de vernieuwing. Het gedownloade CSV-bestand bevat de kenmerken die in de volgende tabel worden beschreven. Premium-vernieuwingen bieden meer informatie op basis van de extra mogelijkheden voor reken- en gegevensstromen, versus pro-gegevensstromen die zich in gedeelde capaciteit bevinden. Als zodanig zijn sommige van de volgende metrische gegevens alleen beschikbaar in Premium.
| Item | Description | PRO | Premium |
|---|---|---|---|
| Aangevraagd op | De tijdvernieuwing was gepland of er is nu op vernieuwen geklikt in lokale tijd. | ✔ | ✔ |
| Naam van gegevensstroom | Naam van uw gegevensstroom. | ✔ | ✔ |
| Vernieuwingsstatus van gegevensstroom | Voltooid, Mislukt of Overgeslagen (voor een entiteit) zijn mogelijke statussen. Gebruiksscenario's zoals gekoppelde entiteiten zijn redenen waarom bepaalde gevallen mogelijk worden overgeslagen. | ✔ | ✔ |
| Naam entiteit | Tabelnaam. | ✔ | ✔ |
| Partitienaam | Dit item is afhankelijk van of de gegevensstroom premium is of niet, en als Pro wordt weergegeven als NA omdat dit geen ondersteuning biedt voor incrementele vernieuwingen. Premium laat FullRefreshPolicyPartition of IncrementalRefreshPolicyPartition-[DateRange] zien. | ✔ | |
| Status vernieuwen | Vernieuwingsstatus van de afzonderlijke entiteit of partitie, die de status voor dat tijdssegment biedt van gegevens die worden vernieuwd. | ✔ | ✔ |
| Begintijd | In Premium is dit item het tijdstip waarop de gegevensstroom in de wachtrij is geplaatst voor verwerking voor de entiteit of partitie. Deze tijd kan verschillen als gegevensstromen afhankelijkheden hebben en moeten wachten totdat de resultatenset van een upstream-gegevensstroom wordt verwerkt. | ✔ | ✔ |
| Eindtijd | Eindtijd is de tijd waarop de gegevensstroomentiteit of -partitie is voltooid, indien van toepassing. | ✔ | ✔ |
| Duur | Totale tijdsduur voor het vernieuwen van de gegevensstroom uitgedrukt in UU:MM:SS. | ✔ | ✔ |
| Verwerkte rijen | Voor een bepaalde entiteit of partitie wordt het aantal rijen gescand of geschreven door de gegevensstroomengine. Dit item bevat mogelijk niet altijd gegevens op basis van de bewerking die u hebt uitgevoerd. Gegevens kunnen worden weggelaten wanneer de berekeningsengine niet wordt gebruikt of wanneer u een gateway gebruikt als de gegevens daar worden verwerkt. | ✔ | |
| Verwerkte bytes | Voor een bepaalde entiteit of partitie worden gegevens geschreven door de gegevensstroomengine, uitgedrukt in bytes. Wanneer u een gateway gebruikt voor deze specifieke gegevensstroom, wordt deze informatie niet opgegeven. |
✔ | |
| Maximale doorvoer (KB) | "Max Commit" is het maximale commit-geheugen dat nuttig is voor het diagnosticeren van out-of-memory problemen wanneer de M-query niet is geoptimaliseerd. Wanneer u een gateway gebruikt voor deze specifieke gegevensstroom, wordt deze informatie niet opgegeven. |
✔ | |
| Processortijd | Voor een bepaalde entiteit of partitie is de tijd, uitgedrukt in UU:MM:SS, die de gegevensstroomengine heeft besteed aan het uitvoeren van transformaties. Wanneer u een gateway gebruikt voor deze specifieke gegevensstroom, wordt deze informatie niet opgegeven. |
✔ | |
| Wachttijd | De tijd die een entiteit of partitie in de wachtstatus heeft doorgebracht, op basis van de workload binnen de Premium-capaciteit. | ✔ | |
| Berekeningsengine | Voor een bepaalde entiteit of partitie vindt u meer informatie over de wijze waarop de vernieuwingsbewerking gebruikmaakt van de berekeningsengine. De waarden zijn: - NA -Geplooid - cache - In cache opgeslagen + samengevouwen Deze elementen worden verderop in dit artikel uitgebreider beschreven. |
✔ | |
| Fout | Indien van toepassing wordt het gedetailleerde foutbericht per entiteit of partitie beschreven. | ✔ | ✔ |
Richtlijnen voor het vernieuwen van gegevensstromen
De vernieuwingsstatistieken bieden waardevolle informatie die u kunt gebruiken om de prestaties van uw gegevensstromen te optimaliseren en te versnellen. In de volgende secties beschrijven we enkele scenario's, waar u op moet letten en hoe u kunt optimaliseren op basis van de verstrekte informatie.
Orkestratie
Door gegevensstromen in dezelfde werkruimte te gebruiken, is eenvoudige indeling mogelijk. Als voorbeeld kunt u gegevensstromen A, B en C in één werkruimte hebben en koppelen zoals A > B > C. Als u de bron (A) vernieuwt, worden de downstreamentiteiten ook vernieuwd. Als u echter C vernieuwt, moet u anderen onafhankelijk vernieuwen. Als u ook een nieuwe gegevensbron toevoegt in gegevensstroom B (die niet in A is opgenomen), worden die gegevens niet vernieuwd als onderdeel van orkestratie.
Mogelijk wilt u items koppelen die niet passen bij de beheerde indeling die Power BI uitvoert. In deze scenario's kunt u de API's gebruiken en/of Power Automate gebruiken. Raadpleeg de API-documentatie en het PowerShell-script voor programmatisch vernieuwen. Er is een Power Automate-connector waarmee u deze procedure kunt uitvoeren zonder code te schrijven. U kunt gedetailleerde voorbeelden bekijken, met specifieke stapsgewijze instructies voor sequentiële vernieuwingen.
Controle
Met behulp van de verbeterde vernieuwingsstatistieken die eerder in dit artikel zijn beschreven, kunt u gedetailleerde informatie over vernieuwen per gegevensstroom ophalen. Maar als u gegevensstromen wilt zien met een tenantbreed of werkruimtebreed overzicht van vernieuwingen, misschien om een bewakingsdashboard te maken, kunt u de API's of Power Automate-sjablonen gebruiken. Voor gebruiksvoorbeelden, zoals het verzenden van eenvoudige of complexe meldingen, kunt u de Power Automate-connector gebruiken of uw eigen aangepaste toepassing bouwen met behulp van de API's.
Time-outfouten
Het optimaliseren van de tijd die nodig is om ETL-scenario's (extract, transform and load) uit te voeren, is ideaal. In Power BI zijn de volgende gevallen van toepassing:
- Sommige connectors hebben expliciete time-outinstellingen die u kunt configureren. Zie Connectors in Power Query voor meer informatie.
- Power BI-gegevensstromen, met power BI Pro, kunnen ook time-outs ervaren voor langdurige query's binnen een entiteit of gegevensstromen zelf. Deze beperking bestaat niet in Power BI Premium-werkruimten.
Richtlijnen voor time-outs
Time-outdrempels voor Power BI Pro-gegevensstromen zijn:
- Twee uur op het niveau van individuele entiteiten.
- Drie uur op het volledige gegevensstroomniveau.
Als u bijvoorbeeld een gegevensstroom met drie tabellen hebt, kan geen enkele tabel meer dan twee uur duren en treedt er een time-out voor de hele gegevensstroom op als de duur langer is dan drie uur.
Als u time-outs ondervindt, overweeg dan om uw gegevensstroomquery's te optimaliseren en om query folding te gebruiken op uw bronsystemen.
Overweeg afzonderlijk een upgrade uit te voeren naar Premium Per Gebruiker, die niet onderhevig is aan deze time-outs en betere prestaties biedt vanwege veel functies van Power BI Premium per gebruiker.
Lange duur
Complexe of grote gegevensstromen kunnen meer tijd in beslag nemen om te vernieuwen, zoals slecht geoptimaliseerde gegevensstromen ook meer tijd kunnen vragen. De volgende secties bevatten richtlijnen voor het beperken van de duur van lange vernieuwingen.
Richtlijnen voor lange vernieuwingsduur
De eerste stap om lange vernieuwingsduren voor gegevensstromen te verbeteren, is gegevensstromen te bouwen volgens de aanbevolen procedures. Belangrijke patronen zijn:
- Gebruik gekoppelde entiteiten voor gegevens die later in andere transformaties kunnen worden gebruikt.
- Gebruik berekende entiteiten om gegevens te cachen, waardoor de belasting van gegevensinvoer en -lading op bronsystemen wordt verminderd.
- Splits gegevens in faseringsgegevensstromen en transformatiegegevensstromen, waarbij de ETL wordt gescheiden in verschillende gegevensstromen.
- Uitbreidende tabelbewerkingen optimaliseren.
- Volg de richtlijnen voor complexe gegevensstromen.
Vervolgens kunt u evalueren of u incrementele vernieuwing kunt gebruiken.
Het gebruik van incrementeel vernieuwen kan de prestaties verbeteren. Het is belangrijk dat de partitiefilters naar het bronsysteem worden gepusht wanneer query's worden verzonden voor vernieuwingsbewerkingen. Als u filteren omlaag wilt pushen, betekent dit dat de gegevensbron ondersteuning moet bieden voor het vouwen van query's, of dat u bedrijfslogica kunt uitdrukken via een functie of een ander middel waarmee Power Query bestanden of mappen kan elimineren en filteren. De meeste gegevensbronnen die ondersteuning bieden voor SQL-query's ondersteunen het vouwen van query's en sommige OData-feeds kunnen ook filteren ondersteunen.
Gegevensbronnen zoals platte bestanden, blobs en API's bieden doorgaans geen ondersteuning voor filteren. In gevallen waarin de back-end van de gegevensbron het filter niet ondersteunt, kan het niet omlaag worden gepusht. In dergelijke gevallen compenseert en past de mash-up-engine het filter lokaal toe, waarvoor mogelijk het volledige semantische model uit de gegevensbron moet worden opgehaald. Deze bewerking kan ertoe leiden dat incrementeel vernieuwen traag is en dat het proces zonder voldoende resources komt te zitten, zowel in de Power BI-service als in de on-premises gegevensgateway, indien gebruikt.
Gezien de verschillende niveaus van ondersteuning voor het vouwen van query's voor elke gegevensbron, moet u verificatie uitvoeren om ervoor te zorgen dat de filterlogica is opgenomen in de bronquery's. Om dit eenvoudiger te maken, probeert Power BI deze verificatie voor u uit te voeren, met stapsgewijze indicatoren voor Power Query Online. Veel van deze optimalisaties zijn ontwerptijdervaringen, maar nadat een vernieuwing plaatsvindt, hebt u de mogelijkheid om uw vernieuwingsprestaties te analyseren en te optimaliseren.
Overweeg ten slotte om uw omgeving te optimaliseren. U kunt de Power BI-omgeving optimaliseren door uw capaciteit omhoog te schalen, de grootte van gegevensgateways te wijzigen en de netwerklatentie te verminderen met de volgende optimalisaties:
Wanneer u capaciteiten gebruikt die beschikbaar zijn met Power BI Premium of Premium per gebruiker, kunt u de prestaties verhogen door uw Premium-exemplaar te verhogen of de inhoud toe te wijzen aan een andere capaciteit.
Er is een gateway vereist wanneer Power BI toegang nodig heeft tot gegevens die niet rechtstreeks via internet beschikbaar zijn. U kunt de on-premises gegevensgateway installeren op een on-premises server of op een virtuele machine.
- Zie Het dimensioneren van de on-premises gegevensgateway voor meer informatie over gatewayworkloads en aanbevelingen voor de grootte.
- Evalueer ook hoe u de gegevens eerst in een faseringsgegevensstroom brengt en hiernaar verwijst met behulp van gekoppelde en berekende entiteiten.
Netwerklatentie kan van invloed zijn op de vernieuwingsprestaties door de tijd te verhogen die nodig is voor aanvragen om de Power BI-service te bereiken en om reacties te leveren. Tenants in Power BI worden toegewezen aan een specifieke regio. Zie De standaardregio voor uw organisatie zoeken om te bepalen waar uw tenant zich bevindt. Wanneer gebruikers van een tenant toegang hebben tot de Power BI-service, worden hun aanvragen altijd doorgestuurd naar die regio. Wanneer aanvragen de Power BI-service bereiken, kan de service vervolgens extra aanvragen verzenden, bijvoorbeeld naar de onderliggende gegevensbron of een gegevensgateway, die ook onderhevig zijn aan netwerklatentie.
- Hulpprogramma's zoals Azure Speed Test bieden een indicatie van netwerklatentie tussen de client en de Azure-regio. In het algemeen, om de impact van netwerklatentie te minimaliseren, streeft u ernaar om gegevensbronnen, gateways en uw Power BI-cluster zo dicht mogelijk bij elkaar te houden. Verblijf in dezelfde regio heeft de voorkeur. Als netwerklatentie een probleem is, kunt u gateways en gegevensbronnen dichter bij uw Power BI-cluster zoeken door ze in de cloud gehoste virtuele machines te plaatsen.
Hoge processortijd
Als u een hoge processortijd ziet, hebt u waarschijnlijk dure transformaties die niet worden gevouwen. De hoge processortijd komt door het aantal toegepaste stappen dat u hebt, of het type transformaties dat u maakt. Elk van deze mogelijkheden kan leiden tot hogere vernieuwingstijden.
Richtlijnen voor hoge processortijd
Er zijn twee opties voor het optimaliseren van hoge processortijd.
Gebruik eerst query folding binnen de gegevensbron zelf, om de belasting op de berekeningsengine van de gegevensstroom direct te verminderen. Door query's binnen de gegevensbron te vouwen, kan het bronsysteem het meeste werk doen. De gegevensstroom kan vervolgens query's doorgeven in de systeemeigen taal van de bron, in plaats van dat alle berekeningen in het geheugen na de eerste query moeten worden uitgevoerd.
Niet alle gegevensbronnen kunnen query's vouwen, en zelfs wanneer het vouwen van query's mogelijk is, zijn er mogelijk gegevensstromen die bepaalde transformaties uitvoeren die niet naar de bron kunnen worden gevouwen. In dergelijke gevallen is de verbeterde berekeningsengine een mogelijkheid die door Power BI wordt geïntroduceerd om de prestaties maximaal 25 keer te verbeteren voor transformaties.
De berekeningsengine gebruiken om de prestaties te maximaliseren
Hoewel Power Query ontwerptijdzichtbaarheid voor het vouwen van query's heeft, biedt de kolom rekenengine details over of de interne motor daadwerkelijk wordt gebruikt. De berekeningsengine is handig wanneer u een complexe gegevensstroom hebt en transformaties uitvoert in het geheugen. In deze situatie kunnen de verbeterde vernieuwingsstatistieken nuttig zijn, omdat de kolom van de berekeningsengine details bevat over het feit of de engine zelf al dan niet is gebruikt.
De volgende secties bevatten richtlijnen voor het gebruik van de rekenengine en de bijbehorende statistieken.
Waarschuwing
Tijdens de ontwerpperiode kan de vouwindicator in de editor aantonen dat de query niet samenvouwt wanneer gegevens van een andere gegevensstroom worden verbruikt. Controleer de brongegevensstroom en of verbeterde berekening is ingeschakeld om ervoor te zorgen dat het samenvoegen van gegevens in de brongegevensstroom is geactiveerd.
Richtlijnen voor de status van de berekeningsengine
Het inschakelen van de verbeterde berekeningsengine en het begrijpen van de verschillende statussen is nuttig. Intern maakt de verbeterde berekeningsengine gebruik van een SQL-database om gegevens te lezen en op te slaan. Het is raadzaam om uw transformaties hier uit te voeren op de query-engine. De volgende alinea's bieden verschillende situaties en richtlijnen over wat u voor elk moet doen.
NA - Deze status betekent dat de berekeningsengine niet is gebruikt, hetzij omdat:
- U gebruikt Power BI Pro-gegevensstromen.
- U hebt de rekenengine expliciet uitgeschakeld.
- U maakt gebruik van query folding op de gegevensbron.
- U voert complexe transformaties uit die geen gebruik kunnen maken van de SQL-engine die wordt gebruikt om query's te versnellen.
Als u langere verwerkingstijd ondervindt en nog steeds de status NA krijgt, moet u ervoor zorgen dat deze ingeschakeld is en niet per ongeluk is uitgeschakeld. Een aanbevolen patroon is het gebruik van faseringsgegevensstromen om uw gegevens in eerste instantie op te halen in de Power BI-service en vervolgens gegevensstromen te bouwen boven op deze gegevens, nadat deze zich in een faseringsgegevensstroom bevindt. Dit patroon kan de belasting van bronsystemen verminderen en samen met de rekenengine een snelheidsverbetering bieden voor transformaties en betere prestaties.
Gecached - Als u de status 'gecachete' ziet, zijn de gegevens van de gegevensstroom opgeslagen in de berekeningsengine en beschikbaar om als onderdeel van een andere query te worden geraadpleegd. Deze situatie is ideaal als u deze als gekoppelde entiteit gebruikt, omdat de computing engine die gegevens cachet voor gebruik verderop. De gegevens in de cache hoeven niet meerdere keren in dezelfde gegevensstroom te worden vernieuwd. Deze situatie is mogelijk ook ideaal als u deze wilt gebruiken voor DirectQuery.
Wanneer gegevens worden opgeslagen in een cache, loont de prestatie-impact van de eerste gegevensinvoer later, in dezelfde gegevensstroom of in een andere gegevensstroom binnen dezelfde werkruimte.
Als u een lange duur voor de entiteit hebt, kunt u overwegen de rekenengine uit te schakelen. Als u de entiteit in de cache wilt opslaan, schrijft Power BI deze naar de opslag en naar SQL. Als het een entiteit voor eenmalig gebruik is, is het prestatievoordeel voor gebruikers mogelijk niet het nadeel van de dubbele opname waard.
Gevouwen : gevouwen betekent dat de gegevensstroom SQL-rekenkracht kon gebruiken om gegevens te lezen. De berekende entiteit heeft de tabel uit SQL gebruikt om gegevens te lezen en de GEBRUIKTE SQL is gerelateerd aan de constructies van de query.
De gevouwen status verschijnt als u, bij het gebruik van on-premises of cloudgegevensbronnen, eerst gegevens in een staging dataflow hebt geladen en deze in deze gegevensstroom hebt gerefereerd. Deze status is alleen van toepassing op entiteiten die verwijzen naar een andere entiteit. Dit betekent dat uw query's boven op de SQL-engine zijn uitgevoerd en dat ze de mogelijkheid hebben om te worden verbeterd met SQL-rekenkracht. Gebruik transformaties die ondersteuning bieden voor SQL-vouwen, zoals samenvoegen (join), groeperen (aggregatie), en toevoegen (union) acties in de Query-editor om ervoor te zorgen dat de SQL-engine uw transformaties verwerkt.
Cached + Folded - Wanneer u 'cached + folded' ziet, is het waarschijnlijk dat het vernieuwen van gegevens geoptimaliseerd is, omdat u een entiteit hebt die zowel naar een andere entiteit verwijst als waarnaar wordt verwezen door een andere entiteit in een eerdere fase. Deze bewerking wordt ook uitgevoerd boven op de SQL en heeft als zodanig ook de mogelijkheid om te verbeteren met SQL-rekenkracht. Gebruik transformaties die SQL Folding ondersteunen, zoals samenvoegen (join), groeperen op (aggregatie), en toevoegen (union) in de Query-editor om ervoor te zorgen dat u de beste prestaties krijgt.
Richtlijnen voor optimalisatie van de prestaties van de berekeningsengine
Met de volgende stappen kunnen workloads de berekeningsengine activeren, waardoor de prestaties altijd worden verbeterd.
Berekende en gekoppelde entiteiten in dezelfde werkruimte:
Voor opname kunt u zich richten op het zo snel mogelijk ophalen van de gegevens in de opslag. Gebruik filters alleen als ze de totale semantische modelgrootte verminderen. Houd uw transformatielogica gescheiden van deze stap. Scheid vervolgens uw transformatie en bedrijfslogica in een afzonderlijke gegevensstroom in dezelfde werkruimte. Gekoppelde of berekende entiteiten gebruiken. Hierdoor kan de engine uw berekeningen activeren en versnellen. Voor een eenvoudige analogie: het is net als voedselbereiding in een keuken. Voedselbereiding is meestal een afzonderlijke en duidelijke stap van het verzamelen van je onbewerkte ingrediënten en een vereiste voor het plaatsen van het voedsel in de oven. Op dezelfde manier moet u uw logica afzonderlijk voorbereiden voordat deze kan profiteren van de berekeningsengine.
Zorg ervoor dat u de bewerkingen uitvoert die integreren, zoals samenvoegingen, koppelingen, conversies en andere.
Bouw ook gegevensstromen binnen gepubliceerde richtlijnen en beperkingen.
Wanneer de berekeningsengine is ingeschakeld, maar de prestaties traag zijn:
Voer de volgende stappen uit bij het onderzoeken van scenario's waarin de berekeningsengine is ingeschakeld, maar u ziet slechte prestaties:
- Beperk berekende en gekoppelde entiteiten die in de werkruimte bestaan.
- Als uw eerste vernieuwing met de rekenengine ingeschakeld is, worden gegevens geschreven in het data lake en in de cache. Deze dubbele schrijfbewerking resulteert in een tragere vernieuwing.
- Als u een gegevensstroom hebt die is gekoppeld aan meerdere gegevensstromen, moet u ervoor zorgen dat u vernieuwingen van de brongegevensstromen plant, zodat ze niet allemaal tegelijk worden vernieuwd.
Overwegingen en beperkingen
Een Power BI Pro-licentie heeft een vernieuwingslimiet van 8 vernieuwingen per dag voor gegevensstromen.