Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Als de gegevensstroom die u ontwikkelt groter en complexer wordt, kunt u hier enkele dingen doen om uw oorspronkelijke ontwerp te verbeteren.
Deze opsplitsen in meerdere gegevensstromen
Doe niet alles in één gegevensstroom. Niet alleen maakt één complexe gegevensstroom het gegevenstransformatieproces langer, maar het maakt het ook moeilijker om de gegevensstroom te begrijpen en opnieuw te gebruiken. U kunt uw gegevensstroom opsplitsen in meerdere gegevensstromen door tabellen in verschillende gegevensstromen te scheiden of zelfs één tabel in meerdere gegevensstromen. U kunt het concept van een berekende tabel of gekoppelde tabel gebruiken om een deel van de transformatie in één gegevensstroom te maken en deze opnieuw te gebruiken in andere gegevensstromen.
Gegevensstromen voor gegevenstransformatie splitsen van faserings-/extractiegegevensstromen
Sommige gegevensstromen alleen voor het extraheren van gegevens (d.z. fasering van gegevensstromen) en andere alleen voor het transformeren van gegevens is niet alleen handig voor het maken van een meerlaagse architectuur, maar ook voor het verminderen van de complexiteit van gegevensstromen. In sommige stappen worden alleen gegevens uit de gegevensbron geëxtraheerd, zoals het ophalen van gegevens, navigatie en wijzigingen in het gegevenstype. Door de faseringsgegevensstromen en transformatiegegevensstromen te scheiden, kunt u uw gegevensstromen eenvoudiger ontwikkelen.
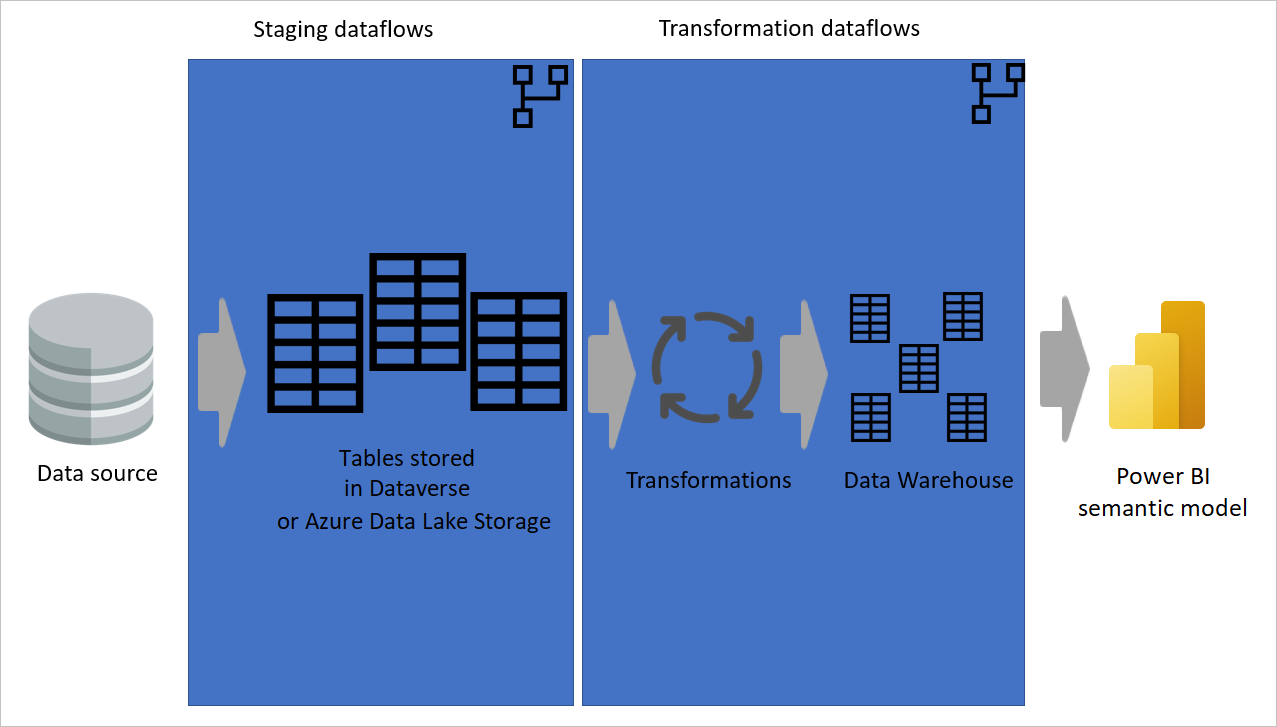
Afbeelding van gegevens die worden geëxtraheerd uit een gegevensbron naar faseringsgegevensstromen, waarbij de tabellen worden opgeslagen in Dataverse of Azure Data Lake Storage. Vervolgens worden de gegevens verplaatst naar transformatiegegevensstromen waarin de gegevens worden getransformeerd en geconverteerd naar de datawarehouse-structuur. Vervolgens worden de gegevens verplaatst naar het semantische model.
Aangepaste functies gebruiken
Aangepaste functies zijn handig in scenario's waarin een bepaald aantal stappen moet worden uitgevoerd voor een aantal query's uit verschillende bronnen. Aangepaste functies kunnen worden ontwikkeld via de grafische interface in De Power Query-editor of met behulp van een M-script. Functies kunnen worden hergebruikt in een gegevensstroom in zo veel tabellen als nodig is.
Het gebruik van een aangepaste functie helpt door slechts één versie van de broncode te hebben, dus u hoeft de code niet te dupliceren. Als gevolg hiervan is het onderhouden van de Power Query-transformatielogica en de hele gegevensstroom veel eenvoudiger. Ga voor meer informatie naar het volgende blogbericht: Custom Functions Made Easy in Power BI Desktop.
Opmerking
Soms ontvangt u mogelijk een melding die aangeeft dat een Premium-capaciteit is vereist voor het vernieuwen van een gegevensstroom met een aangepaste functie. U kunt dit bericht negeren en de gegevensstroomeditor opnieuw openen. Dit lost uw probleem meestal op, tenzij uw functie verwijst naar een query met 'belasting ingeschakeld'.
Queries in mappen plaatsen
Het gebruik van mappen voor query's helpt bij het groeperen van gerelateerde query's. Besteed bij het ontwikkelen van de gegevensstroom wat meer tijd aan het rangschikken van query's in mappen die zinvol zijn. Met deze methode kunt u query's in de toekomst gemakkelijker vinden en de code onderhouden is veel eenvoudiger.
Berekende tabellen gebruiken
Berekende tabellen maken uw gegevensstroom niet alleen begrijpelijker, maar bieden ook betere prestaties. Wanneer u een berekende tabel gebruikt, worden in de andere tabellen waarnaar wordt verwezen gegevens opgehaald uit een tabel die al is verwerkt en opgeslagen. De transformatie is veel eenvoudiger en sneller.
Profiteren van de verbeterde berekeningsengine
Voor gegevensstromen die zijn ontwikkeld in de Power BI-beheerportal, moet u ervoor zorgen dat u de verbeterde berekeningsengine gebruikt door eerst joins en filtertransformaties uit te voeren in een berekende tabel voordat u andere typen transformaties uitvoert.
Veel stappen in meerdere query's opsplitsen
Het is moeilijk om een groot aantal stappen in één tabel bij te houden. In plaats daarvan moet u een groot aantal stappen in meerdere tabellen opsplitsen. U kunt Laden inschakelen voor andere query's gebruiken en uitschakelen als ze tussenliggende query's zijn en alleen de uiteindelijke tabel via de gegevensstroom laden. Wanneer u meerdere query's met kleinere stappen in elke query hebt, is het eenvoudiger om het afhankelijkheidsdiagram te gebruiken en elke query bij te houden voor verder onderzoek, in plaats van honderden stappen in één query te graven.
Eigenschappen voor query's en stappen toevoegen
Documentatie is de sleutel tot het eenvoudig onderhouden van code. In Power Query kunt u eigenschappen toevoegen aan de tabellen en ook aan stappen. De tekst die u in de eigenschappen toevoegt, wordt weergegeven als knopinfo wanneer u de muisaanwijzer op die query of stap plaatst. Deze documentatie helpt u bij het onderhouden van uw model in de toekomst. In een oogopslag in een tabel of stap begrijpt u wat er gebeurt, in plaats van te herzien en te onthouden wat u in die stap hebt gedaan.
Zorg ervoor dat de capaciteit zich in dezelfde regio bevindt
Gegevensstromen ondersteunen momenteel niet meerdere landen of regio's. De Premium-capaciteit moet zich in dezelfde regio bevinden als uw Power BI-tenant.
Scheid on-premises bronnen van cloudbronnen
U wordt aangeraden een afzonderlijke gegevensstroom te maken voor elk type bron, zoals on-premises, cloud, SQL Server, Spark en Dynamics 365. Het scheiden van gegevensstromen op brontype vergemakkelijkt snelle probleemoplossing en voorkomt interne limieten wanneer u uw gegevensstromen vernieuwt.
Afzonderlijke gegevensstromen op basis van de geplande vernieuwing die vereist is voor tabellen
Als u een verkooptransactietabel hebt die elk uur wordt bijgewerkt in het bronsysteem en u een tabel met producttoewijzing hebt die elke week wordt bijgewerkt, breekt u deze twee tabellen op in twee gegevensstromen met verschillende schema's voor gegevensvernieuwing.
Voorkom het inplannen van vernieuwing voor gekoppelde tabellen in dezelfde werkruimte
Als uw gegevensstromen die gekoppelde tabellen bevatten, regelmatig worden vergrendeld, kan dit worden veroorzaakt door een bijbehorende, afhankelijke gegevensstroom in dezelfde werkruimte die is vergrendeld tijdens het vernieuwen van de gegevensstroom. Dergelijke vergrendeling biedt transactie nauwkeurigheid en zorgt ervoor dat beide gegevensstromen succesvol worden vernieuwd, maar het kan u blokkeren bij het bewerken.
Als u een afzonderlijke planning instelt voor de gekoppelde gegevensstroom, kunnen gegevensstromen onnodig worden vernieuwd en kunt u de gegevensstroom niet bewerken. Er zijn twee aanbevelingen om dit probleem te voorkomen:
- Stel geen vernieuwingsschema in voor een gekoppelde gegevensstroom in dezelfde werkruimte als de brongegevensstroom.
- Als u een vernieuwingsschema afzonderlijk wilt configureren en het vergrendelingsgedrag wilt voorkomen, verplaatst u de gegevensstroom naar een afzonderlijke werkruimte.