Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Aanbeveling
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel wordt beschreven hoe u de kopieeractiviteit gebruikt in een Azure Data Factory- of Synapse Analytics-pijplijn om gegevens uit Spark te kopiëren. Het bouwt voort op het artikel overzicht van kopieeractiviteiten dat een algemeen overzicht van kopieeractiviteit presenteert.
Belangrijk
De Spark-connector versie 1.0 bevindt zich in de verwijderingsfase. U wordt aangeraden om de Spark-connector te upgraden van versie 1.0 naar 2.0.
Ondersteunde mogelijkheden
Deze Spark-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Kopieeractiviteit (bron/-) | (1) (2) |
| Zoekactiviteit | (1) (2) |
(1) Azure-integratieruntime (2) Zelfgehoste integratieruntime
Zie de tabel Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen/sinks door de kopieeractiviteit.
De service biedt een ingebouwd stuurprogramma om connectiviteit in te schakelen, daarom hoeft u geen stuurprogramma handmatig te installeren met behulp van deze connector.
Vereiste voorwaarden
Als uw gegevensarchief zich in een on-premises netwerk, een virtueel Azure-netwerk of een virtuele particuliere cloud van Amazon bevindt, moet u een zelf-hostende Integration Runtime configureren om er verbinding mee te maken.
Als uw gegevensarchief een beheerde cloudgegevensservice is, kunt u De Azure Integration Runtime gebruiken. Als de toegang is beperkt tot IP-adressen die zijn goedgekeurd in de firewallregels, kunt u IP-adressen van Azure Integration Runtime toevoegen aan de acceptatielijst.
U kunt ook de beheerde functie voor integratieruntime voor virtuele netwerken in Azure Data Factory gebruiken om toegang te krijgen tot het on-premises netwerk zonder een zelf-hostende Integration Runtime te installeren en te configureren.
Zie Strategieën voor gegevenstoegang voor meer informatie over de netwerkbeveiligingsmechanismen en -opties die door Data Factory worden ondersteund.
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Tool Gegevens kopiëren
- Azure-portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST API
- Azure Resource Manager-sjabloon
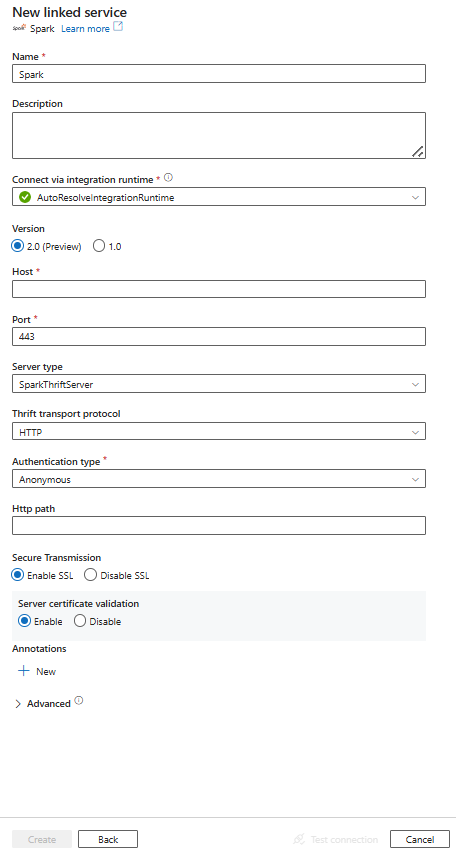
Een gekoppelde service maken voor Spark met behulp van de gebruikersinterface
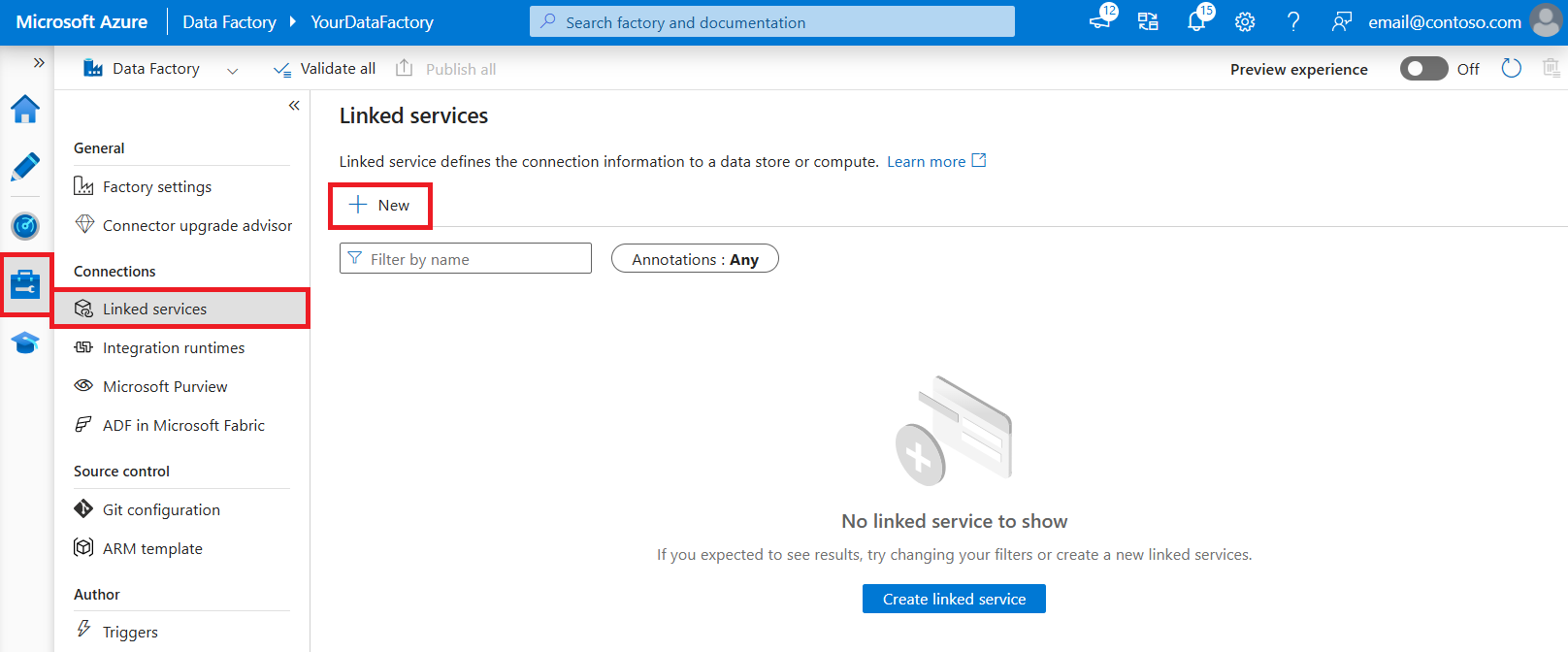
Gebruik de volgende stappen om een gekoppelde service te maken voor Spark in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Spark en selecteer de Spark-connector.

Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
Details van de configuratie van de connector
De volgende secties bevatten details over eigenschappen die worden gebruikt voor het definiëren van Data Factory-entiteiten die specifiek zijn voor Spark-connector.
Eigenschappen van gekoppelde service
De Spark-connector ondersteunt nu versie 2.0. Raadpleeg deze sectie om uw Spark-connectorversie bij te werken vanaf versie 1.0. Raadpleeg de desbetreffende secties voor de details van de eigendom.
Versie 2.0
De volgende eigenschappen worden ondersteund voor gekoppelde Spark-serviceversie 2.0:
| Vastgoed | Beschrijving | Verplicht |
|---|---|---|
| soort | De eigenschap Type moet worden ingesteld op: Spark | Ja |
| Versie | De versie die je opgeeft. De waarde is 2.0. |
Ja |
| gastheer | IP-adres of hostnaam van de Spark-server | Ja |
| poort/haven | De TCP-poort die de Spark-server gebruikt om te luisteren naar clientverbindingen. Als u verbinding maakt met Azure HDInsight, geeft u poort op als 443. | Ja |
| serverType | Het type Spark-server. De toegestane waarde is: SparkThriftServer |
Nee. |
| spaarzaamheidTransportProtocol | Het transportprotocol dat moet worden gebruikt in de Thrift-laag. De toegestane waarde is: HTTP |
Nee. |
| authenticatietype | De verificatiemethode die wordt gebruikt voor toegang tot de Spark-server. Toegestane waarden zijn: Anoniem, UsernameAndPassword, WindowsAzureHDInsightService |
Ja |
| gebruikersnaam | De gebruikersnaam die u gebruikt voor toegang tot Spark Server. | Nee. |
| wachtwoord | Het wachtwoord dat overeenkomt met de gebruiker. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Nee. |
| httpPath | De gedeeltelijke URL die overeenkomt met de Spark-server. Voor het verificatietype WindowsAzureHDInsightService is /sparkhive2de standaardwaarde . |
Nee. |
| SSL inschakelen | Hiermee geeft u op of de verbindingen met de server zijn versleuteld met behulp van TLS. De standaardwaarde is waar. | Nee. |
| inschakelenServerCertificaatValidatie | Geef op of u ssl-certificaatvalidatie van de server wilt inschakelen wanneer u verbinding maakt. Gebruik altijd System Trust Store. De standaardwaarde is waar. |
Nee. |
| connectVia | De Integration Runtime die gebruikt moet worden om verbinding te maken met de datastore. Raadpleeg de sectie Vereisten voor meer informatie. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee. |
Voorbeeld:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"version": "2.0",
"typeProperties": {
"host": "<cluster>.azurehdinsight.net",
"port": "<port>",
"authenticationType": "WindowsAzureHDInsightService",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Versie 1.0
De volgende eigenschappen worden ondersteund voor versie 1.0 van de gekoppelde Spark-service:
| Vastgoed | Beschrijving | Verplicht |
|---|---|---|
| soort | De eigenschap Type moet worden ingesteld op: Spark | Ja |
| gastheer | IP-adres of hostnaam van de Spark-server | Ja |
| poort/haven | De TCP-poort die de Spark-server gebruikt om te luisteren naar clientverbindingen. Als u verbinding maakt met Azure HDInsight, geeft u poort op als 443. | Ja |
| serverType | Het type Spark-server. Toegestane waarden zijn: SharkServer, SharkServer2, SparkThriftServer |
Nee. |
| spaarzaamheidTransportProtocol | Het transportprotocol dat moet worden gebruikt in de Thrift-laag. Toegestane waarden zijn: Binair, SASL, HTTP |
Nee. |
| authenticatietype | De verificatiemethode die wordt gebruikt voor toegang tot de Spark-server. Toegestane waarden zijn: Anoniem, Gebruikersnaam, UsernameAndPassword, WindowsAzureHDInsightService |
Ja |
| gebruikersnaam | De gebruikersnaam die u gebruikt voor toegang tot Spark Server. | Nee. |
| wachtwoord | Het wachtwoord dat overeenkomt met de gebruiker. Markeer dit veld als SecureString om het veilig op te slaan of verwijs naar een geheim dat is opgeslagen in Azure Key Vault. | Nee. |
| httpPath | De gedeeltelijke URL die overeenkomt met de Spark-server. | Nee. |
| SSL inschakelen | Hiermee geeft u op of de verbindingen met de server zijn versleuteld met behulp van TLS. De standaardwaarde is onwaar. | Nee. |
| trustedCertPath | Het volledige pad van het PEM-bestand met vertrouwde CA-certificaten voor het verifiëren van de server bij het maken van verbinding via TLS. Deze eigenschap kan alleen worden ingesteld wanneer u TLS gebruikt op zelf-hostende IR. De standaardwaarde is het cacerts.pem-bestand dat is geïnstalleerd met de IR. | Nee. |
| gebruikSystemTrustStore | Hiermee geeft u op of u een CA-certificaat uit het systeemvertrouwensarchief of een opgegeven PEM-bestand wilt gebruiken. De standaardwaarde is onwaar. | Nee. |
| toestaanHostNameCNMismatch | Hiermee geeft u op of een door een CA uitgegeven TLS/SSL-certificaatnaam moet overeenkomen met de hostnaam van de server bij het maken van verbinding via TLS. De standaardwaarde is onwaar. | Nee. |
| toestaanZelfondertekendServerCertificaat | Hiermee geeft u op of zelfondertekende certificaten van de server moeten worden toegestaan. De standaardwaarde is onwaar. | Nee. |
| connectVia | De Integration Runtime die gebruikt moet worden om verbinding te maken met de datastore. Raadpleeg de sectie Vereisten voor meer informatie. Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nee. |
Voorbeeld:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host": "<cluster>.azurehdinsight.net",
"port": "<port>",
"authenticationType": "WindowsAzureHDInsightService",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Eigenschappen van gegevensset
Voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van datasets, zie het artikel gegevenssets. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Spark-gegevensset.
Als u gegevens uit Spark wilt kopiëren, stelt u de typeeigenschap van de gegevensset in op SparkObject. De volgende eigenschappen worden ondersteund:
| Vastgoed | Beschrijving | Verplicht |
|---|---|---|
| soort | De typeeigenschap van de gegevensset moet zijn ingesteld op: SparkObject | Ja |
| overzicht | Naam van het schema. | Nee (als 'query' in de bron van de activiteit staat vermeld) |
| tafel | Naam van de tabel. | Nee (als 'query' in de bron van de activiteit staat vermeld) |
| tabelnaam | Naam van de tabel met schema. Deze eigenschap wordt ondersteund voor compatibiliteit met eerdere versies. Gebruik schema en table voor nieuwe workload. |
Nee (als 'query' in de bron van de activiteit staat vermeld) |
Voorbeeld
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van activiteiten. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door spark-bron.
Spark als bron
Als u gegevens uit Spark wilt kopiëren, stelt u het brontype in de kopieeractiviteit in op SparkSource. De volgende eigenschappen worden ondersteund in de sectie bron van kopieeractiviteit:
| Vastgoed | Beschrijving | Verplicht |
|---|---|---|
| soort | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op: SparkSource | Ja |
| zoekopdracht | Gebruik de aangepaste SQL-query om gegevens te lezen. Voorbeeld: "SELECT * FROM MyTable". |
Nee (als 'tableName' in de gegevensset is opgegeven) |
Voorbeeld:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Toewijzing van gegevenstypen voor Spark
Wanneer u gegevens van en naar Spark kopieert, worden de volgende tijdelijke toewijzingen van gegevenstypen binnen de service gebruikt. Zie Schema- en gegevenstypetoewijzingen voor meer informatie over hoe de kopieeractiviteit het bronschema en het gegevenstype toewijst aan de sink.
| Spark-gegevenstype | Tussentijds servicedatatype (voor versie 2.0) | Interim service-gegevenssoort (voor versie 1.0) |
|---|---|---|
| Boolean-type | Booleaans | Booleaans |
| ByteType | Sbyte | Int16 |
| ShortType | Int16 | Int16 |
| IntegerType | Int32 | Int32 |
| LongType | Int64 | Int64 |
| FloatType | Ongetrouwd | Ongetrouwd |
| Dubbeltype | Dubbel | Dubbel |
| DatumType | Datum/tijd | Datum/tijd |
| TijdstempelType | DateTimeOffset | Datum/tijd |
| StringType | Tekenreeks | Tekenreeks |
| Binaire Type | Byte[] | Byte[] |
| DecimaalType | Decimaal | Decimaal Tekenreeks (precisie > 28) |
| ArrayType | Tekenreeks | Tekenreeks |
| StructType | Tekenreeks | Tekenreeks |
| KaartType | Tekenreeks | Tekenreeks |
| TimestampNTZType | Datum/tijd | Datum/tijd |
| JaarMaandIntervalType | Tekenreeks | Wordt niet ondersteund. |
| DagTijdsintervalType | Tekenreeks | Wordt niet ondersteund. |
Eigenschappen van opzoekactiviteit
Om meer te weten te komen over de eigenschappen, raadpleegt u Lookup activity.
Levenscyclus en upgrade van Spark-connector
In de volgende tabel ziet u de releasefase en wijzigingslogboeken voor verschillende versies van de Spark-connector:
| Versie | Releasefase | Wijzigingslogboek |
|---|---|---|
| Versie 1.0 | Removed | Niet van toepassing. |
| Versie 2.0 | GA-versie beschikbaar | • enableServerCertificateValidation wordt ondersteund. • De standaardwaarde van enableSSL is True. • Voor het verificatietype WindowsAzureHDInsightService is de standaardwaarde httpPath ./sparkhive2• DecimalType wordt gelezen als decimaal gegevenstype. • TimestampType wordt gelezen als het DateTimeOffset-gegevenstype. • YearMonthIntervalType, DayTimeIntervalType worden gelezen als tekenreeksgegevenstype. • trustedCertPath, useSystemTrustStoreen allowHostNameCNMismatchallowSelfSignedServerCert worden niet ondersteund. • SharkServer en SharkServer2 worden niet ondersteund voor serverType. • Binair en SASL worden niet ondersteund voor thriftTransportProtocl. • Verificatietype voor gebruikersnaam wordt niet ondersteund. |
De Spark-connector upgraden van versie 1.0 naar versie 2.0
Selecteer op de pagina Gekoppelde service bewerken 2.0 voor versie en configureer de gekoppelde service door te verwijzen naar de eigenschappen van de gekoppelde service versie 2.0.
De gegevenstype-toewijzing voor de gekoppelde Spark-service versie 2.0 verschilt van de toewijzing voor versie 1.0. Zie Gegevenstypetoewijzing voor Spark voor meer informatie over de meest recente toewijzing van gegevenstypen.
Verwante inhoud
Zie ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door de kopieeractiviteit.