Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Aanbeveling
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Gegevensstromen zijn beschikbaar in zowel Azure Data Factory-pijplijnen als Azure Synapse Analytics-pijplijnen. Dit artikel is van toepassing op het in kaart brengen van datastromen. Als u nieuw bent met transformaties, raadpleegt u het inleidende artikel Gegevens transformeren met behulp van mapping-dataflows.
Nadat u klaar bent met het transformeren van uw gegevens, schrijft u deze in een doelarchief met behulp van de sinktransformatie. Voor elke gegevensstroom is ten minste één sink-transformatie vereist, maar u kunt naar zoveel sinks schrijven als nodig is om uw transformatiestroom te voltooien. Als u naar extra sinks wilt schrijven, maakt u nieuwe streams via nieuwe branches en voorwaardelijke splitsingen.
Elke sink-transformatie is gekoppeld aan precies één gegevensset, object of gekoppelde service. De sink-transformatie bepaalt de vorm en locatie van de gegevens waarnaar u wilt schrijven.
Inline gegevenssets
Wanneer u een sinktransformatie maakt, kiest u of uw sink-informatie wordt gedefinieerd in een gegevenssetobject of binnen de sinktransformatie. De meeste indelingen zijn slechts in één van beide beschikbaar. Zie het juiste connectordocument voor meer informatie over het gebruik van een specifieke connector.
Wanneer een indeling wordt ondersteund voor zowel inline als in een gegevenssetobject, zijn er voordelen aan beide opties. Gegevenssetobjecten zijn herbruikbare entiteiten die kunnen worden gebruikt in andere gegevensstromen en activiteiten zoals Kopiëren. Deze herbruikbare entiteiten zijn vooral handig wanneer u een beperkt schema gebruikt. Gegevenssets zijn niet gebaseerd op Spark. Af en toe moet u mogelijk bepaalde instellingen of schemaprojectie overschrijven in de sinktransformatie.
Inline-gegevenssets worden aanbevolen wanneer u flexibele schema's, eenmalige sink-exemplaren of geparametriseerde sinks gebruikt. Als uw sink sterk geparametriseerd is, kunt u met inline datasets geen "dummy"-object maken. Inlinegegevenssets zijn gebaseerd op Spark en hun eigenschappen zijn onderdeel van de gegevensstroom.
Als u een inline gegevensset wilt gebruiken, selecteert u de gewenste indeling in de kiezer voor het type Sink . In plaats van een sink-gegevensset te selecteren, selecteert u de gekoppelde service waarmee u verbinding wilt maken.
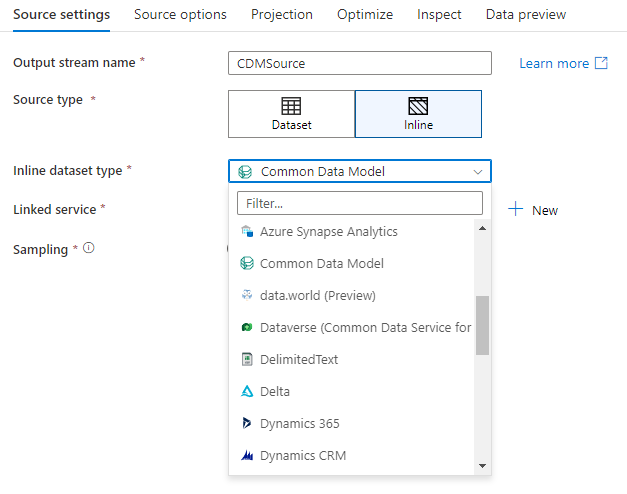
Werkruimtedatabase (alleen Synapse-werkruimten)
Wanneer u gegevensstromen gebruikt in Azure Synapse-werkruimten, hebt u een extra optie om uw gegevens rechtstreeks in een databasetype te plaatsen dat zich in uw Synapse-werkruimte bevindt. Dit zal de noodzaak verlichten om gekoppelde services of datasets voor die databases toe te voegen. De databases die zijn gemaakt via de Azure Synapse-databasesjablonen , zijn ook toegankelijk wanneer u Werkruimtedatabase selecteert.
Opmerking
De Azure Synapse Workspace DB-connector is momenteel beschikbaar als openbare preview en kan op dit moment alleen werken met Spark Lake-databases
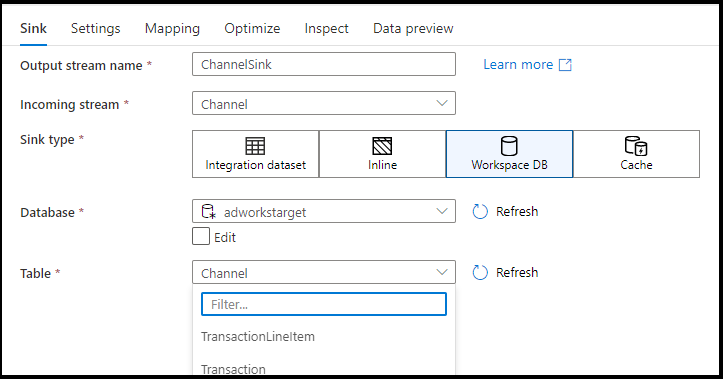
Ondersteunde spoelbaktypes
Toewijzingsgegevensstroom volgt een ELT-benadering (EXTRAHEREN, laden en transformeren) en werkt met faseringsgegevenssets die zich allemaal in Azure bevinden. Momenteel kunnen de volgende gegevenssets worden gebruikt in een sink-transformatie.
Aanbeveling
Uw gootsteen kan een ander formaat hebben dan uw bron. Dit is een stap van hoe u van het ene formaat naar het andere kunt transformeren. Bijvoorbeeld van een CSV tot een Parket-spoelbak. Mogelijk moet u enkele transformaties aanbrengen in uw gegevensstroom tussen bron en sink om dit correct te laten werken. (Parket heeft bijvoorbeeld meer specifieke koptekstvereisten dan CSV.)
| Verbinder | Formaat | Gegevensset/inline |
|---|---|---|
| Azure Blob-opslagruimte |
Avro Gescheiden tekst Delta JSON ORK Parket |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB voor NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro Gescheiden tekst JSON ORK Parket |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
Avro Common Data Model Gescheiden tekst Delta JSON ORK Parket |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database voor MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Azure SQL Managed Instance | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Stof Lakehouse | ✓/✓ | |
| SFTP |
Avro Gescheiden tekst JSON ORK Parket |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Sneeuwvlok | ✓/✓ | |
| SQL Server | ✓/✓ |
Instellingen die specifiek zijn voor deze connectors bevinden zich op het tabblad Instellingen . Voorbeelden van scripts voor informatie en gegevensstromen over deze instellingen bevinden zich in de documentatie van de connector.
De service heeft toegang tot meer dan 90 native connectoren. Als u gegevens uit uw gegevensstroom naar die andere bronnen wilt schrijven, gebruikt u de kopieeractiviteit om die gegevens te laden vanaf een ondersteunde sink.
Spoelbak instellingen
Nadat je een spoelbak hebt toegevoegd, configureer je deze via het tabblad Spoelbak . Hier kunt u de dataset kiezen of maken waarnaar uw sink schrijft. Ontwikkelingswaarden voor gegevenssetparameters kunnen worden geconfigureerd in de instellingen voor foutopsporing. (De foutopsporingsmodus moet zijn ingeschakeld.)
In de volgende video worden een aantal verschillende sink-opties voor door tekst gescheiden bestandstypen uitgelegd.
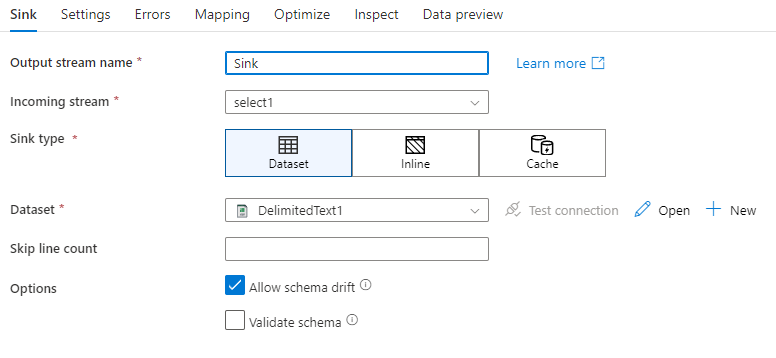
Schemadrift: Schemadrift is de mogelijkheid van de service om flexibele schema's in uw gegevensstromen systeemeigen af te handelen zonder dat u expliciet kolomwijzigingen hoeft te definiëren. Schakel Schemadrift toestaan in om extra kolommen te schrijven bovenop wat is gedefinieerd in het schema voor sinkgegevens.
Schema valideren: als schema valideren is geselecteerd, mislukt de gegevensstroom als een kolom in sinkprojectie niet wordt gevonden in het sink-archief of als de gegevenstypen niet overeenkomen. Gebruik deze instelling om af te dwingen dat het sink-schema voldoet aan het contract van uw gedefinieerde projectie. Het is handig in scenario's voor databasesink om aan te geven dat kolomnamen of -typen zijn gewijzigd.
Cache zinken
Een cachesink is wanneer een gegevensstroom gegevens naar de Spark-cache schrijft in plaats van naar een gegevensarchief. Bij het toewijzen van gegevensstromen kunt u vele malen naar deze gegevens binnen dezelfde stroom verwijzen met behulp van een cache-opzoekopdracht. Dit is handig wanneer u naar gegevens wilt verwijzen als onderdeel van een expressie, maar de kolommen niet expliciet wilt koppelen. Veelvoorkomende voorbeelden waar een cachesink kan helpen, zijn het opzoeken van een maximale waarde in een gegevensarchief en het matchen van foutcodes met een database met foutmeldingen.
Als u naar een cachesink wilt schrijven, voegt u een sinktransformatie toe en selecteert u Cache als het sinktype. In tegenstelling tot andere sink-typen hoeft u geen gegevensset of gekoppelde service te selecteren omdat u niet naar een extern archief schrijft.
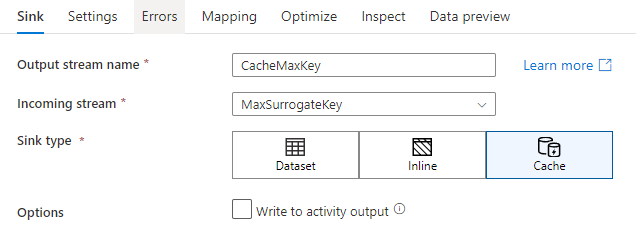
In de sink-instellingen kunt u optioneel de belangrijkste kolommen van de cachesink opgeven. Deze worden gebruikt als overeenkomende voorwaarden bij het gebruik van de lookup() functie in een cache-zoekopdracht. Als u sleutelkolommen opgeeft, kunt u de outputs() functie niet gebruiken in een cache-opzoekopdracht. Zie Opzoekacties in cache voor meer informatie over de syntaxis voor het opzoeken in cache.
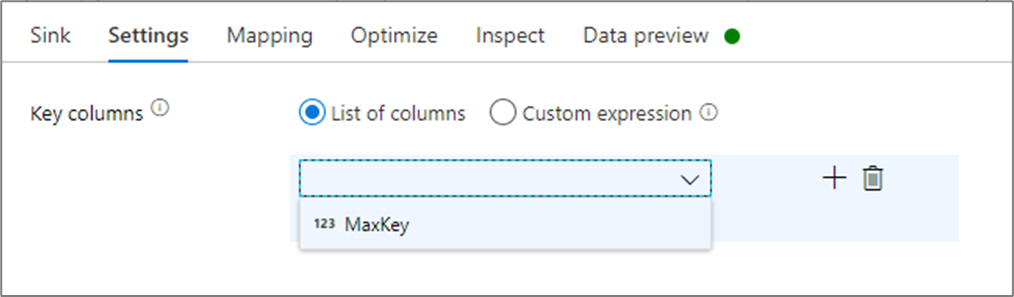
Als ik bijvoorbeeld een enkele sleutelkolom opgeef in column1 een cachesink met de naam cacheExample, zou aanroepen cacheExample#lookup() één parameter hebben die aangeeft op welke rij in de cachesink moet worden gematcht. De functie voert één complexe kolom uit met subkolommen voor elke toegewezen kolom.
Opmerking
Een cachesink moet zich in een volledig onafhankelijke gegevensstroom bevinden van elke transformatie waarnaar wordt verwezen via een cache-lookup. Een cache-sink moet ook de eerste geschreven sink zijn.
Schrijven naar activiteitsuitvoer
De Cache-sink kan optioneel zijn gegevens schrijven naar de uitvoer van de Data Flow-activiteit, die vervolgens kan worden gebruikt als invoer voor een andere activiteit in de pijplijn. Hierdoor kunt u snel en eenvoudig gegevens uit uw gegevensstroomactiviteit halen zonder dat u de gegevens in een gegevensarchief hoeft te bewaren.
Houd er rekening mee dat de uitvoer van Data Flow die rechtstreeks in uw pijplijn wordt geïnjecteerd, beperkt is tot 2 MB. Gegevensstroom zal dus proberen zoveel mogelijk rijen aan de uitvoer toe te voegen terwijl deze binnen de limiet van 2 MB blijft, daarom ziet u soms niet alle rijen in de activiteitsuitvoer. Als u 'Alleen eerste rij' instelt op het activiteitsniveau van de gegevensstroom, kunt u indien nodig ook de gegevensuitvoer van de gegevensstroom beperken.
Update-methode
Voor databasesinktypen bevat het tabblad Instellingen de eigenschap 'Methode bijwerken'. De standaardinstelling is invoegen, maar bevat ook selectievakjes voor bijwerken, upsert en verwijderen. Om deze extra opties te gebruiken, moet u een Alter Row-transformatie toevoegen vóór de sink. Met de rij Wijzigen kunt u de voorwaarden voor elk van de databaseacties definiëren. Als uw bron een systeemeigen CDC-inschakelbron is, kunt u de updatemethoden instellen zonder een Alter Row, aangezien ADF al op de hoogte is van de rijmarkeringen voor invoegen, bijwerken, upsert en verwijderen.
Veldtoewijzing
Net als bij een selectietransformatie kunt u op het tabblad Toewijzing van de sink bepalen welke binnenkomende kolommen worden geschreven. Standaard worden alle invoerkolommen, inclusief driftkolommen, in kaart gebracht. Dit gedrag wordt automapping genoemd.
Wanneer u automatisch toewijzen uitschakelt, kunt u vaste toewijzingen op basis van kolommen of op regels gebaseerde toewijzingen toevoegen. Met toewijzingen op basis van regels kunt u expressies schrijven met patroonovereenkomst. Vaste toewijzing brengt logische en fysieke kolomnamen in kaart. Zie Kolompatronen in toewijzingsgegevensstroom voor meer informatie over toewijzing op basis van regels.
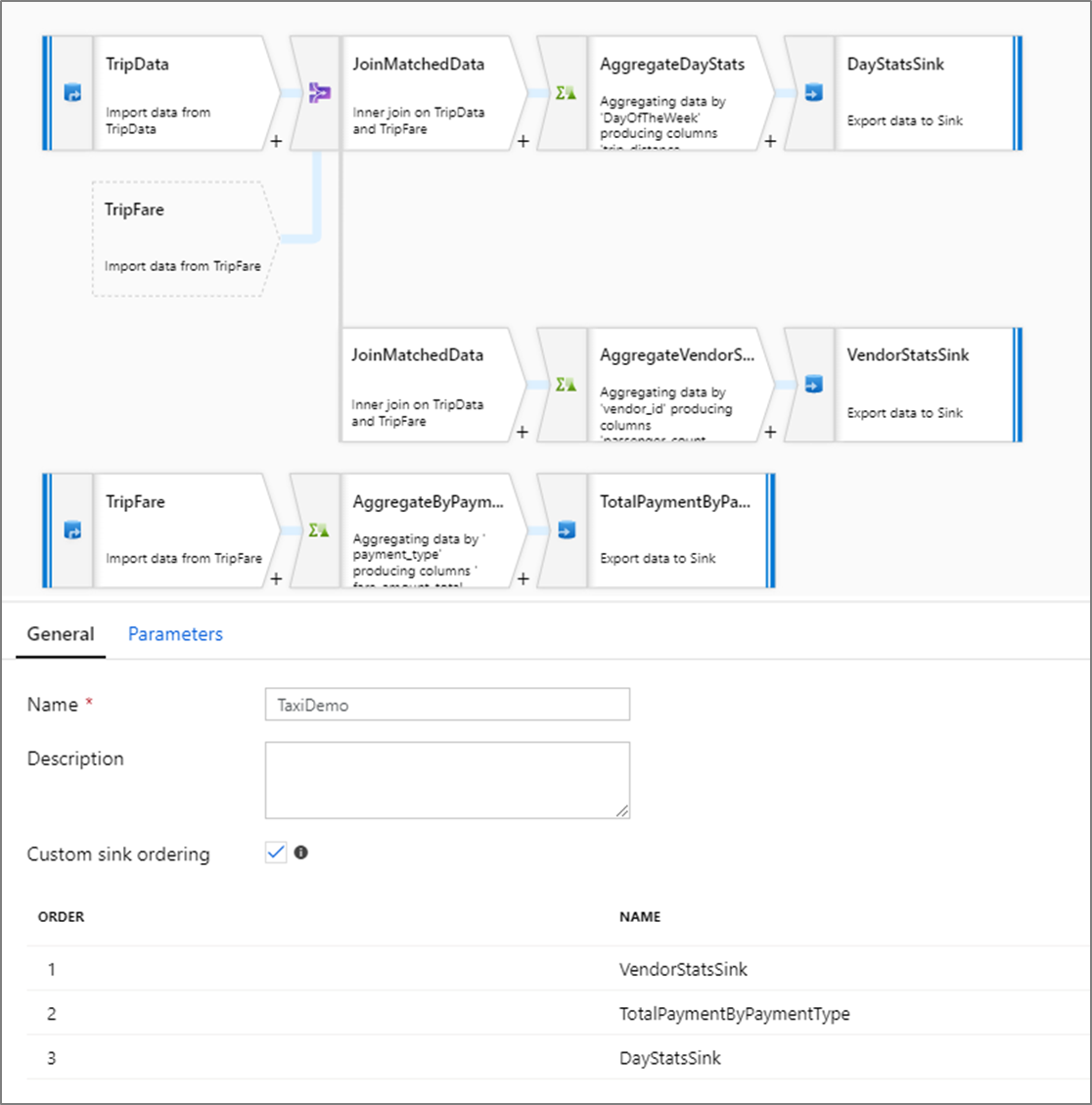
Spoelbak op maat bestellen
Standaard worden gegevens in een niet-deterministische volgorde naar meerdere sinks geschreven. De uitvoeringsengine schrijft gegevens parallel wanneer de transformatielogica is voltooid en de sink-volgorde kan elke uitvoering variëren. Als u een exacte sinkvolgorde wilt opgeven, schakelt u Aangepaste sink-volgorde in op het tabblad Algemeen van de gegevensstroom. Indien ingeschakeld, worden sinks opeenvolgend in oplopende volgorde geschreven.
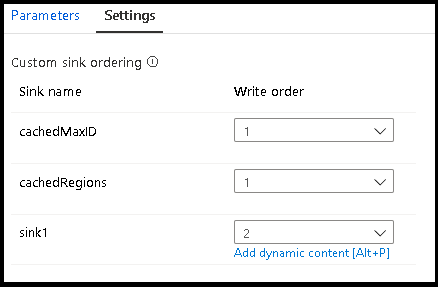
Opmerking
Wanneer u zoekopdrachten in de cache gebruikt, moet u ervoor zorgen dat de sinks in de cache bij de volgorde zijn ingesteld op 1, de laagste (of eerste) in de volgorde.
Zinken groepen
U kunt spoelbakken groeperen door hetzelfde volgnummer toe te passen op een reeks spoelbakken. De service behandelt deze sinks als groepen die parallel kunnen worden uitgevoerd. Opties voor parallelle uitvoering worden weergegeven in de gegevensstroomactiviteit van de pijplijn.
Fouten
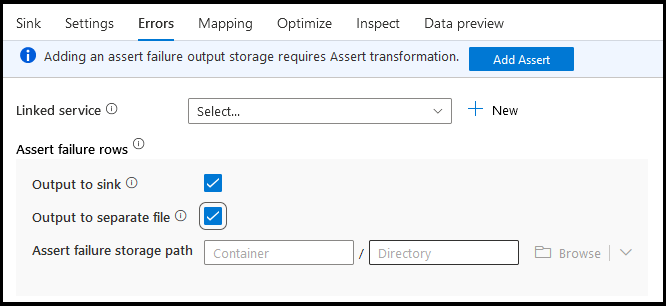
Op het tabblad sink-fouten kunt u de afhandeling van foutrijen configureren om uitvoer vast te leggen en om te leiden voor fouten in databasestuurprogramma's en mislukte beweringen.
Bij het schrijven naar databases kunnen bepaalde gegevensrijen mislukken als gevolg van beperkingen die door het doel zijn ingesteld. Standaard mislukt een uitvoering van een gegevensstroom bij de eerste fout die deze krijgt. In bepaalde connectors kunt u ervoor kiezen om Doorgaan bij fout te gebruiken, waardoor uw gegevensstroom kan worden voltooid, zelfs als afzonderlijke rijen fouten bevatten. Momenteel is deze mogelijkheid alleen beschikbaar in Azure SQL Database en Azure Synapse. Zie Foutrijafhandeling in Azure SQL DB voor meer informatie.
Hieronder vindt u een videozelfstudie over het automatisch afhandelen van databasefoutrijen in uw sink-transformatie.
Voor rijen met assert-fouten kunt u de Assert-transformatie stroomopwaarts in uw gegevensstroom gebruiken en vervolgens mislukte assertions omleiden naar een uitvoerbestand hier op het tabblad sinkfouten. U hebt hier ook een optie om rijen met assertiefouten te negeren en deze rijen helemaal niet uit te voeren naar het gegevensarchief van de sinkbestemming.
Voorbeeld van gegevens in sink
Wanneer u een gegevensvoorbeeld ophaalt in de foutopsporingsmodus, worden er geen gegevens naar uw sink geschreven. Er wordt een momentopname geretourneerd van hoe de gegevens eruit zien, maar er wordt niets naar uw bestemming geschreven. Als u het schrijven van gegevens in uw sink wilt testen, voert u een pijplijnfoutopsporing uit vanuit het pijplijncanvas.
Script voor gegevensstroom
Voorbeeld
Hieronder ziet u een voorbeeld van een sink-transformatie en het bijbehorende gegevensstroomscript:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Verwante inhoud
Nu u uw gegevensstroom hebt gemaakt, voegt u een gegevensstroomactiviteit toe aan uw pijplijn.