Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Queue Storage is een service voor het opslaan en distribueren van grote aantallen berichten. Queue Storage wordt vaak gebruikt om een achterstand van werk te maken om asynchroon te verwerken. Het biedt betrouwbare berichtbezorging voor losjes gekoppelde toepassingsarchitecturen. Een wachtrijbericht kan maximaal 64 kB groot zijn en een wachtrij kan miljoenen berichten bevatten, tot aan de totale capaciteitslimiet van een opslagaccount.
Wanneer u Azure gebruikt, is betrouwbaarheid een gedeelde verantwoordelijkheid. Microsoft biedt een scala aan mogelijkheden ter ondersteuning van tolerantie en herstel. U bent verantwoordelijk voor het begrijpen van de werking van deze mogelijkheden binnen alle services die u gebruikt en het selecteren van de mogelijkheden die u nodig hebt om te voldoen aan uw bedrijfsdoelstellingen en beschikbaarheidsdoelen.
In dit artikel wordt beschreven hoe u Queue Storage tolerant maakt voor verschillende mogelijke storingen en problemen, waaronder tijdelijke fouten, storingen in de beschikbaarheidszone en regiostoringen. Ook wordt beschreven hoe u back-ups kunt gebruiken om te herstellen van andere soorten problemen en benadrukt enkele belangrijke punten over de Service Level Agreement (SLA) van Queue Storage.
Note
Queue Storage maakt deel uit van het Azure Storage-platform. Sommige van de mogelijkheden van Queue Storage zijn gebruikelijk in veel Azure Storage-services.
Aanbevelingen voor productie-implementatie voor betrouwbaarheid
Voor productieomgevingen:
Schakel zone-redundante opslag (ZRS) in voor de opslagaccounts die Queue Storage-resources bevatten. ZRS biedt een hogere beschikbaarheid door uw gegevens synchroon te repliceren over meerdere beschikbaarheidszones in de primaire regio. Hogere beschikbaarheid helpt uw opslagaccounts te beschermen tegen fouten in de beschikbaarheidszone.
Als u tolerantie nodig hebt voor regiostoringen en de primaire regio van uw opslagaccount is gekoppeld, kunt u overwegen geografisch redundante opslag (GRS) in te schakelen. GRS repliceert gegevens asynchroon naar de gekoppelde regio. In ondersteunde regio's kunt u georedundantie combineren met zoneredundantie met behulp van geografisch zone-redundante opslag (GZRS).
Overweeg het gebruik van Azure Service Bus voor geavanceerde berichtenvereisten. Zie Azure Storage-wachtrijen en Service Bus-wachtrijen vergelijken voor meer informatie over de verschillen tussen Queue Storage en Service Bus.
Overzicht van betrouwbaarheidsarchitectuur
Queue Storage werkt als een gedistribueerde berichtenservice binnen de Azure Storage-platforminfrastructuur. De service biedt redundantie via meerdere kopieën van uw wachtrij- en berichtgegevens. Het specifieke redundantiemodel is afhankelijk van de configuratie van uw opslagaccount.
Lokaal redundante opslag (LRS) repliceert de gegevens in uw opslagaccounts naar een of meer Azure-beschikbaarheidszones die zich in de primaire regio van uw keuze bevinden. Hoewel er geen optie is om de gewenste beschikbaarheidszone te kiezen, kan Azure LRS-accounts verplaatsen of uitbreiden tussen zones om de taakverdeling te verbeteren. Er is geen garantie dat uw gegevens worden verspreid over zones. Zie Wat zijn beschikbaarheidszones? voor meer informatie over beschikbaarheidszones.

Zone-redundante opslag (ZRS), geografisch redundante opslag (GRS) en geografisch zone-redundante opslag (GZRS) bieden extra beveiliging. In dit artikel worden deze opties uitgebreid beschreven.
Tolerantie voor tijdelijke fouten
Tijdelijke fouten zijn korte, onregelmatige fouten in onderdelen. Ze vinden vaak plaats in een gedistribueerde omgeving, zoals de cloud, en ze zijn een normaal onderdeel van de bewerkingen. Tijdelijke fouten corrigeren zichzelf na een korte periode. Het is belangrijk dat uw toepassingen tijdelijke fouten kunnen afhandelen, meestal door de betreffende aanvragen opnieuw uit te voeren.
Alle in de cloud gehoste toepassingen moeten de richtlijnen voor tijdelijke foutafhandeling van Azure volgen wanneer ze communiceren met eventuele in de cloud gehoste API's, databases en andere onderdelen. Zie Aanbevelingen voor het afhandelen van tijdelijke foutenvoor meer informatie.
Queue Storage wordt vaak gebruikt in toepassingen om tijdelijke fouten in andere onderdelen te verwerken. Met behulp van asynchrone berichten met een service zoals Queue Storage kunnen toepassingen op een later tijdstip herstellen van tijdelijke fouten door berichten opnieuw te verwerken. Zie Asynchrone Messaging Primer voor meer informatie.
In de service zelf verwerkt Queue Storage tijdelijke fouten automatisch met behulp van verschillende mechanismen die het Azure Storage-platform en de clientbibliotheken bieden. De service is ontworpen om tolerante mogelijkheden voor berichtenwachtrijen te bieden, zelfs tijdens tijdelijke infrastructuurproblemen.
Queue Storage-clientbibliotheken bevatten ingebouwde beleidsregels voor opnieuw proberen die automatisch veelvoorkomende tijdelijke fouten verwerken, zoals netwerktime-outs, tijdelijke serviceonbeschikbaarheid (HTTP 503) en beperkingsreacties (HTTP 429). Wanneer uw toepassing deze tijdelijke omstandigheden tegenkomt, proberen de clientbibliotheken automatisch bewerkingen opnieuw met behulp van exponentieel uitstelstrategieën.
Als u tijdelijke fouten effectief wilt beheren met behulp van Queue Storage, kunt u de volgende acties uitvoeren:
Configureer de juiste time-outs in uw Queue Storage-client om de reactiesnelheid te verdelen met tolerantie voor tijdelijke vertragingen. De standaardtime-outs in Azure Storage-clientbibliotheken zijn doorgaans geschikt voor de meeste scenario's.
Implementeer circuitonderbrekerpatronen in uw toepassing wanneer berichten uit wachtrijen worden verwerkt. Circuitonderbrekerpatronen voorkomen trapsgewijze fouten wanneer downstreamservices problemen ondervinden.
Gebruik time-outs voor zichtbaarheid op de juiste manier wanneer uw toepassing berichten ontvangt. Time-outs voor zichtbaarheid zorgen ervoor dat berichten beschikbaar zijn voor opnieuw proberen als uw toepassing fouten ondervindt tijdens de verwerking.
Zie de controlelijst prestaties en schaalbaarheid voor Queue Storage voor meer informatie over de Architectuur van Azure Table Storage en het ontwerpen van robuuste en grootschalige toepassingen.
Tolerantie voor fouten in beschikbaarheidszones
Beschikbaarheidszones zijn fysiek gescheiden groepen datacenters binnen een Azure-regio. Wanneer één zone uitvalt, kunnen services een failover uitvoeren naar een van de resterende zones.
Azure Queue Storage is zone-redundant wanneer deze wordt geïmplementeerd met ZRS-configuratie. In tegenstelling tot LRS garandeert ZRS dat azure uw wachtrijgegevens synchroon repliceert in meerdere beschikbaarheidszones. ZRS zorgt ervoor dat uw gegevens toegankelijk blijven, zelfs als één zone een storing ondervindt. ZRS zorgt ervoor dat uw wachtrijen toegankelijk blijven, zelfs als een volledige beschikbaarheidszone niet beschikbaar is. Alle schrijfbewerkingen moeten worden bevestigd in meerdere zones voordat ze zijn voltooid, wat sterke consistentiegaranties biedt.
Zoneredundantie is ingeschakeld op het niveau van het opslagaccount en is van toepassing op alle Queue Storage-resources binnen dat account. U kunt afzonderlijke wachtrijen niet configureren voor verschillende redundantieniveaus. De instelling is van toepassing op het hele opslagaccount. Wanneer een beschikbaarheidszone een storing ondervindt, stuurt Azure Storage aanvragen automatisch naar gezonde zones zonder tussenkomst van uw toepassing.

Requirements
- Regioondersteuning: U kunt zoneredundante Azure Storage-accounts implementeren in elke regio die beschikbaarheidszones ondersteunt.
- Typen opslagaccounts: U moet een Standaard v2-opslagaccount voor algemeen gebruik gebruiken om ZRS in te schakelen voor Queue Storage. Premium-opslagaccounts bieden geen ondersteuning voor Queue Storage.
Cost
Wanneer u zone-redundante opslag (ZRS) inschakelt, worden er kosten in rekening gebracht tegen een ander tarief dan lokaal redundante opslag (LRS) vanwege de extra replicatie- en opslagoverhead.
Zie Queue Storage-prijzen voor gedetailleerde prijsinformatie.
Ondersteuning voor beschikbaarheidszones configureren
Maak een zone-redundant opslagaccount en wachtrij door de volgende stappen uit te voeren.
Maak een opslagaccount en selecteer ZRS, GZRS of geografisch zone-redundante opslag met leestoegang (RA-GZRS) als redundantieoptie tijdens het maken van het account.
Replicatietype wijzigen. Zie Wijzigen hoe een opslagaccount wordt gerepliceerd voor meer informatie over het wijzigen van een bestaand opslagaccount in zone-redundante opslag (ZRS) en over configuratieopties en -vereisten.
Zoneredundantie uitschakelen. Converteer ZRS-accounts terug naar een niet-zonegebonden configuratie, zoals lokaal redundante opslag (LRS), met behulp van hetzelfde wijzigingsproces voor redundantieconfiguratie.
Gedrag wanneer alle zones in orde zijn
In deze sectie wordt beschreven wat u kunt verwachten wanneer een wachtrijopslagaccount is geconfigureerd voor zoneredundantie en alle beschikbaarheidszones operationeel zijn.
Verkeersroutering tussen zones: Azure Storage met zone-redundante opslag (ZRS) distribueert aanvragen automatisch over opslagclusters in meerdere beschikbaarheidszones. De distributie van verkeer is transparant voor toepassingen en vereist geen configuratie aan de clientzijde.
Gegevensreplicatie tussen zones: Alle schrijfbewerkingen naar ZRS worden synchroon gerepliceerd in alle beschikbaarheidszones binnen de regio. Wanneer u gegevens uploadt of wijzigt, wordt de bewerking pas als voltooid beschouwd als de gegevens zijn gerepliceerd in alle beschikbaarheidszones. Deze synchrone replicatie zorgt voor sterke consistentie en nul gegevensverlies tijdens zonefouten.
Gedrag tijdens een zonefout
Wanneer een beschikbaarheidszone niet beschikbaar is, verwerkt Queue Storage het failoverproces automatisch door de volgende acties uit te voeren.
Detectie en reactie: Microsoft detecteert automatisch zonefouten en initieert herstelprocessen. Er is geen actie van de klant vereist voor ZRS-accounts (zone-redundante opslag).
Als een zone niet meer beschikbaar is, voert Azure netwerkupdates uit, zoals het opnieuw verwijzen van het Domain Name System (DNS).
- Melding: Microsoft informeert u niet automatisch wanneer een zone niet beschikbaar is. U kunt Azure Resource Health echter gebruiken om te controleren op de status van een afzonderlijke resource en u kunt Resource Health-waarschuwingen instellen om u op de hoogte te stellen van problemen. U kunt Azure Service Health ook gebruiken om inzicht te hebben in de algehele status van de service, inclusief eventuele zonefouten, en u kunt Service Health-waarschuwingen instellen om u op de hoogte te stellen van problemen.
Actieve aanvragen: Aanvragen tijdens het herstelproces kunnen tijdens het herstelproces worden verwijderd en moeten opnieuw worden geprobeerd. Toepassingen moeten logica voor opnieuw proberen implementeren om deze tijdelijke onderbrekingen af te handelen.
Verwachte gegevensverlies: Er treden geen gegevensverlies op tijdens zonefouten omdat gegevens synchroon worden gerepliceerd in meerdere zones voordat schrijfbewerkingen zijn voltooid.
Verwachte downtime: Een kleine hoeveelheid downtime, meestal een paar seconden, kan optreden tijdens het automatisch herstel, omdat verkeer wordt omgeleid naar gezonde zones. Wanneer u toepassingen voor ZRS ontwerpt, volgt u procedures voor tijdelijke foutafhandeling, waaronder het implementeren van beleid voor opnieuw proberen met exponentieel uitstel.
- Verkeer omleiden. Als een zone niet meer beschikbaar is, voert Azure netwerkupdates zoals DNS(Domain Name System) opnieuw aan, zodat aanvragen worden omgeleid naar de resterende beschikbaarheidszones die in orde zijn. De service onderhoudt volledige functionaliteit met behulp van de overlevende zones zonder tussenkomst van de klant.
Zoneherstel
Wanneer de mislukte beschikbaarheidszone wordt hersteld, herstelt Azure Storage automatisch normale bewerkingen in alle beschikbaarheidszones. De service zorgt automatisch voor gegevensconsistentie door alle bewerkingen te synchroniseren die zijn opgetreden tijdens de onderbrekingsperiode.
Testen op zonefouten
Wanneer u zone-redundante opslag (ZRS) gebruikt, beheert Azure Storage automatisch replicatie, verkeersroutering en zone-down antwoorden. Omdat deze functie volledig wordt beheerd, hoeft u geen processen voor fouten in de beschikbaarheidszone te initiëren of valideren.
Tolerantie voor storingen in de hele regio
Azure Storage, waaronder Azure Blob Storage, Azure Files, Azure Table Storage en Azure Queue Storage, biedt een scala aan georedundantie- en failovermogelijkheden die aan verschillende vereisten voldoen.
Important
Geografisch redundante opslag (GRS) werkt alleen binnen gekoppelde Azure-regio's. Als de regio van uw opslagaccount niet is gekoppeld, kunt u overwegen om de aangepaste oplossingen voor meerdere regio's te gebruiken voor tolerantie.
Geografisch redundante opslag voor gekoppelde regio's
Azure Storage biedt verschillende typen GRS in gekoppelde regio's. Welk type GRS u ook gebruikt, gegevens in de secundaire regio worden altijd gerepliceerd met behulp van lokaal redundante opslag (LRS). Deze aanpak biedt bescherming tegen hardwarefouten binnen de secundaire regio.
GRS biedt ondersteuning voor geplande en ongeplande failovers naar de gekoppelde Azure-regio wanneer er een storing optreedt in de primaire regio. GRS repliceert asynchroon gegevens van de primaire regio naar de gekoppelde regio.
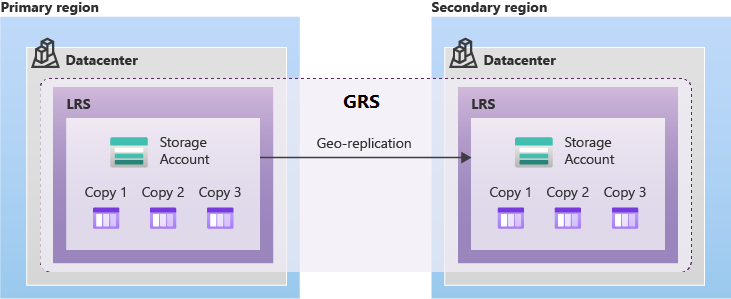
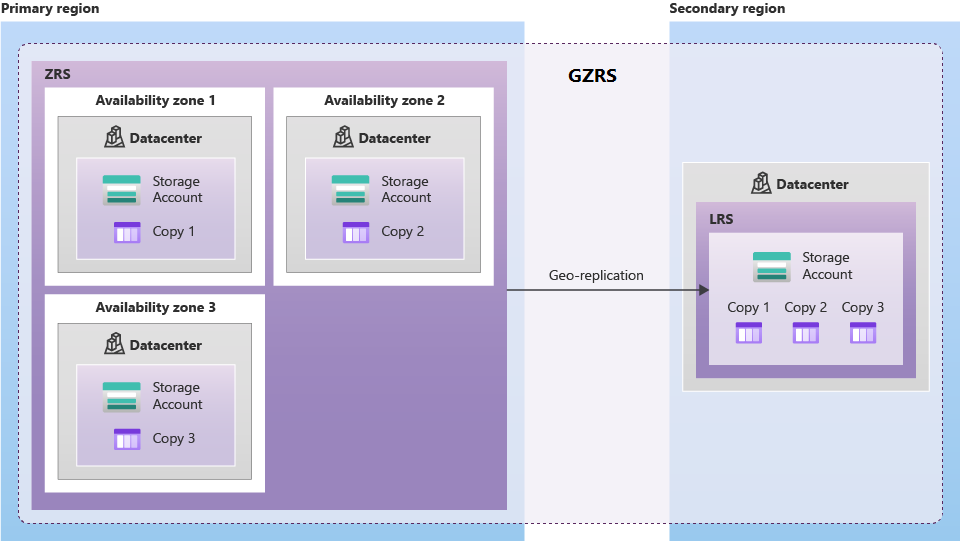
Geografisch zone-redundante opslag (GZRS) repliceert gegevens in meerdere beschikbaarheidszones in de primaire regio en in de gekoppelde regio.


Georedundante opslag
- Geografisch redundante opslag met leestoegang (RA-GRS) en geografisch zone-redundante opslag met leestoegang (RA-GZRS) breidt geografisch redundante opslag (GRS) en geografisch zone-redundante opslag (GZRS) uit met het extra voordeel van leestoegang tot het secundaire eindpunt. Deze opties zijn ideaal voor toepassingen die zijn ontworpen voor bedrijfskritieke toepassingen met hoge beschikbaarheid. In het onwaarschijnlijke geval dat het primaire eindpunt een storing ondervindt, kunnen toepassingen die zijn geconfigureerd voor leestoegang tot de secundaire regio, blijven werken.
Failovertypen
Azure Storage ondersteunt drie soorten failover voor verschillende scenario's.
Door de klant beheerde niet-geplande failover: U bent verantwoordelijk voor het initiëren van herstel als er sprake is van een opslagfout in de hele regio in uw primaire regio.
Door de klant beheerde geplande failover: U bent verantwoordelijk voor het initiëren van herstel als een ander deel van uw oplossing een storing heeft in uw primaire regio en u moet uw hele oplossing overschakelen naar een secundaire regio. Gebruik een geplande failover wanneer de opslag operationeel blijft in de primaire regio, maar u uw gehele oplossing moet overzetten naar een secundaire regio, bijvoorbeeld voor rampenhersteloefeningen die zijn ontworpen om te voldoen aan nalevings- en controlevereisten.
Door Microsoft beheerde failover: In uitzonderlijke omstandigheden kan Microsoft failover initiëren voor alle GEOGRAFISCH redundante opslagaccounts (GRS) in een regio. Door Microsoft beheerde failover is echter een laatste redmiddel en wordt naar verwachting alleen uitgevoerd na een langere periode van storing. U moet niet afhankelijk zijn van door Microsoft beheerde failover.
GRS-accounts kunnen elk van deze failovertypen gebruiken. U hoeft een opslagaccount niet vooraf te configureren voor het gebruik van een van de failovertypen van tevoren.
Requirements
Regioondersteuning: Geografisch redundante Azure Storage-configuraties maken gebruik van gekoppelde Azure-regio's voor replicatie van secundaire regio's . De secundaire regio wordt automatisch bepaald op basis van de selectie van uw primaire regio en kan niet worden aangepast. Zie de lijst met Gekoppelde Azure-regio's voor een volledige lijst met gekoppelde Azure-regio's.
Als de regio van uw opslagaccount niet is gekoppeld, kunt u overwegen om de aangepaste oplossingen voor meerdere regio's te gebruiken voor tolerantie.
- Typen opslagaccounts: Geografisch redundante opslag (GRS) en door de klant geïnitieerde failover en failback zijn beschikbaar in alle gekoppelde Azure-regio's die ondersteuning bieden voor v2 Azure Storage-accounts voor algemeen gebruik.
Considerations
Houd rekening met de volgende belangrijke factoren wanneer u Queue Storage met meerdere regio's implementeert.
Asynchrone replicatielatentie: Gegevensreplicatie naar de secundaire regio is asynchroon, wat betekent dat er een vertraging is tussen wanneer gegevens naar de primaire regio worden geschreven en wanneer deze beschikbaar zijn in de secundaire regio. Deze vertraging kan leiden tot mogelijk gegevensverlies als er een storing in de primaire regio optreedt voordat recente gegevens worden gerepliceerd. Het gegevensverlies wordt gemeten door het beoogde herstelpunt (RPO). U kunt verwachten dat de replicatievertraging minder dan 15 minuten is, maar deze keer is een schatting en niet gegarandeerd.
U kunt de eigenschap Laatste synchronisatietijd controleren om te begrijpen hoeveel gegevens verloren kunnen gaan als uw opslagaccount een niet-geplande failover heeft.
Toegang tot secundaire regio: Met configuraties van geografisch redundante opslag (GRS) en geografisch zone-redundante opslag (GZRS) is de secundaire regio pas toegankelijk voor leesbewerkingen als er een failover plaatsvindt.
geografisch redundante opslag met leestoegang (RA-GRS) en geografisch zone-redundante opslagconfiguraties met leestoegang (RA-GZRS) bieden leestoegang tot de secundaire regio tijdens normale bewerkingen, maar vanwege de asynchrone replicatielatentie kunnen ze enigszins verouderde gegevens retourneren.
- Functiebeperkingen: Sommige Azure Storage-functies worden niet ondersteund of hebben beperkingen wanneer u geografisch redundante opslag (GRS) of door de klant beheerde failover gebruikt. Controleer de functiecompatibiliteit voordat u georedundantie implementeert.
Cost
Voor configuraties van Azure Storage-accounts met meerdere regio's worden extra kosten in rekening gebracht voor replicatie in meerdere regio's en opslag in de secundaire regio. Gegevensoverdracht tussen Azure-regio's wordt in rekening gebracht op basis van standaard bandbreedtetarieven tussen regio's.
Zie Queue Storage-prijzen voor gedetailleerde prijsinformatie.
Ondersteuning voor meerdere regio's configureren
- Maak een nieuw GRS-account (geografisch redundante opslag). Als u een GRS-account wilt maken, raadpleegt u Een opslagaccount maken en selecteert u GRS, geografisch redundante opslag met leestoegang (RA-GRS), geografisch zone-redundante opslag (GZRS) of geografisch zone-redundante opslag met leestoegang (RA-GZRS) tijdens het maken van het account.
Schakel georedundantie in voor een bestaand opslagaccount. Als u een bestaand opslagaccount wilt converteren naar geografisch redundante opslag (GRS), raadpleegt u Wijzigen hoe een opslagaccount wordt gerepliceerd.
Warning
Nadat uw account opnieuw is geconfigureerd voor georedundantie, kan het enige tijd duren voordat bestaande gegevens in de nieuwe primaire regio volledig naar de nieuwe secundaire regio worden gekopieerd.
Als u een groot gegevensverlies wilt voorkomen, controleert u de waarde van de eigenschap Laatste synchronisatietijd voordat u een niet-geplande failover start. Als u potentiële gegevensverlies wilt evalueren, vergelijkt u de laatste synchronisatietijd met de laatste keer dat gegevens naar de nieuwe primaire regio zijn geschreven.
Schakel georedundantie uit. Converteer GRS-accounts terug naar configuraties met één regio, zoals lokaal redundante opslag (LRS) of zone-redundante opslag (ZRS) met behulp van hetzelfde wijzigingsproces voor redundantieconfiguratie.
Gedrag wanneer alle regio's in orde zijn
In deze sectie wordt beschreven wat u kunt verwachten wanneer een opslagaccount is geconfigureerd voor georedundantie en alle regio's operationeel zijn.
Verkeersroutering tussen regio's: Azure Storage maakt gebruik van een actief-passieve benadering waarbij alle schrijfbewerkingen en de meeste leesbewerkingen worden omgeleid naar de primaire regio.
Voor geografisch redundante opslag met leestoegang (RA-GRS) en geografisch zone-redundante opslagconfiguraties met leestoegang (RA-GZRS) kunnen toepassingen optioneel vanuit de secundaire regio lezen door toegang te krijgen tot het secundaire eindpunt. Deze aanpak vereist expliciete toepassingsconfiguratie en is niet automatisch. Vanwege de asynchrone replicatievertraging kunnen gegevens in de secundaire regio mogelijk enigszins verouderd zijn.
Gegevensreplicatie tussen regio's: Schrijfbewerkingen worden eerst doorgevoerd in de primaire regio met behulp van de volgende geconfigureerde redundantietypen:
- Lokaal redundante opslag (LRS) voor geografisch redundante opslag (GRS) en RA-GRS
- Zone-redundante opslag (ZRS) voor geografisch zone-redundante opslag (GZRS) en RA-GZRS
Na een geslaagde voltooiing in de primaire regio worden gegevens asynchroon gerepliceerd naar de secundaire regio waar ze worden opgeslagen met LRS.
De asynchrone aard van replicatie tussen regio's betekent dat er meestal een vertragingstijd is tussen het moment waarop gegevens naar de primaire regio worden geschreven en wanneer deze beschikbaar zijn in de secundaire regio. U kunt de replicatietijd bewaken met behulp van de eigenschap Laatste synchronisatietijd.
Gedrag tijdens een regiofout
In deze sectie wordt beschreven wat u kunt verwachten wanneer een opslagaccount is geconfigureerd voor georedundantie en er een storing is in de primaire regio.
Door de klant beheerde failover (niet-gepland): Gebruik een niet-geplande failover wanneer opslag in de primaire regio niet beschikbaar is.
Detectie en reactie: In het onwaarschijnlijke geval dat uw opslagaccount niet beschikbaar is in uw primaire regio, kunt u overwegen om een niet-geplande failover door de klant te starten. Houd rekening met de volgende factoren om deze beslissing te nemen:
Of Azure Resource Health problemen toont bij het openen van het opslagaccount in uw primaire regio
Of Microsoft u adviseert failover naar een andere regio uit te voeren
Warning
Een niet-geplande failover kan leiden tot gegevensverlies. Voordat u een door de klant beheerde failover start, moet u beslissen of het herstel van de service het risico op gegevensverlies rechtvaardigt.
Melding: Microsoft informeert u niet automatisch wanneer een regio niet beschikbaar is. Echter:
U kunt Azure Resource Health gebruiken om te controleren op de status van een afzonderlijke resource en u kunt Resource Health-waarschuwingen instellen om u op de hoogte te stellen van problemen.
U kunt Azure Service Health gebruiken om inzicht te hebben in de algehele status van de service, inclusief eventuele regiofouten, en u kunt Service Health-waarschuwingen instellen om u op de hoogte te stellen van problemen.
Actieve aanvragen: Tijdens het failoverproces zijn zowel de primaire als de secundaire eindpunten van het opslagaccount tijdelijk niet beschikbaar voor zowel lees- als schrijfbewerkingen. Actieve aanvragen kunnen worden verwijderd en clienttoepassingen moeten het opnieuw proberen nadat de failover is voltooid.
Verwachte gegevensverlies: Gegevensverlies is gebruikelijk tijdens een niet-geplande failover vanwege de asynchrone replicatievertraging, wat betekent dat recente schrijfbewerkingen mogelijk niet worden gerepliceerd. U kunt de eigenschap Laatste synchronisatietijd controleren om te begrijpen hoeveel gegevens verloren kunnen gaan tijdens een niet-geplande failover. Verwacht gegevensverlies wordt vaak het beoogde herstelpunt (RPO) genoemd. U kunt normaal gesproken verwachten dat de RPO minder dan 15 minuten is, maar die tijd is niet gegarandeerd.
Verwachte downtime: De hoeveelheid verwachte downtime wordt vaak aangeduid als de beoogde hersteltijd (RTO). Door de klant beheerde failover wordt doorgaans binnen 60 minuten voltooid, afhankelijk van de accountgrootte en complexiteit.
Verkeer omleiden: Wanneer de failover is voltooid, worden de eindpunten van het opslagaccount automatisch bijgewerkt, zodat toepassingen niet opnieuw hoeven te worden geconfigureerd. Als uw toepassing DNS-vermeldingen (Domain Name System) in de cache bewaart, kan het nodig zijn om de cache te wissen om ervoor te zorgen dat de toepassing verkeer naar de nieuwe primaire regio verzendt.
Configuratie na failover: Nadat een niet-geplande failover is voltooid, gebruikt uw opslagaccount in de doelregio de lokaal redundante opslaglaag (LRS). Als u deze opnieuw wilt repliceren, moet u geografisch redundante opslag (GRS) opnieuw inschakelen en wachten totdat de gegevens worden gerepliceerd naar de nieuwe secundaire regio.
Zie Hoe door de klant beheerde (niet-geplande) failover werkt en een failover van een opslagaccount initiëren voor meer informatie over het initiëren van door de klant beheerde failover.
Door de klant beheerde failover (gepland): Gebruik een geplande failover wanneer de opslag operationeel blijft in de primaire regio, maar u moet om een andere reden een failover van uw hele oplossing uitvoeren naar een secundaire regio. Een andere Azure-service kan bijvoorbeeld een probleem ondervinden en u moet overschakelen naar het gebruik van een secundaire regio voor uw hele oplossing. Of u kunt een geplande failover gebruiken om een disaster recovery (DR)-oefening uit te voeren voor nalevings- en controledoeleinden.
Detectie en reactie: U bent verantwoordelijk voor het kiezen van een failover. Normaal gesproken neemt u deze beslissing als u een failover tussen regio's wilt uitvoeren, ook al is uw opslagaccount in orde. U kunt bijvoorbeeld een failover activeren wanneer er een grote storing optreedt in een ander toepassingsonderdeel waarvan u niet kunt herstellen in de primaire regio.
Melding: Microsoft informeert u niet automatisch wanneer een regio niet beschikbaar is. Echter:
U kunt Azure Resource Health gebruiken om te controleren op de status van een afzonderlijke resource en u kunt Resource Health-waarschuwingen instellen om u op de hoogte te stellen van problemen.
U kunt Azure Service Health gebruiken om inzicht te hebben in de algehele status van de service, inclusief eventuele regiofouten, en u kunt Service Health-waarschuwingen instellen om u op de hoogte te stellen van problemen.
Actieve aanvragen: Tijdens het failoverproces zijn zowel de primaire als de secundaire eindpunten van het opslagaccount tijdelijk niet beschikbaar voor zowel lees- als schrijfbewerkingen. Actieve aanvragen kunnen worden verwijderd en clienttoepassingen moeten het opnieuw proberen nadat de failover is voltooid.
Verwachte gegevensverlies: Er wordt geen gegevensverlies verwacht omdat het failoverproces pas wordt voltooid nadat alle gegevens zijn gesynchroniseerd, wat resulteert in een RPO van nul.
Verwachte downtime: Failover wordt doorgaans binnen 60 minuten voltooid, wat betekent dat de verwachte RTO 60 minuten is, afhankelijk van de grootte en complexiteit van het account. Tijdens het failoverproces zijn zowel de primaire als de secundaire eindpunten van het opslagaccount tijdelijk niet beschikbaar voor zowel lees- als schrijfbewerkingen.
Verkeer omleiden: Wanneer de failover is voltooid, worden de eindpunten van het opslagaccount automatisch bijgewerkt, zodat toepassingen niet opnieuw hoeven te worden geconfigureerd. Als uw toepassing DNS-vermeldingen in de cache bewaart, kan het nodig zijn om de cache te wissen om ervoor te zorgen dat de toepassing verkeer naar de nieuwe primaire regio verzendt.
Configuratie na failover: Nadat een geplande failover is voltooid, blijft uw opslagaccount in de doelregio geo-repliceren en blijft deze op de GRS-laag staan.
Zie Hoe door de klant beheerde (geplande) failover werkt en een failover van een opslagaccount initiëren voor meer informatie over het initiëren van door de klant beheerde failover.
Door Microsoft beheerde failover: In het zeldzame geval van een grote ramp waarbij Microsoft bepaalt dat de primaire regio permanent onherstelbaar is, kan een automatische failover naar de secundaire regio worden gestart. Microsoft verwerkt het hele proces en er is geen actie van de klant vereist. De hoeveelheid tijd die is verstreken voordat een failover plaatsvindt, is afhankelijk van de ernst van de ramp en de tijd die nodig is om de situatie te beoordelen.
Melding: Microsoft informeert u niet automatisch wanneer een regio niet beschikbaar is. Echter:
U kunt Azure Resource Health gebruiken om te controleren op de status van een afzonderlijke resource en u kunt Resource Health-waarschuwingen instellen om u op de hoogte te stellen van problemen.
U kunt Azure Service Health gebruiken om inzicht te hebben in de algehele status van de service, inclusief eventuele regiofouten, en u kunt Service Health-waarschuwingen instellen om u op de hoogte te stellen van problemen.
Important
Gebruik door de klant beheerde failoveropties voor het ontwikkelen, testen en implementeren van uw DR-plannen. Vertrouw niet op door Microsoft beheerde failover, die alleen in extreme omstandigheden kan worden gebruikt. Een door Microsoft beheerde failover wordt waarschijnlijk geïnitieerd voor een hele regio. Het kan niet worden gestart voor afzonderlijke opslagaccounts, abonnementen of klanten. Failover kan zich op verschillende momenten voordoen voor verschillende Azure-services. We raden u aan om door de klant beheerde failover te gebruiken.
Regio herstel
Het failbackproces verschilt aanzienlijk tussen door Microsoft beheerde en door de klant beheerde failoverscenario's.
Door de klant beheerde failover (niet-gepland): Na een niet-geplande failover wordt het opslagaccount geconfigureerd met lokaal redundante opslag (LRS). Als u een failback wilt uitvoeren, moet u de GRS-relatie (geografisch redundante opslag) opnieuw tot stand brengen en wachten totdat de gegevens zijn gerepliceerd.
Door de klant beheerde failover (gepland): Na een geplande failover blijft het opslagaccount geo-gerepliceerd. U kunt een andere door de klant beheerde failover initiëren om een failback uit te voeren naar de oorspronkelijke primaire regio. Dezelfde overwegingen voor failover zijn van toepassing.
Door Microsoft beheerde failover: Als Microsoft een failover initieert, is het waarschijnlijk dat er een aanzienlijke ramp is opgetreden in de primaire regio en dat de primaire regio mogelijk niet kan worden hersteld. Tijdlijnen of herstelplannen zijn afhankelijk van de omvang van de regionale nood- en herstelinspanningen. U moet Azure Service Health-communicatie controleren voor details.
Test voor regiofouten
U kunt regionale fouten simuleren om uw procedures voor herstel na noodgevallen te testen.
Geplande failovertests: Voor GRS-accounts (geografisch redundante opslag) kunt u geplande failoverbewerkingen uitvoeren tijdens onderhoudsvensters om het volledige failover- en failbackproces te testen. Geplande failover vereist geen gegevensverlies, maar er is wel sprake van downtime tijdens zowel failover als failback.
Secundair eindpunt testen: Voor geografisch redundante opslag met leestoegang (RA-GRS) en geografisch zone-redundante opslagconfiguraties (RA-GZRS) met leestoegang, test u regelmatig leesbewerkingen op het secundaire eindpunt om ervoor te zorgen dat uw toepassing gegevens uit de secundaire regio kan lezen.
Aangepaste oplossingen voor meerdere regio's voor veerkracht
De failovermogelijkheden tussen regio's van Azure Storage zijn mogelijk niet geschikt vanwege de volgende redenen:
Uw opslagaccount bevindt zich in een niet-gekoppelde regio.
Uw doelstellingen voor bedrijfstijd worden niet gerealiseerd door de hersteltijd of het gegevensverlies dat de ingebouwde failoveropties bieden.
U moet een failover uitvoeren naar een regio die niet gekoppeld is aan uw primaire regio.
U hebt een actieve/actieve configuratie in verschillende regio's nodig.
In deze sectie vindt u een algemeen overzicht van enkele benaderingen die u kunt overwegen. Een uitgebreid overzicht van implementatietopologieën voor meerdere regio's voor Azure Storage valt buiten het bereik van dit artikel.
Note
Voor geavanceerde vereisten voor meerdere regio's kunt u in plaats daarvan Service Bus gebruiken, waaronder ondersteuning voor niet-gereaireerde regio's.
U kunt Azure Storage implementeren in meerdere regio's met behulp van afzonderlijke opslagaccounts in elke regio. Deze benadering biedt flexibiliteit in regioselectie, de mogelijkheid om niet-geaireerde regio's te gebruiken en meer gedetailleerde controle over de timing van replicatie en gegevensconsistentie. Wanneer u meerdere opslagaccounts in verschillende regio's implementeert, moet u replicatie van gegevens in meerdere regio's configureren, taakverdeling en failoverbeleid implementeren en gegevensconsistentie tussen regio's garanderen.
Voor deze aanpak moet u de distributie van berichten beheren, gegevenssynchronisatie tussen wachtrijen in de verschillende opslagaccounts afhandelen en aangepaste failoverlogica implementeren.
Backups en herstel
Queue Storage biedt geen traditionele back-upmogelijkheden, zoals herstel naar een bepaald tijdstip (PITR). Dit komt doordat wachtrijen zijn ontworpen voor tijdelijke berichtopslag in plaats van langetermijngegevenspersistentie. Berichten worden doorgaans verwerkt en verwijderd uit wachtrijen tijdens normale toepassingsbewerkingen.
Voor scenario's waarvoor de duurzaamheid van berichten buiten de ingebouwde redundantieopties is vereist, kunt u overwegen om uw eigen logboekregistratie op toepassingsniveau of persistentie te implementeren in een permanent gegevensarchief, zoals Blob Storage of Azure SQL Database. Met deze methode kunt u de berichtgeschiedenis behouden terwijl u Queue Storage gebruikt voor het beoogde doel van tijdelijke berichtbuffering en verwerkingscoördinatie.
Diensteniveauovereenkomst
De SLA (Service Level Agreement) voor Azure Storage beschrijft de verwachte beschikbaarheid van de service en de voorwaarden waaraan moet worden voldaan om die beschikbaarheidsverwachting te bereiken. De SLA voor beschikbaarheid waarvoor u in aanmerking komt, is afhankelijk van de opslaglaag en het replicatietype dat u gebruikt. Zie SLA's voor onlineservices voor meer informatie.