Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie wordt azure Machine Learning Designer gebruikt om een voorspellend machine learning-model te bouwen. Het model is gebaseerd op de gegevens die zijn opgeslagen in Azure Synapse. Het scenario voor de zelfstudie is om te voorspellen of een klant waarschijnlijk een fiets koopt of niet zo is dat Adventure Works, de fietswinkel, een gerichte marketingcampagne kan bouwen.
Vereisten
Voor deze handleiding hebt u dit nodig:
- een SQL-pool die vooraf is geladen met AdventureWorksDW-voorbeeldgegevens. Om deze SQL-pool in te richten, zie Een SQL-pool maken en kies ervoor om de voorbeeldgegevens te laden. Als u al een datawarehouse hebt maar geen voorbeeldgegevens hebt, kunt u voorbeeldgegevens handmatig laden.
- een Azure Machine Learning-werkruimte. Volg deze handleiding om een nieuwe te maken.
De gegevens ophalen
De gebruikte gegevens zijn opgenomen in de weergave dbo.vTargetMail in AdventureWorksDW. Als u datastore in deze zelfstudie wilt gebruiken, worden de gegevens eerst geëxporteerd naar het Azure Data Lake Storage-account, omdat Azure Synapse momenteel geen ondersteuning biedt voor gegevenssets. Azure Data Factory kan worden gebruikt voor het exporteren van gegevens uit het datawarehouse naar Azure Data Lake Storage met behulp van de kopieeractiviteit. Gebruik de volgende query voor importeren:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Zodra de gegevens beschikbaar zijn in Azure Data Lake Storage, worden gegevensarchieven in Azure Machine Learning gebruikt om verbinding te maken met Azure Storage-services. Volg de onderstaande stappen om een gegevensarchief en een bijbehorende gegevensset te maken:
Start Azure Machine Learning-studio vanuit Azure Portal of meld u aan bij Azure Machine Learning-studio.
Klik op Gegevensarchieven in het linkerdeelvenster in de sectie Beheren en klik vervolgens op Nieuw gegevensarchief.
Geef een naam op voor het gegevensarchief, selecteer het type als Azure Blob Storage, geef locatie en referenties op. Klik vervolgens op Maken.
Klik vervolgens op Gegevenssets in het linkerpaneel in de sectie Assets. Selecteer Gegevensset maken met de optie Van datastore.
Geef de naam van de dataset op en selecteer het type als Tabular. Klik vervolgens op Volgende om vooruit te gaan.
In de sectie Selecteer of maak een gegevensarchief, kies de optie Eerder gemaakte gegevensarchief. Selecteer de datastore die eerder is gemaakt. Klik op Volgende en geef het pad en de bestandsinstellingen op. Zorg ervoor dat u de kolomkop opgeeft als de bestanden er een bevatten.
Klik ten slotte op Maken om de gegevensset te maken.
Ontwerpersexperiment configureren
Volg vervolgens de onderstaande stappen voor de configuratie van de ontwerpfunctie:
Klik op het tabblad Designer in het linkerdeelvenster in de sectie Auteur .
Selecteer Eenvoudig te gebruiken vooraf gemaakte onderdelen om een nieuwe pijplijn te bouwen.
Geef in het deelvenster Instellingen aan de rechterkant de naam van de pijplijn op.
Selecteer ook een doel-rekencluster voor het hele experiment in de knop Instellingen voor een eerder ingericht cluster. Sluit het deelvenster Instellingen.
De gegevens importeren
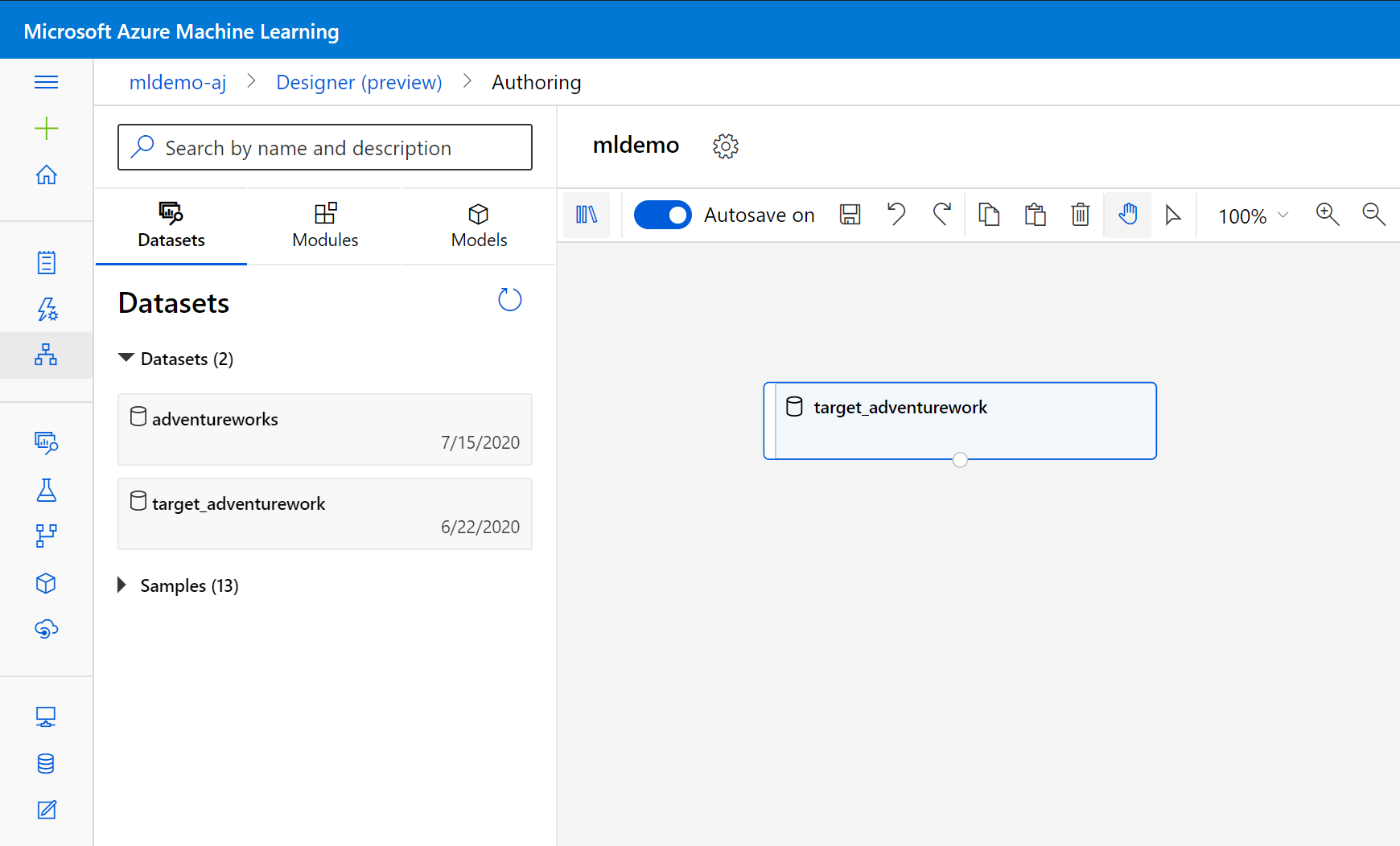
Selecteer het subtabblad Gegevenssets in het linkerdeelvenster onder het zoekvak.
Sleep de gegevensset die u eerder hebt gemaakt naar het canvas.
De gegevens opschonen
Als u de gegevens wilt opschonen, verwijdert u kolommen die niet relevant zijn voor het model. Voer de onderstaande stappen uit:
Selecteer het subtabblad Onderdelen in het linkerdeelvenster.
Sleep het onderdeel Kolommen selecteren in gegevensset onder Gegevenstransformatiemanipulatie < naar het canvas. Dit onderdeel verbinden met het onderdeel Gegevensset .
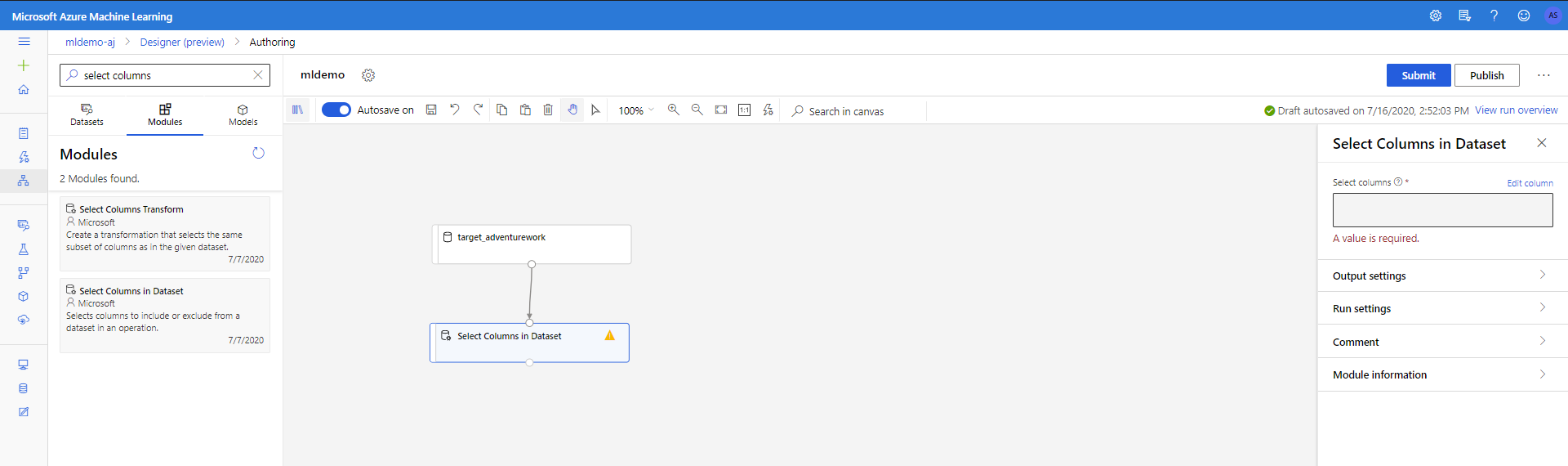
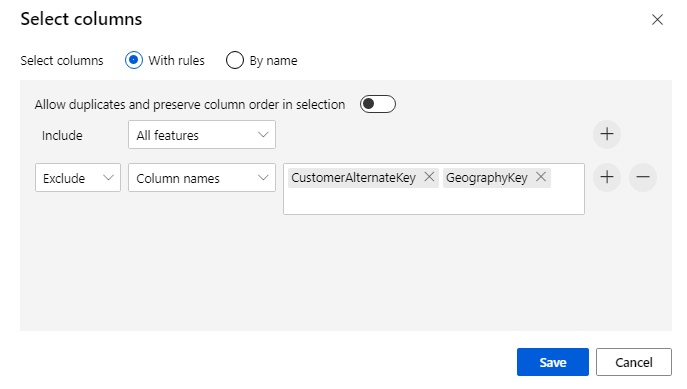
Klik op het onderdeel om het deelvenster Eigenschappen te openen. Klik op Kolom bewerken om op te geven welke kolommen u wilt verwijderen.
Sluit twee kolommen uit: CustomerAlternateKey en GeographyKey. Klik op Opslaan.

Het model bouwen
De gegevens worden gesplitst 80-20: 80% om een machine learning-model te trainen en 20% om het model te testen. Algoritmen met twee klassen worden gebruikt in dit binaire classificatieprobleem.
Sleep het onderdeel Split Data naar het canvas.
Voer in het deelvenster Eigenschappen 0,8 in voor fractie van rijen in de eerste uitvoergegevensset.
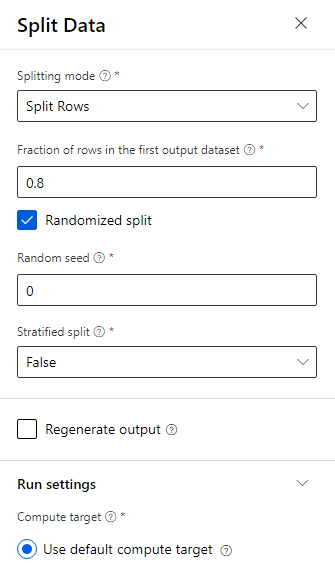
Sleep het Twee-klassen Versterkte Beslissingsboom onderdeel naar het canvas.
Sleep het onderdeel Train Model naar het canvas. Geef invoer op door deze te verbinden met de componenten Two-Class Boosted Decision Tree (ML-algoritme) en Split Data (gegevens om het algoritme op te trainen).
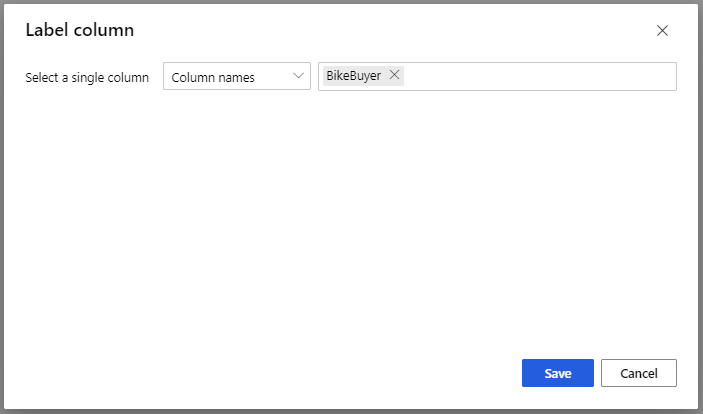
Selecteer in het deelvenster Eigenschappen voor het Train Model-model de optie Labelkolom en kies Kolom bewerken. Selecteer de kolom BikeBuyer als de kolom die u wilt voorspellen en selecteer Opslaan.
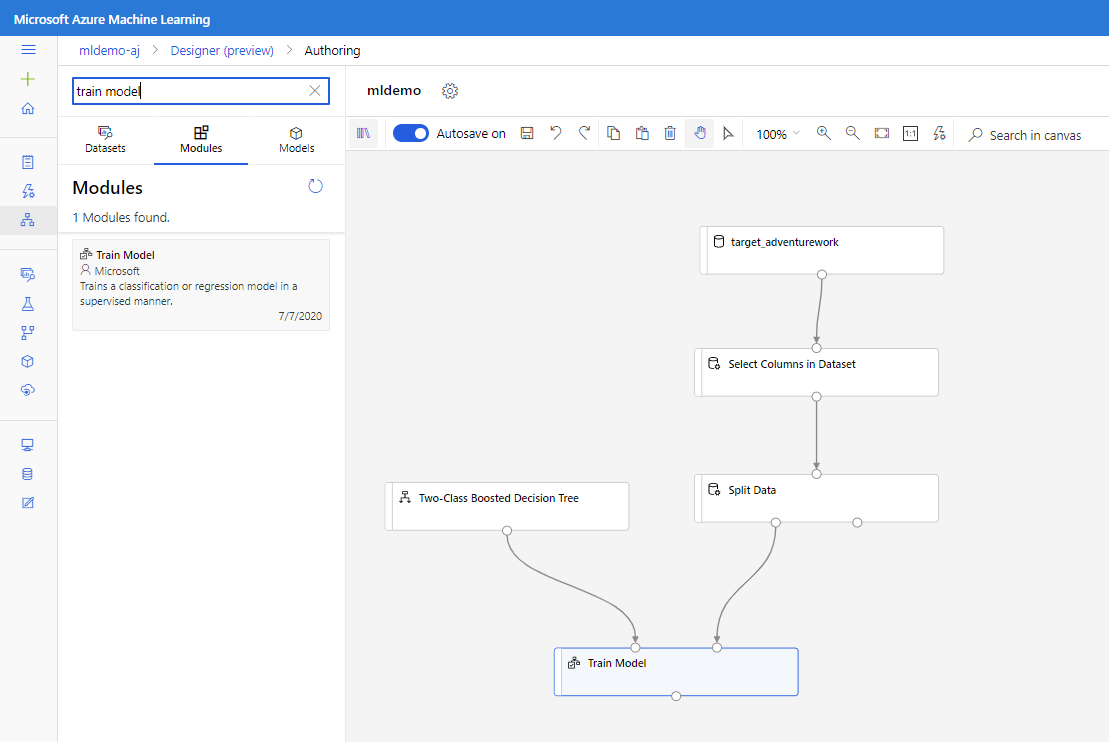
Het model beoordelen
Test nu hoe het model presteert op testgegevens. Er worden twee verschillende algoritmen vergeleken om te zien welke beter presteert. Voer de onderstaande stappen uit:
Sleep Score Model op het canvas en verbind het met Train Model en Split Data componenten.
Sleep de Two-Class Bayes Averaged Perceptron naar het experiment-canvas. Je vergelijkt hoe dit algoritme presteert in vergelijking met de twee-klasse-Boosted Decision Tree.
Kopieer en plak de onderdelen Train Model and Score Model in het canvas.
Sleep het onderdeel Evaluate Model naar het canvas om de twee algoritmen te vergelijken.
Klik op Verzenden om de pijplijnuitvoering in te stellen.
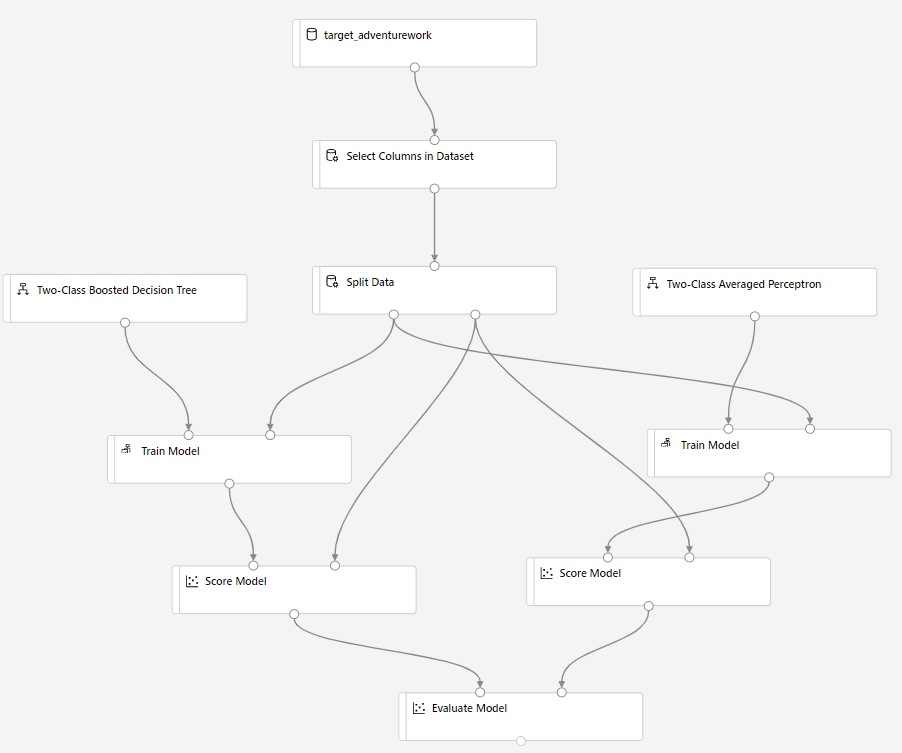
Zodra de uitvoering is voltooid, klikt u met de rechtermuisknop op het onderdeel Evaluatie evalueren en klikt u op Evaluatieresultaten visualiseren.
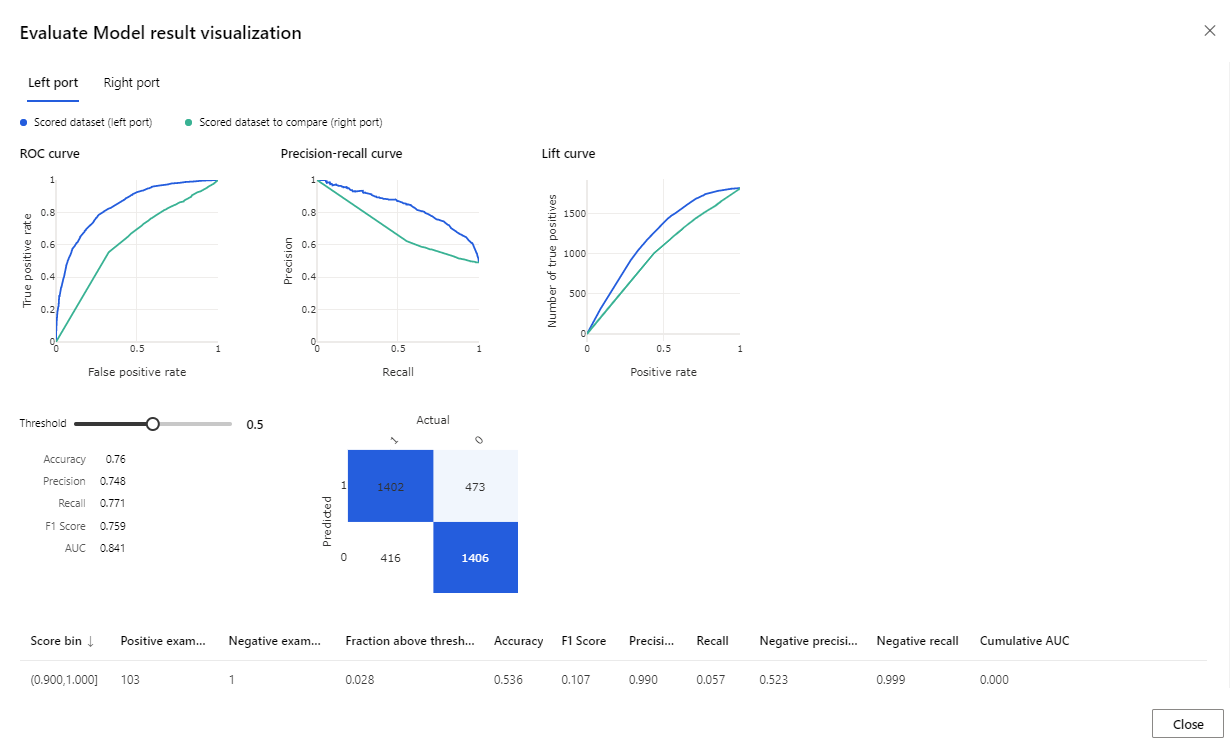

De opgegeven metrische gegevens zijn de ROC-curve, het diagram met precisieherhaling en de liftcurve. Bekijk deze metrische gegevens om te zien dat het eerste model beter presteerde dan het tweede model. Als u wilt bekijken wat het eerste voorspelde model is, klikt u met de rechtermuisknop op het onderdeel Score Model en klikt u op Scored-gegevensset visualiseren om de voorspelde resultaten te bekijken.
Er worden nog twee kolommen toegevoegd aan uw testgegevensset.
- Scored Probabilities (Berekende waarschijnlijkheden): de waarschijnlijkheid dat een klant een fiets koopt.
- Scored Labels (Beoordeelde Labels): de classificatie die door het model is uitgevoerd: fietskoper (1) of niet (0). Deze drempelwaarde voor waarschijnlijkheid voor labeling is ingesteld op 50% en kan worden aangepast.
Vergelijk de kolom BikeBuyer (werkelijk) met de Scored Labels (voorspelling) om te zien hoe goed het model gepresteerd heeft. Vervolgens kunt u dit model gebruiken om voorspellingen te doen voor nieuwe klanten. U kunt dit model publiceren als een webservice of resultaten terugschrijven naar Azure Synapse.
Volgende stappen
Raadpleeg Inleiding tot Machine Learning in Azure voor meer informatie over Azure Machine Learning.
Hier vindt u meer informatie over ingebouwde scoren in het datawarehouse.