Zelfstudie: Azure Functions en Python gebruiken om opgeslagen documenten te verwerken
Document Intelligence kan worden gebruikt als onderdeel van een geautomatiseerde pijplijn voor gegevensverwerking die is gebouwd met Azure Functions. In deze handleiding ziet u hoe u Azure Functions gebruikt om documenten te verwerken die zijn geüpload naar een Azure Blob Storage-container. Deze werkstroom extraheert tabelgegevens uit opgeslagen documenten met behulp van het Document Intelligence-indelingsmodel en slaat de tabelgegevens op in een .csv bestand in Azure. Vervolgens kunt u de gegevens weergeven met Behulp van Microsoft Power BI (hier niet behandeld).
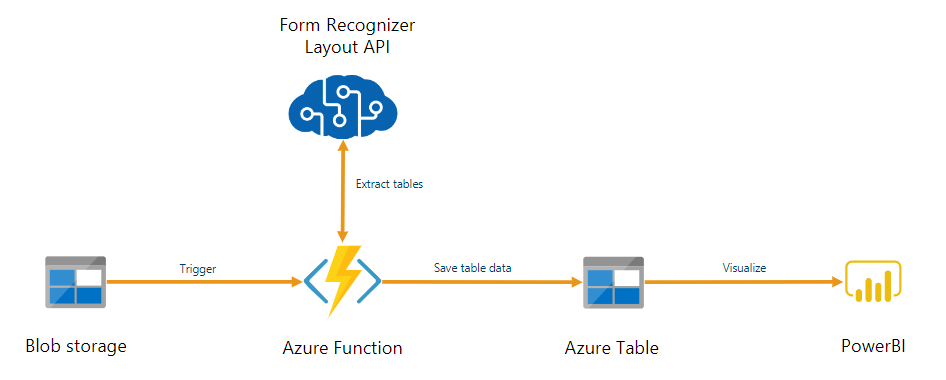
In deze zelfstudie leert u het volgende:
- Een Azure Storage-account maken.
- Maak een Azure Functions-project.
- Indelingsgegevens extraheren uit geüploade formulieren.
- Upload geëxtraheerde indelingsgegevens naar Azure Storage.
Vereisten
Gratis een Azure-abonnement - maken
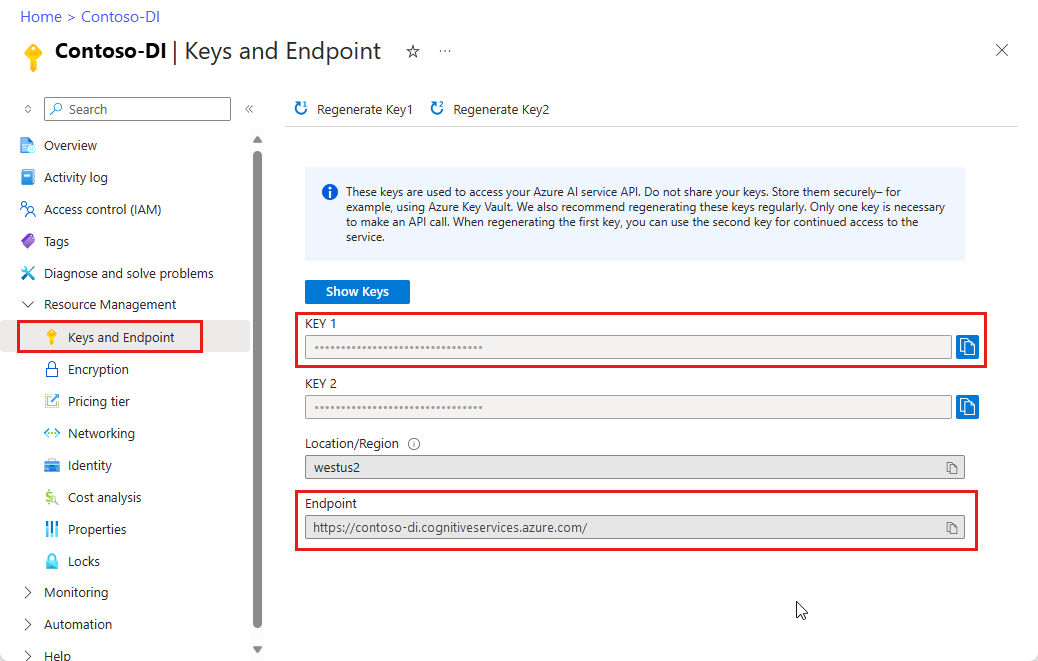
Een Document Intelligence-resource. Zodra u uw Azure-abonnement hebt, maakt u een Document Intelligence-resource in Azure Portal om uw sleutel en eindpunt op te halen. U kunt de gratis prijscategorie (
F0) gebruiken om de service uit te proberen, en later upgraden naar een betaalde laag voor productie.Nadat de resource is geïmplementeerd, selecteert u Ga naar de resource. U hebt de sleutel en het eindpunt nodig van de resource die u maakt om uw toepassing te verbinden met de Document Intelligence-API. Verderop in de zelfstudie plakt u uw sleutel en eindpunt in de onderstaande code:
Python 3.6.x, 3.7.x, 3.8.x of 3.9.x (Python 3.10.x wordt niet ondersteund voor dit project).
De nieuwste versie van Visual Studio Code (VS Code) waarop de volgende extensies zijn geïnstalleerd:
Azure Functions-extensie. Zodra het is geïnstalleerd, ziet u het Azure-logo in het linkernavigatiedeelvenster.
Azure Functions Core Tools versie 3.x (versie 4.x wordt niet ondersteund voor dit project).
Python-extensie voor Visual Studio-code. ZieAan de slag met Python in VS Code voor meer informatie
Azure Storage Explorer geïnstalleerd.
Een lokaal PDF-document dat moet worden geanalyseerd. U kunt ons pdf-voorbeelddocument voor dit project gebruiken.
Een Azure Storage-account maken
Maak een v2 Azure Storage-account voor algemeen gebruik in Azure Portal. Als u niet weet hoe u een Azure-opslagaccount maakt met een opslagcontainer, volgt u deze quickstarts:
- Een opslagaccount maken. Wanneer u uw opslagaccount maakt, selecteert u Standaardprestaties in het veld Prestaties van exemplaardetails>.
- Maak een container. Wanneer u uw container maakt, stelt u het openbare toegangsniveau in op Container (anonieme leestoegang voor containers en bestanden) in het venster Nieuwe container .
Selecteer in het linkerdeelvenster het tabblad Resource delen (CORS) en verwijder indien aanwezig het bestaande CORS-beleid.
Zodra uw opslagaccount is geïmplementeerd, maakt u twee lege blobopslagcontainers, met de naam invoer en uitvoer.
Een Azure Functions-project maken
Maak een nieuwe map met de naam functions-app die het project bevat en kies Selecteren.
Open Visual Studio Code en open het opdrachtenpalet (Ctrl+Shift+P). Zoek en kies Python:Interpreter selecteren → een geïnstalleerde Python-interpreter kiezen die versie 3.6.x, 3.7.x, 3.8.x of 3.9.x is. Met deze selectie wordt het Python-interpreterpad toegevoegd dat u hebt geselecteerd aan uw project.
Selecteer het Azure-logo in het linkernavigatiedeelvenster.
U ziet uw bestaande Azure-resources in de weergave Resources.
Selecteer het Azure-abonnement dat u voor dit project gebruikt. Hieronder ziet u de Azure Function-app.
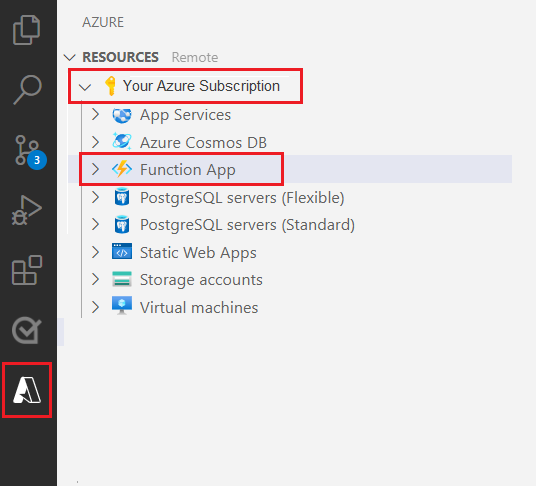
Selecteer de sectie Werkruimte (Lokaal) onder de vermelde resources. Selecteer het plusteken en kies de knop Functie maken.

Wanneer u hierom wordt gevraagd, kiest u Nieuw project maken en navigeert u naar de map function-app . Kies Selecteren.
U wordt gevraagd om verschillende instellingen te configureren:
Selecteer een taal → Kies Python.
Selecteer een Python-interpreter om een virtuele omgeving te maken → selecteer de interpreter die u eerder hebt ingesteld als de standaardinstelling.
Selecteer een sjabloon → azure Blob Storage-trigger te kiezen en geef de trigger een naam of accepteer de standaardnaam. Druk op Enter om te bevestigen.
Selecteer instelling → kies ➕Nieuwe lokale app-instelling maken in de vervolgkeuzelijst.
Selecteer het abonnement → kies uw Azure-abonnement met het opslagaccount dat u hebt gemaakt → selecteer uw opslagaccount → selecteer vervolgens de naam van de opslaginvoercontainer (in dit geval
input/{name}). Druk op Enter om te bevestigen.Selecteer hoe u het project wilt openen → kies Het project openen in het huidige venster in de vervolgkeuzelijst.
Zodra u deze stappen hebt voltooid, voegt VS Code een nieuw Azure Function-project toe met een __init__.py Python-script. Dit script wordt geactiveerd wanneer een bestand wordt geüpload naar de invoeropslagcontainer :
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
De functie testen
Druk op F5 om de basisfunctie uit te voeren. VS Code vraagt u om een opslagaccount te selecteren waarmee u een interface wilt maken.
Selecteer het opslagaccount dat u hebt gemaakt en ga door.
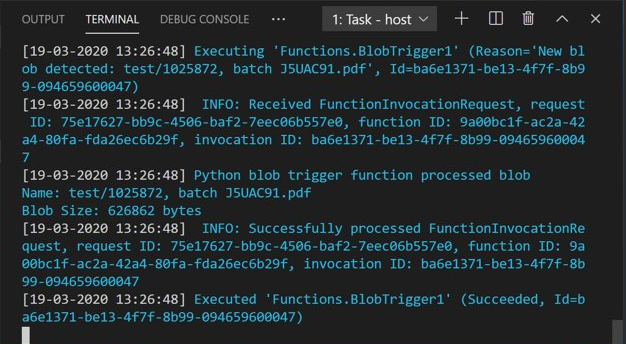
Open Azure Storage Explorer en upload het PDF-voorbeelddocument naar de invoercontainer . Controleer vervolgens de VS Code-terminal. Het script moet registreren dat het is geactiveerd door de PDF-upload.
Stop het script voordat u doorgaat.
Documentverwerkingscode toevoegen
Vervolgens voegt u uw eigen code toe aan het Python-script om de Document Intelligence-service aan te roepen en de geüploade documenten te parseren met behulp van het Document Intelligence-indelingsmodel.
Navigeer in VS Code naar het requirements.txt-bestand van de functie. Dit bestand definieert de afhankelijkheden voor uw script. Voeg de volgende Python-pakketten toe aan het bestand:
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpyOpen vervolgens het __init__.py script. Voeg de volgende
importinstructies toe:import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pdU kunt de gegenereerde
mainfunctie als zodanig laten staan. U voegt uw aangepaste code toe in deze functie.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")Het volgende codeblok roept de Document Intelligence Analyze Layout-API aan op het geüploade document. Vul uw eindpunt- en sleutelwaarden in.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Belangrijk
Vergeet niet de sleutel uit uw code te verwijderen wanneer u klaar bent, en maak deze sleutel nooit openbaar. Gebruik voor productie een veilige manier om uw referenties op te slaan en te openen, zoals Azure Key Vault. Zie Beveiliging van Azure AI-services voor meer informatie.
Voeg vervolgens code toe om een query uit te voeren op de service en de geretourneerde gegevens op te halen.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonVoeg de volgende code toe om verbinding te maken met de Azure Storage-uitvoercontainer. Vul uw eigen waarden in voor de naam en sleutel van het opslagaccount. U kunt de sleutel ophalen op het tabblad Toegangssleutels van uw opslagresource in Azure Portal.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")Met de volgende code wordt het geretourneerde Antwoord van Document Intelligence geparseerd, wordt een .csv-bestand gemaakt en geüpload naar de uitvoercontainer .
Belangrijk
U moet deze code waarschijnlijk bewerken zodat deze overeenkomt met de structuur van uw eigen documenten.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1Ten slotte uploadt het laatste codeblok de geëxtraheerde tabel- en tekstgegevens naar het blobopslagelement.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
De functie uitvoeren
Druk op F5 om de functie opnieuw uit te voeren.
Gebruik Azure Storage Explorer om een pdf-voorbeeldformulier te uploaden naar de invoeropslagcontainer . Met deze actie wordt het script geactiveerd dat moet worden uitgevoerd. Vervolgens ziet u het resulterende .csv bestand (weergegeven als een tabel) in de uitvoercontainer .
U kunt deze container verbinden met Power BI om uitgebreide visualisaties te maken van de gegevens die deze bevat.
Volgende stappen
In deze zelfstudie hebt u geleerd hoe u een Azure-functie gebruikt die is geschreven in Python om geüploade PDF-documenten automatisch te verwerken en de inhoud ervan uit te voeren in een meer gegevensvriendelijke indeling. Leer vervolgens hoe u Power BI gebruikt om de gegevens weer te geven.
- Wat is Document Intelligence?
- Meer informatie over het indelingsmodel
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor