Uw professionele spraakmodel trainen
In dit artikel leert u hoe u een aangepaste neurale stem traint via de Speech Studio-portal.
Belangrijk
Aangepaste neurale spraaktraining is momenteel alleen beschikbaar in sommige regio's. Nadat uw spraakmodel is getraind in een ondersteunde regio, kunt u het naar een spraakresource in een andere regio kopiëren , indien nodig. Zie de voetnoten in de speech-servicetabel voor meer informatie.
De duur van de training varieert, afhankelijk van de hoeveelheid gegevens die u gebruikt. Het duurt gemiddeld ongeveer 40 rekenuren om een aangepaste neurale stem te trainen. Gebruikers van een Standard-abonnement (S0) kunnen vier stemmen tegelijk trainen. Als u de limiet bereikt, wacht u totdat ten minste één van uw spraakmodellen klaar is met trainen en probeert u het opnieuw.
Notitie
Hoewel het totale aantal benodigde uren per trainingsmethode varieert, geldt dezelfde eenheidsprijs voor elk. Zie de prijsinformatie voor aangepaste neurale training voor meer informatie.
Een trainingsmethode kiezen
Nadat u uw gegevensbestanden hebt gevalideerd, gebruikt u deze om uw aangepaste neurale spraakmodel te bouwen. Wanneer u een aangepaste neurale stem maakt, kunt u ervoor kiezen om deze te trainen met een van de volgende methoden:
Neurale: Maak een stem in dezelfde taal als uw trainingsgegevens.
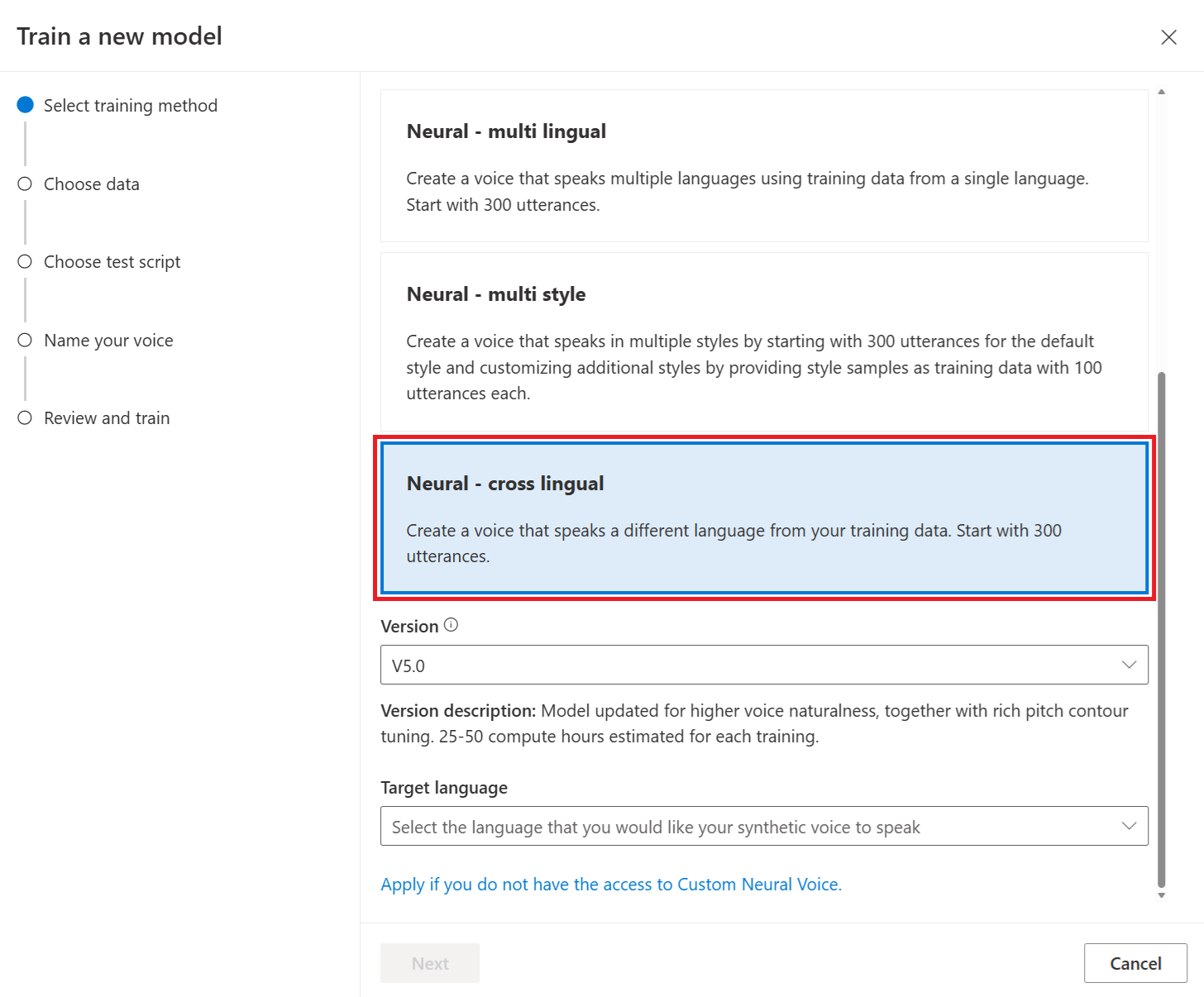
Neurale taaloverschrijdende: maak een stem die een andere taal spreekt dan uw trainingsgegevens. Met de
zh-CNtrainingsgegevens kunt u bijvoorbeeld een stem maken die spreekten-US.De taal van de trainingsgegevens en de doeltaal moet beide een van de talen zijn die worden ondersteund voor taaloverschrijdende spraaktraining. U hoeft geen trainingsgegevens voor te bereiden in de doeltaal, maar uw testscript moet zich in de doeltaal hebben.
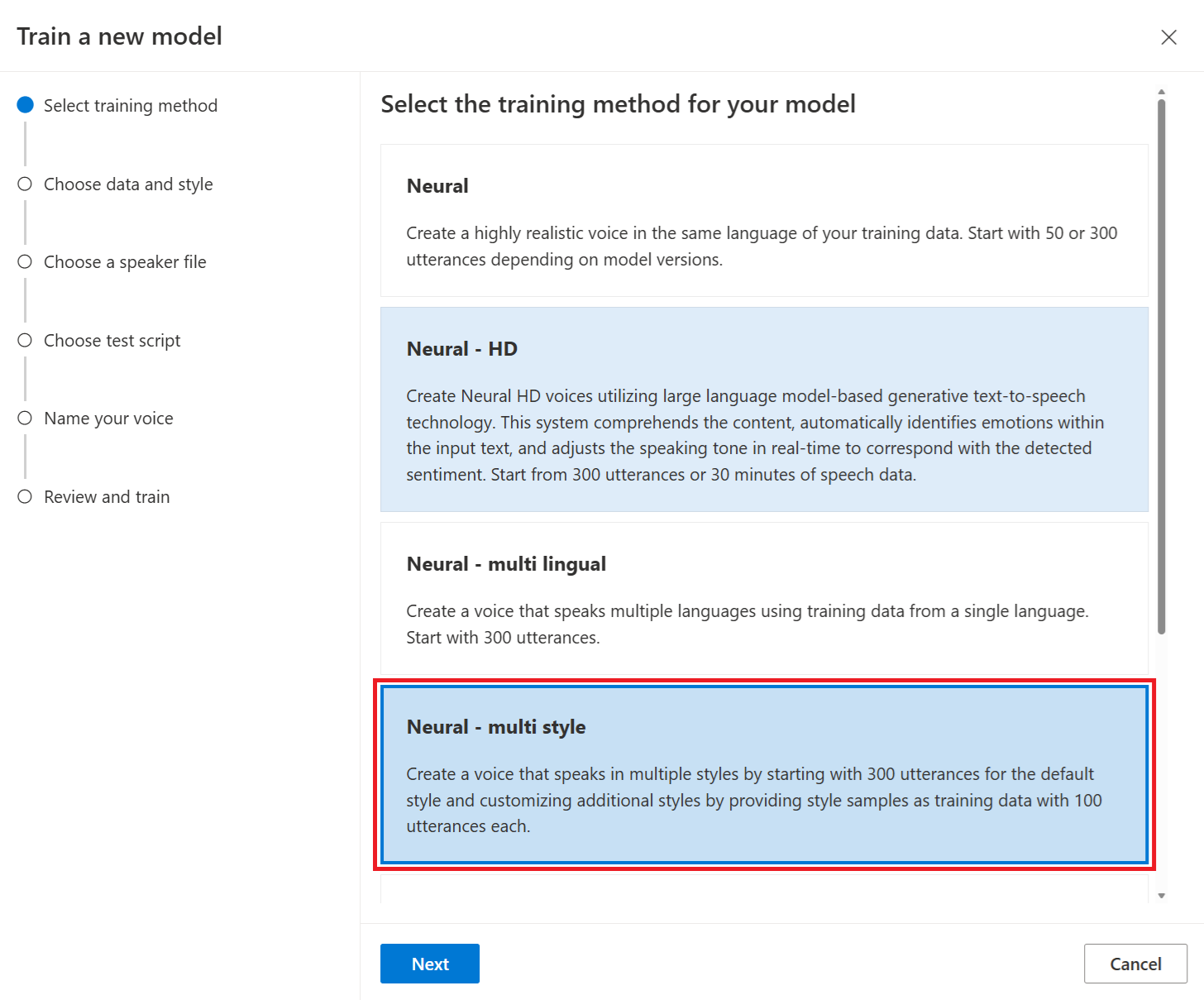
Neurale - meerdere stijlen: Maak een aangepaste neurale stem die in meerdere stijlen en emoties spreekt, zonder nieuwe trainingsgegevens toe te voegen. Meerdere stijlstemmen zijn handig voor videospeltekens, conversationele chatbots, audioboeken, inhoudslezers en meer.
Als u een stem met meerdere stijlen wilt maken, moet u een set algemene trainingsgegevens voorbereiden, ten minste 300 utterances. Selecteer een of meer van de vooraf ingestelde doelstijlen voor spreken. U kunt ook meerdere aangepaste stijlen maken door stijlvoorbeelden, van ten minste 100 utterances per stijl, als extra trainingsgegevens voor dezelfde stem op te geven. De ondersteunde vooraf ingestelde stijlen variëren afhankelijk van verschillende talen. Bekijk beschikbare vooraf ingestelde stijlen in verschillende talen.
De taal van de trainingsgegevens moet een van de talen zijn die worden ondersteund voor aangepaste neurale spraak, cross-lingual of training met meerdere stijlen.
Uw aangepaste neurale spraakmodel trainen
Als u een aangepaste neurale spraak wilt maken in Speech Studio, volgt u deze stappen voor een van de volgende methoden:
Meld u aan bij Speech Studio.
Selecteer Aangepaste stem<>Uw projectnaam>>Train model>Train a new model.
Selecteer Neural als de trainingsmethode voor uw model en selecteer vervolgens Volgende. Als u een andere trainingsmethode wilt gebruiken, raadpleegt u Neural - cross lingual of Neural - multi style.
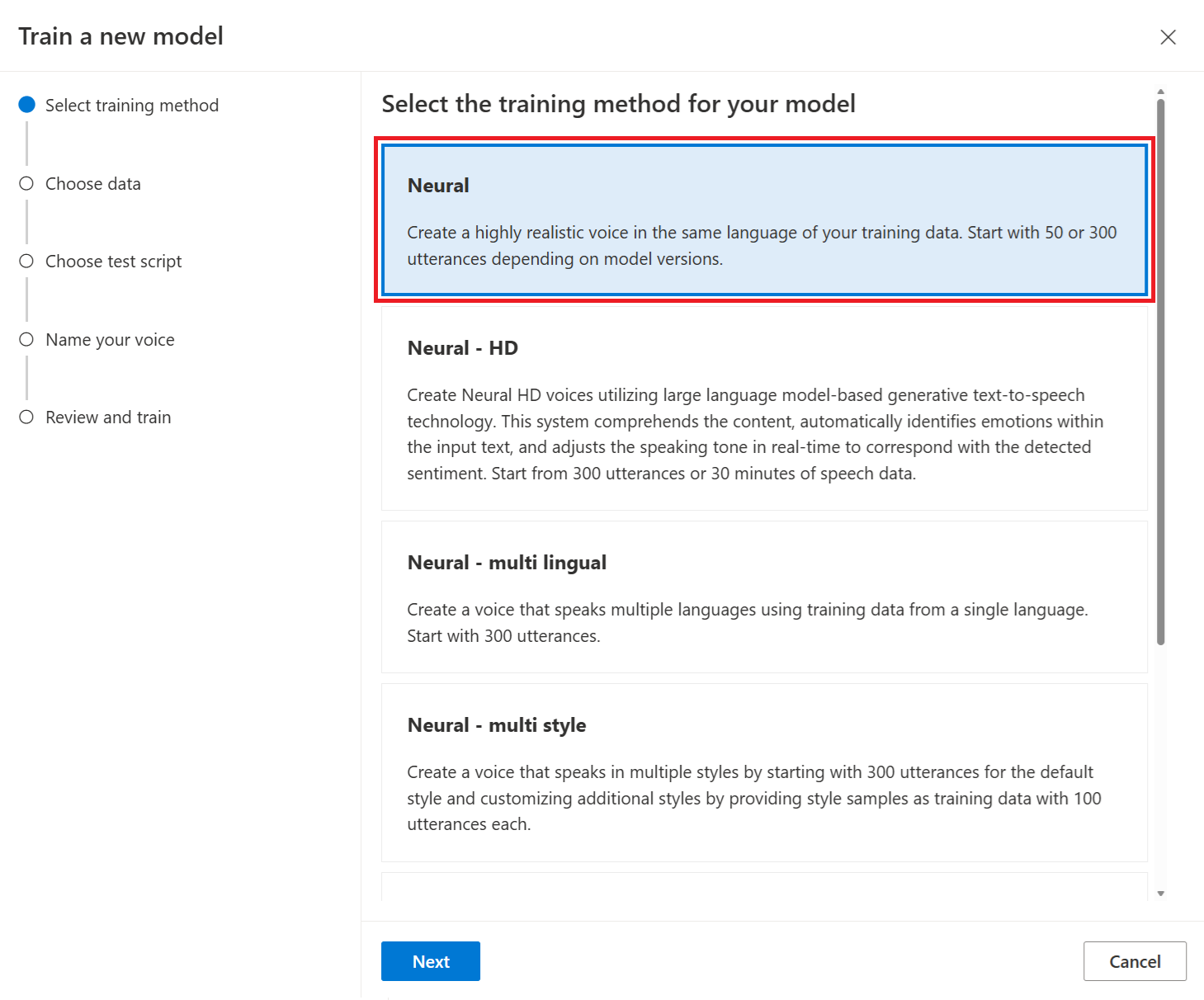
Selecteer een versie van het trainingsrecept voor uw model. De nieuwste versie is standaard geselecteerd. De ondersteunde functies en trainingstijd kunnen per versie verschillen. Normaal gesproken raden we de nieuwste versie aan. In sommige gevallen kunt u een eerdere versie kiezen om de trainingstijd te verminderen. Zie Tweetalige training voor meer informatie over tweetalige training en verschillen tussen landinstellingen.
Notitie
Modelversies
V2.2021.07,V4.2021.10, ,V5.2022.05enV9.2023.10V6.2022.11worden tegen 1 oktober 2024 buiten gebruik gesteld. De spraakmodellen die al in deze buiten gebruik gestelde versies zijn gemaakt, worden niet beïnvloed.Selecteer de gegevens die u wilt gebruiken voor training. Dubbele audionamen worden uit de training verwijderd. Zorg ervoor dat de gegevens die u selecteert niet dezelfde audionamen bevatten voor meerdere .zip bestanden.
U kunt alleen verwerkte gegevenssets selecteren voor training. Als u de trainingsset niet in de lijst ziet, controleert u de verwerkingsstatus van uw gegevens.
Selecteer een sprekerbestand met de stemtalentinstructie die overeenkomt met de spreker in uw trainingsgegevens.
Selecteer Volgende.
Elke training genereert automatisch 100 voorbeeldaudiobestanden om u te helpen het model te testen met een standaardscript.
U kunt eventueel ook Mijn eigen testscript toevoegen selecteren en uw eigen testscript opgeven met maximaal 100 utterances om het model zonder extra kosten te testen. De gegenereerde audiobestanden zijn een combinatie van de automatische testscripts en aangepaste testscripts. Zie testscriptvereisten voor meer informatie.
Voer een naam in om het model te identificeren. Kies zorgvuldig een naam. De modelnaam wordt gebruikt als de spraaknaam in uw aanvraag voor spraaksynthese door de SDK en SSML-invoer. Alleen letters, cijfers en een paar interpunctietekens zijn toegestaan. Gebruik verschillende namen voor verschillende neurale spraakmodellen.
Voer desgewenst de beschrijving in om u te helpen het model te identificeren. Een veelvoorkomend gebruik van de beschrijving is het vastleggen van de namen van de gegevens die u hebt gebruikt om het model te maken.
Selecteer Volgende.
Controleer de instellingen en selecteer het vakje om de gebruiksvoorwaarden te accepteren.
Selecteer Verzenden om het model te trainen.
Tweetalige training
Als u het type neurale training selecteert, kunt u een stem trainen om in meerdere talen te spreken. De zh-CN, zh-HKen zh-TW landinstellingen ondersteunen tweetalige training voor de stem om zowel Chinees als Engels te spreken. Afhankelijk van uw trainingsgegevens kan de gesynthetiseerde stem Engels spreken met een Engels accent of Engels met hetzelfde accent als de trainingsgegevens.
Notitie
Als u wilt dat een stem in de zh-CN landinstelling Engels spreekt met hetzelfde accent als de voorbeeldgegevens, moet u kiezen Chinese (Mandarin, Simplified), English bilingual bij het maken van een project of de zh-CN (English bilingual) landinstelling voor de trainingsetgegevens opgeven via REST API.
In de volgende tabel ziet u de verschillen tussen de landinstellingen:
| Landinstelling van Speech Studio | REST API-landinstellingen | Tweetalige ondersteuning |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Als uw voorbeeldgegevens Engels bevatten, spreekt de gesynthetiseerde stem Engels met een Engels accent, in plaats van hetzelfde accent als de voorbeeldgegevens, ongeacht de hoeveelheid Engelse gegevens. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Als u wilt dat de gesynthetiseerde stem Engels spreekt met hetzelfde accent als de voorbeeldgegevens, raden we u aan meer dan 10% Engelse gegevens op te nemen in uw trainingsset. Anders is het Engels sprekende accent mogelijk niet ideaal. |
Chinese (Cantonese, Simplified) |
zh-HK |
Als u een gesynthetiseerde stem wilt trainen die Engels kan spreken met hetzelfde accent als uw voorbeeldgegevens, moet u ervoor zorgen dat u meer dan 10% Engelse gegevens in uw trainingsset opgeeft. Anders wordt het standaard ingesteld op een Engels native accent. De drempelwaarde van 10% wordt berekend op basis van de gegevens die zijn geaccepteerd na het uploaden, niet de gegevens vóór het uploaden. Als sommige geüploade Engelse gegevens worden geweigerd vanwege defecten en niet voldoen aan de drempelwaarde van 10%, wordt de gesynthetiseerde stem standaard ingesteld op een Engels native accent. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Als u een gesynthetiseerde stem wilt trainen die Engels kan spreken met hetzelfde accent als uw voorbeeldgegevens, moet u ervoor zorgen dat u meer dan 10% Engelse gegevens in uw trainingsset opgeeft. Anders wordt het standaard ingesteld op een Engels native accent. De drempelwaarde van 10% wordt berekend op basis van de gegevens die zijn geaccepteerd na het uploaden, niet de gegevens vóór het uploaden. Als sommige geüploade Engelse gegevens worden geweigerd vanwege defecten en niet voldoen aan de drempelwaarde van 10%, wordt de gesynthetiseerde stem standaard ingesteld op een Engels native accent. |
Beschikbare vooraf ingestelde stijlen in verschillende talen
De volgende tabel bevat een overzicht van de verschillende vooraf ingestelde stijlen op basis van verschillende talen.
| Spreekstijl | Taal (landinstelling) |
|---|---|
| boos | Engels (Verenigde Staten) (en-US)Japans (Japan) ( ja-JP) 1Chinees (Mandarijn, Vereenvoudigd) ( zh-CN) 1 |
| kalm | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| chat | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| vrolijk | Engels (Verenigde Staten) (en-US)Japans (Japan) ( ja-JP) 1Chinees (Mandarijn, Vereenvoudigd) ( zh-CN) 1 |
| ontevreden | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| opgewonden | Engels (Verenigde Staten) (en-US) |
| angstig | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| vriendelijk | Engels (Verenigde Staten) (en-US) |
| hoopvol | Engels (Verenigde Staten) (en-US) |
| treurig | Engels (Verenigde Staten) (en-US)Japans (Japan) ( ja-JP) 1Chinees (Mandarijn, Vereenvoudigd) ( zh-CN) 1 |
| geschreeuw | Engels (Verenigde Staten) (en-US) |
| ernstig | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| Doodsbang | Engels (Verenigde Staten) (en-US) |
| onvriendelijk | Engels (Verenigde Staten) (en-US) |
| Whispering | Engels (Verenigde Staten) (en-US) |
1 De neurale stemstijl is beschikbaar in openbare preview. Stijlen in openbare preview zijn alleen beschikbaar in deze serviceregio's: VS - oost, Europa - west en Azië - zuidoost.
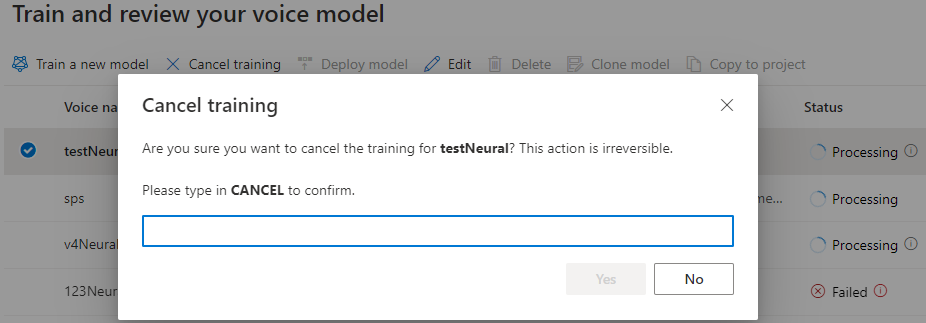
In de tabel Model trainen wordt een nieuwe vermelding weergegeven die overeenkomt met dit zojuist gemaakte model. De status weerspiegelt het proces van het converteren van uw gegevens naar een spraakmodel, zoals beschreven in deze tabel:
| Staat | Betekenis |
|---|---|
| Verwerken | Uw spraakmodel wordt gemaakt. |
| Geslaagd | Uw spraakmodel is gemaakt en kan worden geïmplementeerd. |
| Mislukt | Uw spraakmodel is mislukt tijdens de training. De oorzaak van de fout kan bijvoorbeeld ongelezen gegevensproblemen of netwerkproblemen zijn. |
| Geannuleerd | De training voor uw spraakmodel is geannuleerd. |
Terwijl de modelstatus Verwerking is, kunt u Training annuleren selecteren om uw spraakmodel te annuleren. Er worden geen kosten in rekening gebracht voor deze geannuleerde training.
Nadat u klaar bent met het trainen van het model, kunt u de modeldetails bekijken en uw spraakmodel testen.
U kunt het hulpprogramma Voor het maken van audio-inhoud in Speech Studio gebruiken om audio te maken en uw geïmplementeerde stem af te stemmen. Indien van toepassing op uw stem, kunt u een van de stijlen selecteren.
De naam van uw model wijzigen
Als u de naam van het model dat u hebt gemaakt, wilt wijzigen, selecteert u Kloonmodel om een kloon van het model te maken met een nieuwe naam in het huidige project.
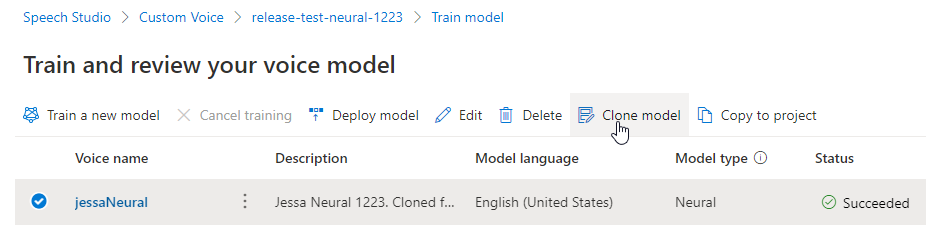
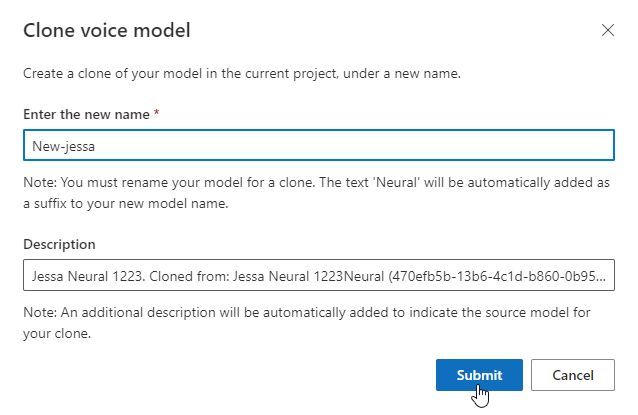
Voer de nieuwe naam in het venster Spraakmodel klonen in en selecteer Verzenden. De tekst Neural wordt automatisch toegevoegd als achtervoegsel aan de naam van uw nieuwe model.
Uw spraakmodel testen
Nadat uw spraakmodel is gebouwd, kunt u de gegenereerde voorbeeldaudiobestanden gebruiken om het te testen voordat u het implementeert.
De kwaliteit van de stem is afhankelijk van veel factoren, zoals:
- De grootte van de trainingsgegevens.
- De kwaliteit van de opname.
- De nauwkeurigheid van het transcriptbestand.
- Hoe goed de opgenomen stem in de trainingsgegevens overeenkomt met de persoonlijkheid van de ontworpen stem voor uw beoogde gebruiksscenario.
Selecteer DefaultTests onder Testen om naar de voorbeeldaudiobestanden te luisteren. De standaardtestvoorbeelden bevatten 100 voorbeeldaudiobestanden die automatisch tijdens de training worden gegenereerd om u te helpen het model te testen. Naast deze 100 audiobestanden die standaard worden geleverd, worden uw eigen testscriptuitingen ook toegevoegd aan defaulttestset . Deze toevoeging is maximaal 100 utterances. Er worden geen kosten in rekening gebracht voor het testen met DefaultTests.
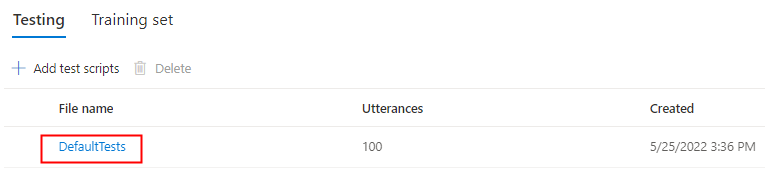
Als u uw eigen testscripts wilt uploaden om uw model verder te testen, selecteert u Testscripts toevoegen om uw eigen testscript te uploaden.
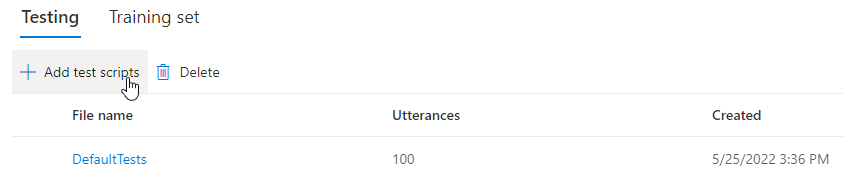
Voordat u een testscript uploadt, controleert u de vereisten voor testscripts. Er worden kosten in rekening gebracht voor het extra testen met de batchsynthese op basis van het aantal factureerbare tekens. Zie prijzen voor Azure AI Speech.
Selecteer onder Testscripts toevoegen de optie Bladeren naar een bestand om uw eigen script te selecteren en selecteer Vervolgens Toevoegen om het te uploaden.
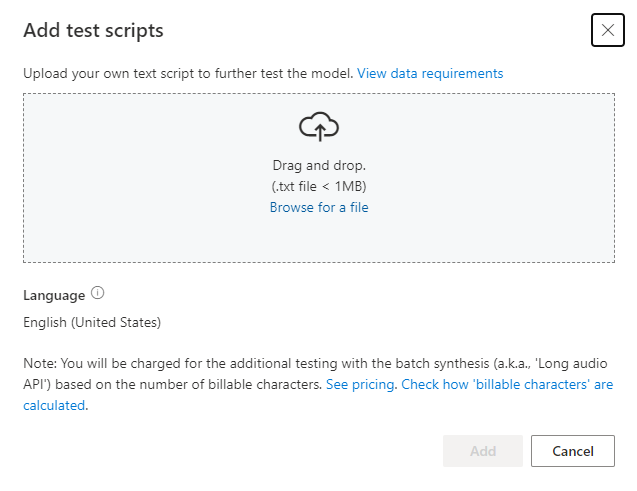
Vereisten voor testscripts
Het testscript moet een .txt-bestand zijn dat kleiner is dan 1 MB. Ondersteunde coderingsindelingen zijn ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE of UTF-16-BE.
In tegenstelling tot de transcriptiebestanden van de training moet het testscript de uitings-id uitsluiten. Dit is de bestandsnaam van elke utterance. Anders worden deze id's gesproken.
Hier volgt een voorbeeldset utterances in één .txt bestand:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Elke alinea van de uiting resulteert in een afzonderlijke audio. Als u alle zinnen in één audio wilt combineren, maakt u ze één alinea.
Notitie
De gegenereerde audiobestanden zijn een combinatie van de automatische testscripts en aangepaste testscripts.
Engine-versie voor uw spraakmodel bijwerken
Azure-tekst-naar-spraakengines worden van tijd tot tijd bijgewerkt om het nieuwste taalmodel vast te leggen waarmee de uitspraak van de taal wordt gedefinieerd. Nadat u uw stem hebt getraind, kunt u uw stem toepassen op het nieuwe taalmodel door bij te werken naar de nieuwste engineversie.
Wanneer er een nieuwe engine beschikbaar is, wordt u gevraagd uw neurale spraakmodel bij te werken.

Ga naar de pagina met modeldetails en volg de instructies op het scherm om de nieuwste engine te installeren.
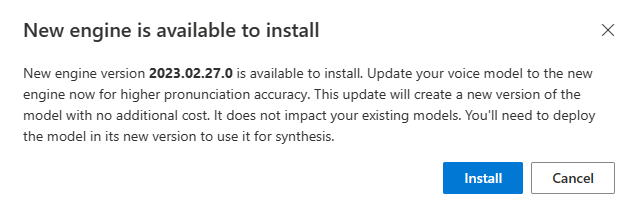
U kunt ook de nieuwste engine later installeren selecteren om uw model bij te werken naar de nieuwste engineversie.
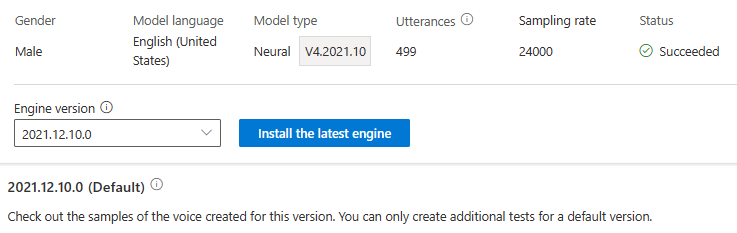
Er worden geen kosten in rekening gebracht voor de engine-update. De vorige versies worden nog steeds bewaard.
U kunt alle engineversies voor het model controleren in de lijst met engineversies of een versie verwijderen als u het niet meer nodig hebt.
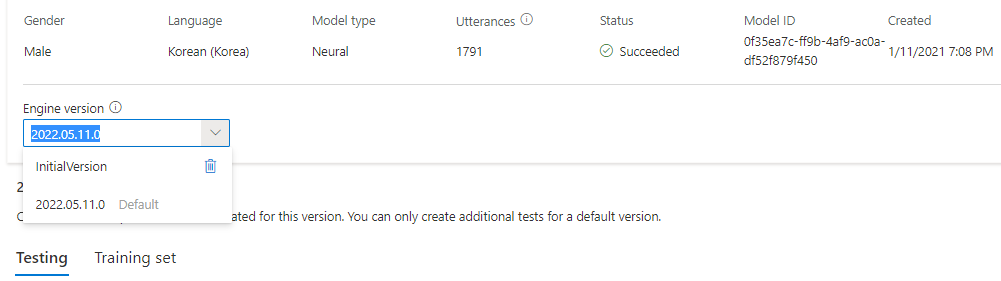
De bijgewerkte versie wordt automatisch als standaard ingesteld. Maar u kunt de standaardversie wijzigen door een versie te selecteren in de vervolgkeuzelijst en Als standaard instellen te selecteren.
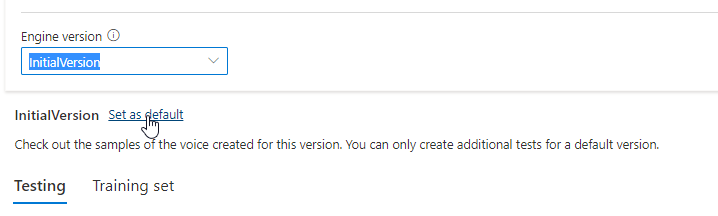

Als u elke engineversie van uw spraakmodel wilt testen, kunt u een versie in de lijst selecteren en vervolgens DefaultTests selecteren onder Testen om naar de voorbeeldaudiobestanden te luisteren. Als u uw eigen testscripts wilt uploaden om uw huidige engineversie verder te testen, controleert u eerst of de versie als standaard is ingesteld en volgt u de stappen in Uw spraakmodel testen.
Als u de engine bijwerkt, wordt er zonder extra kosten een nieuwe versie van het model gemaakt. Nadat u de engineversie voor uw spraakmodel hebt bijgewerkt, moet u de nieuwe versie implementeren om een nieuw eindpunt te maken. U kunt alleen de standaardversie implementeren.
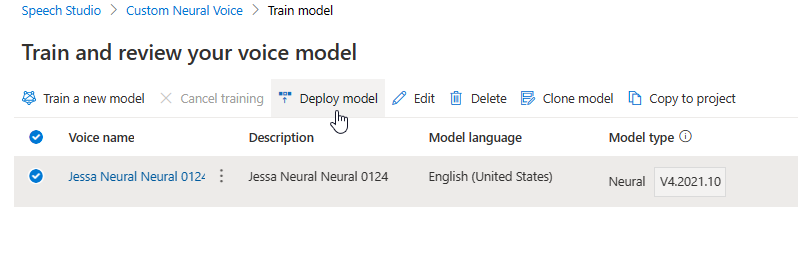
Nadat u een nieuw eindpunt hebt gemaakt, moet u het verkeer overdragen naar het nieuwe eindpunt in uw product.
Zie Kenmerken en beperkingen voor het gebruik van aangepaste neurale spraak voor meer informatie over de mogelijkheden en limieten van deze functie en de best practice om de kwaliteit van uw model te verbeteren.
Uw spraakmodel kopiëren naar een ander project
U kunt uw spraakmodel kopiëren naar een ander project voor dezelfde regio of een andere regio. U kunt bijvoorbeeld een neuraal spraakmodel kopiëren dat in de ene regio is getraind, naar een project voor een andere regio.
Notitie
Aangepaste neurale spraaktraining is momenteel alleen beschikbaar in sommige regio's. U kunt een neuraal spraakmodel van die regio's naar andere regio's kopiëren. Zie de regio's voor aangepaste neurale spraak voor meer informatie.
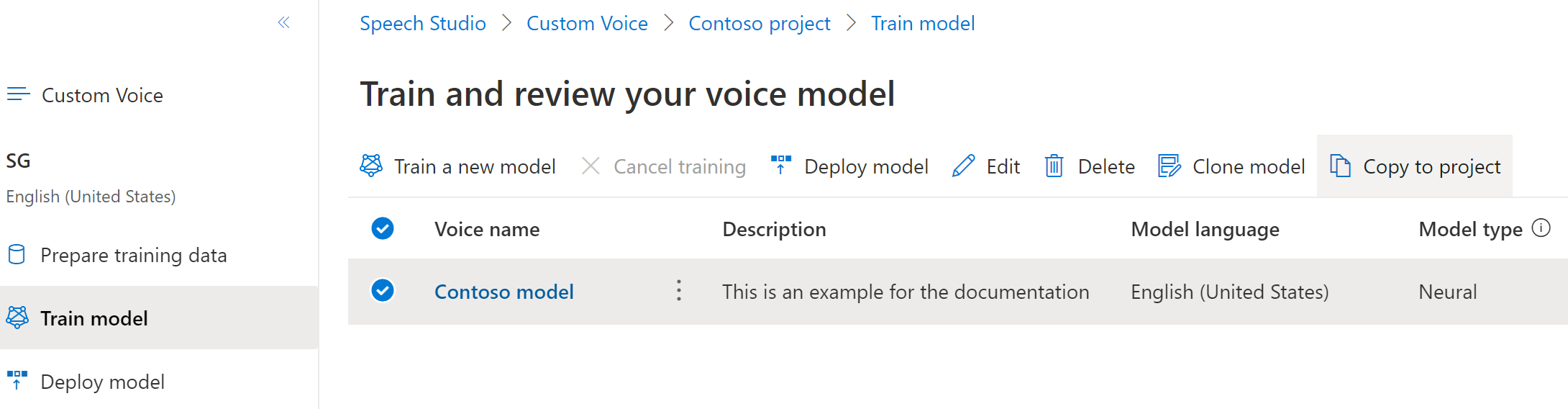
Uw aangepaste neurale spraakmodel naar een ander project kopiëren:
Selecteer op het tabblad Model trainen een spraakmodel dat u wilt kopiëren en selecteer vervolgens Kopiëren naar project.
Selecteer het abonnement, de regio, de spraakresource en project waar u het model wilt kopiëren. U moet een spraakresource en -project in de doelregio hebben, anders moet u ze eerst maken.
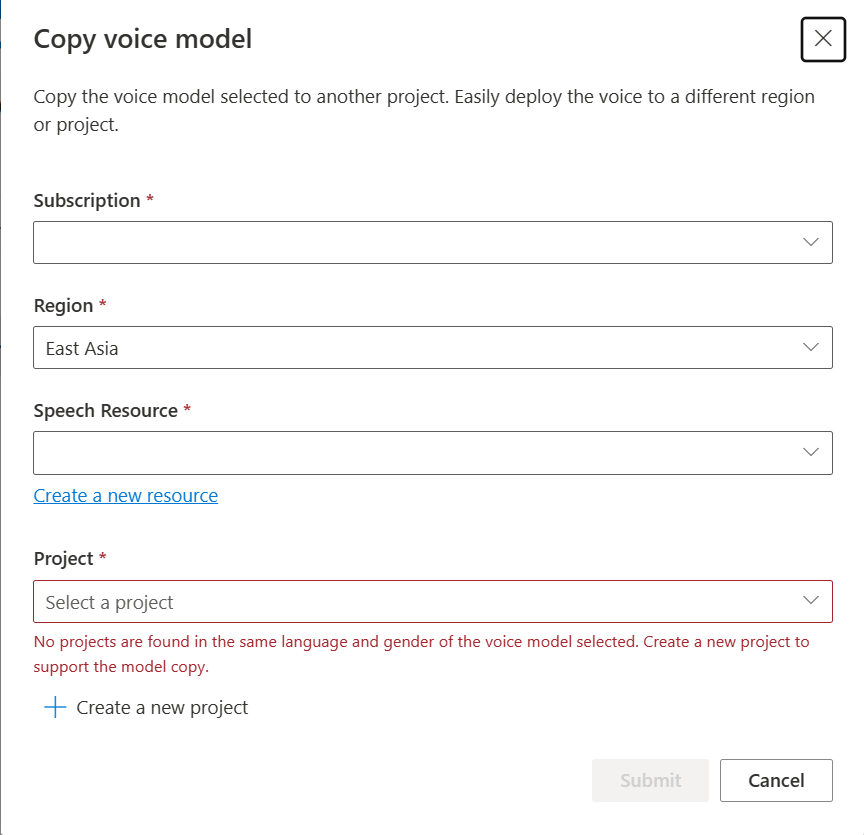
Selecteer Verzenden om het model te kopiëren.
Selecteer Model weergeven onder het meldingsbericht voor het kopiëren.
Navigeer naar het project waar u het model hebt gekopieerd om de modelkopie te implementeren.
Volgende stappen
In dit artikel leert u hoe u een aangepaste neurale stem traint via de aangepaste spraak-API.
Belangrijk
Aangepaste neurale spraaktraining is momenteel alleen beschikbaar in sommige regio's. Nadat uw spraakmodel is getraind in een ondersteunde regio, kunt u het naar een spraakresource in een andere regio kopiëren, indien nodig. Zie de voetnoten in de speech-servicetabel voor meer informatie.
De duur van de training varieert, afhankelijk van de hoeveelheid gegevens die u gebruikt. Het duurt gemiddeld ongeveer 40 rekenuren om een aangepaste neurale stem te trainen. Gebruikers van een Standard-abonnement (S0) kunnen vier stemmen tegelijk trainen. Als u de limiet bereikt, wacht u totdat ten minste één van uw spraakmodellen klaar is met trainen en probeert u het opnieuw.
Notitie
Hoewel het totale aantal benodigde uren per trainingsmethode varieert, geldt dezelfde eenheidsprijs voor elk. Zie de prijsinformatie voor aangepaste neurale training voor meer informatie.
Een trainingsmethode kiezen
Nadat u uw gegevensbestanden hebt gevalideerd, gebruikt u deze om uw aangepaste neurale spraakmodel te bouwen. Wanneer u een aangepaste neurale stem maakt, kunt u ervoor kiezen om deze te trainen met een van de volgende methoden:
Neurale: Maak een stem in dezelfde taal als uw trainingsgegevens.
Neurale taaloverschrijdende: maak een stem die een andere taal spreekt dan uw trainingsgegevens. Met de
fr-FRtrainingsgegevens kunt u bijvoorbeeld een stem maken die spreekten-US.De taal van de trainingsgegevens en de doeltaal moet beide een van de talen zijn die worden ondersteund voor taaloverschrijdende spraaktraining. U hoeft geen trainingsgegevens voor te bereiden in de doeltaal, maar uw testscript moet zich in de doeltaal hebben.
Neurale - meerdere stijlen: Maak een aangepaste neurale stem die in meerdere stijlen en emoties spreekt, zonder nieuwe trainingsgegevens toe te voegen. Meerdere stijlstemmen zijn handig voor videospeltekens, conversationele chatbots, audioboeken, inhoudslezers en meer.
Als u een stem met meerdere stijlen wilt maken, moet u een set algemene trainingsgegevens voorbereiden, ten minste 300 utterances. Selecteer een of meer van de vooraf ingestelde doelstijlen voor spreken. U kunt ook meerdere aangepaste stijlen maken door stijlvoorbeelden, van ten minste 100 utterances per stijl, als extra trainingsgegevens voor dezelfde stem op te geven. De ondersteunde vooraf ingestelde stijlen variëren afhankelijk van verschillende talen. Bekijk beschikbare vooraf ingestelde stijlen in verschillende talen.
De taal van de trainingsgegevens moet een van de talen zijn die worden ondersteund voor aangepaste neurale spraak, cross lingual of meerdere stijltrainingen.
Een spraakmodel maken
Als u een neurale stem wilt maken, gebruikt u de Models_Create bewerking van de aangepaste spraak-API. Bouw de aanvraagbody volgens de volgende instructies:
- Stel de vereiste
projectIdeigenschap in. Zie Een project maken. - Stel de vereiste
consentIdeigenschap in. Zie Stemtalenttoestemming toevoegen. - Stel de vereiste
trainingSetIdeigenschap in. Zie Een trainingsset maken. - Stel de vereiste recepteigenschap
kindin opDefaultvoor neurale spraaktraining. Het recepttype geeft de trainingsmethode aan en kan later niet meer worden gewijzigd. Als u een andere trainingsmethode wilt gebruiken, raadpleegt u Neural - cross lingual of Neural - multi style. Zie Tweetalige training voor meer informatie over tweetalige training en verschillen tussen landinstellingen. - Stel de vereiste
voiceNameeigenschap in. De naam van de stem moet eindigen op 'Neural' en kan later niet meer worden gewijzigd. Kies zorgvuldig een naam. De spraaknaam wordt gebruikt in uw aanvraag voor spraaksynthese door de SDK en SSML-invoer. Alleen letters, cijfers en een paar interpunctietekens zijn toegestaan. Gebruik verschillende namen voor verschillende neurale spraakmodellen. - U kunt desgewenst de
descriptioneigenschap voor de spraakbeschrijving instellen. De spraakbeschrijving kan later worden gewijzigd.
Maak een HTTP PUT-aanvraag met behulp van de URI, zoals wordt weergegeven in het volgende Models_Create voorbeeld.
- Vervang door
YourResourceKeyuw Spraak-resourcesleutel. - Vervang door
YourResourceRegionuw spraakresourceregio. - Vervang door
JessicaModelIdeen model-id van uw keuze. De hoofdlettergevoelige id wordt gebruikt in de URI van het model en kan later niet meer worden gewijzigd.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
U ontvangt een antwoordtekst in de volgende indeling:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Tweetalige training
Als u het type neurale training selecteert, kunt u een stem trainen om in meerdere talen te spreken. De zh-CN, zh-HKen zh-TW landinstellingen ondersteunen tweetalige training voor de stem om zowel Chinees als Engels te spreken. Afhankelijk van uw trainingsgegevens kan de gesynthetiseerde stem Engels spreken met een Engels accent of Engels met hetzelfde accent als de trainingsgegevens.
Notitie
Als u wilt dat een stem in de zh-CN landinstelling Engels spreekt met hetzelfde accent als de voorbeeldgegevens, moet u kiezen Chinese (Mandarin, Simplified), English bilingual bij het maken van een project of de zh-CN (English bilingual) landinstelling voor de trainingsetgegevens opgeven via REST API.
In de volgende tabel ziet u de verschillen tussen de landinstellingen:
| Landinstelling van Speech Studio | REST API-landinstellingen | Tweetalige ondersteuning |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Als uw voorbeeldgegevens Engels bevatten, spreekt de gesynthetiseerde stem Engels met een Engels accent, in plaats van hetzelfde accent als de voorbeeldgegevens, ongeacht de hoeveelheid Engelse gegevens. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Als u wilt dat de gesynthetiseerde stem Engels spreekt met hetzelfde accent als de voorbeeldgegevens, raden we u aan meer dan 10% Engelse gegevens op te nemen in uw trainingsset. Anders is het Engels sprekende accent mogelijk niet ideaal. |
Chinese (Cantonese, Simplified) |
zh-HK |
Als u een gesynthetiseerde stem wilt trainen die Engels kan spreken met hetzelfde accent als uw voorbeeldgegevens, moet u ervoor zorgen dat u meer dan 10% Engelse gegevens in uw trainingsset opgeeft. Anders wordt het standaard ingesteld op een Engels native accent. De drempelwaarde van 10% wordt berekend op basis van de gegevens die zijn geaccepteerd na het uploaden, niet de gegevens vóór het uploaden. Als sommige geüploade Engelse gegevens worden geweigerd vanwege defecten en niet voldoen aan de drempelwaarde van 10%, wordt de gesynthetiseerde stem standaard ingesteld op een Engels native accent. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Als u een gesynthetiseerde stem wilt trainen die Engels kan spreken met hetzelfde accent als uw voorbeeldgegevens, moet u ervoor zorgen dat u meer dan 10% Engelse gegevens in uw trainingsset opgeeft. Anders wordt het standaard ingesteld op een Engels native accent. De drempelwaarde van 10% wordt berekend op basis van de gegevens die zijn geaccepteerd na het uploaden, niet de gegevens vóór het uploaden. Als sommige geüploade Engelse gegevens worden geweigerd vanwege defecten en niet voldoen aan de drempelwaarde van 10%, wordt de gesynthetiseerde stem standaard ingesteld op een Engels native accent. |
Beschikbare vooraf ingestelde stijlen in verschillende talen
De volgende tabel bevat een overzicht van de verschillende vooraf ingestelde stijlen op basis van verschillende talen.
| Spreekstijl | Taal (landinstelling) |
|---|---|
| boos | Engels (Verenigde Staten) (en-US)Japans (Japan) ( ja-JP) 1Chinees (Mandarijn, Vereenvoudigd) ( zh-CN) 1 |
| kalm | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| chat | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| vrolijk | Engels (Verenigde Staten) (en-US)Japans (Japan) ( ja-JP) 1Chinees (Mandarijn, Vereenvoudigd) ( zh-CN) 1 |
| ontevreden | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| opgewonden | Engels (Verenigde Staten) (en-US) |
| angstig | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| vriendelijk | Engels (Verenigde Staten) (en-US) |
| hoopvol | Engels (Verenigde Staten) (en-US) |
| treurig | Engels (Verenigde Staten) (en-US)Japans (Japan) ( ja-JP) 1Chinees (Mandarijn, Vereenvoudigd) ( zh-CN) 1 |
| geschreeuw | Engels (Verenigde Staten) (en-US) |
| ernstig | Chinees (Mandarijn, Vereenvoudigd) (zh-CN) 1 |
| Doodsbang | Engels (Verenigde Staten) (en-US) |
| onvriendelijk | Engels (Verenigde Staten) (en-US) |
| Whispering | Engels (Verenigde Staten) (en-US) |
1 De neurale stemstijl is beschikbaar in openbare preview. Stijlen in openbare preview zijn alleen beschikbaar in deze serviceregio's: VS - oost, Europa - west en Azië - zuidoost.
Trainingsstatus ophalen
Als u de trainingsstatus van een spraakmodel wilt ophalen, gebruikt u de Models_Get bewerking van de aangepaste spraak-API. Bouw de aanvraag-URI volgens de volgende instructies:
Maak een HTTP GET-aanvraag met behulp van de URI, zoals wordt weergegeven in het volgende Models_Get voorbeeld.
- Vervang door
YourResourceKeyuw Spraak-resourcesleutel. - Vervang door
YourResourceRegionuw spraakresourceregio. - Vervang
JessicaModelIdals u in de vorige stap een andere model-id hebt opgegeven.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
U ontvangt een antwoordtekst in de volgende indeling.
Notitie
Het recept kind en andere eigenschappen zijn afhankelijk van hoe u de stem hebt getraind. In dit voorbeeld is Default het recepttype bedoeld voor neurale spraaktraining.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Mogelijk moet u enkele minuten wachten voordat de training is voltooid. Uiteindelijk verandert de status in Succeeded of Failed.