Antipatroon Bezette database
Het offloaden van verwerkingstaken naar een databaseserver kan tot gevolg hebben dat deze een aanzienlijk deel van de tijd bezig is met het uitvoeren van code in plaats van het reageren op aanvragen voor het opslaan en ophalen van gegevens.
Beschrijving van het probleem
Veel databasesystemen kunnen code uitvoeren. Voorbeelden zijn opgeslagen procedures en triggers. Vaak is het efficiënter om deze verwerkingen dicht bij de gegevens uit te voeren in plaats van de gegevens voor verwerking naar een clienttoepassing te versturen. Als dit echter te veel gebeurt, kan dit om verschillende redenen nadelig zijn voor de prestaties:
- De databaseserver besteedt te veel tijd aan verwerkingstaken in plaats van nieuwe aanvragen van clients te accepteren en gegevens op te halen.
- Een database is meestal een gedeelde resource en kan dus een bottleneck worden tijdens perioden van intensief gebruik.
- De runtime-kosten kunnen zeer hoog worden als voor het gegevensarchief een datalimiet geldt. Die geldt met name voor beheerde databaseservices. Zo worden in Azure SQL Database kosten in rekening gebracht voor Database Transaction Units (DTU's).
- Databases hebben een eindige capaciteit voor wat betreft omhoog schalen en het is geen pretje om een database horizontaal te schalen. Daarom kan het zijn beter om de verwerking te verplaatsen naar een rekenresource, zoals een VM of een App Service-app, die eenvoudig kan worden uitgeschaald.
Enkele veelvoorkomende oorzaken voor dit antipatroon:
- De database wordt beschouwd als een service in plaats van een opslagplaats. Een toepassing kan de databaseserver gebruiken voor het opmaken van gegevens (bijvoorbeeld converteren naar XML), het manipuleren van tekenreeksgegevens of het uitvoeren van complexe berekeningen.
- Ontwikkelaars proberen query's te schrijven waarvan de resultaten rechtstreeks aan gebruikers kunnen worden weergegeven. In een query kunnen bijvoorbeeld velden worden gecombineerd of kunnen datums, tijden en valuta worden opgemaakt volgens de landinstelling.
- Ontwikkelaars proberen om het antipatroon Overbodige ophaalbewerking op te lossen door berekeningen naar de database te pushen.
- Opgeslagen procedures worden gebruikt voor het inkapselen van bedrijfslogica, misschien omdat ze, althans gevoelsmatig, gemakkelijker zijn te onderhouden en bij te werken.
In het volgende voorbeeld worden de twintig waardevolste orders voor een opgegeven verkoopgebied opgehaald en worden de resultaten opgemaakt als XML. Met behulp van Transact-SQL-functies worden de gegevens geparseerd en worden de resultaten geconverteerd naar XML. U vindt het complete voorbeeld hier.
SELECT TOP 20
soh.[SalesOrderNumber] AS '@OrderNumber',
soh.[Status] AS '@Status',
soh.[ShipDate] AS '@ShipDate',
YEAR(soh.[OrderDate]) AS '@OrderDateYear',
MONTH(soh.[OrderDate]) AS '@OrderDateMonth',
soh.[DueDate] AS '@DueDate',
FORMAT(ROUND(soh.[SubTotal],2),'C')
AS '@SubTotal',
FORMAT(ROUND(soh.[TaxAmt],2),'C')
AS '@TaxAmt',
FORMAT(ROUND(soh.[TotalDue],2),'C')
AS '@TotalDue',
CASE WHEN soh.[TotalDue] > 5000 THEN 'Y' ELSE 'N' END
AS '@ReviewRequired',
(
SELECT
c.[AccountNumber] AS '@AccountNumber',
UPPER(LTRIM(RTRIM(REPLACE(
CONCAT( p.[Title], ' ', p.[FirstName], ' ', p.[MiddleName], ' ', p.[LastName], ' ', p.[Suffix]),
' ', ' ')))) AS '@FullName'
FROM [Sales].[Customer] c
INNER JOIN [Person].[Person] p
ON c.[PersonID] = p.[BusinessEntityID]
WHERE c.[CustomerID] = soh.[CustomerID]
FOR XML PATH ('Customer'), TYPE
),
(
SELECT
sod.[OrderQty] AS '@Quantity',
FORMAT(sod.[UnitPrice],'C')
AS '@UnitPrice',
FORMAT(ROUND(sod.[LineTotal],2),'C')
AS '@LineTotal',
sod.[ProductID] AS '@ProductId',
CASE WHEN (sod.[ProductID] >= 710) AND (sod.[ProductID] <= 720) AND (sod.[OrderQty] >= 5) THEN 'Y' ELSE 'N' END
AS '@InventoryCheckRequired'
FROM [Sales].[SalesOrderDetail] sod
WHERE sod.[SalesOrderID] = soh.[SalesOrderID]
ORDER BY sod.[SalesOrderDetailID]
FOR XML PATH ('LineItem'), TYPE, ROOT('OrderLineItems')
)
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC
FOR XML PATH ('Order'), ROOT('Orders')
Het moge duidelijk zijn dat dit een complexe query is. Zoals we later zullen zien, zijn voor de query nogal wat verwerkingsresources nodig op de databaseserver.
Het probleem oplossen
Verplaats verwerkingstaken van de databaseserver naar andere toepassingslagen. In het ideale geval moet u de database beperken tot het uitvoeren van bewerkingen voor gegevenstoegang, met behulp van alleen de mogelijkheden waarvoor de database is geoptimaliseerd, zoals aggregatie in een RDBMS.
Zo kan de bovenstaande Transact-SQL-code worden vervangen door een instructie waarmee de gegevens worden opgehaald die moeten worden verwerkt.
SELECT
soh.[SalesOrderNumber] AS [OrderNumber],
soh.[Status] AS [Status],
soh.[OrderDate] AS [OrderDate],
soh.[DueDate] AS [DueDate],
soh.[ShipDate] AS [ShipDate],
soh.[SubTotal] AS [SubTotal],
soh.[TaxAmt] AS [TaxAmt],
soh.[TotalDue] AS [TotalDue],
c.[AccountNumber] AS [AccountNumber],
p.[Title] AS [CustomerTitle],
p.[FirstName] AS [CustomerFirstName],
p.[MiddleName] AS [CustomerMiddleName],
p.[LastName] AS [CustomerLastName],
p.[Suffix] AS [CustomerSuffix],
sod.[OrderQty] AS [Quantity],
sod.[UnitPrice] AS [UnitPrice],
sod.[LineTotal] AS [LineTotal],
sod.[ProductID] AS [ProductId]
FROM [Sales].[SalesOrderHeader] soh
INNER JOIN [Sales].[Customer] c ON soh.[CustomerID] = c.[CustomerID]
INNER JOIN [Person].[Person] p ON c.[PersonID] = p.[BusinessEntityID]
INNER JOIN [Sales].[SalesOrderDetail] sod ON soh.[SalesOrderID] = sod.[SalesOrderID]
WHERE soh.[TerritoryId] = @TerritoryId
AND soh.[SalesOrderId] IN (
SELECT TOP 20 SalesOrderId
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC)
ORDER BY soh.[TotalDue] DESC, sod.[SalesOrderDetailID]
De toepassing gebruikt vervolgens System.Xml.Linq-API's van .NET Framework om de resultaten op te maken als XML.
// Create a new SqlCommand to run the Transact-SQL query
using (var command = new SqlCommand(...))
{
command.Parameters.AddWithValue("@TerritoryId", id);
// Run the query and create the initial XML document
using (var reader = await command.ExecuteReaderAsync())
{
var lastOrderNumber = string.Empty;
var doc = new XDocument();
var orders = new XElement("Orders");
doc.Add(orders);
XElement lineItems = null;
// Fetch each row in turn, format the results as XML, and add them to the XML document
while (await reader.ReadAsync())
{
var orderNumber = reader["OrderNumber"].ToString();
if (orderNumber != lastOrderNumber)
{
lastOrderNumber = orderNumber;
var order = new XElement("Order");
orders.Add(order);
var customer = new XElement("Customer");
lineItems = new XElement("OrderLineItems");
order.Add(customer, lineItems);
var orderDate = (DateTime)reader["OrderDate"];
var totalDue = (Decimal)reader["TotalDue"];
var reviewRequired = totalDue > 5000 ? 'Y' : 'N';
order.Add(
new XAttribute("OrderNumber", orderNumber),
new XAttribute("Status", reader["Status"]),
new XAttribute("ShipDate", reader["ShipDate"]),
... // More attributes, not shown.
var fullName = string.Join(" ",
reader["CustomerTitle"],
reader["CustomerFirstName"],
reader["CustomerMiddleName"],
reader["CustomerLastName"],
reader["CustomerSuffix"]
)
.Replace(" ", " ") //remove double spaces
.Trim()
.ToUpper();
customer.Add(
new XAttribute("AccountNumber", reader["AccountNumber"]),
new XAttribute("FullName", fullName));
}
var productId = (int)reader["ProductID"];
var quantity = (short)reader["Quantity"];
var inventoryCheckRequired = (productId >= 710 && productId <= 720 && quantity >= 5) ? 'Y' : 'N';
lineItems.Add(
new XElement("LineItem",
new XAttribute("Quantity", quantity),
new XAttribute("UnitPrice", ((Decimal)reader["UnitPrice"]).ToString("C")),
new XAttribute("LineTotal", RoundAndFormat(reader["LineTotal"])),
new XAttribute("ProductId", productId),
new XAttribute("InventoryCheckRequired", inventoryCheckRequired)
));
}
// Match the exact formatting of the XML returned from SQL
var xml = doc
.ToString(SaveOptions.DisableFormatting)
.Replace(" />", "/>");
}
}
Notitie
Deze code is redelijk complex. Voor een nieuwe toepassing gebruikt u misschien liever een serialisatiebibliotheek. De veronderstelling hier is echter dat het ontwikkelingsteam een bestaande toepassing aanpast, wat betekent dat de methode exact dezelfde indeling moet retourneren als de oorspronkelijke code.
Overwegingen
Veel databasesystemen zijn sterk geoptimaliseerd voor het uitvoeren van bepaalde typen gegevensverwerking, zoals het berekenen van cumulatieve waarden voor grote gegevenssets. Houd deze typen verwerking binnen de database.
Het heeft geen zin om verwerkingstaken te verplaatsen als de database hierdoor nog veel meer gegevens moet overdragen via het netwerk. Zie voor meer informatie het antipatroon Ophalen van overbodige gegevens.
Als u verwerkingstaken overbrengt naar een toepassingslaag, moet die laag mogelijk worden uitgeschaald om het extra werk af te handelen.
Het probleem vaststellen
Symptomen van een bezette database zijn een onevenredige daling van de doorvoer en reactietijd van bewerkingen die de database raadplegen.
U kunt de volgende stappen uitvoeren om dit probleem te identificeren:
Gebruik tools voor prestatiebewaking om vast te stellen hoe lang het productiesysteem bezig is met het uitvoeren van databaseactiviteiten.
Bekijk de taken die tijdens deze perioden door de database worden uitgevoerd.
Als u vermoedt dat bepaalde bewerkingen te veel databaseactiviteiten veroorzaken, voert u een belastingstest uit in een testomgeving. Elke test moet een combinatie zijn van verdachte activiteiten met een wisselende gebruikersbelasting. Bekijk de telemetrie van de belastingstests om te zien hoe de database wordt gebruikt.
Als de databaseactiviteit flink wat verwerkingstaken vertegenwoordigt maar weinig verkeer, bekijkt u de broncode om te bepalen of de verwerking beter ergens anders kan plaatsvinden.
Als de hoeveelheid databaseactiviteit laag is of de reactietijden relatief snel zijn, wordt het prestatieprobleem waarschijnlijk niet veroorzaakt door een overbezette database.
Voorbeeld van diagnose
In de volgende secties worden deze stappen toegepast op de voorbeeldtoepassing die eerder is beschreven.
De hoeveelheid activiteit in een database bewaken
Het volgende diagram toont de resultaten van het uitvoeren van een belastingstest op de voorbeeldtoepassing, met een belasting die stapsgewijs wordt opgevoerd tot maximaal 50 gelijktijdige gebruikers. Het aantal aanvragen heeft snel een hoogste waarde bereikt en blijft stabiel op dat niveau, terwijl de gemiddelde reactietijd steeds verder oploopt. Er wordt een logaritmische schaal gebruikt voor deze twee parameters.
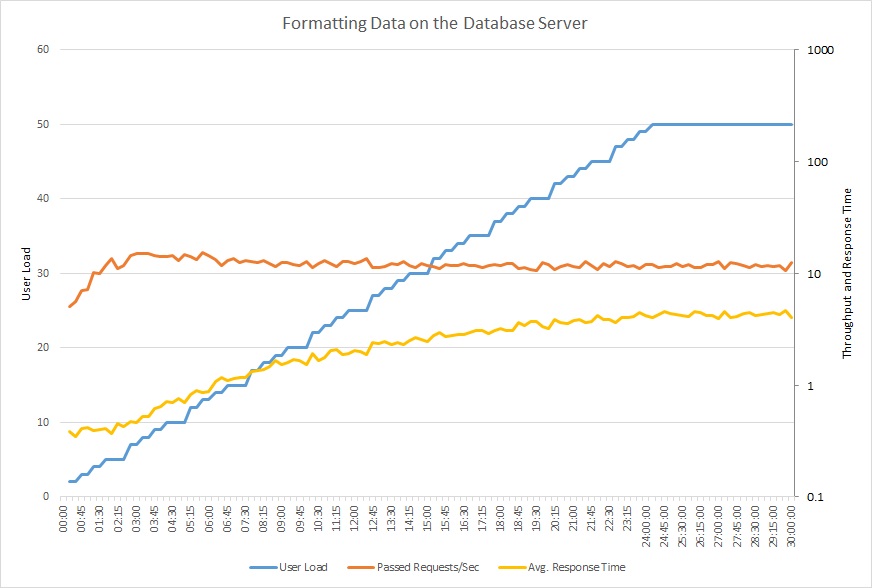
Dit lijndiagram toont de gebruikersbelasting, het aantal aanvragen per seconde en de gemiddelde reactietijd. Het diagram laat zien dat de reactietijd toeneemt naarmate de belasting toeneemt.
Het volgende diagram toont het CPU-gebruik en het aantal DTU's als een percentage van het servicequotum. DTU's geven een beeld van de verwerking die door de database wordt uitgevoerd. Het diagram laat zien dat zowel het CPU-gebruik als het DTU-gebruik snel de 100% heeft bereikt.
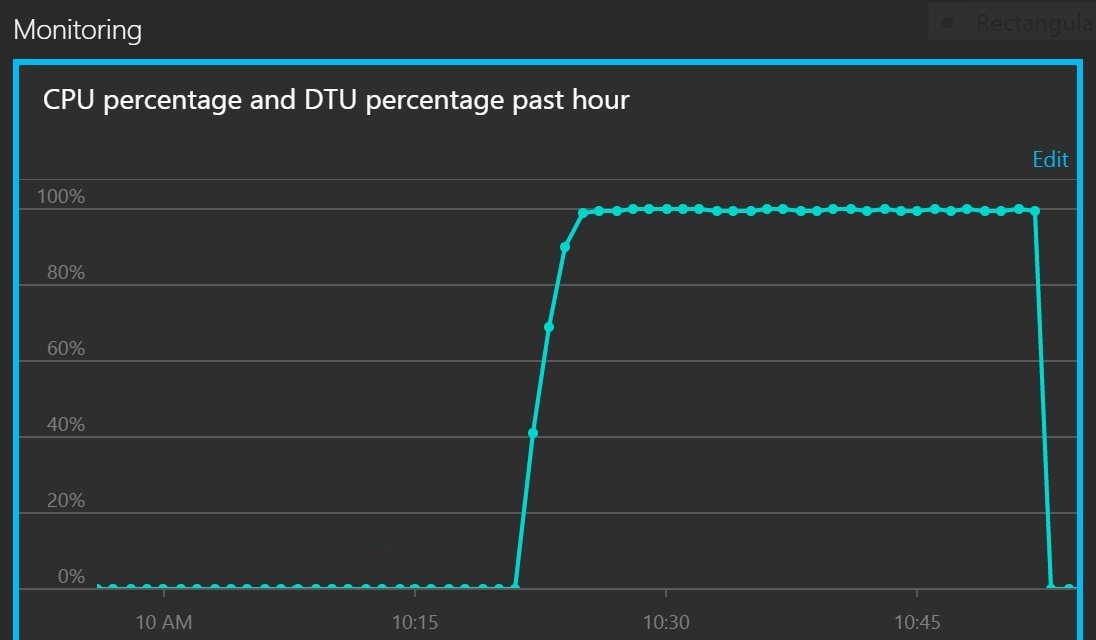
Dit lijndiagram toont het CPU-percentage en het DTU-percentage naar verloop van tijd. In het diagram ziet u dat beide snel de 100% bereiken.
Taken bekijken die door de database zijn uitgevoerd
Het kan zijn dat de taken die worden uitgevoerd door de database daadwerkelijk bewerkingen voor gegevenstoegang zijn in plaats van verwerkingstaken. Om die reden is het belangrijk om de SQL-instructies te begrijpen die worden uitgevoerd terwijl de database bezet is. Monitor het systeem om het SQL-verkeer vast te leggen en de SQL-bewerkingen te koppelen aan toepassingsaanvragen.
Als de databasebewerkingen uitsluitend betrekking hebben op gegevenstoegang, zonder een grote hoeveelheid verwerking, kan het probleem worden veroorzaakt door het antipatroon Ophalen van overbodige gegevens.
De oplossing implementeren en het resultaat controleren
In het volgende diagram ziet u een belastingstest met de bijgewerkte code. De doorvoer is aanzienlijk hoger, met meer dan 400-aanvragen per seconde tegenover 12 daarvoor. De gemiddelde reactietijd is ook veel lager, namelijk iets meer dan 0,1 seconde vergeleken met meer dan 4 seconden.
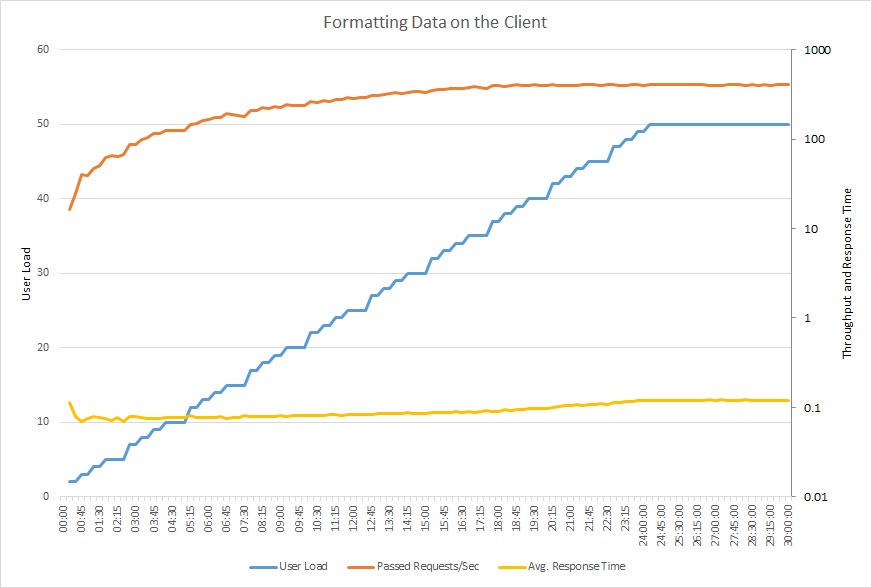
Dit lijndiagram toont de gebruikersbelasting, het aantal aanvragen per seconde en de gemiddelde reactietijd. Het diagram laat zien dat de reactietijd vrijwel constant blijft gedurende de hele belastingtest.
Het CPU- en DTU-verbruik laat zien dat langer heeft geduurd voordat het systeem was verzadigd, ondanks de verbeterde doorvoer.
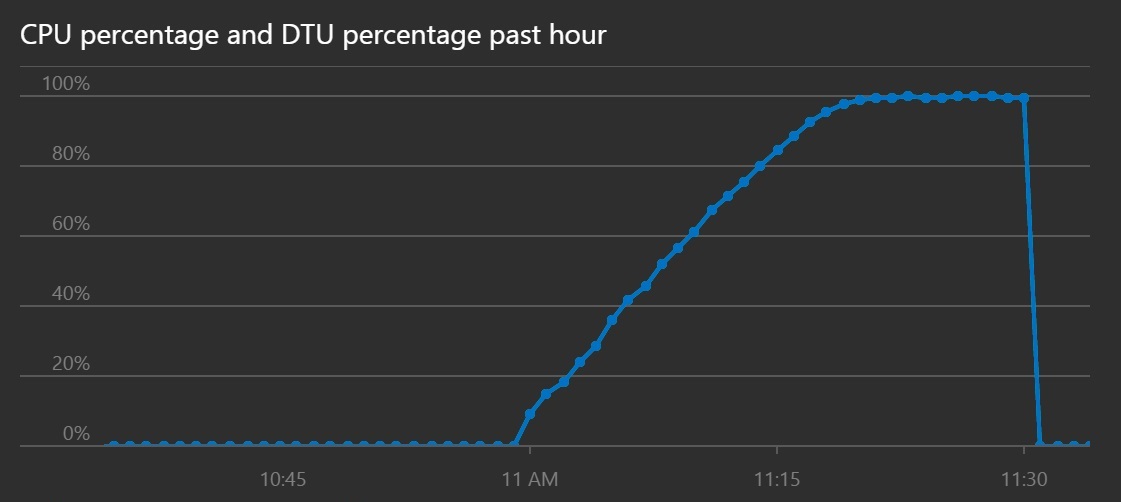
Dit lijndiagram toont het CPU-percentage en het DTU-percentage naar verloop van tijd. In het diagram ziet u dat het CPU- en DTU-percentage pas later de 100% bereiken.
Verwante resources
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor