Antipatroon Ophalen van overbodige gegevens
Antipatronen zijn veelvoorkomende ontwerpfouten die uw software of toepassingen onder stresssituaties kunnen breken en die niet over het hoofd mogen worden gezien. In een overbodig ophalen antipatroon worden meer dan de benodigde gegevens opgehaald voor een bedrijfsbewerking, wat vaak resulteert in onnodige I/O-overhead en verminderde reactiesnelheid.
Voorbeelden van overbodig ophalen van antipatroon
Dit antipatroon kan zich voordoen als de toepassing probeert om I/O-aanvragen te minimaliseren door alle gegevens op te halen die mogelijk nodig zijn. Dit is vaak een resultaat van overcompensatie voor het antipatroon Drukke I/O. Een toepassing kan bijvoorbeeld de details voor elk product in een database ophalen. Maar de gebruiker heeft mogelijk slechts een subset van de details nodig (sommige zijn mogelijk niet relevant voor klanten), en hij hoeft waarschijnlijk niet alle producten in één keer t zien. Zelfs als de gebruiker door de hele catalogus bladert, zou het zinvol zijn om de resultaten te pagineren, bijvoorbeeld 20 tegelijk.
Een andere oorzaak van dit probleem is het volgen van slechte programmeer- of ontwerpprocedures. De volgende code gebruikt bijvoorbeeld Entity Framework voor het ophalen van alle details voor elk product. Vervolgens worden de resultaten gefilterd en wordt alleen een subset van de velden geretourneerd. De rest wordt genegeerd. U vindt het complete voorbeeld hier.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
In het volgende voorbeeld haalt de applicatie gegevens op om een aggregatie uit te voeren die ook door de database kan worden gedaan. De toepassing berekent de totale verkoop door elke record voor alle verkochte orders op te halen en vervolgens de som van deze records te berekenen. U vindt het complete voorbeeld hier.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
In het volgende voorbeeld ziet u een subtiel probleem dat wordt veroorzaakt door de manier waarop Entity Framework LINQ to Entities gebruikt.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
De toepassing probeert producten te vinden met een SellStartDate van meer dan een week oud. In de meeste gevallen vertaalt LINQ to Entities een where-component naar een SQL-instructie die wordt uitgevoerd door de database. In dit geval kan LINQ to Entities de AddDays-methode echter niet toewijzen aan SQL. In plaats daarvan wordt elke rij van de Product-tabel geretourneerd en de resultaten worden gefilterd in het geheugen.
De aanroep van AsEnumerable is een aanwijzing dat er een probleem is. Deze methode zet de resultaten om naar een IEnumerable-interface. Hoewel IEnumerable filteren ondersteunt, wordt het filteren uitgevoerd aan de clientzijde, niet via de database. LINQ to Entities gebruikt standaard IQueryable, waarmee de verantwoordelijkheid voor het filteren aan de gegevensbron wordt doorgegeven.
Antipatroon voor ophalen van overbodige gegevens oplossen
Voorkom dat grote hoeveelheden gegevens worden opgehaald die mogelijk al snel verouderd zijn of kunnen worden verwijderd, en haal alleen de gegevens op die nodig zijn voor de bewerking die wordt uitgevoerd.
Haal niet elke kolom op uit een tabel om deze vervolgens te filteren, maar selecteer de kolommen die u nodig hebt uit de database.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
Voer daarnaast aggregatiebewerkingen uit in de database en niet in het geheugen van de toepassing.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Wanneer u Entity Framework gebruikt, moet u ervoor zorgen dat LINQ-query's worden omgezet met behulp van de IQueryable interface en niet IEnumerable. Mogelijk moet u de query aanpassen zodat alleen functies worden gebruikt die kunnen worden toegewezen aan de gegevensbron. Het vorige voorbeeld kan worden geherstructureerd om de AddDays methode t verwijderen uit de query, zodat het filteren kan worden uitgevoerd door de database.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Overwegingen
In sommige gevallen kunt u de prestaties verbeteren door gegevens horizontaal te partitioneren. Als verschillende bewerkingen verschillende kenmerken van de gegevens gebruiken, kan horizontaal partitioneren het aantal conflicten verminderen. De meeste bewerkingen worden vaak uitgevoerd tegen een kleine subset van de gegevens, dus het spreiden van deze belasting kan de prestaties verbeteren. Zie Gegevenspartitionering.
Voor bewerkingen die niet-gebonden query’s moeten ondersteunen, moet u paginering implementeren en slechts een beperkt aantal entiteiten tegelijk ophalen. Als een klant bijvoorbeeld door een productcatalogus bladert, kunt u één pagina met resultaten tegelijk weergeven.
Maak, indien mogelijk, gebruik van de functies die zijn ingebouwd in het gegevensarchief. SQL-databases bevatten doorgaans bijvoorbeeld statistische functies.
Als u een gegevensarchief gebruikt dat geen ondersteuning biedt voor een bepaalde functie, zoals aggregratie, kunt u het berekende resultaat ook elders opslaan en de waarde bijwerken wanneer records worden toegevoegd of bijgewerkt. Zo hoeft de toepassing de waarde niet telkens opnieuw te berekenen wanneer deze nodig is.
Als u ziet dat aanvragen een groot aantal velden ophalen, controleert u de broncode om te bepalen of al deze velden daadwerkelijk nodig zijn. Soms zijn deze aanvragen het resultaat van een slecht ontworpen
SELECT *-query.Aanvragen die een groot aantal entiteiten ophalen, zijn mogelijk op dezelfde manier een teken dat de toepassing gegevens correct filtert. Controleer of alle entiteiten nodig zijn. Gebruik waar mogelijk filtering via de database, bijvoorbeeld met behulp van
WHERE-componenten in SQL.Het offloaden van de verwerking naar de database is niet altijd de beste optie. Gebruik deze strategie alleen wanneer de database is ontworpen of geoptimaliseerd om dit te doen. De meeste databasesystemen zijn geoptimaliseerd voor bepaalde functies, maar zijn niet ontworpen om te fungeren als een algemene toepassingsengine. Zie voor meer informatie het Antipatroon bezette database.
Antipatroon voor ophalen van overbodige gegevens detecteren
Symptomen van overbodige ophaalbewerkingen zijn hoge latentie en lage doorvoer. Als de gegevens worden opgehaald uit een gegevensarchief, neemt het aantal conflicten waarschijnlijk ook toe. Eindgebruikers melden waarschijnlijk uitgebreide reactietijden of fouten die worden veroorzaakt door time-outs van services. Deze fouten kunnen HTTP 500-fouten (interne server) of HTTP 503-fouten (service niet beschikbaar) retourneren. Raadpleeg de gebeurtenislogboeken van de webserver, die waarschijnlijk meer gedetailleerde informatie over de oorzaken en omstandigheden van de fouten bevatten.
De symptomen van dit antipatroon en een deel van de telemetrie die is verkregen, is mogelijk vergelijkbaar met die van het Antipatroon monolithische persistentie.
U kunt de volgende stappen uitvoeren om het probleem te identificeren:
- Identificeer trage werkbelastingen of transacties identificeren door de belasting te testen, processen te bewaken of andere methoden te gebruiken voor het vastleggen van gegevens.
- Onderzoek eventuele gedragspatronen van het systeem. Zijn er bepaalde limieten wat betreft het aantal transacties per seconde of een aantal gebruikers?
- Correleer de exemplaren van trage werkbelastingen met gedragspatronen.
- Identificeer de gegevensarchieven die worden gebruikt. Voer voor elke gegevensbron telemetrie van een lager niveau uit om het gedrag van bewerkingen te kunnen observeren.
- Identificeer trage query's die verwijzen naar deze gegevensbronnen.
- Voer een resource-specifieke analyse uit van de trage query's en ga na hoe de gegevens worden gebruikt en verbruikt.
Kijk of er sprake is van deze symptomen:
- Regelmatige, grote I/O-aanvragen voor dezelfde bron of hetzelfde gegevensarchief.
- Conflicten in een gedeelde bron of het gegevensarchief.
- Een bewerking die regelmatig grote hoeveelheden gegevens via het netwerk ontvangt.
- Toepassingen en services met een aanzienlijke wachttijd voordat I/O-bewerkingen worden voltooid.
Voorbeeld van diagnose
In de volgende secties worden deze stappen op bovenstaande voorbeelden toegepast.
Identificeer trage werkbelastingen
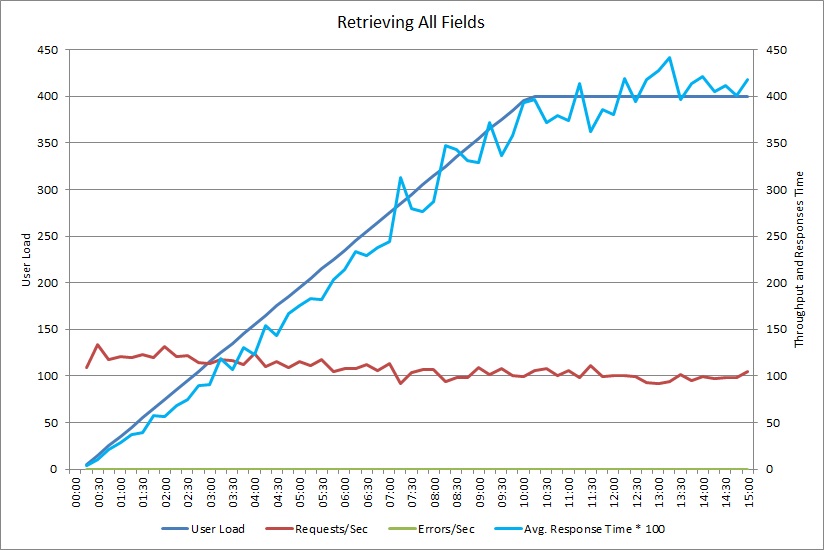
Deze grafiek toont de prestatieresultaten van een belastingtest die maximaal 400 gelijktijdige gebruikers met de eerder weergegeven GetAllFieldsAsync-methode heeft gesimuleerd. De doorvoer vermindert langzaam wanneer de belasting toeneemt. Gemiddelde reactietijd neemt toe als de werkbelasting toeneemt.
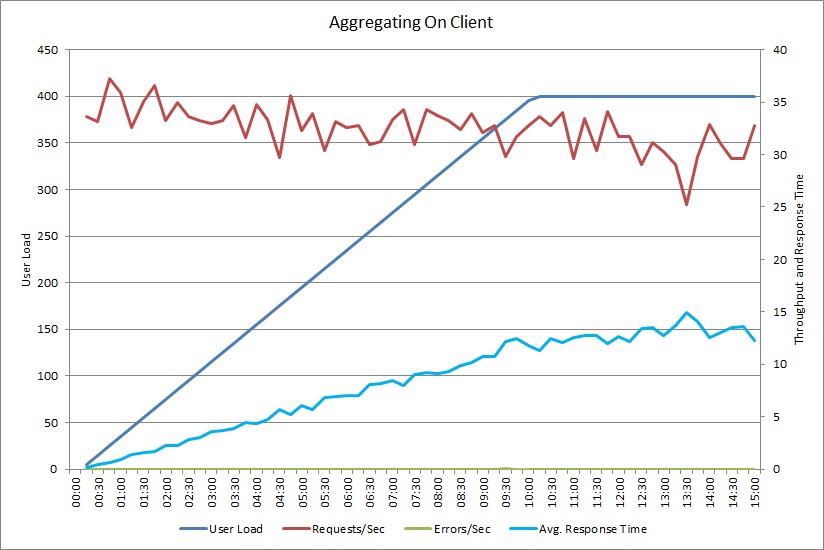
Een belastingtest voor de AggregateOnClientAsync-bewerking resulteert in een vergelijkbaar patroon. Het aantal aanvragen is redelijk stabiel. De gemiddelde reactietijd neemt toe naarmate de werkbelasting stijgt, maar wel langzamer dan in de vorige grafiek.
Correleer trage werkbelastingen met gedragspatronen
Een correlatie tussen reguliere perioden met een hoog gebruik en vertraagde prestaties kan wijzen op een probleemgebied. Onderzoek het prestatieprofiel van de functionaliteit die vermoedelijk traag is om te bepalen of dit overeenkomt met de belastingtests die u eerder hebt uitgevoerd.
Voer een belastingtest uit op dezelfde functie met behulp van stapgebaseerde gebruiksbelastingen om het punt te vinden waarop de prestaties aanzienlijk verminderen of volledig mislukken. Als dat punt binnen de grenzen van het verwachte daadwerkelijke gebruik valt, controleert u hoe de functie wordt geïmplementeerd.
Een trage bewerking is niet noodzakelijkerwijs een probleem, als deze niet wordt uitgevoerd wanneer het systeem zwaar wordt belast, niet tijdkritisch is en geen negatieve invloed heeft op de prestaties van andere belangrijke bewerkingen. Het genereren van maandelijkse operationele statistische gegevens is mogelijk tijdrovend, maar deze bewerking kan waarschijnlijk worden uitgevoerd als een batchproces en als een taak met lage prioriteit. Wanneer klanten query’s sturen naar de productcatalogus, gaat het echter om een kritieke zakelijke bewerking. Richt u op de telemetrie die is gegenereerd door deze kritieke bewerkingen om te zien hoe de prestaties variëren tijdens perioden met een hoog gebruik.
Identificeer gegevensbronnen in trage werkbelastingen
Als u vermoedt dat een service slecht presteert vanwege de manier waarop deze gegevens ophaalt, moet u onderzoeken hoe de toepassing communiceert met de opslagplaatsen die de service gebruikt. Bewaat het live systeem om te zien welke bronnen worden geopend wanneer de prestaties tegenvallen.
Voor elke gegevensbron moet u het systeem opdragen om het volgende vast te leggen:
- De frequentie waarmee elk gegevensarchief wordt geopend.
- De hoeveelheid inkomende en uitgaande gegevens in het gegevensarchief.
- De duur van deze bewerkingen, met name de latentie van aanvragen.
- De aard en de frequentie van fouten die optreden bij het openen van elk gegevensarchief bij normale belasting.
Vergelijk deze informatie met tot de hoeveelheid gegevens die wordt geretourneerd door de toepassing naar de client. Houd de verhouding bij van de hoeveelheid gegevens die door het gegevensarchief worden geretourneerd en de hoeveelheid gegevens die worden geretourneerd naar de client. Als er geen grote verschillen zijn, moet u onderzoeken of de toepassing meer gegevens ophaalt dan nodig is.
U kunt deze gegevens mogelijk vastleggen door het live systeem te observeren en de levenscyclus van elke gebruikersaanvraag bij te houden. U kunt ook een reeks synthetische werkbelastingen modelleren en deze uitvoeren in een testsysteem.
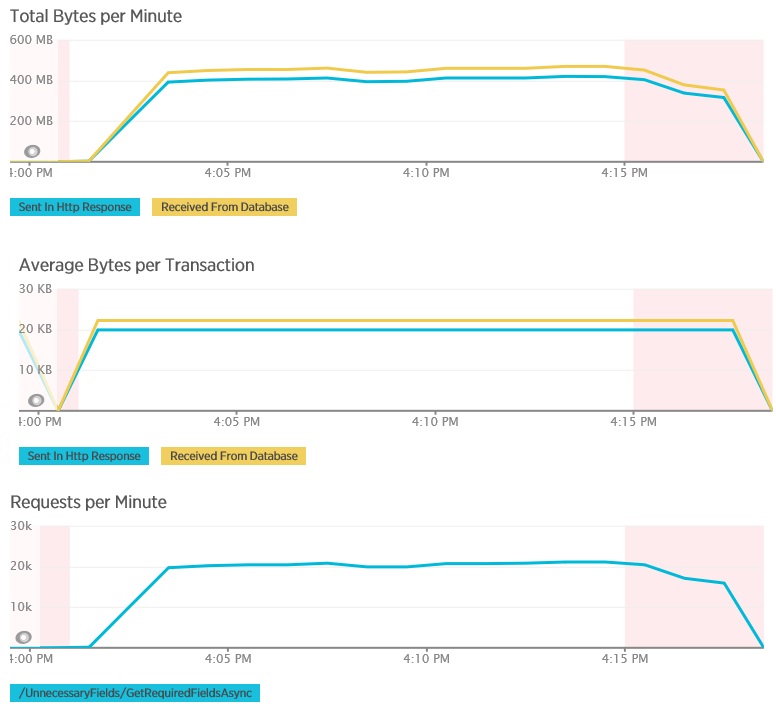
In de volgende grafieken ziet u de telemetrie die is vastgelegd met behulp van New Relic APM tijdens een belastingtest van de GetAllFieldsAsync-methode. Let op het verschil tussen de hoeveelheid ontvangen gegevens uit de database en de bijbehorende HTTP-antwoorden.
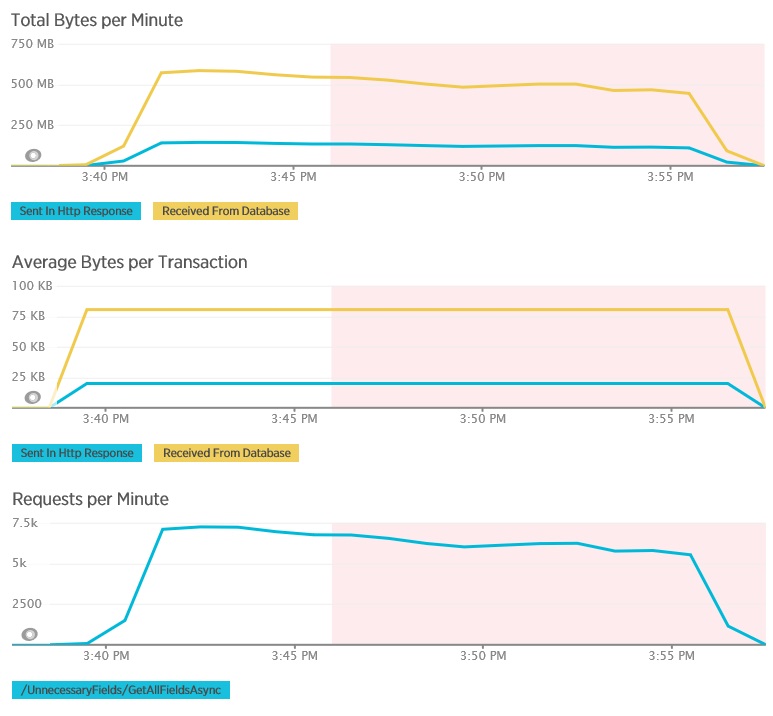
De database heeft 80.503 bytes geretourneerd voor elke aanvraag, maar het antwoord aan de client bevat slechts 19.855 bytes, ongeveer 25% van de reactie van de database. Het aantal gegevens dat wordt geretourneerd naar de client kan variëren afhankelijk van de indeling. In deze belastingtest heeft de client JSON-gegevens aangevraagd. Een afzonderlijke test met behulp van XML (niet weergegeven) resulteerde in een antwoord van 35.655, wat neerkomt op 44% van het antwoord van de database.
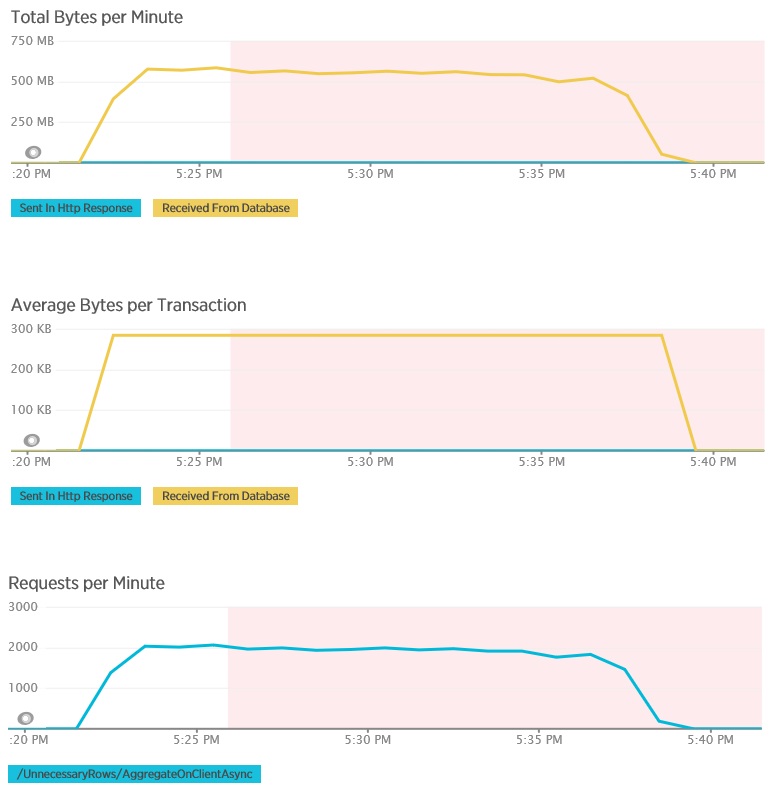
De belastingtest voor de AggregateOnClientAsync-methode geeft extremere resultaten. In dit geval voerde elke test een query uit die meer dan 280 Kb aan gegevens uit de database ophaalde, maar het JSON-antwoord bevatte slechts 14 bytes. Het verschil ontstaat omdat de methode een samengevoegd resultaat berekent op basis van een grote hoeveelheid gegevens.
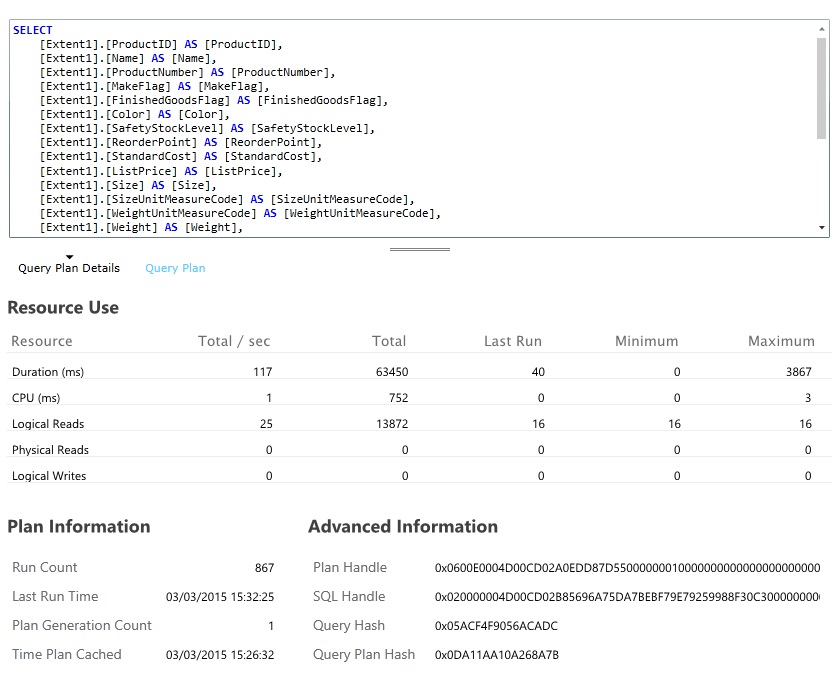
Identificeer en analyseer trage query 's
Zoek de database-query's die de meeste bronnen verbruiken en de meeste tijd kosten bij het uitvoeren. U kunt instrumentatie toevoegen om de begin- en eindtijden voor veel databasebewerkingen te vinden. Veel gegevensarchieven bevatten ook gedetailleerde informatie over hoe query's worden uitgevoerd en geoptimaliseerd. In het deelvenster Query-prestaties in de beheerportal van Azure SQL Database kunt u een query selecteren en gedetailleerde gegevens over de runtimeprestaties weergeven. Dit is de query die is gegenereerd door de GetAllFieldsAsync-bewerking:
De oplossing implementeren en het resultaat controleren
Na het wijzigen van de GetRequiredFieldsAsync-methode om een SELECT-instructie te gebruiken in de database, gaf de belastingtest de volgende resultaten.
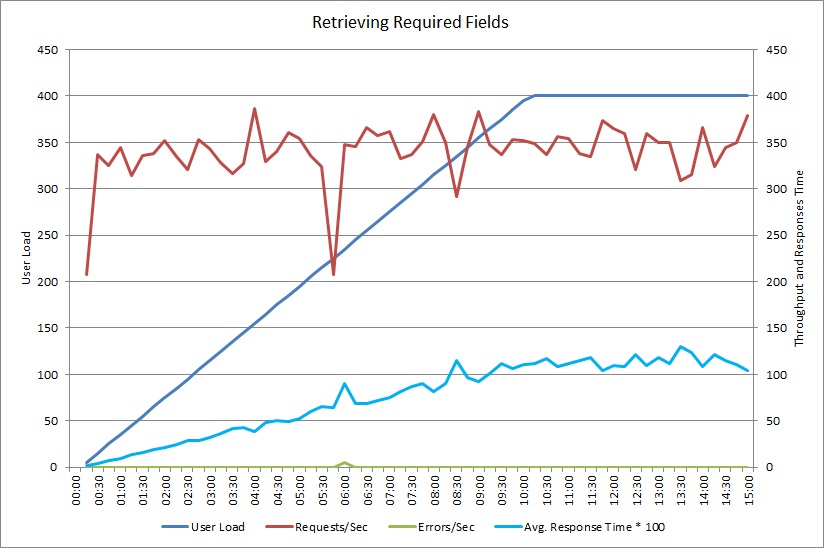
Deze belastingtest gebruikt dezelfde implementatie en dezelfde gesimuleerde werkbelasting van 400 gelijktijdige gebruikers als de vorige test. De grafiek toont een veel lagere latentie. De reactietijd stijgt samen met de belasting tot ongeveer 1,3 seconden, vergeleken met 4 seconden in het vorige geval. De doorvoer is ook hoger: 350 aanvragen per seconde in plaats van 100, zoals we eerder zagen. De hoeveelheid gegevens die is opgehaald uit de database komt nu nauw overeen met de grootte van de HTTP-antwoordberichten.
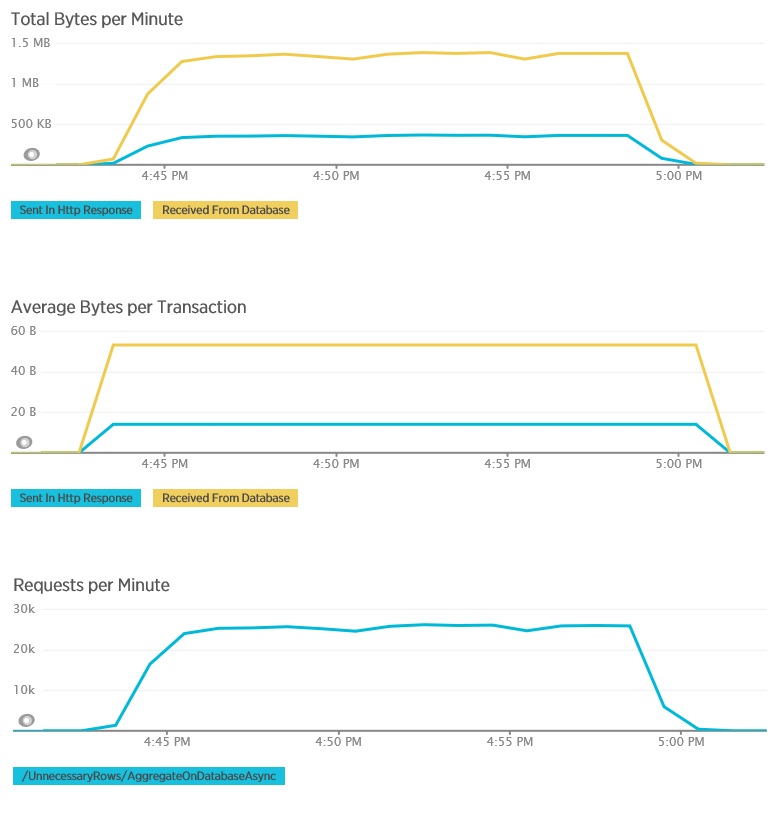
Een belastingtest met behulp van de AggregateOnDatabaseAsync-methode genereert de volgende resultaten:
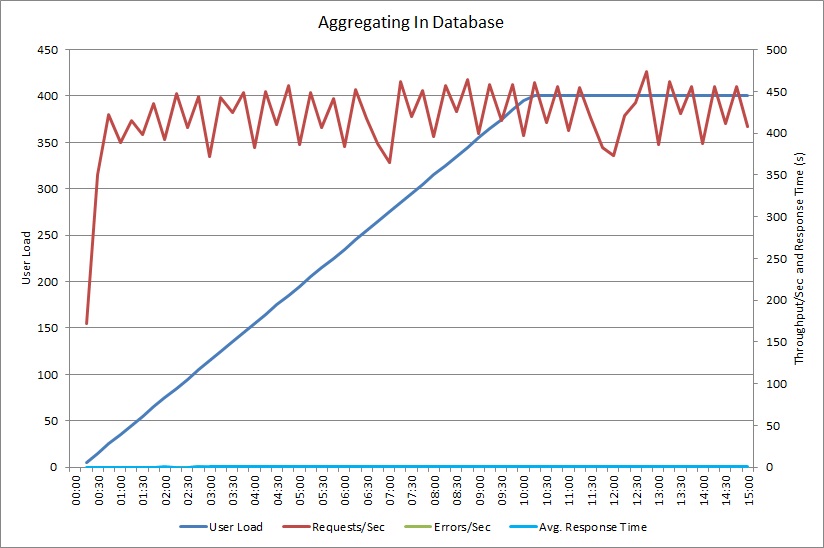
De gemiddelde reactietijd is nu minimaal. Dit is een grote verbetering de van prestaties, voornamelijk door de aanzienlijke vermindering van I/O-bewerkingen uit de database.
Hier ziet u de bijbehorende telemetrie voor de AggregateOnDatabaseAsync-methode. De hoeveelheid gegevens die zijn opgehaald uit de database is aanzienlijk verminderd, van 280 Kb naar 53 bytes per transactie. Als gevolg hiervan kon het maximum aantal aanvragen per minuut worden verhoogd van ongeveer 2000 naar meer dan 25.000.
Verwante resources
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor