Storm-antipatroon opnieuw proberen
Wanneer een service niet beschikbaar of bezet is, kunnen clients hun verbindingen te vaak opnieuw proberen, ertoe leiden dat de service moeilijk kan worden hersteld en kan het probleem erger worden. Het heeft ook geen zin om het voor altijd opnieuw te proberen, omdat aanvragen doorgaans alleen geldig zijn voor een bepaalde periode.
Beschrijving van het probleem
In de cloud ondervinden services soms problemen en zijn ze niet meer beschikbaar voor clients, of moeten ze hun clients beperken of beperken. Hoewel het een goede gewoonte is dat clients mislukte verbindingen met services opnieuw proberen, is het belangrijk dat ze niet te vaak of te lang opnieuw proberen. Het is onwaarschijnlijk dat nieuwe pogingen binnen een korte periode zullen slagen, omdat de services waarschijnlijk niet zijn hersteld. Services kunnen ook nog meer stress krijgen wanneer er veel verbindingspogingen worden gedaan terwijl ze proberen te herstellen. Herhaalde verbindingspogingen kunnen zelfs de service overbelasten en het onderliggende probleem verergeren.
In het volgende voorbeeld ziet u een scenario waarin een client verbinding maakt met een servergebaseerde API. Als de aanvraag niet slaagt, probeert de client onmiddellijk opnieuw en blijft het voor altijd opnieuw proberen. Vaak is dit soort gedrag subtieler dan in dit voorbeeld, maar hetzelfde principe is van toepassing.
public async Task<string> GetDataFromServer()
{
while(true)
{
var result = await httpClient.GetAsync(string.Format("http://{0}:8080/api/...", hostName));
if (result.IsSuccessStatusCode) break;
}
// ... Process result.
}
Het probleem oplossen
Clienttoepassingen moeten enkele aanbevolen procedures volgen om te voorkomen dat er een storm voor nieuwe pogingen wordt veroorzaakt.
- Beperk het aantal nieuwe pogingen en blijf het gedurende een lange periode niet opnieuw proberen. Hoewel het misschien eenvoudig lijkt om een
while(true)lus te schrijven, wilt u het bijna zeker niet gedurende een lange periode opnieuw proberen, omdat de situatie die heeft geleid tot het starten van de aanvraag waarschijnlijk is gewijzigd. In de meeste toepassingen is het voldoende om het een paar seconden of minuten opnieuw te proberen. - Pauzeer tussen nieuwe pogingen. Als een service niet beschikbaar is, is het onwaarschijnlijk dat het direct opnieuw proberen lukt. Verhoog geleidelijk de hoeveelheid tijd die u wacht tussen pogingen, bijvoorbeeld met behulp van een exponentieel uitstelstrategie.
- Fouten probleemloos afhandelen. Als de service niet reageert, moet u overwegen of het zinvol is om de poging af te breken en een fout terug te sturen naar de gebruiker of beller van uw onderdeel. Houd rekening met deze foutscenario's bij het ontwerpen van uw toepassing.
- Overweeg het circuitonderbrekerpatroon te gebruiken, dat speciaal is ontworpen om stormen opnieuw te voorkomen.
- Als de server een
retry-afterantwoordheader opgeeft, moet u ervoor zorgen dat u het niet opnieuw probeert te proberen totdat de opgegeven periode is verstreken. - Gebruik officiële SDK's bij het communiceren met Azure-services. Deze SDK's hebben over het algemeen een ingebouwd beleid voor opnieuw proberen en bescherming tegen het veroorzaken of bijdragen aan stormen voor opnieuw proberen. Als u communiceert met een service die geen SDK heeft of waarbij de SDK de logica voor opnieuw proberen niet correct verwerkt, kunt u overwegen om een bibliotheek zoals Polly (voor .NET) of opnieuw (voor JavaScript) te gebruiken om uw logica voor opnieuw proberen correct af te handelen en te voorkomen dat u de code zelf schrijft.
- Als u werkt in een omgeving die dit ondersteunt, gebruikt u een service-mesh (of een andere abstractielaag) om uitgaande aanroepen te verzenden. Deze hulpprogramma's, zoals Dapr, ondersteunen doorgaans beleid voor opnieuw proberen en volgen automatisch best practices, zoals een back-off na herhaalde pogingen. Deze benadering betekent dat u zelf geen code voor nieuwe pogingen hoeft te schrijven.
- Overweeg om aanvragen in batches te verwerken en aanvragen te groeperen, indien beschikbaar. Veel SDK's verwerken namens u batchverwerking van aanvragen en groepsgewijze verbindingen, waardoor het totale aantal uitgaande verbindingspogingen die uw toepassing uitvoert, wordt verminderd, hoewel u er wel voor moet zorgen dat u deze verbindingen niet te vaak opnieuw probeert.
Services moeten zich ook beschermen tegen stormen bij opnieuw proberen.
- Voeg een gatewaylaag toe zodat u verbindingen tijdens een incident kunt afsluiten. Dit is een voorbeeld van het schottenpatroon. Azure biedt veel verschillende gatewayservices voor verschillende soorten oplossingen, waaronder Front Door, Application Gateway en API Management.
- Verperk aanvragen bij uw gateway, zodat u niet zoveel aanvragen accepteert dat uw back-endonderdelen niet meer kunnen werken.
- Als u beperkingen aan het beperken bent, stuurt u een
retry-afterheader terug om clients te helpen begrijpen wanneer ze hun verbindingen moeten herstellen.
Overwegingen
- Clients moeten rekening houden met het type fout dat wordt geretourneerd. Sommige fouttypen duiden niet op een fout van de service, maar geven aan dat de client een ongeldige aanvraag heeft verzonden. Als een clienttoepassing bijvoorbeeld een
400 Bad Requestfoutbericht ontvangt, zal het opnieuw proberen van dezelfde aanvraag waarschijnlijk niet helpen omdat de server u vertelt dat uw aanvraag ongeldig is. - Clients moeten rekening houden met de tijdsduur die zinvol is om verbindingen te herstellen. De tijdsduur die u opnieuw moet proberen, wordt bepaald door uw bedrijfsvereisten en of u een fout redelijkerwijs kunt doorgeven aan een gebruiker of beller. In de meeste toepassingen is het voldoende om het een paar seconden of minuten opnieuw te proberen.
Het probleem vaststellen
Vanuit het perspectief van een client kunnen de symptomen van dit probleem bestaan uit zeer lange reactie- of verwerkingstijden, samen met telemetrie die wijst op herhaalde pogingen om de verbinding opnieuw te proberen.
Vanuit het perspectief van een service kunnen de symptomen van dit probleem bestaan uit een groot aantal aanvragen van één client binnen een korte periode, of een groot aantal aanvragen van één client tijdens het herstellen van storingen. Symptomen kunnen ook problemen zijn bij het herstellen van de service of doorlopende trapsgewijze fouten van de service direct nadat een fout is hersteld.
Voorbeeld van diagnose
In de volgende secties wordt één benadering beschreven voor het detecteren van een mogelijke storm voor opnieuw proberen, zowel aan de clientzijde als aan de servicezijde.
Identificeren op basis van clienttelemetrie
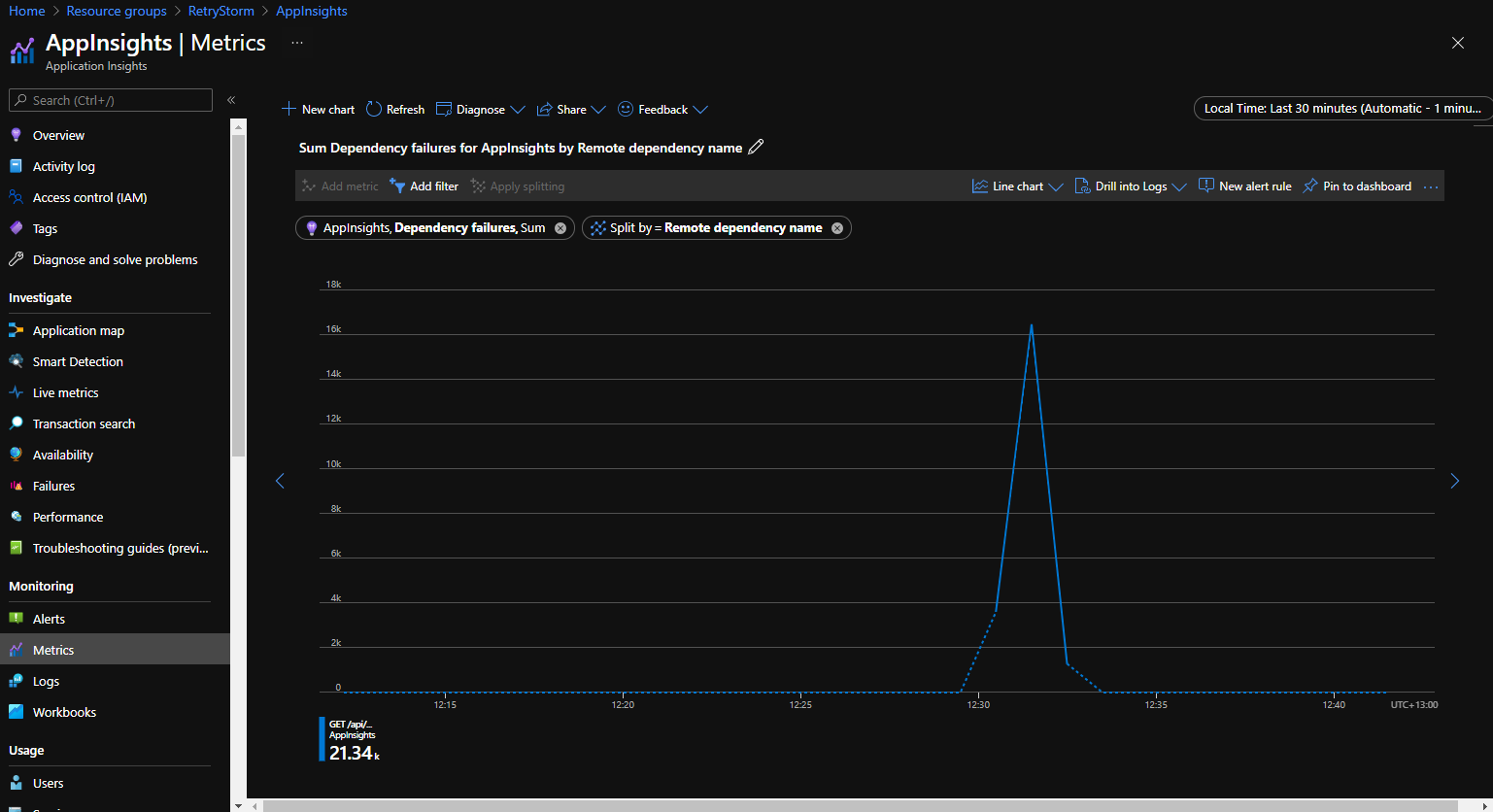
Azure-toepassing Insights registreert telemetrie van toepassingen en maakt de gegevens beschikbaar voor het uitvoeren van query's en visualisaties. Uitgaande verbindingen worden bijgehouden als afhankelijkheden en informatie over deze verbindingen kan worden geopend en in een grafiek worden weergegeven om te bepalen wanneer een client een groot aantal uitgaande aanvragen naar dezelfde service doet.
De volgende grafiek is afkomstig van het tabblad Metrische gegevens in de Application Insights-portal en toont het metrische gegeven Afhankelijkheidsfouten gesplitst op naam van externe afhankelijkheid. Dit illustreert een scenario waarin er binnen korte tijd een groot aantal (meer dan 21.000) mislukte verbindingspogingen met een afhankelijkheid waren.
Identificeren op servertelemetrie
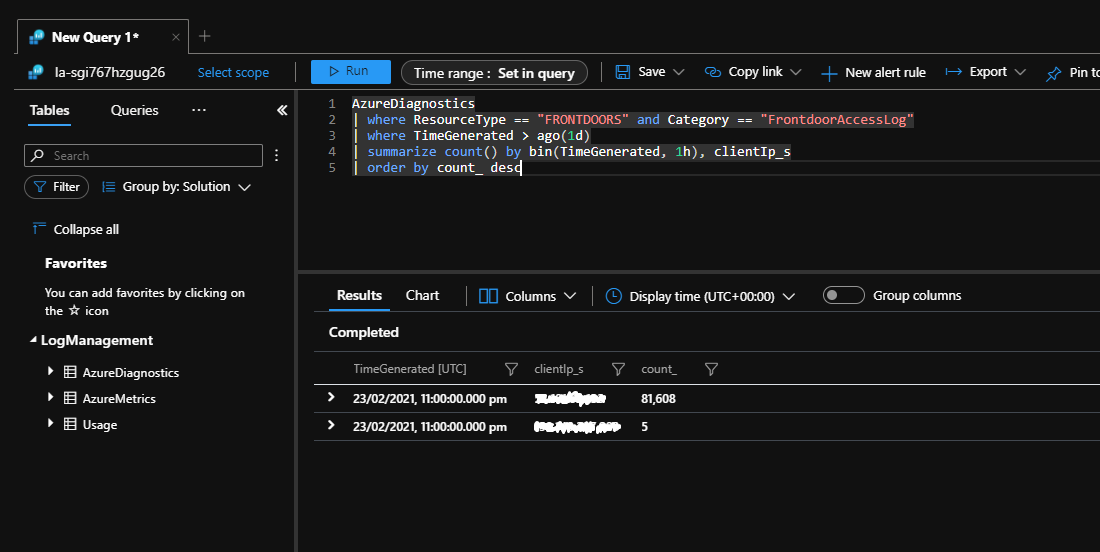
Servertoepassingen kunnen mogelijk grote aantallen verbindingen van één client detecteren. In het volgende voorbeeld fungeert Azure Front Door als een gateway voor een toepassing en is geconfigureerd om alle aanvragen in een Log Analytics-werkruimte te registreren.
De volgende Kusto-query kan worden uitgevoerd op basis van Log Analytics. Hiermee worden client-IP-adressen geïdentificeerd die in de afgelopen dag een groot aantal aanvragen naar de toepassing hebben verzonden.
AzureDiagnostics
| where ResourceType == "FRONTDOORS" and Category == "FrontdoorAccessLog"
| where TimeGenerated > ago(1d)
| summarize count() by bin(TimeGenerated, 1h), clientIp_s
| order by count_ desc
Als u deze query uitvoert tijdens een storm met nieuwe pogingen, ziet u een groot aantal verbindingspogingen vanaf één IP-adres.
Gerelateerde resources
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor