Richtlijnen voor gegevenspartitionering
In veel grootschalige oplossingen worden gegevens onderverdeeld in partities die afzonderlijk kunnen worden beheerd en geopend. Partitioneren kan de schaalbaarheid verbeteren, conflicten verminderen en de prestaties optimaliseren. Het kan ook een mechanisme bieden voor het delen van gegevens met behulp van een gebruikspatroon. U kunt bijvoorbeeld oudere gegevens archiveren in goedkopere gegevensopslag.
De partitioneringsstrategie moet echter zorgvuldig worden gekozen om de voordelen te maximaliseren terwijl negatieve effecten worden geminimaliseerd.
Opmerking
In dit artikel betekent de term partitionering het proces van het fysiek verdelen van gegevens in afzonderlijke gegevensarchieven. Het is niet hetzelfde als partitionering van SQL Server-tabellen.
Waarom partitiegegevens?
De schaalbaarheid verbeteren. Wanneer u één databasesysteem omhoog schaalt, bereikt het uiteindelijk een fysieke hardwarelimiet. Als u gegevens over meerdere partities verdeelt, die elk op een afzonderlijke server worden gehost, kunt u het systeem bijna voor onbepaalde tijd uitschalen.
Prestaties verbeteren. Bewerkingen voor gegevenstoegang op elke partitie vinden plaats via een kleiner volume aan gegevens. Correct gedaan, partitioneren kan uw systeem efficiënter maken. Bewerkingen die van invloed zijn op meer dan één partitie, kunnen parallel worden uitgevoerd.
Verbeter de beveiliging. In sommige gevallen kunt u gevoelige en niet-gevoelige gegevens scheiden in verschillende partities en verschillende beveiligingscontroles toepassen op de gevoelige gegevens.
Operationele flexibiliteit bieden. Partitionering biedt veel mogelijkheden voor het verfijnen van bewerkingen, het maximaliseren van de administratieve efficiëntie en het minimaliseren van de kosten. U kunt bijvoorbeeld verschillende strategieën definiëren voor beheer, bewaking, back-up en herstel en andere beheertaken op basis van het belang van de gegevens in elke partitie.
Koppel het gegevensarchief aan het gebruikspatroon. Met partitionering kan elke partitie worden geïmplementeerd op een ander type gegevensarchief, op basis van de kosten en de ingebouwde functies van het gegevensarchief. Grote binaire gegevens kunnen bijvoorbeeld worden opgeslagen in blobopslag, terwijl er meer gestructureerde gegevens in een documentdatabase kunnen worden opgeslagen. Zie Het juiste gegevensarchief kiezen voor meer informatie.
De beschikbaarheid verbeteren. Het scheiden van gegevens over meerdere servers voorkomt een single point of failure. Als één exemplaar mislukt, zijn alleen de gegevens in die partitie niet beschikbaar. Bewerkingen op andere partities kunnen worden voortgezet. Voor paaS-gegevensarchieven (Managed Platform as a Service) is deze overweging minder relevant, omdat deze services zijn ontworpen met ingebouwde redundantie.
Partities ontwerpen
Er zijn drie typische strategieën voor het partitioneren van gegevens:
Horizontale partitionering (vaak sharding genoemd). In deze strategie is elke partitie een afzonderlijk gegevensarchief, maar alle partities hebben hetzelfde schema. Elke partitie wordt een shard genoemd en bevat een specifieke subset van de gegevens, zoals alle orders voor een specifieke set klanten.
Verticale partitionering. In deze strategie bevat elke partitie een subset van de velden voor items in het gegevensarchief. De velden worden verdeeld op basis van hun gebruikspatroon. Veelgebruikte velden kunnen bijvoorbeeld in één verticale partitie worden geplaatst en minder vaak gebruikte velden in een andere.
Functionele partitionering. In deze strategie worden gegevens geaggregeerd op basis van de wijze waarop deze worden gebruikt door elke gebonden context in het systeem. Een e-commercesysteem kan bijvoorbeeld factuurgegevens opslaan in één partitie en productinventarisgegevens in een andere.
Deze strategieën kunnen worden gecombineerd en we raden u aan ze allemaal te overwegen wanneer u een partitioneringsschema ontwerpt. U kunt bijvoorbeeld gegevens onderverdelen in shards en vervolgens verticale partitionering gebruiken om de gegevens in elke shard verder te onderverdelen.
Horizontale partitionering (sharding)
In afbeelding 1 ziet u horizontale partitionering of sharding. In dit voorbeeld worden productinventarisgegevens onderverdeeld in shards op basis van de productcode. Elke shard bevat de gegevens voor een aaneengesloten bereik van shardsleutels (A-G en H-Z), alfabetisch ingedeeld. Sharding verspreidt de belasting over meer computers, waardoor conflicten worden verminderd en de prestaties worden verbeterd.
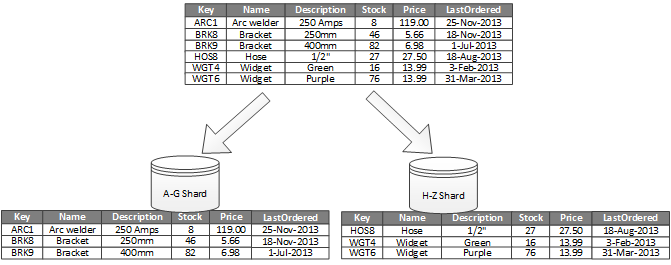
Afbeelding 1: gegevens horizontaal partitioneren (sharding) op basis van een partitiesleutel.
De belangrijkste factor is de keuze van een sharding-sleutel. Het kan lastig zijn om de sleutel te wijzigen nadat het systeem in werking is. De sleutel moet ervoor zorgen dat gegevens worden gepartitioneerd om de werkbelasting zo gelijkmatig mogelijk over de shards te verdelen.
De shards hoeven niet dezelfde grootte te hebben. Het is belangrijker om het aantal aanvragen te verdelen. Sommige shards kunnen erg groot zijn, maar elk item heeft een laag aantal toegangsbewerkingen. Andere shards zijn mogelijk kleiner, maar elk item wordt veel vaker geopend. Het is ook belangrijk om ervoor te zorgen dat één shard de schaallimieten (qua capaciteit en verwerkingsbronnen) van het gegevensarchief niet overschrijdt.
Vermijd het maken van 'dynamische' partities die van invloed kunnen zijn op de prestaties en beschikbaarheid. Als u bijvoorbeeld de eerste letter van de naam van een klant gebruikt, wordt een niet-verdeelde verdeling veroorzaakt, omdat sommige letters vaker voorkomen. Gebruik in plaats daarvan een hash van een klant-id om gegevens gelijkmatiger over partities te verdelen.
Kies een shardingsleutel waarmee toekomstige vereisten worden geminimaliseerd om grote shards te splitsen, kleine shards te samenvoegen in grotere partities of het schema te wijzigen. Deze bewerkingen kunnen erg tijdrovend zijn en vereisen dat een of meer shards offline worden gehaald terwijl ze worden uitgevoerd.
Als shards worden gerepliceerd, is het mogelijk om sommige replica's online te houden terwijl andere worden gesplitst, samengevoegd of opnieuw geconfigureerd. Het systeem moet echter mogelijk de bewerkingen beperken die kunnen worden uitgevoerd tijdens de herconfiguratie. De gegevens in de replica's kunnen bijvoorbeeld worden gemarkeerd als alleen-lezen om inconsistenties van gegevens te voorkomen.
Zie Sharding-patroon voor meer informatie over horizontale partitionering.
Verticale partitionering
Het meest voorkomende gebruik voor verticale partitionering is het verminderen van de I/O- en prestatiekosten die zijn gekoppeld aan het ophalen van items die vaak worden geopend. Afbeelding 2 toont een voorbeeld van verticale partitionering. In dit voorbeeld worden verschillende eigenschappen van een item opgeslagen in verschillende partities. Eén partitie bevat gegevens die vaker worden geopend, waaronder productnaam, beschrijving en prijs. Een andere partitie bevat inventarisgegevens: het aantal aandelen en de laatste bestelde datum.
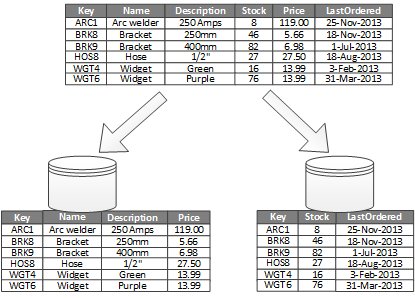
Afbeelding 2: gegevens verticaal partitioneren op basis van het gebruikspatroon.
In dit voorbeeld voert de toepassing regelmatig een query uit op de productnaam, beschrijving en prijs bij het weergeven van de productgegevens aan klanten. Voorraadtelling en laatste bestelde datum worden in een afzonderlijke partitie bewaard, omdat deze twee items vaak samen worden gebruikt.
Andere voordelen van verticale partitionering:
Relatief langzaam bewegende gegevens (productnaam, beschrijving en prijs) kunnen worden gescheiden van de dynamischere gegevens (voorraadniveau en laatste bestelde datum). Trage verplaatsing van gegevens is een goede kandidaat voor een toepassing om in het geheugen op te cachen.
Gevoelige gegevens kunnen worden opgeslagen in een afzonderlijke partitie met aanvullende beveiligingsmaatregelen.
Verticale partitionering kan de hoeveelheid gelijktijdige toegang verminderen die nodig is.
Verticale partitionering werkt op entiteitsniveau in een gegevensarchief, waardoor een entiteit gedeeltelijk wordt genormaliseerd om deze op te splitsen van een breed item naar een set smalle items. Het is ideaal voor kolomgeoriënteerde gegevensarchieven, zoals HBase en Cassandra. Als de gegevens in een verzameling kolommen waarschijnlijk niet veranderen, kunt u ook overwegen om kolomarchieven in SQL Server te gebruiken.
Functionele partitionering
Wanneer het mogelijk is om een gebonden context te identificeren voor elk afzonderlijk bedrijfsgebied in een toepassing, is functionele partitionering een manier om isolatie- en gegevenstoegangsprestaties te verbeteren. Een ander veelvoorkomend gebruik voor functionele partitionering is het scheiden van alleen-lezen gegevens van alleen-lezengegevens. Afbeelding 3 toont een overzicht van functionele partitionering waarbij inventarisgegevens worden gescheiden van klantgegevens.
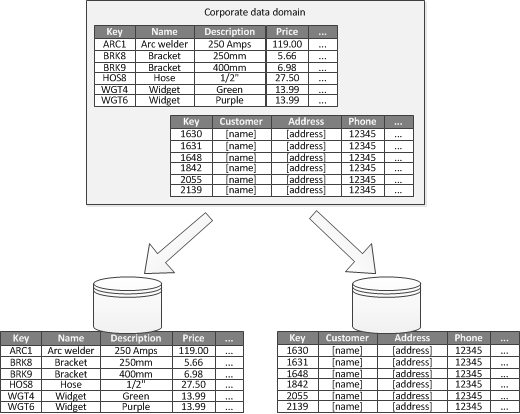
Afbeelding 3: Functioneel partitioneren van gegevens door gebonden context of subdomein.
Deze partitioneringsstrategie kan helpen bij het verminderen van conflicten over gegevenstoegang in verschillende delen van een systeem.
Partities ontwerpen voor schaalbaarheid
Het is essentieel om de grootte en workload voor elke partitie te overwegen en deze te verdelen, zodat gegevens worden gedistribueerd om maximale schaalbaarheid te bereiken. U moet echter ook de gegevens partitioneren, zodat deze niet groter zijn dan de schaallimieten van één partitiearchief.
Volg deze stappen bij het ontwerpen van partities voor schaalbaarheid:
- Analyseer de toepassing om inzicht te krijgen in de gegevenstoegangspatronen, zoals de grootte van de resultatenset die door elke query wordt geretourneerd, de frequentie van toegang, de inherente latentie en de verwerkingsvereisten aan de serverzijde. In veel gevallen vragen enkele belangrijke entiteiten de meeste verwerkingsbronnen.
- Gebruik deze analyse om de huidige en toekomstige schaalbaarheidsdoelen te bepalen, zoals gegevensgrootte en workload. Distribueer vervolgens de gegevens over de partities om te voldoen aan het schaalbaarheidsdoel. Voor horizontale partitionering is het kiezen van de juiste shardsleutel belangrijk om ervoor te zorgen dat de distributie gelijkmatig is. Zie het sharding-patroon voor meer informatie.
- Zorg ervoor dat elke partitie voldoende resources heeft om de schaalbaarheidsvereisten af te handelen, wat betreft de gegevensgrootte en doorvoer. Afhankelijk van het gegevensarchief is er mogelijk een limiet voor de hoeveelheid opslagruimte, verwerkingskracht of netwerkbandbreedte per partitie. Als de vereisten waarschijnlijk deze limieten overschrijden, moet u mogelijk uw partitioneringsstrategie verfijnen of gegevens verder splitsen, mogelijk door twee of meer strategieën te combineren.
- Bewaak het systeem om te controleren of de gegevens worden gedistribueerd zoals verwacht en of de partities de belasting kunnen verwerken. Het werkelijke gebruik komt niet altijd overeen met wat een analyse voorspelt. Als dat het zo is, kan het mogelijk zijn om de partities opnieuw te verdelen of een deel van het systeem opnieuw te ontwerpen om het vereiste saldo te verkrijgen.
Sommige cloudomgevingen wijzen resources toe in termen van infrastructuurgrenzen. Zorg ervoor dat de limieten van de geselecteerde grens voldoende ruimte bieden voor elke verwachte groei van het gegevensvolume, wat betreft gegevensopslag, verwerkingskracht en bandbreedte.
Als u bijvoorbeeld Azure Table Storage gebruikt, is er een limiet voor het aantal aanvragen dat kan worden verwerkt door één partitie in een bepaalde periode. (Zie Schaalbaarheids- en prestatiedoelen voor Azure Storage voor meer informatie.) Een bezet shard vereist mogelijk meer resources dan één partitie kan verwerken. Zo ja, dan moet de shard mogelijk opnieuw worden gepartitioneerd om de belasting te verdelen. Als de totale grootte of doorvoer van deze tabellen de capaciteit van een opslagaccount overschrijdt, moet u mogelijk extra opslagaccounts maken en de tabellen over deze accounts verdelen.
Partities ontwerpen voor queryprestaties
Queryprestaties kunnen vaak worden verhoogd met behulp van kleinere gegevenssets en door parallelle query's uit te voeren. Elke partitie moet een klein deel van de volledige gegevensset bevatten. Deze vermindering van het volume kan de prestaties van query's verbeteren. Partitionering is echter geen alternatief voor het ontwerpen en configureren van een database. Zorg er bijvoorbeeld voor dat u over de benodigde indexen beschikt.
Volg deze stappen bij het ontwerpen van partities voor queryprestaties:
Bekijk de toepassingsvereisten en prestaties:
- Gebruik bedrijfsvereisten om de kritieke query's te bepalen die altijd snel moeten worden uitgevoerd.
- Bewaak het systeem om query's te identificeren die langzaam worden uitgevoerd.
- Zoek welke query's het vaakst worden uitgevoerd. Zelfs als één query minimale kosten heeft, kan het cumulatieve resourceverbruik aanzienlijk zijn.
Partitioneer de gegevens die trage prestaties veroorzaken:
- Beperk de grootte van elke partitie zodat de reactietijd van de query binnen het doel valt.
- Als u horizontale partitionering gebruikt, ontwerpt u de shardsleutel zodat de toepassing eenvoudig de juiste partitie kan selecteren. Hiermee voorkomt u dat de query elke partitie moet scannen.
- Houd rekening met de locatie van een partitie. Probeer, indien mogelijk, gegevens in partities te bewaren die geografisch dicht bij de toepassingen en gebruikers staan die er toegang toe hebben.
Als een entiteit vereisten voor doorvoer- en queryprestaties heeft, gebruikt u functionele partitionering op basis van die entiteit. Als dit nog steeds niet voldoet aan de vereisten, past u ook horizontale partitionering toe. In de meeste gevallen volstaat één partitioneringsstrategie, maar in sommige gevallen is het efficiënter om beide strategieën te combineren.
Overweeg query's parallel uit te voeren in meerdere partities om de prestaties te verbeteren.
Partities ontwerpen voor beschikbaarheid
Het partitioneren van gegevens kan de beschikbaarheid van toepassingen verbeteren door ervoor te zorgen dat de volledige gegevensset geen single point of failure vormt en dat afzonderlijke subsets van de gegevensset onafhankelijk kunnen worden beheerd.
Houd rekening met de volgende factoren die van invloed zijn op de beschikbaarheid:
Hoe kritiek de gegevens zijn voor bedrijfsactiviteiten. Bepaal welke gegevens kritieke bedrijfsgegevens zijn, zoals transacties, en welke gegevens minder kritieke operationele gegevens zijn, zoals logboekbestanden.
Overweeg kritieke gegevens op te slaan in maximaal beschikbare partities met een geschikt back-upplan.
Stel afzonderlijke beheer- en bewakingsprocedures in voor de verschillende gegevenssets.
Plaats gegevens met hetzelfde kritieke niveau in dezelfde partitie, zodat er een back-up van kan worden gemaakt met een geschikte frequentie. Partities met transactiegegevens moeten bijvoorbeeld vaker een back-up maken dan partities die logboek- of traceringsgegevens bevatten.
Hoe afzonderlijke partities kunnen worden beheerd. Het ontwerpen van partities ter ondersteuning van onafhankelijk beheer en onderhoud biedt verschillende voordelen. Voorbeeld:
Als een partitie mislukt, kan deze onafhankelijk worden hersteld zonder toepassingen die toegang hebben tot gegevens in andere partities.
Door gegevens per geografisch gebied te partitioneren, kunnen geplande onderhoudstaken op daluren plaatsvinden voor elke locatie. Zorg ervoor dat partities niet te groot zijn om te voorkomen dat gepland onderhoud tijdens deze periode wordt voltooid.
Of kritieke gegevens tussen partities moeten worden gerepliceerd. Deze strategie kan de beschikbaarheid en prestaties verbeteren, maar kan ook consistentieproblemen veroorzaken. Het duurt even om wijzigingen met elke replica te synchroniseren. Gedurende deze periode bevatten verschillende partities verschillende gegevenswaarden.
Overwegingen voor applicatieontwerp
Partitionering voegt complexiteit toe aan het ontwerp en de ontwikkeling van uw systeem. Overweeg partitioneren als een fundamenteel onderdeel van het systeemontwerp, zelfs als het systeem in eerste instantie slechts één partitie bevat. Als u partitionering als een achteraf adresseert, is het lastiger omdat u al een live systeem hebt om te onderhouden:
- Logica voor gegevenstoegang moet worden gewijzigd.
- Grote hoeveelheden bestaande gegevens moeten mogelijk worden gemigreerd om deze over partities te verdelen.
- Gebruikers verwachten dat ze het systeem tijdens de migratie kunnen blijven gebruiken.
In sommige gevallen wordt partitionering niet als belangrijk beschouwd omdat de initiële gegevensset klein is en eenvoudig kan worden verwerkt door één server. Dit geldt mogelijk voor sommige workloads, maar veel commerciële systemen moeten worden uitgebreid naarmate het aantal gebruikers toeneemt.
Bovendien zijn het niet alleen grote gegevensarchieven die profiteren van partitionering. Een klein gegevensarchief kan bijvoorbeeld intensief worden geopend door honderden gelijktijdige clients. Het partitioneren van de gegevens in deze situatie kan helpen om conflicten te verminderen en de doorvoer te verbeteren.
Houd rekening met de volgende punten wanneer u een schema voor gegevenspartitionering ontwerpt:
Minimaliseer bewerkingen voor gegevenstoegang tussen meerdere partities. Bewaar waar mogelijk gegevens voor de meest voorkomende databasebewerkingen in elke partitie om gegevenstoegangsbewerkingen tussen meerdere partities te minimaliseren. Query's uitvoeren op meerdere partities kan tijdrovender zijn dan het uitvoeren van query's binnen één partitie, maar het optimaliseren van partities voor één set query's kan nadelig zijn voor andere sets query's. Als u query's op meerdere partities moet uitvoeren, minimaliseert u de querytijd door parallelle query's uit te voeren en de resultaten in de toepassing samen te stellen. (Deze benadering is in sommige gevallen mogelijk niet mogelijk, bijvoorbeeld wanneer het resultaat van de ene query wordt gebruikt in de volgende query.)
Overweeg om statische referentiegegevens te repliceren. Als query's relatief statische referentiegegevens gebruiken, zoals postcodetabellen of productlijsten, kunt u overwegen deze gegevens in alle partities te repliceren om afzonderlijke opzoekbewerkingen in verschillende partities te verminderen. Deze aanpak kan ook de kans verminderen dat de referentiegegevens een 'dynamische' gegevensset worden, met veel verkeer van over het hele systeem. Er zijn echter extra kosten verbonden aan het synchroniseren van wijzigingen in de referentiegegevens.
Minimaliseer joins tussen partities. Minimaliseer waar mogelijk de vereisten voor referentiële integriteit voor verticale en functionele partities. In deze schema's is de toepassing verantwoordelijk voor het onderhouden van referentiële integriteit tussen partities. Query's die gegevens samenvoegen tussen meerdere partities zijn inefficiënt, omdat de toepassing doorgaans opeenvolgende query's moet uitvoeren op basis van een sleutel en vervolgens een refererende sleutel. In plaats daarvan kunt u overwegen om de relevante gegevens te repliceren of de normaliseren. Als joins tussen partities nodig zijn, voert u parallelle query's uit over de partities en voegt u de gegevens in de toepassing toe.
De uiteindelijke consistentie omarmen. Evalueer of sterke consistentie daadwerkelijk een vereiste is. Een algemene benadering in gedistribueerde systemen is het implementeren van uiteindelijke consistentie. De gegevens in elke partitie worden afzonderlijk bijgewerkt en de toepassingslogica zorgt ervoor dat alle updates zijn voltooid. Het verwerkt ook de inconsistenties die kunnen ontstaan door het uitvoeren van query's op gegevens terwijl een uiteindelijk consistente bewerking wordt uitgevoerd.
Bedenk hoe query's de juiste partitie vinden. Als een query alle partities moet scannen om de vereiste gegevens te vinden, is er een aanzienlijke invloed op de prestaties, zelfs wanneer meerdere parallelle query's worden uitgevoerd. Met verticale en functionele partitionering kunnen query's op natuurlijke wijze de partitie opgeven. Horizontale partitionering kan daarentegen het lastig maken om een item te vinden, omdat elke shard hetzelfde schema heeft. Een typische oplossing voor het onderhouden van een kaart die wordt gebruikt om de shardlocatie voor specifieke items op te zoeken. Deze kaart kan worden geïmplementeerd in de shardinglogica van de toepassing of worden onderhouden door het gegevensarchief als deze transparante sharding ondersteunt.
Overweeg regelmatig shards opnieuw te verdelen. Met horizontale partitionering kunt u shards gelijkmatig verdelen op grootte en werkbelasting om hotspots te minimaliseren, queryprestaties te maximaliseren en beperkingen voor fysieke opslag te omzeilen. Dit is echter een complexe taak die vaak het gebruik van een aangepast hulpprogramma of proces vereist.
Partities repliceren. Als u elke partitie repliceert, biedt deze extra beveiliging tegen fouten. Als één replica mislukt, kunnen query's worden omgeleid naar een werkende kopie.
Als u de fysieke limieten van een partitioneringsstrategie bereikt, moet u de schaalbaarheid mogelijk uitbreiden naar een ander niveau. Als partitionering zich bijvoorbeeld op databaseniveau bevindt, moet u mogelijk partities in meerdere databases zoeken of repliceren. Als partitionering zich al op databaseniveau bevindt en fysieke beperkingen een probleem zijn, kan het betekenen dat u partities in meerdere hostingaccounts moet zoeken of repliceren.
Vermijd transacties die toegang hebben tot gegevens in meerdere partities. Sommige gegevensarchieven implementeren transactionele consistentie en integriteit voor bewerkingen die gegevens wijzigen, maar alleen wanneer de gegevens zich in één partitie bevinden. Als u transactionele ondersteuning nodig hebt voor meerdere partities, moet u dit waarschijnlijk implementeren als onderdeel van uw toepassingslogica, omdat de meeste partitioneringssystemen geen systeemeigen ondersteuning bieden.
Voor alle gegevensarchieven is een aantal operationele beheer- en bewakingsactiviteiten vereist. De taken kunnen variëren van het laden van gegevens, het maken van back-ups en het herstellen van gegevens, het opnieuw organiseren van gegevens en het garanderen dat het systeem correct en efficiënt presteert.
Houd rekening met de volgende factoren die van invloed zijn op operationeel beheer:
Hoe u de juiste beheer- en operationele taken implementeert wanneer de gegevens worden gepartitioneerd. Deze taken kunnen bestaan uit back-up en herstel, archivering van gegevens, bewaking van het systeem en andere beheertaken. Het onderhouden van logische consistentie tijdens back-up- en herstelbewerkingen kan bijvoorbeeld een uitdaging zijn.
Hoe u de gegevens in meerdere partities laadt en nieuwe gegevens toevoegt die afkomstig zijn van andere bronnen. Sommige hulpprogramma's en hulpprogramma's ondersteunen mogelijk geen shard-gegevensbewerkingen, zoals het laden van gegevens in de juiste partitie.
Hoe u de gegevens regelmatig kunt archiveren en verwijderen. Als u de overmatige groei van partities wilt voorkomen, moet u gegevens regelmatig archiveren en verwijderen (zoals maandelijks). Het kan nodig zijn om de gegevens te transformeren zodat deze overeenkomen met een ander archiefschema.
Problemen met gegevensintegriteit vinden. Overweeg een periodiek proces uit te voeren om problemen met gegevensintegriteit te vinden, zoals gegevens in één partitie die verwijst naar ontbrekende informatie in een andere partitie. Het proces kan proberen deze problemen automatisch op te lossen of een rapport genereren voor handmatige controle.
Partities opnieuw verdelen
Als een systeem volwassen wordt, moet u mogelijk het partitioneringsschema aanpassen. Afzonderlijke partities kunnen bijvoorbeeld een onevenredig volume aan verkeer krijgen en heet worden, wat leidt tot overmatige conflicten. Of u hebt het volume van gegevens in sommige partities onderschat, waardoor sommige partities capaciteitslimieten naderen.
Sommige gegevensarchieven, zoals Azure Cosmos DB, kunnen partities automatisch opnieuw verdelen. In andere gevallen is herverdeling een beheertaak die uit twee fasen bestaat:
Bepaal een nieuwe partitioneringsstrategie.
- Welke partities moeten worden gesplitst (of mogelijk gecombineerd)?
- Wat is de nieuwe partitiesleutel?
Gegevens migreren van het oude partitioneringsschema naar de nieuwe set partities.
Afhankelijk van het gegevensarchief kunt u mogelijk gegevens migreren tussen partities terwijl ze in gebruik zijn. Dit wordt onlinemigratie genoemd. Als dat niet mogelijk is, moet u partities mogelijk niet beschikbaar maken terwijl de gegevens worden verplaatst (offlinemigratie).
Offlinemigratie
Offlinemigratie is doorgaans eenvoudiger omdat het de kans op conflicten vermindert. Conceptueel werkt offlinemigratie als volgt:
- Markeer de partitie offline.
- Split-merge en verplaats de gegevens naar de nieuwe partities.
- Controleer de gegevens.
- Breng de nieuwe partities online.
- Verwijder de oude partitie.
U kunt desgewenst een partitie markeren als alleen-lezen in stap 1, zodat toepassingen de gegevens nog steeds kunnen lezen terwijl ze worden verplaatst.
Online migratie
Onlinemigratie is complexer om uit te voeren, maar minder verstorend. Het proces is vergelijkbaar met offlinemigratie, behalve dat de oorspronkelijke partitie niet als offline is gemarkeerd. Afhankelijk van de granulariteit van het migratieproces (bijvoorbeeld item per item versus shard by shard), moet de code voor gegevenstoegang in de clienttoepassingen mogelijk het lezen en schrijven van gegevens verwerken die op twee locaties zijn opgeslagen, de oorspronkelijke partitie en de nieuwe partitie.
Volgende stappen
- Meer informatie over partitioneringsstrategieën voor specifieke Azure-services. Zie Strategieën voor gegevenspartitionering voor meer informatie.
- Schaalbaarheids- en prestatiedoelen voor Azure Storage
Verwante middelen
De volgende ontwerppatronen zijn mogelijk relevant voor uw scenario:
Het sharding-patroon beschrijft enkele veelvoorkomende strategieën voor shardinggegevens.
Het indextabelpatroon laat zien hoe u secundaire indexen maakt voor gegevens. Een toepassing kan snel gegevens ophalen met deze methode, met behulp van query's die niet verwijzen naar de primaire sleutel van een verzameling.
In het gerealiseerde weergavepatroon wordt beschreven hoe u vooraf ingevulde weergaven genereert die gegevens samenvatten om snelle querybewerkingen te ondersteunen. Deze benadering kan nuttig zijn in een gepartitioneerd gegevensarchief als de partities die de samengevatte gegevens bevatten, worden verdeeld over meerdere sites.