Modellen voor gegevensopslag begrijpen
Moderne bedrijfssystemen beheren steeds grotere hoeveelheden heterogene gegevens. Deze heterogeniteit houdt in dat één gegevensarchief meestal niet de beste aanpak is. In plaats daarvan is het vaak beter om verschillende typen gegevens op te slaan in verschillende gegevensarchieven, elk gericht op een specifieke workload of een specifiek gebruikspatroon. De term polyglot persistence wordt gebruikt voor oplossingen waarbij een mix van opslagtechnologieën wordt gebruikt. Daarom is het belangrijk om inzicht te hebben in de belangrijkste opslagmodellen en hun compromissen.
Het is van belang dat u het juiste gegevensarchief kiest dat bij de bedrijfsvereisten past. U kunt voor SQL- en NoSQL-databases kiezen uit letterlijk honderden implementaties. Gegevensarchieven worden vaak onderverdeeld naar de manier waarop ze gegevens structureren en naar de typen bewerkingen die ze ondersteunen. In dit artikel wordt een aantal van de meestvoorkomende opslagmodellen beschreven. Vergeet niet dat een bepaalde opslagtechnologie meerdere opslagmodellen kan ondersteunen. Een relationeel databasebeheersysteem (RDBMS) kan ook de opslag van sleutels/waarden of grafieken ondersteunen. In feite is er een algemene trend voor zogenaamde ondersteuning voor meerdere modellen , waarbij één databasesysteem verschillende modellen ondersteunt. Het is echter nuttig kennis te hebben van de verschillende modellen op hoog niveau.
Niet elk gegevensarchief binnen een bepaalde categorie biedt de zelfde functionaliteit. De meeste gegevensarchieven bieden functionaliteit aan de serverzijde om query's in gegevens uit te voeren en gegevens te verwerken. Soms is deze functionaliteit in de engine voor het opslagarchief ingebouwd. In andere gevallen zijn het gegevensarchief en de verwerkende functies gescheiden en kunnen zijn er meerdere opties mogelijk voor verwerking en analyse. Gegevensarchieven ondersteunen ook verschillende programmatische en beheerinterfaces.
In het algemeen dient u eerst te overwegen welk opslagmodel het meest geschikt is voor uw vereisten. Vervolgens overweegt u een bepaald gegevensarchief binnen die categorie, op basis van bijvoorbeeld de functieset, de kosten en het beheergemak.
Notitie
Meer informatie over het identificeren en controleren van de vereisten voor uw gegevensservice voor cloudimplementatie in het Microsoft Cloud Adoption Framework voor Azure. Op dezelfde manier kunt u ook meer te weten komen over het selecteren van opslaghulpprogramma's en -services.
Relationele databasebeheersystemen
In een relationele database worden gegevens gerangschikt als een reeks tweedimensionale tabellen met rijen en kolommen. De meeste leveranciers bieden een dialect van de Structured Query Language (SQL) voor het ophalen en beheren van gegevens. Een RDBMS bevat gewoonlijk een consistent mechanisme dat voldoet aan het ACID-model (Atomisch, Consistent, geÏsoleerd, Duurzaam) voor het bijwerken van gegevens.
Gewoonlijk ondersteunt een RDBMS een Schema-on-Write-model, waarbij de gegevensstructuur van tevoren wordt gedefinieerd en alle lees- en schrijfbewerkingen dit schema moeten gebruiken.
Dit model is zeer nuttig wanneer sterke consistentiegaranties belangrijk zijn, waarbij alle wijzigingen atomisch zijn en transacties altijd de gegevens in een consistente status achterlaten. Een RDBMS kan echter over het algemeen niet horizontaal worden uitgeschaald zonder de gegevens op een of andere manier te sharden. De gegevens in een RDBMS moeten ook worden genormaliseerd, wat niet geschikt is voor elke gegevensset.
Azure-services
- Azure SQL Database | (beveiligingsbasislijn)
- Azure Database for MySQL | (beveiligingsbasislijn)
- Azure Database for PostgreSQL | (beveiligingsbasislijn)
- Azure Database for MariaDB | (beveiligingsbasislijn)
Workload
- Records worden regelmatig gemaakt en bijgewerkt.
- Meerdere bewerkingen moeten in één transactie worden uitgevoerd.
- Relaties worden afgedwongen met behulp van databasebeperkingen.
- Indexen worden gebruikt om queryprestaties te optimaliseren.
Gegevenstype
- Gegevens zijn maximaal genormaliseerd.
- Databaseschema's zijn vereist en worden afgedwongen.
- Veel-op-veelrelaties tussen gegevensentiteiten in de database.
- Beperkingen worden gedefinieerd in het schema en opgelegd aan alle gegevens in de database.
- Gegevens vereisen hoge integriteit. Indexen en relaties moeten nauwkeurig worden bijgehouden.
- Gegevens vereisen hoge consistentie. Transacties worden zodanig uitgevoerd dat alle gegevens 100% consistent zijn voor alle gebruikers en processen.
- De grootte van afzonderlijke gegevensvermeldingen is klein tot middelgroot.
Voorbeelden
- Voorraadbeheer
- Bestellingsbeheer
- Rapportagedatabase
- Financiële administratie
Sleutel-/waardearchieven
Een sleutel-/waardearchief koppelt elke gegevenswaarde aan een unieke sleutel. De meeste sleutel-/waardearchieven ondersteunen slechts eenvoudige zoek-, invoeg- en verwijder-bewerkingen. Als er een waarde (deels of volledig) moet worden gewijzigd, moeten de bestaande gegevens voor de hele waarde worden overschreven. Bij de meeste implementaties is het lezen of schrijven van één waarde een atomische bewerking.
Een toepassing kan willekeurige gegevens opslaan als een set waarden. Alle schemagegevens moeten door de toepassing worden verstrekt. In het sleutel-/waardearchief wordt de waarde op basis van de sleutel opgehaald of opgeslagen.
Sleutel-/waardearchieven zijn sterk geoptimaliseerd voor toepassingen die eenvoudige zoekopdrachten uitvoeren, maar zijn minder geschikt als u gegevens in verschillende sleutel-/waardearchieven moet opvragen. Sleutel-/waardearchieven zijn ook niet geoptimaliseerd voor het uitvoeren van query's op waarde.
Een sleutel-/waardearchief kan zeer schaalbaar zijn, omdat het opslagarchief makkelijk gegevens kan verdelen over meerde knooppunten op verschillende computers.
Azure-services
- Azure Cosmos DB for Table en Azure Cosmos DB for NoSQL | (Azure Cosmos DB-beveiligingsbasislijn)
- | Azure Cache voor Redis (beveiligingsbasislijn)
- Azure Table Storage | (beveiligingsbasislijn)
Workload
- Gegevens worden geopend met één sleutel, zoals een woordenlijst.
- Geen joins, vergrendelingen of verenigingen vereist.
- Er worden geen aggregatiemethoden gebruikt.
- Secundaire indexen worden over het algemeen niet gebruikt.
Gegevenstype
- Elke sleutel is gekoppeld aan één waarde.
- Schema's worden niet afgedwongen.
- Geen relaties tussen entiteiten.
Voorbeelden
- Gegevens in de cache
- Sessiebeheer
- Gebruikersvoorkeur en profielbeheer
- Productaanbevelingen en advertenties
Documentdatabases
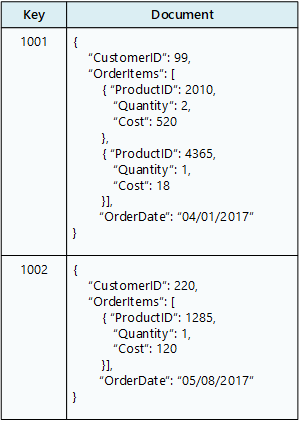
In een documentdatabase wordt een verzameling documenten opgeslagen, waarbij elk document bestaat uit benoemde velden en gegevens. De gegevens kunnen eenvoudige waarden of complexe elementen zijn, zoals lijsten en onderliggende verzamelingen. Documenten worden opgehaald met unieke sleutels.
Normaal gesproken bevat een document de gegevens voor één entiteit, zoals een klant of een order. Een document kan informatie bevatten die zou worden verspreid over verschillende relationele tabellen in een RDBMS. Documenten hoeven niet dezelfde structuur te hebben. Toepassingen kunnen verschillende gegevens in documenten opslaan als bedrijfsvereisten veranderen.
Azure-service
Workload
- Invoeg- en updatebewerkingen komen veel voor.
- Geen objectrelationele onverenigbaarheid wat betreft impedantie. Documenten komen beter overeen met de objectstructuren die in de toepassingscode worden gebruikt.
- Afzonderlijke documenten worden als één blok opgehaald en geschreven.
- Voor gegevens is een index op meerdere velden vereist.
Gegevenstype
- Gegevens kunnen worden beheerd in de gedenormaliseerde manier.
- Grootte van afzonderlijke documentgegevens is relatief klein.
- Elk documenttype kan een eigen schema gebruiken.
- Documenten kunnen optionele velden bevatten.
- Documentgegevens zijn semigestructureerd. Dat wil zeggen dat gegevenstypen van elk veld niet strikt zijn gedefinieerd.
Voorbeelden
- Productcatalogus
- Inhoudbeheer
- Voorraadbeheer
Grafiekdatabases
Een diagramdatabase slaat twee typen gegevens op: knooppunten en randen. Randen geven relaties tussen knooppunten op. Knooppunten en randen kunnen eigenschappen hebben die informatie bieden over dat knooppunt of die rand, vergelijkbaar met kolommen in een tabel. Randen kunnen ook een richting hebben die op de aard van de relatie duidt.
Grafiekdatabases kunnen efficiënt query's uitvoeren in het netwerk van knooppunten en randen en de relaties tussen entiteiten analyseren. In het volgende diagram ziet u de personeelsdatabase van een organisatie die is gestructureerd als een grafiek. De entiteiten zijn werknemers en afdelingen en de randen geven rapportagerelaties en de afdelingen waarin werknemers werken aan.
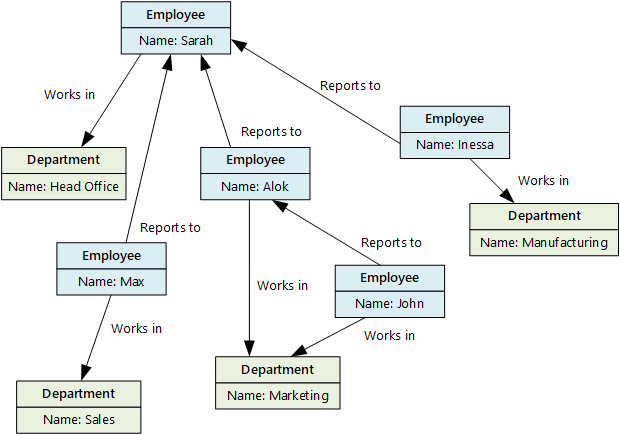
Deze structuur maakt het eenvoudig om query's uit te voeren, zoals 'Zoek alle werknemers die direct of indirect rapporteren aan Sarah' of 'Wie werkt op dezelfde afdeling als John?' Voor grote grafieken met veel entiteiten en relaties kunt u zeer snel zeer complexe analyses uitvoeren. Vele diagramdatabases hebben een querytaal waarmee u een netwerk van relaties efficiënt kunt doorlopen.
Azure-services
Workload
- Complexe relaties tussen gegevensitems met veel hops tussen gerelateerde gegevensitems.
- De relaties tussen gegevensitems zijn dynamisch en veranderen in de loop van de tijd.
- Relaties tussen de objecten zijn eersteklasrelaties, waarvoor geen refererende sleutels zijn vereist of joins hoeven te worden doorlopen.
Gegevenstype
- Knooppunten en relaties.
- Knooppunten zijn vergelijkbaar met tabelrijen of JSON-documenten.
- Relaties zijn net zo belangrijk als knooppunten en worden rechtstreeks in de querytaal weergegeven.
- Samengestelde objecten, zoals een persoon met meerdere telefoonnummers, worden vaak onderverdeeld in afzonderlijke, kleinere knooppunten, gecombineerd met doorloopbare relaties
Voorbeelden
- Organigrammen
- Sociaal diagram
- Fraudedetectie
- Aanbevelingsengines
Gegevensanalyse
Archieven voor gegevensanalyse bieden massaal parallelle oplossingen voor het opnemen, opslaan en analyseren van gegevens. De gegevens worden verdeeld over meerdere servers om de schaalbaarheid te maximaliseren. Grote gegevensbestandsindelingen, zoals csv-bestanden (scheidingstekens), parquet en ORC , worden veel gebruikt in gegevensanalyse. Historische gegevens worden doorgaans opgeslagen in gegevensarchieven, zoals blobopslag of Azure Data Lake Storage Gen2, die vervolgens worden geopend door Azure Synapse, Databricks of HDInsight als externe tabellen. Een typisch scenario waarin gegevens worden gebruikt die zijn opgeslagen als Parquet-bestanden voor prestaties, wordt beschreven in het artikel Externe tabellen gebruiken met Synapse SQL.
Azure-services
- Azure Synapse Analytics | (beveiligingsbasislijn)
- Azure Data Lake | (beveiligingsbasislijn)
- Azure Data Explorer | (beveiligingsbasislijn)
- Azure Analysis Services
- HDInsight | (beveiligingsbasislijn)
- Azure Databricks | (beveiligingsbasislijn)
Workload
- Gegevensanalyse
- Enterprise BI
Gegevenstype
- Historische gegevens uit meerdere bronnen.
- Gewoonlijk gedenormaliseerd in een 'ster'- of 'sneeuwvlokschema', bestaande uit feiten- en dimensietabellen.
- Gewoonlijk geladen met nieuwe gegevens volgens planning.
- Dimensietabellen bevatten vaak meerdere historische versies van een entiteit, aangeduid als een langzaam wijzigende dimensie.
Voorbeelden
- Datawarehouse op bedrijfsniveau
Kolomfamiliedatabases
In een kolomfamiliedatabase zijn de gegevens in rijen en kolommen gerangschikt. In zijn eenvoudigste vorm kan een kolomfamiliedatabase sterk overeenkomen met een relationele database, althans conceptueel. De ware kracht van een kolomfamiliedatabase ligt in de gedenormaliseerde benadering van het structureren van verspreide gegevens.
U kunt zich een kolomfamiliedatabase voorstellen als een database met tabelgegevens met rijen en kolommen. De kolommen zijn echter onderverdeeld in groepen, de zogenaamde kolomfamilies. Elke kolomfamilie bevat een verzameling kolommen die logisch gerelateerd zijn en die gewoonlijk als een eenheid worden opgehaald of behandeld. Andere gegevens die afzonderlijk worden geopend, kunnen in aparte kolomfamilies worden opgeslagen. Binnen een kolomfamilie kunnen nieuwe kolommen dynamisch worden toegevoegd en rijen kunnen verspreid zijn (dat wil zeggen dat een rij geen waarde voor elke kolom hoeft te hebben).
In het volgende diagram wordt een voorbeeld getoond met twee kolomfamilies, Identity en Contact Info. De gegevens voor één entiteit hebben dezelfde rijsleutel in elke kolomfamilie. Deze structuur, waarin de rijen voor een bepaald object in een kolomfamilie sterk kunnen wisselen, is een belangrijk voordeel van een degelijke benadering. Deze wijze van gegevensopslag is daarom erg geschikt voor het opslaan van gestructureerde, snel veranderende gegevens.

In tegenstelling tot sleutel-/waardearchieven of documentdatabases worden in de meeste kolomfamiliedatabases gegevens op volgorde van de sleutel opgeslagen in plaats van op een berekende hash-waarde. In vele implementaties kunt u indices maken voor bepaalde kolommen in een kolomfamilie. Met indices kunt u gegevens op kolomwaarde ophalen in plaats van op rijsleutel.
Lees- en schrijfbewerkingen voor een rij zijn gewoonlijk atomisch voor één kolomfamilie, hoewel sommige implementaties atomiciteit bieden voor de hele rij, waardoor meerdere kolomfamilies omvatten.
Azure-services
- Azure Cosmos DB voor Apache Cassandra | (beveiligingsbasislijn)
- HBase in HDInsight | (beveiligingsbasislijn)
Workload
- De meeste kolomfamiliedatabases voeren schrijfbewerkingen zeer snel uit.
- Update- en verwijderbewerkingen zijn relatief zeldzaam.
- Ontworpen om toegang van hoge doorvoer en lage latentie te bieden.
- Eenvoudige toegang tot query's wordt voor een bepaalde set velden in een veel grotere record ondersteund.
- Zeer schaalbaar.
Gegevenstype
- Gegevens worden opgeslagen in tabellen met een sleutelkolom en een of meer kolomfamilies.
- Afzonderlijke rijen in specifieke kolommen kunnen variëren.
- Afzonderlijke cellen zijn toegankelijk via get- en put-opdrachten
- Meerdere rijen worden geretourneerd met behulp van een scanopdracht.
Voorbeelden
- Aanbevelingen
- Personalisatie
- Sensorgegevens
- Telemetrie
- Berichten
- Analyse van sociale media
- Webanalyse
- Controle van activiteiten
- Weergegevens en andere gegevens uit tijdreeksen
Zoekprogrammadatabases
Met een zoekmachinedatabase kunnen toepassingen zoeken naar informatie die is opgeslagen in externe gegevensarchieven. Een zoekmachinedatabase kan enorme hoeveelheden gegevens indexeren en bijna realtime toegang bieden tot deze indexen.
Indices kunnen multidimensionaal zijn en het zoeken in grote volumes vrije tekstgegevens mogelijk maken. Het indexeren kan met een pull-model worden uitgevoerd en geactiveerd door de zoekprogrammadatabase. Er kan ook een push-model worden gebruikt, die door de externe toepassingscode wordt gestart.
Het zoeken kan exact of fuzzy zijn. Bij een fuzzy zoekopdracht worden documenten gevonden die met een verzameling termen overeenkomen en wordt berekend wat de overeenkomst is. Sommige zoekprogramma's ondersteunen ook een taalkundige analyse die matches kan retourneren op basis van synoniemen, genre-uitbreidingen (bijvoorbeeld door dogs met pets te matchen) en zoeken op stam (waarbij woorden met dezelfde stam worden vergeleken).
Azure-service
Workload
- Gegevensindexen uit meerdere bronnen en services.
- Query's zijn ad hoc en kunnen complex zijn.
- Zoeken in volledige tekst vereist.
- Ad-hocselfservicequery's vereist.
Gegevenstype
- Semi-gestructureerde of ongestructureerde tekst
- Tekst met verwijzing naar gestructureerde gegevens
Voorbeelden
- Productcatalogus
- Websites zoeken
- Logboekregistratie
Tijdreeksdatabases
Tijdreeksgegevens zijn een set waarden die zijn geordend op tijd. Tijdreeksdatabases verzamelen doorgaans grote hoeveelheden gegevens in realtime uit een groot aantal bronnen. Updates worden zelden uitgevoerd en verwijderingen worden vaak als een bulkbewerking uitgevoerd. Hoewel de naar een tijdreeksdatabase geschreven records in het algemeen klein zijn, gaat het vaak om grote aantallen records en kan de totale grootte snel toenemen.
Azure-service
Workload
- Records worden in het algemeen opeenvolgend in volgorde van tijd toegevoegd.
- Een overweldigend deel van de bewerkingen (95-99%) zijn schrijfbewerkingen.
- Updates zijn zeldzaam.
- Verwijderingen worden bulksgewijs uitgevoerd op aaneengesloten blokken of records.
- Gegevens worden opeenvolgend gelezen in oplopende of aflopende tijdsvolgorde, vaak parallel.
Gegevenstype
- Een tijdstempel wordt gebruikt als de primaire sleutel en het sorteermechanisme.
- Tags kunnen aanvullende informatie definiëren over het type, de oorsprong en andere informatie over de vermelding.
Voorbeelden
- Bewakings- en gebeurtenistelemetrie.
- Sensor- of andere IoT-gegevens.
Objectopslag
Objectopslag is geoptimaliseerd voor het opslaan en ophalen van grote, binaire objecten (afbeeldingen, bestanden, video- en audiostreams, documenten en gegevensobjecten van grote toepassingen en installatiekopieën van virtuele machines). Grote gegevensbestanden worden ook populair gebruikt in dit model, bijvoorbeeld scheidingstekens (CSV), parquet en ORC. Objectarchieven kunnen zeer grote hoeveelheden ongestructureerde gegevens beheren.
Azure-service
Workload
- Geïdentificeerd op sleutel.
- Inhoud is doorgaans een asset, zoals een scheidingsteken, afbeelding of videobestand.
- Inhoud moet duurzaam en extern zijn voor elke toepassingslaag.
Gegevenstype
- Omvangrijke gegevensgrootte.
- Waarde is ondoorzichtig.
Voorbeelden
- Afbeeldingen, video's, Office-documenten, PDF-bestanden
- Statische HTML, JSON, CSS
- Logboek- en auditbestanden
- Databaseback-ups
Gedeelde bestanden
Soms kan het gebruik van eenvoudige, platte bestanden de meest efficiënte manier zijn voor het opslaan en ophalen van informatie. Dankzij het gebruik van bestandsshares kunnen bestanden in een heel netwerk worden geopend. Met de juiste beveiliging- en controlemechanismen voor gelijktijdige toegang, kunnen gedistribueerde services - als gegevens op deze manier worden gedeeld - hoog schaalbare gegevenstoegang bieden voor het uitvoeren van bewerkingen op laag niveau, zoals eenvoudige lees- en schrijfaanvragen.
Azure-service
Workload
- Migratie van bestaande apps die interactie met het bestandssysteem aangaan.
- SMB-interface vereist.
Gegevenstype
- Bestanden in een hiërarchische verzameling mappen.
- Toegankelijk met standaard-I/O-bibliotheken.
Voorbeelden
- Verouderde bestanden
- Gedeelde inhoud is toegankelijk voor een aantal VM's of app-exemplaren
De volgende stap is het evalueren van uw workload en toepassing en bepalen welke gegevensopslag aan uw specifieke behoeften voldoet. Gebruik de beslissingsstructuur voor gegevensopslag om u te helpen met dit proces.
Volgende stappen
- Oplossingen en services voor Azure Cloud Storage
- Uw opslagopties controleren
- Kennismaking met Azure Storage
- Inleiding tot Azure Data Explorer
Verwante resources
- Big data architectures (Big data-architecturen)
- Een technologie voor gegevensopslag kiezen
- Beslissingsstructuur voor gegevensarchief