In dit artikel wordt een alternatieve benadering beschreven voor datawarehouseprojecten die experimentele gegevensanalyse (EDA) worden genoemd. Deze aanpak kan de uitdagingen van ETL-bewerkingen (extract, transform, load) verminderen. Het richt zich eerst op het genereren van bedrijfsinzichten en vervolgens op het oplossen van de modellering en ETL-taken.
Architectuur

Een Visio-bestand van deze architectuur downloaden.
Voor EDA maakt u zich alleen zorgen over de rechterkant van het diagram. Serverloze Azure Synapse SQL wordt gebruikt als de rekenengine voor de data lake-bestanden.
Ga als volgende te werk om EDA uit te voeren:
- T-SQL-query's worden rechtstreeks uitgevoerd in serverloze Azure Synapse SQL of Azure Synapse Spark.
- Query's worden uitgevoerd vanuit een grafisch queryprogramma, zoals Power BI of Azure Data Studio.
We raden u aan om alle lakehouse-gegevens op te zetten met behulp van Parquet of Delta.
U kunt de linkerkant van het diagram (gegevensopname) implementeren met behulp van elk hulpprogramma voor extraheren, laden, transformeren (ELT). Het heeft geen effect op EDA.
Onderdelen
Azure Synapse Analytics combineert gegevensintegratie, zakelijke datawarehousing en big data-analyses ten opzichte van lakehouse-gegevens. In deze oplossing:
- Een Azure Synapse-werkruimte bevordert de samenwerking tussen data engineers, gegevenswetenschappers, gegevensanalisten en BI-professionals (Business Intelligence) voor EDA-taken.
- Serverloze SQL-pools van Azure Synapse analyseren ongestructureerde en semi-gestructureerde gegevens in Azure Data Lake Storage met behulp van standaard T-SQL.
- Serverloze Apache Spark-pools in Azure Synapse voeren code-first verkenningen uit in Data Lake Storage met behulp van Spark-talen zoals Spark SQL, PySpark en Scala.
Azure Data Lake Storage biedt opslag voor gegevens die vervolgens worden geanalyseerd door serverloze SQL-pools van Azure Synapse.
Azure Machine Learning biedt gegevens aan Azure Synapse Spark.
Power BI wordt in deze oplossing gebruikt om query's uit te voeren op gegevens om EDA uit te voeren.
Alternatieven
U kunt serverloze Synapse SQL-pools vervangen of aanvullen met Azure Databricks.
In plaats van een lakehouse-model te gebruiken met serverloze Synapse SQL-pools, kunt u toegewezen SQL-pools van Azure Synapse gebruiken om zakelijke gegevens op te slaan. Bekijk de use cases en overwegingen in dit artikel en gerelateerde resources om te bepalen welke technologie moet worden gebruikt.
Scenariodetails
Deze oplossing toont een implementatie van de EDA-benadering voor datawarehouse-projecten. Deze aanpak kan de uitdagingen van ETL-bewerkingen verminderen. Het richt zich eerst op het genereren van bedrijfsinzichten en vervolgens op het oplossen van modellering en ETL-taken.
Potentiële gebruikscases
Andere scenario's die kunnen profiteren van dit analysepatroon:
Prescriptieve analyses. Stel vragen over uw gegevens, zoals volgende beste actie, of wat doen we vervolgens? Gebruik gegevens om meer gegevensgestuurd en minder gevoelsgestuurd te zijn. De gegevens kunnen ongestructureerd zijn en uit veel externe bronnen van verschillende kwaliteit. U kunt de gegevens zo snel mogelijk gebruiken om uw bedrijfsstrategie te evalueren zonder de gegevens daadwerkelijk in een datawarehouse te laden. U kunt de gegevens verwijderen nadat u uw vragen hebt beantwoord.
Selfservice ETL. Voer ETL/ELT uit wanneer u uw EDA-activiteiten (data sandboxing) uitvoert. Transformeer gegevens en maak deze waardevol. Dit kan de schaal van uw ETL-ontwikkelaars verbeteren.
Verkennende gegevensanalyse
Voordat we nader bekijken hoe EDA werkt, is het de moeite waard om de traditionele benadering van datawarehouse-projecten samen te vatten. De traditionele benadering ziet er als volgt uit:
Vereisten verzamelen. Documenteer wat u met de gegevens moet doen.
Gegevensmodellering. Bepaal hoe u de numerieke en kenmerkgegevens modelleren in feiten- en dimensietabellen. Normaal gesproken voert u deze stap uit voordat u de nieuwe gegevens verkrijgt.
ETL. Verwerf de gegevens en masseer deze in het gegevensmodel van het datawarehouse.
Deze stappen kunnen weken of zelfs maanden duren. Alleen dan kunt u beginnen met het opvragen van de gegevens en het zakelijke probleem op te lossen. De gebruiker ziet pas waarde nadat de rapporten zijn gemaakt. De oplossingsarchitectuur ziet er meestal ongeveer als volgt uit:
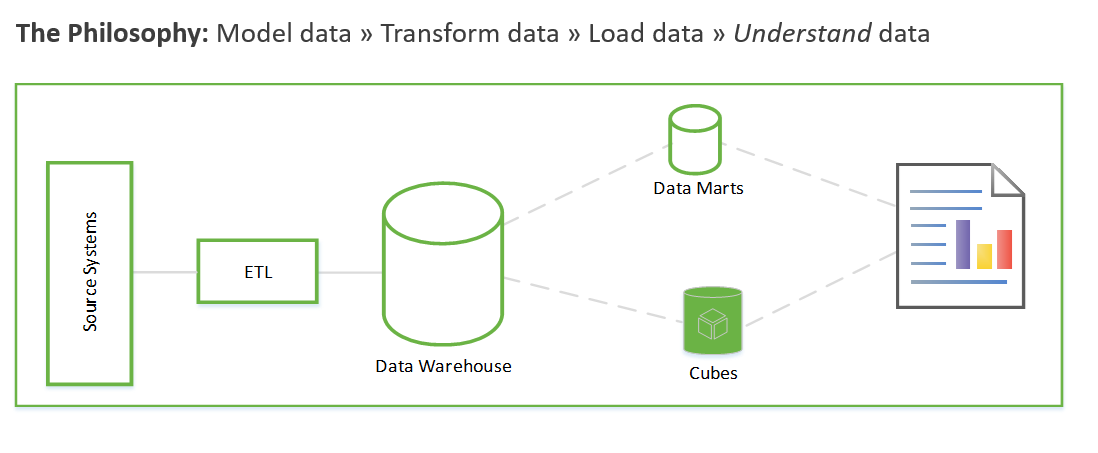
U kunt dit op een andere manier doen die zich eerst richt op het genereren van bedrijfsinzichten en vervolgens het oplossen van de modellerings- en ETL-taken. Het proces is vergelijkbaar met data science-processen. Het ziet er ongeveer als volgt uit:
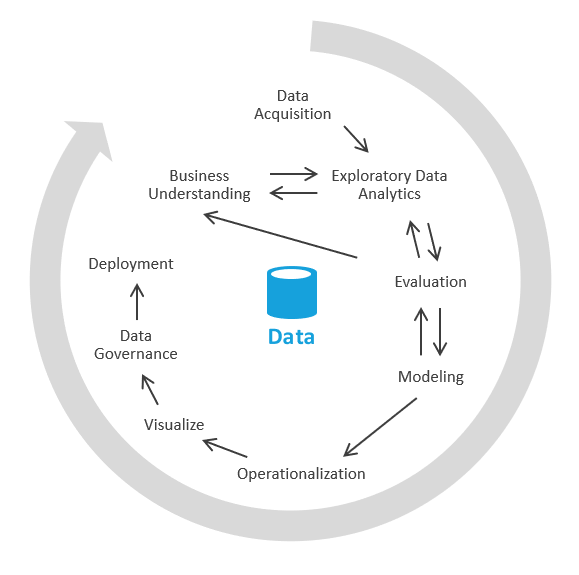
In de branche wordt dit proces EDA of experimentele gegevensanalyse genoemd.
Dit zijn de stappen:
Gegevensverwerving. Eerst moet u bepalen welke gegevensbronnen u moet opnemen in uw Data Lake/sandbox. Vervolgens moet u die gegevens overbrengen naar het landingsgebied van uw meer. Azure biedt hulpprogramma's zoals Azure Data Factory en Azure Logic Apps waarmee gegevens snel kunnen worden opgenomen.
Gegevens sandboxing. In eerste instantie werken een bedrijfsanalist en een technicus die ervaring heeft met verkennende gegevensanalyse via serverloze of eenvoudige SQL van Azure Synapse Analytics. Tijdens deze fase proberen ze het zakelijke inzicht te ontdekken met behulp van de nieuwe gegevens. EDA is een iteratief proces. Mogelijk moet u meer gegevens opnemen, praten met kmo's, meer vragen stellen of visualisaties genereren.
Evaluatie. Nadat u het zakelijke inzicht hebt gevonden, moet u evalueren wat u moet doen met de gegevens. Mogelijk wilt u de gegevens in het datawarehouse behouden (zodat u naar de modelleringsfase gaat). In andere gevallen kunt u besluiten om de gegevens in data lake/lakehouse te bewaren en deze te gebruiken voor predictive analytics (machine learning-algoritmen). In nog andere gevallen kunt u besluiten om uw recordsystemen te vullen met de nieuwe inzichten. Op basis van deze beslissingen krijgt u een beter inzicht in wat u vervolgens moet doen. Mogelijk hoeft u GEEN ETL uit te voeren.
Deze methoden vormen de kern van echte selfserviceanalyses. Met behulp van de data lake en een queryhulpprogramma zoals Azure Synapse serverloos dat inzicht heeft in data lake-querypatronen, kunt u uw gegevensassets in handen van zakelijke mensen die inzicht hebben in een modicum van SQL. U kunt de time-to-value aanzienlijk verkorten met behulp van deze methode en een deel van het risico verwijderen dat is gekoppeld aan initiatieven voor bedrijfsgegevens.
Overwegingen
Met deze overwegingen worden de pijlers van het Azure Well-Architected Framework geïmplementeerd. Dit is een set richtlijnen die kunnen worden gebruikt om de kwaliteit van een workload te verbeteren. Zie Microsoft Azure Well-Architected Framework voor meer informatie.
Beschikbaarheid
Serverloze Azure Synapse SQL-pools is een PaaS-functie (Platform as a Service) die kan voldoen aan uw vereisten voor hoge beschikbaarheid (HA) en herstel na noodgevallen.
Serverloze pools zijn op aanvraag beschikbaar. Ze hoeven niet op te schalen, omlaag, in of uit te schalen of te beheren van welke aard dan ook. Ze gebruiken een model voor betalen per query, dus er is op elk moment geen ongebruikte capaciteit. Serverloze pools zijn ideaal voor:
- Ad-hoc data science-verkenningen in T-SQL.
- Vroege prototypen voor datawarehouse-entiteiten.
- Weergaven definiëren die consumenten kunnen gebruiken, bijvoorbeeld in Power BI, voor scenario's die prestatievertraging kunnen verdragen.
- Verkennende gegevensanalyse.
Operations
Synapse SQL serverloos maakt gebruik van standaard T-SQL voor het uitvoeren van query's en bewerkingen. U kunt de gebruikersinterface van de Synapse-werkruimte, Azure Data Studio of SQL Server Management Studio gebruiken als het T-SQL-hulpprogramma.
Kostenoptimalisatie
Kostenoptimalisatie gaat over manieren om onnodige uitgaven te verminderen en operationele efficiëntie te verbeteren. Zie Overzicht van de pijler kostenoptimalisatie voor meer informatie.
De prijzen van Data Lake Storage zijn afhankelijk van de hoeveelheid gegevens die u opslaat en hoe vaak u de gegevens gebruikt. De voorbeeldprijzen omvatten één TB aan gegevens die zijn opgeslagen, met verdere transactionele veronderstellingen. De ene TB verwijst naar de grootte van de data lake, niet naar de grootte van de oorspronkelijke verouderde database.
Azure Synapse Spark-pool baseert prijzen op knooppuntgrootte, aantal exemplaren en uptime. In het voorbeeld wordt uitgegaan van één klein rekenknooppunt met gebruik tussen vijf uur per week en 40 uur per maand.
Serverloze SQL-pool van Azure Synapse baseert prijzen op TB's met verwerkte gegevens. In het voorbeeld wordt ervan uitgegaan dat er 50 TB per maand zijn verwerkt. Deze afbeelding verwijst naar de grootte van de data lake, niet naar de grootte van de oorspronkelijke verouderde database.
Medewerkers
Dit artikel wordt bijgewerkt en onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- Dave Wentzel | Principal MTC Technical Architect
Volgende stappen
- Data-engineer leertrajecten
- Zelfstudie: Aan de slag met Azure Synapse Analytics
- Een individuele database maken - Azure SQL Database
- Azure Synapse SQL-architectuur
- Een opslagaccount maken voor Azure Data Lake Storage
- Quickstart voor Azure Event Hubs - Een Event Hub maken met behulp van Azure Portal
- Quickstart: Een Stream Analytics-taak maken met behulp van Azure Portal
- Quickstart: Aan de slag met Azure Machine Learning
Verwante resources
- Meer informatie over: