Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Een data lake is een opslagopslagplaats met een grote hoeveelheid gegevens in de oorspronkelijke, onbewerkte indeling. Data Lake Stores zijn geoptimaliseerd voor het schalen van hun grootte naar terabytes en petabytes aan gegevens. De gegevens zijn doorgaans afkomstig uit meerdere verschillende bronnen en kunnen gestructureerde, semi-gestructureerde of ongestructureerde gegevens bevatten. Een data lake helpt u om alles in de oorspronkelijke, niet-vertaalde staat op te slaan. Deze methode verschilt van een traditioneel datawarehouse, dat gegevens transformeert en verwerkt op het moment van opname.
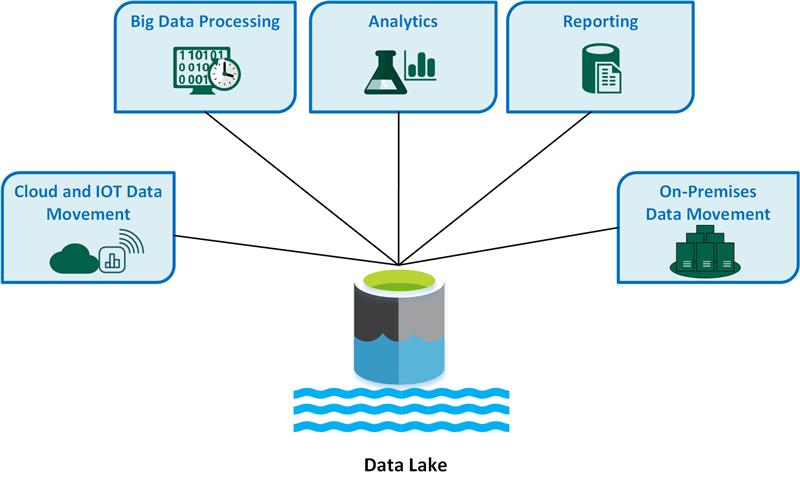
Belangrijke data lake-gebruiksvoorbeelden zijn:
- Gegevensverplaatsing van Cloud en Internet of Things (IoT).
- Verwerking van big data.
- Data-analyse.
- Berichtgeving.
- On-premises gegevensverplaatsing.
Houd rekening met de volgende voordelen van een data lake:
Een data lake verwijdert nooit gegevens omdat er gegevens in de onbewerkte indeling worden opgeslagen. Deze functie is vooral handig in een big data-omgeving, omdat u mogelijk niet van tevoren weet welke inzichten u uit de gegevens kunt verkrijgen.
Gebruikers kunnen de gegevens verkennen en hun eigen query's maken.
Een data lake kan sneller zijn dan traditionele ETL-hulpprogramma's (extract, transform, load).
Een data lake is flexibeler dan een datawarehouse omdat er ongestructureerde en semi-gestructureerde gegevens kunnen worden opgeslagen.
Een volledige Data Lake-oplossing bestaat uit zowel opslag als verwerking. Data Lake Storage is ontworpen voor fouttolerantie, oneindige schaalbaarheid en de snelle opname van gegevens in verschillende vormen en maten. Data lake-verwerking omvat een of meer verwerkingsengines die deze doelen kunnen opnemen en kunnen worden gebruikt op gegevens die op schaal zijn opgeslagen in een data lake.
Wanneer u een data lake moet gebruiken
U wordt aangeraden een data lake te gebruiken voor gegevensverkenning, gegevensanalyse en machine learning.
Een data lake kan fungeren als de gegevensbron voor een datawarehouse. Wanneer u deze methode gebruikt, neemt de data lake onbewerkte gegevens op en transformeert deze vervolgens in een gestructureerde opvraagbare indeling. Deze transformatie maakt doorgaans gebruik van een ELT-pijplijn (extract, load, transform) waarin de gegevens worden opgenomen en getransformeerd. Relationele brongegevens kunnen rechtstreeks naar het datawarehouse gaan via een ETL-proces en de data lake overslaan.
U kunt Data Lake Stores gebruiken in gebeurtenisstreaming- of IoT-scenario's, omdat data lakes grote hoeveelheden relationele en niet-relationele gegevens kan persistent maken zonder transformatie of schemadefinitie. Data Lakes kan grote hoeveelheden kleine schrijfbewerkingen verwerken met lage latentie en zijn geoptimaliseerd voor enorme doorvoer.
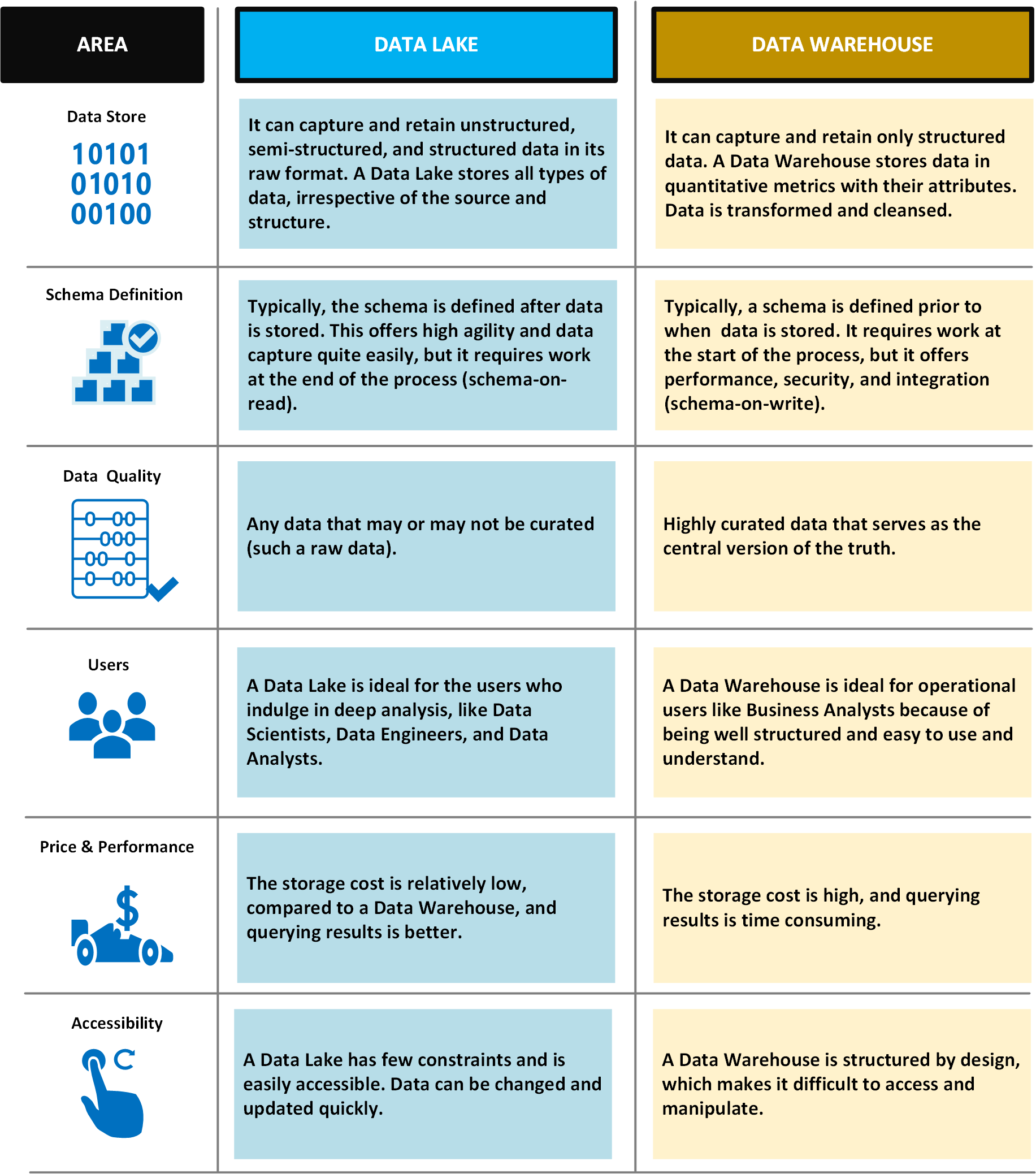
In de volgende tabel worden datalakes en datawarehouses vergeleken.
Uitdagingen
Grote hoeveelheden gegevens: het beheer van grote hoeveelheden onbewerkte en ongestructureerde gegevens kan complex en resource-intensief zijn, dus u hebt robuuste infrastructuur en hulpprogramma's nodig.
Mogelijke knelpunten: gegevensverwerking kan vertragingen en inefficiëntie veroorzaken, met name wanneer u grote hoeveelheden gegevens en diverse gegevenstypen hebt.
Risico's voor gegevensbeschadiging: Onjuiste gegevensvalidatie en -bewaking introduceert een risico op beschadiging van gegevens, waardoor de integriteit van de data lake kan worden aangetast.
Problemen met kwaliteitscontrole: De juiste gegevenskwaliteit is een uitdaging vanwege de verschillende gegevensbronnen en indelingen. U moet strenge procedures voor gegevensbeheer implementeren.
Prestatieproblemen: queryprestaties kunnen afnemen naarmate de data lake groeit, dus u moet de opslag- en verwerkingsstrategieën optimaliseren.
Technologieopties
Wanneer u een uitgebreide Data Lake-oplossing in Azure bouwt, moet u rekening houden met de volgende technologieën:
Azure Data Lake Storage combineert Azure Blob Storage met data lake-mogelijkheden, die apache Hadoop-compatibele toegang, hiërarchische naamruimtemogelijkheden en verbeterde beveiliging biedt voor efficiënte big data-analyses.
Azure Databricks is een geïntegreerd platform dat u kunt gebruiken om gegevens te verwerken, op te slaan, te analyseren en er geld mee te verdienen. Het ondersteunt ETL-processen, dashboards, beveiliging, gegevensverkenning, machine learning en generatieve AI.
Azure Synapse Analytics is een geïntegreerde service die u kunt gebruiken om gegevens op te nemen, te verkennen, voor te bereiden, te beheren en te leveren voor directe business intelligence- en machine learning-behoeften. Het integreert diep met Azure Data Lakes, zodat u efficiënt grote gegevenssets kunt doorzoeken en analyseren.
Azure Data Factory is een cloudservice voor gegevensintegratie die u kunt gebruiken om gegevensgestuurde werkstromen te maken om gegevensverplaatsing en transformatie vervolgens in te delen en te automatiseren.
Microsoft Fabric is een uitgebreid gegevensplatform dat data engineering, data science, datawarehousing, realtime analyses en business intelligence in één oplossing integreert.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Hoofdauteur:
- Avijit Prasad | Cloudconsultant
Als u niet-openbare LinkedIn-profielen wilt zien, meldt u zich aan bij LinkedIn.
Volgende stappen
- Wat is OneLake?
- Inleiding tot Data Lake Storage
- Documentatie voor Azure Data Lake Analytics
- Training: Inleiding tot Data Lake Storage
- Integratie van Hadoop en Azure Data Lake Storage
- Verbinding maken met Data Lake Storage en Blob Storage
- Gegevens laden in Data Lake Storage met Azure Data Factory