Continue validatie met Azure Load Testing en Azure Chaos Studio
Naarmate cloudeigen toepassingen en services complexer worden, kan het implementeren van wijzigingen en nieuwe releases voor hen lastig zijn. Storingen worden vaak veroorzaakt door defecte implementaties of releases. Maar fouten kunnen ook optreden na de implementatie, wanneer een toepassing echt verkeer ontvangt, met name in complexe workloads die worden uitgevoerd in zeer gedistribueerde multitenant-cloudomgevingen en die worden onderhouden door meerdere ontwikkelteams. Voor deze omgevingen zijn meer tolerantiemaatregelen vereist, zoals logica voor opnieuw proberen en automatisch schalen, die meestal moeilijk te testen zijn tijdens het ontwikkelingsproces.
Daarom is continue validatie in een omgeving die vergelijkbaar is met de productieomgeving belangrijk, zodat u eventuele problemen of bugs zo vroeg mogelijk in de ontwikkelingscyclus kunt vinden en oplossen. Workloadteams moeten vroeg in het ontwikkelingsproces testen (naar links verschuiven) en het voor ontwikkelaars handig maken om tests uit te voeren in een omgeving die zich dicht bij de productieomgeving bevindt.
Bedrijfskritieke workloads hebben hoge beschikbaarheidsvereisten, met doelen van respectievelijk 3, 4 of 5 negens (respectievelijk 99,9%, 99,99% of 99,999%). Het is van cruciaal belang om strenge geautomatiseerde tests te implementeren om deze doelen te bereiken.
Continue validatie is afhankelijk van elke workload en van architectuurkenmerken. Dit artikel bevat een handleiding voor het voorbereiden en integreren van Azure Load Testing en Azure Chaos Studio in een normale ontwikkelingscyclus.
1 – Tests definiëren op basis van verwachte drempelwaarden
Doorlopend testen is een complex proces waarvoor een goede voorbereiding is vereist. Wat wordt getest en de verwachte resultaten moeten duidelijk zijn.
In PE:06 - Aanbevelingen voor prestatietests en RE:08 - Aanbevelingen voor het ontwerpen van een strategie voor betrouwbaarheidstests, raadt het Azure Well-Architected Framework u aan om eerst belangrijke scenario's, afhankelijkheden, verwacht gebruik, beschikbaarheid, prestaties en schaalbaarheidsdoelen te identificeren.
Vervolgens moet u een set meetbare drempelwaarden definiëren om de verwachte prestaties van de belangrijkste scenario's te kwantificeren.
Tip
Voorbeelden van drempelwaarden zijn het verwachte aantal aanmeldingen van gebruikers, aanvragen per seconde voor een bepaalde API en bewerkingen per seconde voor een achtergrondproces.
U moet drempelwaarden gebruiken om een statusmodel voor uw toepassing te ontwikkelen, zowel voor het testen als voor het uitvoeren van de toepassing in productie.
Gebruik vervolgens de waarden om een belastingstest te definiëren waarmee realistisch verkeer wordt gegenereerd voor het testen van de prestaties van de basislijn van toepassingen, het valideren van verwachte schaalbewerkingen, enzovoort. Voortdurend kunstmatig gebruikersverkeer is nodig in preproductieomgevingen, omdat het zonder gebruik moeilijk runtimeproblemen te onthullen is.
Belastingstests zorgen ervoor dat wijzigingen in de toepassing of infrastructuur geen problemen veroorzaken en dat het systeem nog steeds voldoet aan de verwachte prestatie- en testcriteria. Een mislukte testuitvoering die niet voldoet aan de testcriteria geeft aan dat u de basislijn moet aanpassen of dat er een onverwachte fout is opgetreden.
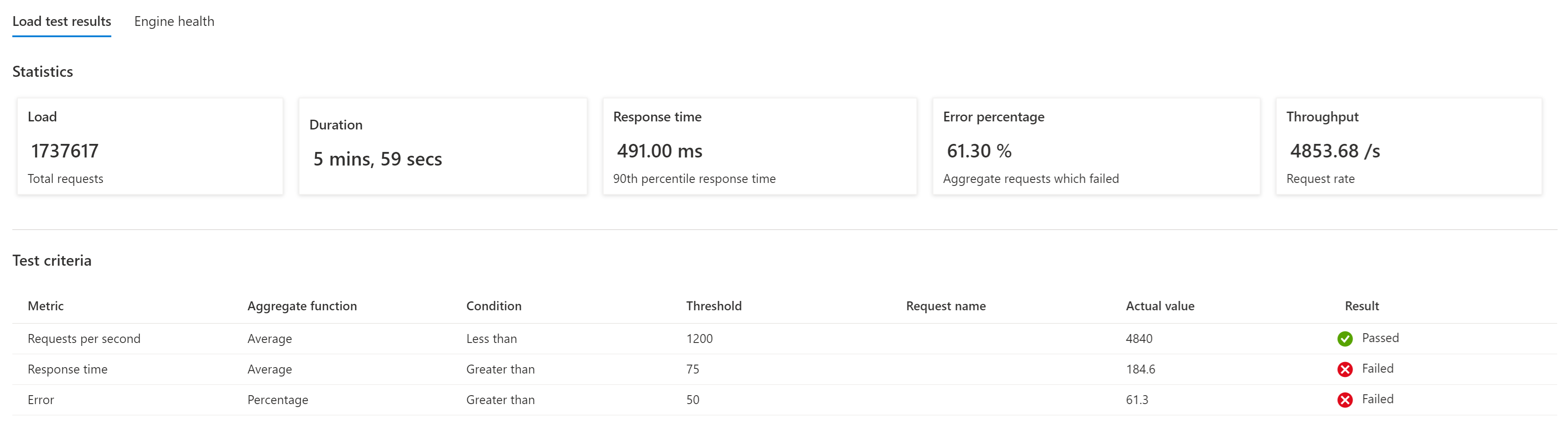
Hoewel geautomatiseerde tests dagelijks gebruik vertegenwoordigen, moet u handmatige belastingstests regelmatig uitvoeren om te controleren hoe het systeem reageert op onverwachte pieken.
Het tweede deel van continue validatie is de injectie van storingen (chaos engineering). Met deze stap wordt de tolerantie van een systeem gecontroleerd door te testen hoe het reageert op fouten. Bovendien werken alle tolerantiemetingen, zoals logica voor opnieuw proberen, automatisch schalen en andere, zoals verwacht.
2 - Validatie implementeren met Belasting testen en Chaos Studio
Microsoft Azure biedt deze beheerde services voor het implementeren van belastingtests en chaos-engineering:
- Azure Load Testing produceert synthetische gebruikersbelasting voor toepassingen en services.
- Azure Chaos Studio biedt de mogelijkheid om chaos-experimenten uit te voeren door systematisch fouten in toepassingsonderdelen en infrastructuur te injecteren.
U kunt zowel Chaos Studio als Load Testing implementeren en configureren via Azure Portal, maar in de context van continue validatie is het belangrijker dat u API's hebt om tests op een programmatische en geautomatiseerde manier te implementeren, configureren en uitvoeren. Door deze twee hulpprogramma's samen te gebruiken, kunt u zien hoe het systeem reageert op problemen en de mogelijkheid om zichzelf te herstellen als reactie op infrastructuur- of toepassingsfouten.
In de volgende video ziet u een gecombineerde implementatie van Chaos en Load Testing die is geïntegreerd in Azure DevOps:
Als u een bedrijfskritieke workload ontwikkelt, profiteert u van de referentiearchitecturen, gedetailleerde richtlijnen, voorbeeld-implementaties en codeartefacten die worden geleverd als onderdeel van het Azure Mission-Critical-project en het Azure Well-Architected Framework.
De Mission-Critical-implementatie implementeert de load testing-service via Terraform en bevat een verzameling PowerShell Core-wrapperscripts om via de API met de service te communiceren. Deze scripts kunnen rechtstreeks worden ingesloten in een implementatiepijplijn.
Een van de opties in de referentie-implementatie is het rechtstreeks uitvoeren van de belastingstest vanuit de end-to-end (e2e) pijplijn die wordt gebruikt voor het instellen van afzonderlijke (vertakkingsspecifieke) ontwikkelomgevingen:

De pijplijn voert automatisch een belastingtest uit, met of zonder chaos-experimenten (afhankelijk van de selectie) parallel:
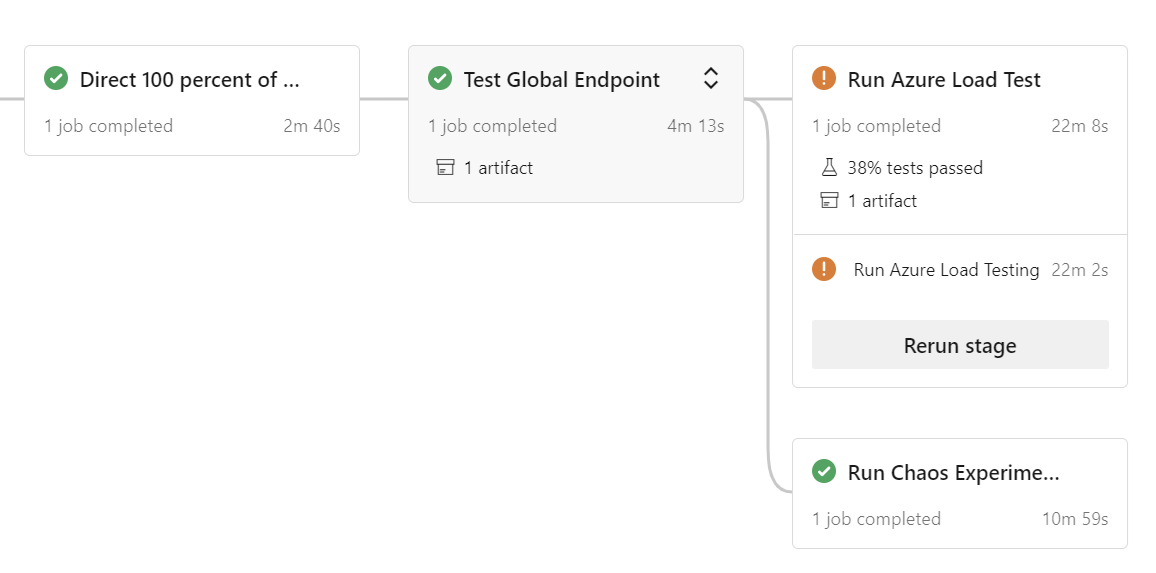
Notitie
Het uitvoeren van chaosexperimenten tijdens een belastingstest kan leiden tot een hogere latentie, hogere reactietijden en tijdelijk verhoogde foutpercentages. U ziet hogere getallen totdat een uitschaalbewerking is voltooid of een failover is voltooid, vergeleken met een uitvoering zonder chaosexperimenten.
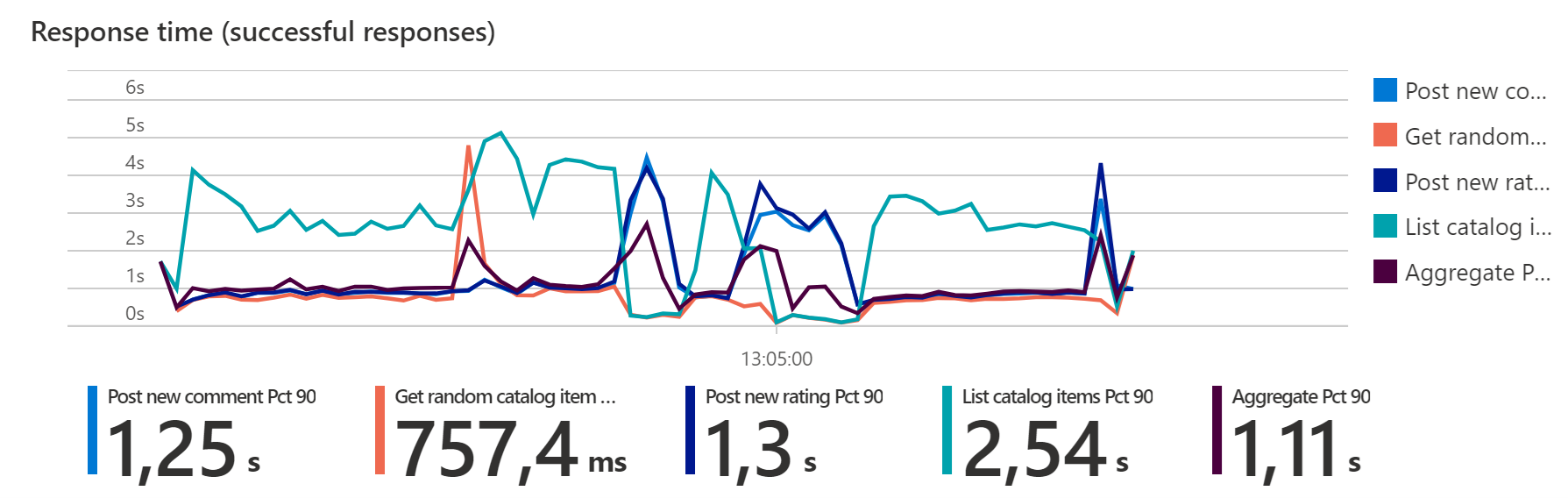
Afhankelijk van of chaostests zijn ingeschakeld en de keuze van experimenten, kunnen basislijndefinities variëren, omdat de tolerantie voor fouten kan verschillen in de status 'normaal' en 'chaos'.
3 – Drempelwaarden aanpassen en een basislijn instellen
Pas ten slotte de drempelwaarden voor de belastingstest voor reguliere uitvoeringen aan om te controleren of de toepassing (nog) de verwachte prestaties levert en geen fouten veroorzaakt. Zorg voor een afzonderlijke basislijn voor chaostests die verwachte pieken in foutpercentages en tijdelijke verminderde prestaties tolereren. Deze activiteit is continu en moet regelmatig worden herhaald. Bijvoorbeeld na het introduceren van nieuwe functies, het wijzigen van service-SKU's en andere.
De Azure Load Testing-service biedt een ingebouwde mogelijkheid, testcriteria genoemd, waarmee bepaalde criteria kunnen worden opgegeven die een test moet doorgeven. Deze mogelijkheid kan worden gebruikt om verschillende basislijnen te implementeren.

De mogelijkheid is beschikbaar via Azure Portal en via de load testing-API en de wrapperscripts die zijn ontwikkeld als onderdeel van Azure Mission-critical, bieden een optie om een basislijndefinitie op basis van JSON over te dragen.
We raden u ten zeerste aan deze tests rechtstreeks te integreren in uw CI/CD-pijplijnen en deze uit te voeren tijdens de vroege fasen van het ontwikkelen van functies. Zie de voorbeeld-implementatie in de Azure Mission-critical reference-implementatie voor een voorbeeld.
Kortom, fout is onvermijdelijk in elk complex gedistribueerd systeem en de oplossing moet daarom worden ontworpen (en getest) om fouten af te handelen. De goed ontworpen framework bedrijfskritieke workloadrichtlijnen en referentie-implementaties kunnen u helpen bij het ontwerpen en gebruiken van zeer betrouwbare toepassingen om de maximale waarde van de Microsoft-cloud af te leiden.
Volgende stap
Bekijk het ontwerpgebied voor implementatie en testen voor bedrijfskritieke workloads.
Verwante resources
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor